NLP入门之语音模型原理

这一篇文章其实是参考了很多篇文章之后写出的一篇对于语言模型的一篇科普文,目的是希望大家可以对于语言模型有着更好地理解,从而在接下来的NLP学习中可以更顺利的学习.
1:传统的语音识别方法:
这里我们讲解一下是如何将声音变成文字,如果有兴趣的同学,我们可以深入的研究.
首先我们知道声音其实是一种波,常见的MP3等都是压缩的格式,必须要转化成非压缩的纯波形的文件来处理,下面以WAV的波形文件来示例:
在进行语音识别之前,有的需要把首尾段的静音进行切除,进行强制对齐,以此来降低对于后续步骤的干扰,整个静音的切除技术一般称为VAD,需要用到对于信号处理的一些技术.
如果要对于声音进行分析,就需要对于声音进行分帧,也就是把声音切成一小块一小块,每一小块称为一帧,分帧并不是简单地切开,而是使用的移动窗函数来实现的,并且帧和帧之间一般是有交叠的
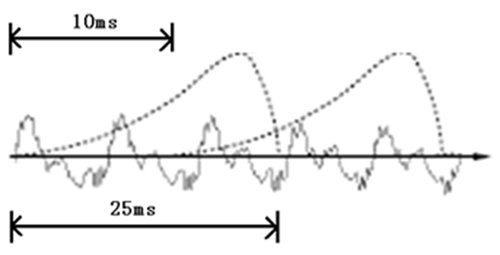
就像上图这样
分帧之后,语音就变成了很多个小段,但是波形在时域上是没有什么描述能力的,因此就必须要将波形进行变换,常见的一种变换方法就是提取MFCC特征,然后根据人耳的生理特性,把每一帧波变成一个多维度向量,这个向量里是包含了这块语音的内容信息,这个过程叫做声学特征的提取,但是实际方法有很多,基本类似.
至此,声音就成了一个12行(假设声学特征是12维)、N列的一个矩阵,称之为观察序列,这里N为总帧数。观察序列如下图所示,图中,每一帧都用一个12维的向量表示,色块的颜色深浅表示向量值的大小。
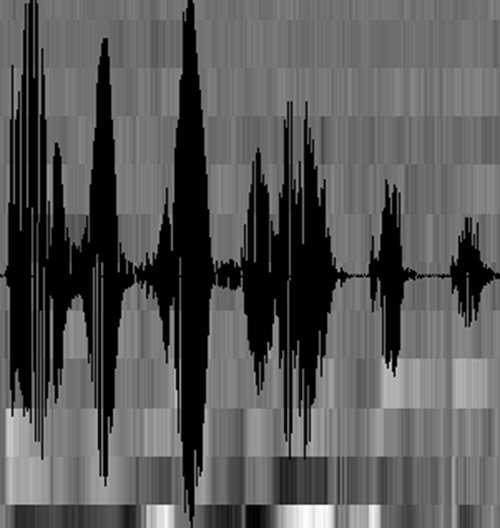
接下来就要介绍怎样把这个矩阵变成文本了。首先要介绍两个概念:
1:音素:
单词的发音由音素构成。对英语,一种常用的音素集是卡内基梅隆大学的一套由39个音素构成的音素集,参见The CMU Pronouncing Dictionary。汉语一般直接用全部声母和韵母作为音素集,另外汉语识别还分有调无调,不详述。
1. 状态:这里理解成比音素更细致的语音单位就行啦。通常把一个音素划分成3个状态。
语音识别是怎么工作的呢?实际上一点都不神秘,无非是:
把帧识别成状态(难点)。
把状态组合成音素。
把音素组合成单词。
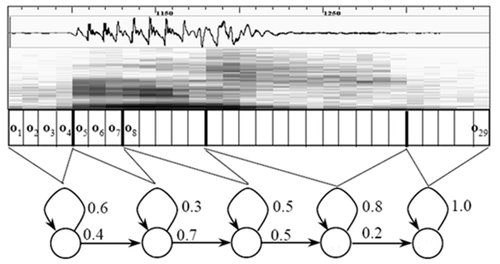
如下图所示:
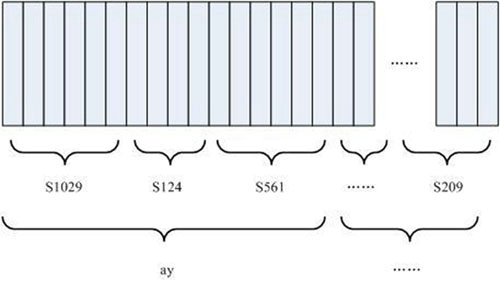
图中,每个小竖条代表一帧,若干帧语音对应一个状态,每三个状态组合成一个音素,若干个音素组合成一个单词。也就是说,只要知道每帧语音对应哪个状态了,语音识别的结果也就出来了。
那每帧音素对应哪个状态呢?有个容易想到的办法,看某帧对应哪个状态的概率最大,那这帧就属于哪个状态。比如下面的示意图,这帧在状态S3上的条件概率最大,因此就猜这帧属于状态S3。
