Python网络数据采集- 创建爬虫
1. 初见网络爬虫
1.1 网络连接
输出某个网页的全部 HTML 代码。
urllib 是 Python 的标准库(就是说你不用额外安装就可以运行这个例子),包含了从网络请求数据,处理 cookie,甚至改变像请求头和用户代理这些元数据的函数。
from urllib.request import urlopen
html = urlopen("http://cn.bing.com")
print(html.read())
1.2 BeautifulSoup
BeautifulSoup 尝试化平淡为神奇。它通过定位 HTML 标签来格式化和组织复杂的网络信息,用简单易用的 Python 对象为我们展现 XML 结构信息。
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://cn.bing.com")
bsObj = BeautifulSoup(html.read())
print(bsObj.h1)
下面的所有函数调用都可以产生同样的结果。

urlopen代码主要可能会发生两种异常:
- 网页在服务器上不存在(或者获取页面的时候出现错误)
- 服务器不存在
第一种异常发生时,程序会返回“HTTPError”异常。
如果服务器不存在(就是说链接打不开,或者是 URL 链接写错了),urlopen 会返回一个 None 对象。
如果调用 None 对象下面的子标签,就会发生 AttributeError 错误。
2. 复杂HTML解析
2.1 BeautifulSoup进阶
1. 标签
基本上每个网站都会有层叠样式表(Cascading Style Sheet,CSS)。CSS 的发明是网络爬虫的福音。CSS 可以让 HTML 元素呈现出差异化,
使那些具有完全相同修饰的元素呈现出不同的样式。


网络爬虫可以通过 class 属性的值,轻松地区分出两种不同的标签。
获取博客园首页上的文章标题。
html源码:

from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("https://www.cnblogs.com/")
bsObj = BeautifulSoup(html)
titleList = bsObj.findAll("a", {"class": "titlelnk"})
for title in titleList:
print(title.get_text())
注:.get_text() 会把正在处理的 HTML 文档中所有的标签都清除,然后返回一个只包含文字的字符串。
find和findAll。
findAll(tag, attributes, recursive, text, limit, keywords)
find(tag, attributes, recursive, text, keywords)</DI< div>
标签参数 tag 可以接受一个标签的名称或多个标签名称组成的 Python 列表。
例如,下面的代码将返回一个包含 HTML 文档中所有标题标签的列表。
.findAll({"h1","h2","h3","h4","h5","h6"})
属性参数 attributes 是用一个 Python 字典封装一个标签的若干属性和对应的属性值。例如,下面这个函数会返回 HTML 文档里红色与绿色两种颜色的 span 标签。
.findAll("span", {"class":{"green", "red"}})
