Python 网络爬虫基本概念篇
爬虫的概念
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。这是百度百科对爬虫的定义,其实,说简单点,爬虫就是利用写好的程序自动的提取网页的信息。
爬虫的价值
抓取互联网上的数据,为自己服务,有了大量的数据,就如同有了一个数据银行一样,下一步做的就是如何将这些爬取的数据产品化,商业化。马云都说过:未来最值钱的不是房子,而是数据。所以,有了数据,就如同有了大把的财富。从就业来看,做一个爬虫工程师或者数据分析师也是不错的选择。然后,在大数据非常火热的今天(简直是火热到一种无法形容的程度了,2017年我刚高中毕业的时候好像全国开大数据专业的就30个学校左右,如今,我们台州学院今年也申请成功了。前年,我们学院合并,数信和电子合并为电子与信息工程学院,又叫大数据学院。我们一直调侃说连大数据专业都没有,还叫什么大数据学院啊。现在,我们就可以从容的说我们是大数据学院了,这听起来还是挺高大上的,哈哈),爬虫技术的应用场景会越来越多,将来肯定会有很好的发展空间。
爬虫的合法性
这个怎么说呢,技术本身是好的,它只是一个工具,但是你用来做一些违法乱纪的事情,那当然就不好了。所以,具体情况具体分析吧,你做的犯不犯法,自己心里还是得有点逼数的。
爬虫的分类
- 通用爬虫:通用爬虫是搜索引擎(Baidu、Google、Yahoo等)“抓取系统”的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。 简单来讲就是尽可能的;把互联网上的所有的网页下载下来,放到本地服务器里形成备分,在对这些网页做相关处理(提取关键字、去掉广告),最后提供一个用户检索接口。
- 聚焦爬虫:聚焦爬虫是根据指定的需求抓取网络上指定的数据。例如:获取豆瓣上电影的名称和影评,而不是获取整张页面中所有的数据值。
- 增量式爬虫:增量式是用来检测网站数据更新的情况,且可以将网站更新的数据进行爬取。
robots协议
就是所谓的"君子协议",是一个文本格式的文件,它里面表明了哪些内容可以爬取,哪些不可以爬取.这样既可以保护隐私和敏感信息,又可以被搜索引擎收录、增加流量。
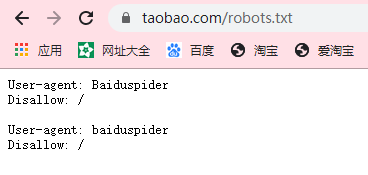
可以通过网站域名 + /robots.txt的形式访问该网站的协议详情,例如:https://www.taobao.com/robots.txt ,下面就是淘宝网的robots协议截图:
Python 网络爬虫基本概念篇的更多相关文章
- Python网络爬虫
http://blog.csdn.net/pi9nc/article/details/9734437 一.网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字. 把互联网比喻成一个蜘蛛 ...
- Python 网络爬虫 001 (科普) 网络爬虫简介
Python 网络爬虫 001 (科普) 网络爬虫简介 1. 网络爬虫是干什么的 我举几个生活中的例子: 例子一: 我平时会将 学到的知识 和 积累的经验 写成博客发送到CSDN博客网站上,那么对于我 ...
- 关于Python网络爬虫实战笔记①
python网络爬虫项目实战笔记①如何下载韩寒的博客文章 python网络爬虫项目实战笔记①如何下载韩寒的博客文章 1. 打开韩寒博客列表页面 http://blog.sina.com.cn/s/ar ...
- python 网络爬虫(二) BFS不断抓URL并放到文件中
上一篇的python 网络爬虫(一) 简单demo 还不能叫爬虫,只能说基础吧,因为它没有自动化抓链接的功能. 本篇追加如下功能: [1]广度优先搜索不断抓URL,直到队列为空 [2]把所有的URL写 ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- python网络爬虫之初始网络爬虫
第一次接触到python是一个很偶然的因素,由于经常在网上看连载小说,很多小说都是上几百的连载.因此想到能不能自己做一个工具自动下载这些小说,然后copy到电脑或者手机上,这样在没有网络或者网络信号不 ...
- 如何利用Python网络爬虫抓取微信朋友圈的动态(上)
今天小编给大家分享一下如何利用Python网络爬虫抓取微信朋友圈的动态信息,实际上如果单独的去爬取朋友圈的话,难度会非常大,因为微信没有提供向网易云音乐这样的API接口,所以很容易找不到门.不过不要慌 ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 《精通python网络爬虫》笔记
<精通python网络爬虫>韦玮 著 目录结构 第一章 什么是网络爬虫 第二章 爬虫技能概览 第三章 爬虫实现原理与实现技术 第四章 Urllib库与URLError异常处理 第五章 正则 ...
随机推荐
- 201843 2019-2020-2 《Python程序设计》实验二报告
201843 2019-2020-2 <Python程序设计>实验二报告 课程:<Python程序设计> 班级: 1843 姓名: 李新锐 学号:20184302 实验教师:王 ...
- 让.NetCore程序跑在任何有docker的地方
一.分别在Windows/Mac/Centos上安装Docker Windows上下载地址:https://docs.docker.com/docker-for-windows/install/(wi ...
- 从模块化到认识Babel
转载自:https://www.cnblogs.com/qcloud1001/p/10167756.html https://blog.csdn.net/a250758092/article/deta ...
- React:Component
web开发由web pages过渡到web app 后,开发的模式也发生了变化,由传统的主张结构.样式.行为分离到现在的组件化,把应用的各个部分看成解耦的部分,每部分自包含js.css和html,以方 ...
- 8086 8255A proteus仿真实验
目录 实验内容 电路图 电路分析 代码 实验内容 数码管循环显示0123456789abcdef- 电路图 电路分析 端口地址和控制字地址主要看电路图,片选信号由译码器的\(\overline{IO1 ...
- DPDK LPM库(学习笔记)
1 LPM库 DPDK LPM库组件为32位的key实现了最长前缀匹配(LPM)表查找方法,该方法通常用于在IP转发应用程序中找到最佳路由匹配. 2 LPM API概述 LPM组件实例的主要配置参数是 ...
- iperf压测linux网卡带宽
1.安装 yum install iperf --enablerepo=epel 2.启动服务端 iperf -s -i 1 3.启动客户端测试10分钟 iperf -c 172.16.3.153 - ...
- 蓝桥杯 试题 历届试题 对局匹配 DP解决
问题描述 小明喜欢在一个围棋网站上找别人在线对弈.这个网站上所有注册用户都有一个积分,代表他的围棋水平. 小明发现网站的自动对局系统在匹配对手时,只会将积分差恰好是K的两名用户匹配在一起.如果两人分差 ...
- 用开源软件TrinityCore在Debian 10上搭建魔兽世界8.3.0.34220的服务器
用开源软件TrinityCore在Debian 10上搭建魔兽世界8.3.0.34220的服务器 TrinityCore是魔兽世界(World of Warcraft)的开源的服务端.目前支持魔兽的3 ...
- Nginx判断客户端实现301跳转
set $a 0; #第一个条件 if ($uri !~* /(.*).php(.*)){ set $a 1; } #第二个条件 if ($http_user_agent ~* (up.UCBrows ...