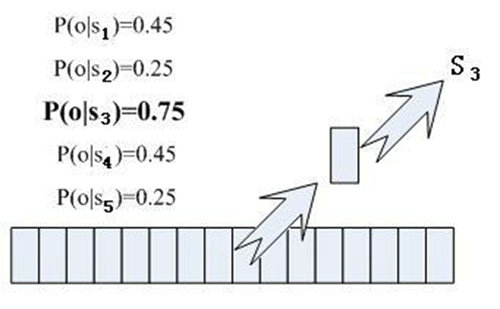
那这些用到的概率从哪里读取呢?有个叫“声学模型”的东西,里面存了一大堆参数,通过这些参数,就可以知道帧和状态对应的概率。获取这一大堆参数的方法叫做“训练”,需要使用巨大数量的语音数据,训练的方法比较繁琐,这里不讲。
但这样做有一个问题:每一帧都会得到一个状态号,最后整个语音就会得到一堆乱七八糟的状态号。假设语音有1000帧,每帧对应1个状态,每3个状态组合成一个音素,那么大概会组合成300个音素,但这段语音其实根本没有这么多音素。如果真这么做,得到的状态号可能根本无法组合成音素。实际上,相邻帧的状态应该大多数都是相同的才合理,因为每帧很短。
解决这个问题的常用方法就是使用隐马尔可夫模型(Hidden Markov Model,HMM)。这东西听起来好像很高深的样子,实际上用起来很简单: 第一步,构建一个状态网络。 第二步,从状态网络中寻找与声音最匹配的路径。
这样就把结果限制在预先设定的网络中,避免了刚才说到的问题,当然也带来一个局限,比如你设定的网络里只包含了“今天晴天”和“今天下雨”两个句子的状态路径,那么不管说些什么,识别出的结果必然是这两个句子中的一句。
那如果想识别任意文本呢?把这个网络搭得足够大,包含任意文本的路径就可以了。但这个网络越大,想要达到比较好的识别准确率就越难。所以要根据实际任务的需求,合理选择网络大小和结构。
搭建状态网络,是由单词级网络展开成音素网络,再展开成状态网络。语音识别过程其实就是在状态网络中搜索一条最佳路径,语音对应这条路径的概率最大,这称之为“解码”。路径搜索的算法是一种动态规划剪枝的算法,称之为Viterbi算法,用于寻找全局最优路径。
这里所说的累积概率,由三部分构成,分别是:
观察概率:每帧和每个状态对应的概率
转移概率:每个状态转移到自身或转移到下个状态的概率
语言概率:根据语言统计规律得到的概率
其中,前两种概率从声学模型中获取,最后一种概率从语言模型中获取。语言模型是使用大量的文本训练出来的,可以利用某门语言本身的统计规律来帮助提升识别正确率。语言模型很重要,如果不使用语言模型,当状态网络较大时,识别出的结果基本是一团乱麻。
这样基本上语音识别过程就完成了。
2:端到端的模型
现阶段深度学习在模式识别领域取得了飞速的发展,特别是在语音和图像的领域,因为深度学习的特性,在语音识别领域中,基于深度学习的声学模型现如今已经取代了传统的混合高斯模型GMM对于状态的输出进行建模,因此在普通的深度神经网络的基础之上,基于长短记忆网络的递归神经网络对语音序列的强大的建模能力进一步提高了语音识别的性能,但是这些方法依旧包含着最基础的隐马尔可夫HMM的基本结构,因此依旧会出现隐马尔科夫模型的训练和解码的复杂度问题.