递归参数 recursive 是一个布尔变量。如果 recursive 设置为 True,findAll 就会根据要求去查找标签参数的所有子标签,以及子标签的子标签。如果 recursive 设置为 False,findAll 就只查找文档的一级标签。
文本参数 text 有点不同,它是用标签的文本内容去匹配,而不是用标签的属性。
List = bsObj.findAll(text = "园子") print(len(List))
结果为1。
find 其实等价于 findAll 的 limit 等于1 时的情形。
还有一个关键词参数 keyword,可以用于选择那些具有指定属性的标签。
List = bsObj.findAll(id = "site_nav_top") print(List)
[<div id="site_nav_top">代码改变世界</div>]
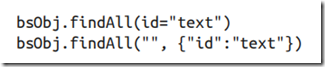
下面两行代码是完全一样的:
class 是 Python 语言的保留字,在 Python 程序里是不能当作变量或参数名使用的,可以在 class 后面增加一个下划线或者把 class 用引号包起来。
2. 导航树
在 BeautifulSoup 库里,孩子(child)和后代(descendant)有显著的不同:和人类的家谱一样,子标签就是一个父标签的下一级,而后代标签是指一个父标签下面所有级别的标签。
一般情况下,BeautifulSoup 函数总是处理当前标签的后代标签。例如,bsObj.body.h1 选择了 body 标签后代里的第一个 h1 标签,不会去找 body 外面的标签。
类似地,bsObj.div.findAll("img") 会找出文档中第一个 div 标签,然后获取这个 div 后代里所有的 img 标签列表。
- 使用 .children 找出子标签;
- 使用 .next_sibling(s) 获取后面的兄弟标签;
- 类似的 .previous_sibling(s) 向前获取兄弟标签;
- 使用 .parent(s) 获取父标签。
2.2 正则表达式
正则表达式可以作为 BeautifulSoup 语句的任意一个参数,让目标元素查找工作极具灵活性。
查看当前首页有多少提到“数据”的随笔。
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html = urlopen("https://www.cnblogs.com/")
bsObj = BeautifulSoup(html)
List = bsObj.findAll(text = re.compile(".*数据.*"))
print(len(List))
2.3 获取属性
对于一个标签对象,可以用下面的代码获取它的全部属性:
myTag.attrs
要注意这行代码返回的是一个 Python 字典对象,可以获取和操作这些属性。比如要获取图片的资源位置 src,可以用下面这行代码:
myImgTag.attrs["src"]
在网络数据采集时经常不需要查找标签的内容,而是需要查找标签属性。比如标签指向的 URL 链接包含在 href 属性中,或者标签的图片文件包含在 src 属性中,这时获取标签属性就变得非常有用了。
获取首页大家的头像地址。
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html = urlopen("https://www.cnblogs.com/")