基于深度学习的声学模型训练过程必须是由传统的混合高斯模型开始的,然后对训练数据集合进行强制的对齐,然后进行切分得到不同的声学特征,其实传统的方式并不利于对于整句话的全局优化,并且这个方法也需要额外的语音学和语言学的知识,比如发音词典,决策树单元绑定建模等等,搭建系统的门槛较高等问题.
一些科学家针对传统的声学建模的缺点,提出了链接时序分类技术,这个技术是将语音识别转换为序列的转换问题,这样一来就可以抛弃了传统的基于HMM的语音识别系统的一系列假设,简化了系统的搭建流程,从而可以进一步提出了端到端的语音识别系统,减少了语音对于发音词典的要求.
端到端的系统是由LSTM的声学建模方法和CTC的目标函数组成的,在CTC的准则下,LSTM可以在训练过程中自动的学习声学的特征和标注序列的对应关系,也就不需要再进行强制的对数据集合进行对齐的过程了.并且可以根据各种语种的特点,端到端识别直接在字或者单词上进行建模,但是因为端到端的识别可能是意味着发展的趋势,但是因为完全崛弃了语音学的知识,现如今在识别性能上仍然和传统的基于深度学习的建模方法有着一定的差距,不过我最近在看的一篇论文中,基于端到端的藏语识别已经达到甚至超过了现有的通用算法.
就拿藏语举例,藏语是一种我国的少数民族语言,但是因为藏族人口较少,相比起对于英文,汉语这样的大语种来说,存在着语音数据收集困难的问题,在上一篇文章中我们可以知道,自然语言处理的最重要的需求就是语料,如果有很好的语料库自然会事半功倍,这样就导致了藏语的语音识别研究工作起步较晚,并且因为藏语的语言学知识的匮乏进一步阻碍了藏语语音识别的研究的进展,在我国,藏语是属于一种单音节字的语言,在端到端的语音过程中,藏语是建模起来非常简单的一种语言,但是作为一种少数民族语言,语料不足会在训练过程中出现严重的稀疏性问题,并且很多人在研究现有的藏语词典中发现,如果完全崛弃现有的藏语发音词典,完全不利用这样的先验知识,这样其实也是不利于技术的发现的,因此现阶段下,采用CTC和语言知识结合的方式来建模,可以解决在资源受限的情况下声学的建模问题,使得基于端到端的声学模型方法的识别率超过当下基于隐马尔科夫的双向长短时记忆模型.
在基于CD-DNN-HMM架构的语音识别声学模型中,训练DNN通常需要帧对齐标签。在GMM中,这个对齐操作是通过EM算法不断迭代完成的,而训练DNN时需要用GMM进行对齐则显得非常别扭。因此一种不需要事先进行帧对齐的方法呼之欲出。此外对于HMM假设一直受到诟病,等到RNN出现之后,使用RNN来对时序关系进行描述来取代HMM成为当时的热潮。随着神经网络优化技术的发展和GPU计算能力的不断提升,最终使用RNN和CTC来进行建模实现了end-to-end语音识别的声学模型。CTC的全称是Connectionist Temporal Classification,中文翻译大概是连接时序分类。它要达到的目标就是直接将语音和相应的文字对应起来,实现时序问题的分类。
这里仍然可以描述为EM的思想:
E-step:使用BPTT算法优化神经网络参数;
M-step:使用神经网络的输出,重新寻找最有的对齐关系。
CTC可以看成是一个分类方法,甚至可以看作是目标函数。在构建end-to-end声学模型的过程中,CTC起到了很好的自动对齐的效果。同传统的基于CD-DNN-HMM的方法相比,对齐效果引用文章[Alex Graves,2006]中的图是这样的效果:
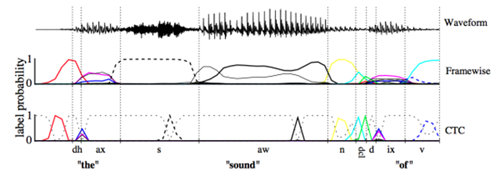
这幅图可以理解:基于帧对齐的方法强制要求切分好的帧对齐到对应的标签上去,而CTC则可以时帧的输出为空,只有少数帧对齐到对应的输出标签上。这样带来的差别就是帧对齐的方法即使输出是正确的,但是在边界区域的切分也很难准确,从而给DNN的训练引入错误。c) End-to-end模型由于神经网络强大的建模能力,End-to-end的输出标签也不再需要像传统架构一样的进行细分。例如对于中文,输出不再需要进行细分为状态、音素或者声韵母,直接将汉字作为输出即可;对于英文,考虑到英文单词的数量庞大,可以使用字母作为输出标签。从这一点出发,我们可以认为神经网络将声学符号到字符串的映射关系也一并建模学习了出来,这部分是在传统的框架中时词典所应承担的任务。针对这个模块,传统框架中有一个专门的建模单元叫做G2P(grapheme-to-phoneme),来处理集外词(out of vocabulary,OOV)。在end-to-end的声学模型中,可以没有词典,没有OOV,也没有G2P。这些全都被建模在一个神经网络中。另外,在传统的框架结构中,语音需要分帧,加窗,提取特征,包括MFCC、PLP等等。在基于神经网络的声学模型中,通常使用更裸的Fbank特征。在End-to-en的识别中,使用更简单的特征比如FFT点,也是常见的做法。或许在不久的将来,语音的采样点也可以作为输入,这就是更加彻底的End-to-end声学模型。除此之外,End-to-end的声学模型中已经带有了语言模型的信息,它是通过RNN在输出序列上学习得到的。但这个语言模型仍然比较弱,如果外加一个更大数据量的语言模型,解码的效果会更好。因此,End-to-end现在指声学模型部分,等到不需要语言模型的时候,才是完全的end-to-end。3、 语言模型(Language Model, LM)语言模型的作用可以简单理解为消解多音字的问题,在声学模型给出发音序列之后,从候选的文字序列中找出概率最大的字符串序列。
4、 解码传统的语音识别解码都是建立在WFST的基础之上,它是将HMM、词典以及语言模型编译成一个网络。解码就是在这个WFST构造的动态网络空间中,找到最优的输出字符序列。搜索通常使用Viterbi算法,另外为了防止搜索空间爆炸,通常会采用剪枝算法,因此搜索得到的结果可能不是最优结果。在end-to-end的语音识别系统中,最简单的解码方法是beam search。尽管end-to-end的声学模型中已经包含了一个弱语言模型,但是利用额外的语言模型仍然能够提高识别性能,因此将传统的基于WFST的解码方式和Viterbi算法引入到end-to-end的语音识别系统中也是非常自然的。然而由于声学模型中弱语言模型的存在,解码可能不是最优的。文章[yuki Kanda, 2016]提出在解码的时候,需要将这个若语言模型减掉才能得到最优结果。
本文作者:云时之间
来源:51CTO
NLP入门之语音模型原理的更多相关文章
- [NLP] TextCNN模型原理和实现
1. 模型原理 1.1 论文 Yoon Kim在论文(2014 EMNLP) Convolutional Neural Networks for Sentence Classification提出Te ...