bsObj = BeautifulSoup(html)
text = "https:\/\/pic\.cnblogs\.com\/face.+\.png"
imgList = bsObj.findAll("img", {"src": re.compile(text)})
for img in imgList:
print(img["src"])
print(len(imgList))
2.4 Lambda表达式
Lambda 表达式本质上就是一个函数,可以作为其他函数的变量使用。
BeautifulSoup 允许我们把特定函数类型当作 findAll 函数的参数。唯一的限制条件是这些函数必须把一个标签作为参数且返回结果是布尔类型。BeautifulSoup 用这个函数来评估它遇到的每个标签对象,最后把评估结果为“真”的标签保留,把其他标签剔除。
例如:
bsObj.findAll(lambda tag: len(tag.attrs) == 2)
2.5 单个域名采集
目标网址:https://baike.sogou.com/v58828.htm?fromTitle=Python
采集搜狗百科上Python词条简介里指向其他词条的链接。
词条链接有以下特点:
- class属性为"ed_inner_link";
- target属性为"_blank";
- 链接以"/lemma/ShowInnerLink.htm"开头。
为了避免一个页面被采集两次,链接去重是非常重要的。在代码运行时,把已发现的所有链接都放到一起,并保存在集合 set 中。这样,只有“新”链接才会被采集,之后再从页面中搜索其他链接。
通过爬虫在页面之间相互跳转:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import random
def getLinks(articleUrl):
html = urlopen("https://baike.sogou.com"+articleUrl)
bsObj = BeautifulSoup(html)
find = "\/lemma\/ShowInnerLink\.htm.+"
return bsObj.findAll("a", {"class": "ed_inner_link",
"target": "_blank",
"href": re.compile(find)})
links = getLinks("/v58828.htm?fromTitle=python")
for i in range(0,10):
if len(links) > 0:
ran = random.randint(0, len(links)-1)
newArticle = links[ran].attrs["href"]
print(i, links[ran].get_text())
links = getLinks(newArticle)
else:
print("爬虫中断")
break

4. 用Scrapy采集
Scrapy 就是一个大幅度降低网页链接查找和识别工作复杂度的 Python 库,它可以让用户轻松地采集一个或多个域名的信息。
教程:https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
4.1 创建项目
在开始爬取之前,必须创建一个新的Scrapy项目。进入打算存储代码的目录中,运行下列命令:
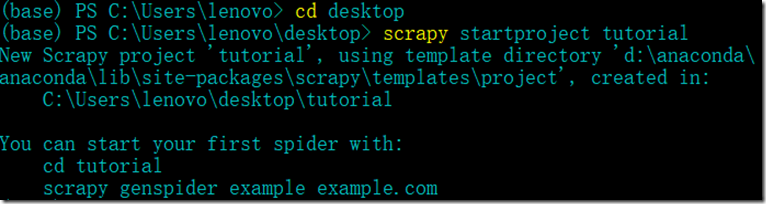
该命令将会创建包含下列内容的 tutorial 目录:
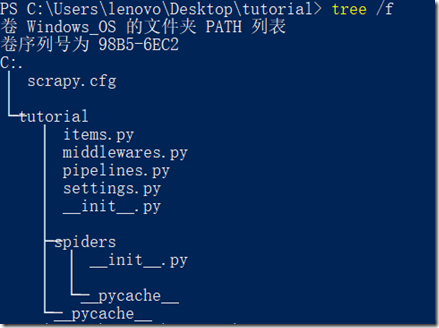
scrapy.cfg: 项目的配置文件;tutorial/: 该项目的python模块。之后将在此加入代码;tutorial/items.py: 项目中的item文件;tutorial/pipelines.py: 项目中的pipelines文件;tutorial/settings.py: 项目的设置文件;tutorial/spiders/: 放置spider代码的目录。
4.2 定义Item
Item 是保存爬取到的数据的容器;其使用方法和 python 字典类似, 并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
这里爬取博客园首页的文章信息(20条)。
import scrapy
class ArticleInfo(scrapy.Item):
title = scrapy.Field()#随笔标题
link = scrapy.Field()#随笔链接
author = scrapy.Field()#随笔作者
read = scrapy.Field()#随笔阅读量
4.3 编辑myspider.py
根据html结构:
<div class="post_item_body">
<h3><a class="titlelnk" href="https://www.cnblogs.com/lxfweb/p/12831417.html" target="_blank">DVWA-对Command Injection(命令注入)的简单演示与分析</a></h3>
<p class="post_item_summary">
<a href="https://www.cnblogs.com/lxfweb/" target="_blank"><img width="48" height="48" class="pfs" src="https://pic.cnblogs.com/face/1996712/20200405145811.png" alt=""/></a> 前言 上一篇文章中,对命令注入进行了简单的分析,有兴趣的可以去看一看,文章地址 https://www.cnblogs.com/lxfweb/p/12828754.html,今天这篇文章以DVWA的Command Injection(命令注入)模块为例进行演示与分析,本地搭建DVWA程序可以看这篇文 ...
</p>
<div class="post_item_foot">
<a href="https://www.cnblogs.com/lxfweb/" class="lightblue">雪痕*</a>
发布于 2020-05-05 17:10
<span class="article_comment"><a href="https://www.cnblogs.com/lxfweb/p/12831417.html#commentform" title="0001-01-01 08:05" class="gray">
评论(0)</a></span><span class="article_view"><a href="https://www.cnblogs.com/lxfweb/p/12831417.html" class="gray">阅读(9)</a></span></div>
</div>
在spiders文件夹下创建并编写myspider.py文件。
import scrapy
from tutorial.items import ArticleInfo
class MySpider(scrapy.Spider):
# 设置name
name = "cnblogs"
# 设定域名
allowed_domains = ["www.cnblogs.com"]
# 填写爬取地址
start_urls = ["https://www.cnblogs.com/"]
# 编写爬取方法
def parse(self, response):
for line in response.xpath('//div[@class="post_item_body"]'):
# 初始化item对象保存爬取的信息
item = ArticleInfo()
# 这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
item['title'] = line.xpath('.//a[@class="titlelnk"]/text()').extract()
item['link'] = line.xpath('.//a[@class="titlelnk"]/@href').extract()
item['author'] = line.xpath('.//div[@class="post_item_foot"]/a/text()').extract()
item['read'] = line.xpath('.//span[@class="article_view"]/a/text()').extract()
yield item
- name:scrapy唯一定位实例的属性,必须唯一
- allowed_domains:允许爬取的域名列表,不设置表示允许爬取所有
- start_urls:起始爬取列表
- parse:回调函数,处理请求并返回处理后的数据和需要跟进的url
4.4 开始爬取
进入tutorial文件夹,执行命令
scrapy crawl cnblogs -o items.json
可以看到部分结果如下:
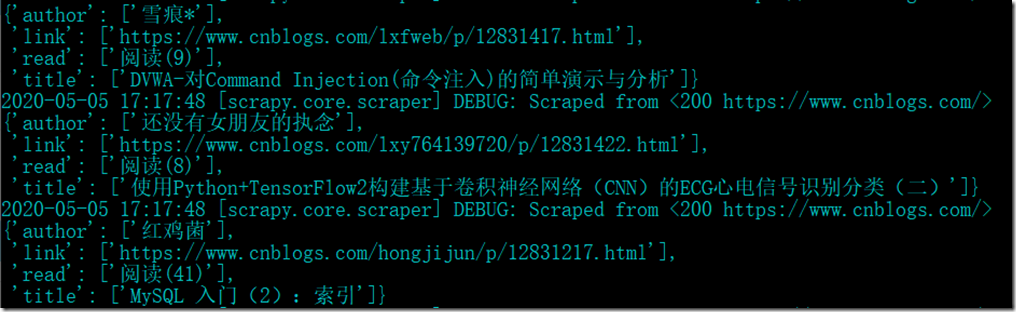
4.5 观察数据
import json
with open('tutorial/items.json', 'r', encoding='utf-8') as f:
rownum = 0
new_list = json.load(f)
for i in new_list:
rownum += 1
print("line{}: title:{}\nlink:{}\nauthor:{}\nread:{}\n".format(rownum,
i['title'][0], i['link'][0], i['author'][0], i['read'][0]))
可以看到输出为:
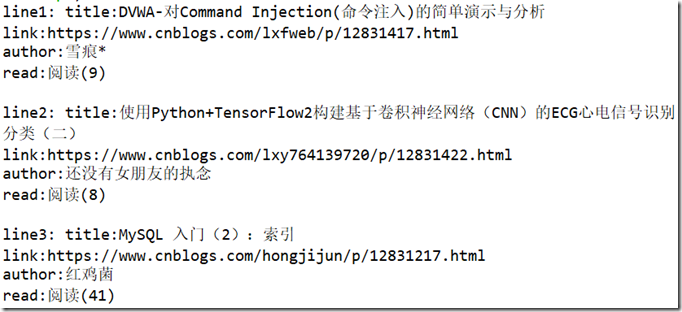
5. XPath
https://www.runoob.com/xpath/xpath-tutorial.html
- XPath 使用路径表达式在 XML 文档中进行导航;
- XPath 包含一个标准函数库;
- XPath 是 XSLT 中的主要元素;
- XPath 是一个 W3C 标准。
5.1 XPath节点
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
节点:
<bookstore> (文档节点) <author>J K. Rowling</author> (元素节点) lang="en" (属性节点)
节点关系:
- 父(Parent): 每个元素以及属性都有一个父。在下面的例子中,book 元素是 title、author、year 以及 price 元素的父;
- 子(Children): 元素节点可有零个、一个或多个子。在下面的例子中,title、author、year 以及 price 元素都是 book 元素的子;
- 同胞(Sibling): 拥有相同的父的节点。在下面的例子中,title、author、year 以及 price 元素都是同胞;
- 先辈(Ancestor): 某节点的父、父的父,等等。在下面的例子中,title 元素的先辈是 book 元素和 bookstore 元素:
- 后代(Descendant): 某个节点的子,子的子,等等。在下面的例子中,bookstore 的后代是 book、title、author、year 以及 price 元素。
5.2 XPath语法
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
<?xml version="1.0" encoding="UTF-8"?> <bookstore> <book> <title lang="eng">Harry Potter</title> <price>29.99</price> </book> <book> <title lang="eng">Learning XML</title> <price>39.95</price> </book> </bookstore>
1. 选取节点
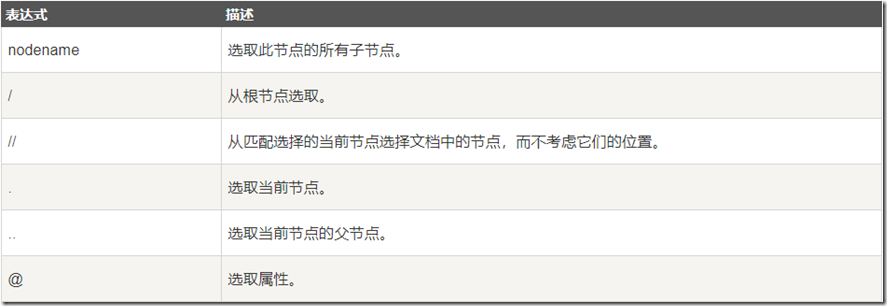
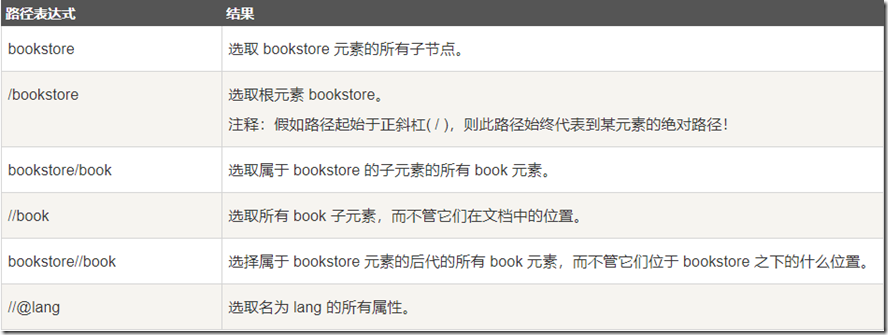
2. 谓语
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
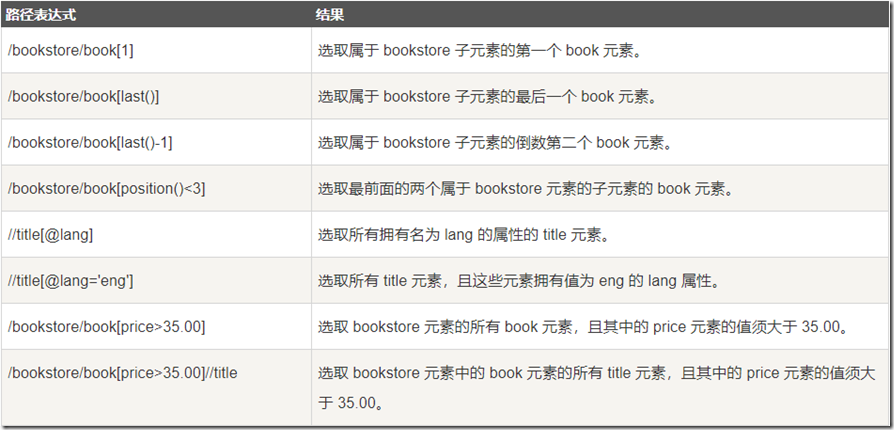
3. 未知节点
XPath 通配符可用来选取未知的 XML 元素。


4. 若干路径
通过在路径表达式中使用"|"运算符,您可以选取若干个路径。

5.3 XPath轴(Axes)
轴可定义相对于当前节点的节点集。
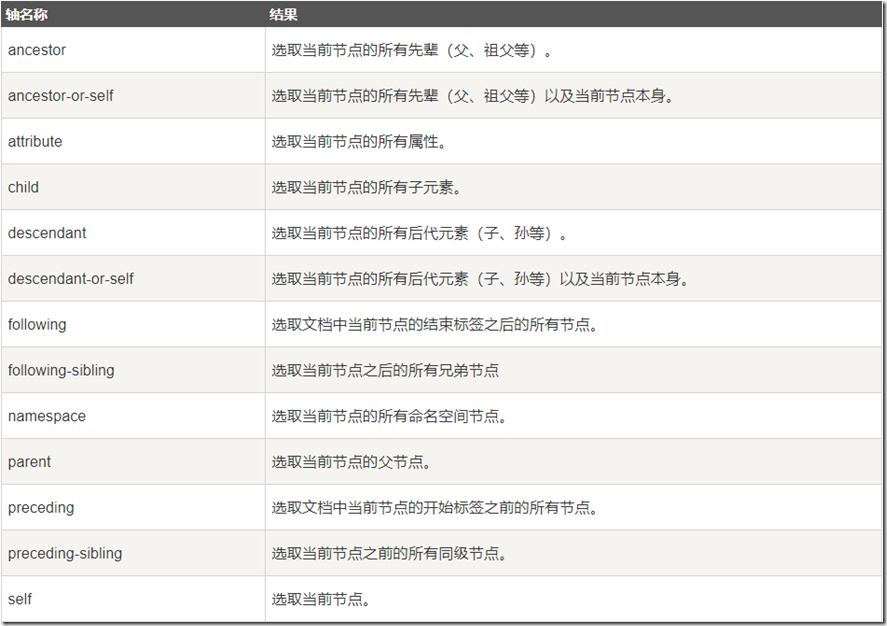
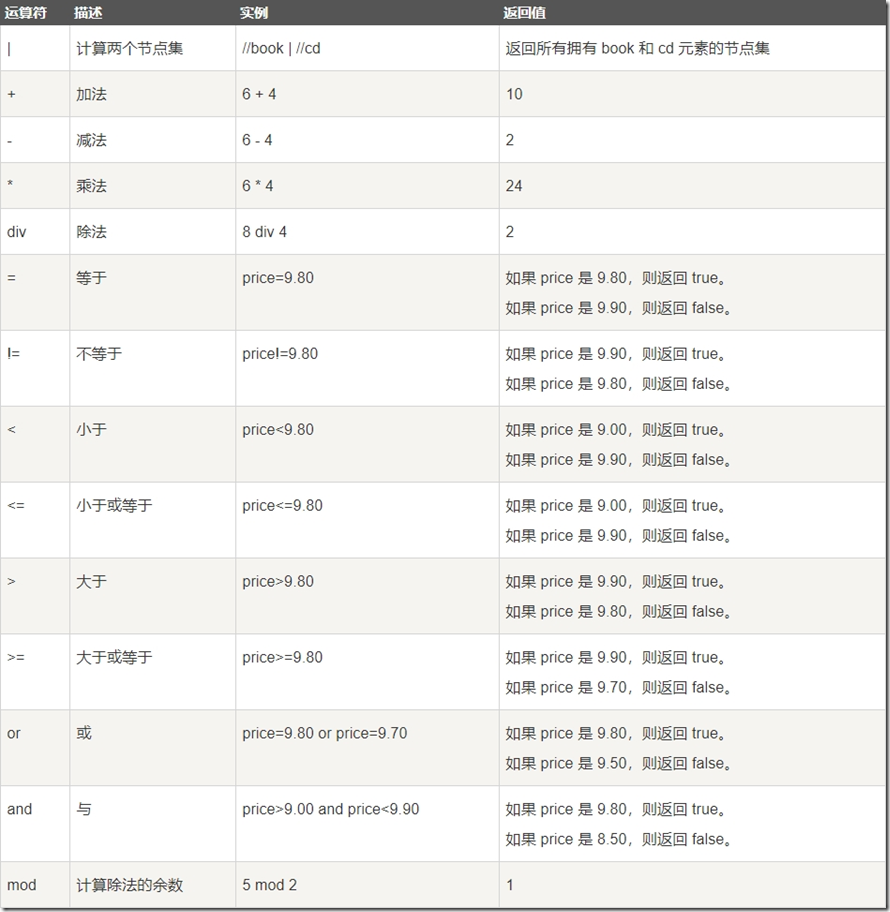
5.4 XPath运算符
XPath 表达式可返回节点集、字符串、逻辑值以及数字。
Python网络数据采集- 创建爬虫的更多相关文章
- 学习爬虫:《Python网络数据采集》中英文PDF+代码
适合爬虫入门的书籍<Python网络数据采集>,采用简洁强大的Python语言,介绍了网络数据采集,并为采集新式网络中的各种数据类型提供了全面的指导.第一部分重点介绍网络数据采集的基本原理 ...
- 笔记之Python网络数据采集
笔记之Python网络数据采集 非原创即采集 一念清净, 烈焰成池, 一念觉醒, 方登彼岸 网络数据采集, 无非就是写一个自动化程序向网络服务器请求数据, 再对数据进行解析, 提取需要的信息 通常, ...
- Python网络数据采集PDF
Python网络数据采集(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/16c4GjoAL_uKzdGPjG47S4Q 提取码:febb 复制这段内容后打开百度网盘手 ...
- [python] 网络数据采集 操作清单 BeautifulSoup、Selenium、Tesseract、CSV等
Python网络数据采集操作清单 BeautifulSoup.Selenium.Tesseract.CSV等 Python网络数据采集操作清单 BeautifulSoup.Selenium.Tesse ...
- Python网络数据采集PDF高清完整版免费下载|百度云盘
百度云盘:Python网络数据采集PDF高清完整版免费下载 提取码:1vc5 内容简介 本书采用简洁强大的Python语言,介绍了网络数据采集,并为采集新式网络中的各种数据类型提供了全面的指导.第 ...
- Python网络数据采集7-单元测试与Selenium自动化测试
Python网络数据采集7-单元测试与Selenium自动化测试 单元测试 Python中使用内置库unittest可完成单元测试.只要继承unittest.TestCase类,就可以实现下面的功能. ...
- Python网络数据采集6-隐含输入字段
Python网络数据采集6-隐含输入字段 selenium的get_cookies可以轻松获取所有cookie. from pprint import pprint from selenium imp ...
- Python网络数据采集4-POST提交与Cookie的处理
Python网络数据采集4-POST提交与Cookie的处理 POST提交 之前访问页面都是用的get提交方式,有些网页需要登录才能访问,此时需要提交参数.虽然在一些网页,get方式也能提交参.比如h ...
- Python网络数据采集3-数据存到CSV以及MySql
Python网络数据采集3-数据存到CSV以及MySql 先热热身,下载某个页面的所有图片. import requests from bs4 import BeautifulSoup headers ...
随机推荐
- "格式化的文本"组件:<span> —— 快应用原生组件
 `<template> <div class="container"> <text><span class="success ...
- Erlang语言之简述及安装
1. 简述 Erlang在1991年由爱立信公司向用户推出了第一个版本,经过不断的改进完善和发展,在1996年爱立信又为所有的Erlang用户提供了一个非常实用且稳定的OTP软件库并在1998年发布了 ...
- leetcode c++做题思路和题解(5)——堆的例题和总结
堆和优先队列 堆的简介, 是一种二叉树, 有最大堆和最小堆miniheap. 通常用于构建优先队列. 0. 目录 数据流中的第K大元素 1. 数据流中的第K大元素 数据流中的第K大元素 复杂度为log ...
- replace into 影响行数
replace into 影响行数,谈起影响行数,先理解replace into 原理:其是先到表里通过一定规则(单主键或复合主键或唯一索引)找到记录,并且删除,然后在insert into 记录,即 ...
- break与continue用法注意事项
break 中断循环执行,跳出循环 注意,break只能中断自己所在的循环,一般用在内层循环,但是不能中断外层循环中的代码. continue 跳到循环的下一轮继续执行,结束自己所在循环体代码,继续自 ...
- E - Roaming Atcoder
题解:https://blog.csdn.net/qq_40655981/article/details/104459253 题目大意:n个房间,,每个房间都有一个人,一共k天,在一天,一个人可以到任 ...
- C - Mind Control CodeForces - 1291C
菜到家了,题意都读不懂. 题目大意: 总共有n个人和n个数字 n个人拍成一队,n个数字也是有顺序的 你排在第m个位置 按照顺序的每个人可以拿走这个序列中的第一个数字或者最后一个数字 你可以在所有人操作 ...
- 使用GML的八方向自动寻路
使用GML的八方向自动寻路 本教程适合无基础人员使用. 提示 本教程中仅使用了最简单的方法,并且有一些错误和不规范之处.请谅解一下,在评论区提出,我会修改.古人曰"教学相长",希望 ...
- 3. JS生成32位随机数
function randomWord ( randomFlag,min,max ) { var str = " ", range = min, arr = ['0','1','2 ...
- [转载]绕过CDN查找真实IP方法总结
前言 类似备忘录形式记录一下,这里结合了几篇绕过CDN寻找真实IP的文章,总结一下绕过CDN查找真实的IP的方法 介绍 CDN的全称是Content Delivery Network,即内容分发网络. ...