- NLP入门(八)使用CRF++实现命名实体识别(NER)
CRF与NER简介 CRF,英文全称为conditional random field, 中文名为条件随机场,是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出随机 ...
- 【第1篇】人工智能(AI)语音测试原理和实践---宣传
前言 本文主要介绍作者关于人工智能(AI)语音测试的各方面知识点和实战技术. 本书共分为9章,第1.2章详细介绍人工智能(AI)语音测试各种知识点和人工智能(AI)语音交互原理:第3.4章介绍人工智 ...
- NLP入门(五)用深度学习实现命名实体识别(NER)
前言 在文章:NLP入门(四)命名实体识别(NER)中,笔者介绍了两个实现命名实体识别的工具--NLTK和Stanford NLP.在本文中,我们将会学习到如何使用深度学习工具来自己一步步地实现N ...
- xgboost入门与实战(原理篇)
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
- 阿里天池 NLP 入门赛 TextCNN 方案代码详细注释和流程讲解
thumbnail: https://image.zhangxiann.com/jung-ho-park-HbnqEhMBpPM-unsplash.jpg toc: true date: 2020/8 ...
- word2vec模型原理与实现
word2vec是Google在2013年开源的一款将词表征为实数值向量的高效工具. gensim包提供了word2vec的python接口. word2vec采用了CBOW(Continuous B ...
- 【转】Select模型原理
Select模型原理利用select函数,判断套接字上是否存在数据,或者能否向一个套接字写入数据.目的是防止应用程序在套接字处于锁定模式时,调用recv(或send)从没有数据的套接字上接收数据,被迫 ...
- Select模型原理
Select模型原理 利用select函数,推断套接字上是否存在数据,或者是否能向一个套接字写入数据.目的是防止应用程序在套接字处于锁定模式时,调用recv(或send)从没有数据的套接字上接收数据, ...
随机推荐
- Visual Studio Code 1.44 解决中文代码显示乱码问题(小白图文教程)
现今主流的计算机中文字符编码方案是:GBK和UTF-8. 不同编码方案使用不同的字符集,GBK字符集在中文字符长度和字符数量上存在绝对优势,但对国外字符并不支持.所以,完全面向国内的程序/网页使用的是 ...
- Flask(python web) 处理表单和Ajax请求
1.处理表单(form) 首先,编一个简单的html登录页面(名字为login.html(根路由jinjia2模板指定)): <html> <head> <meta ch ...
- Deep Dream模型与实现
Deep Dream是谷歌公司在2015年公布的一项有趣的技术.在训练好的卷积神经网络中,只需要设定几个参数,就可以通过这项技术生成一张图像. 本文章的代码和图片都放在我的github上,想实现本文代 ...
- 超详细Go语言源码目录说明
开源项目「go home」聚焦Go语言技术栈与面试题,以协助Gopher登上更大的舞台,欢迎go home~ 导读 学习Go语言源码的第一步就是了解先了解它的目录结构,你对它的源码目录了解多少呢?今天 ...
- Vue 核心最基本的功能
~~~<html><head> <script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"& ...
- 字典树&&AC自动机---看完大概应该懂了吧。。。。
目录 字典树 AC自动机 字典树 又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种.典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计 ...
- cmake添加版本号
vVersion.cmake文件内容如下: #vversion.cmake #vDateTime string(TIMESTAMP vDateTime "%Y%m%d-%H%M%S" ...
- File类心得
File类心得 在程序中设置路径时会有系统依赖的问题,java.io.File类提供一个抽象的.与系统独立的路径表示.给它一个路径字符串,它会将其转换为与系统无关的抽象路径表示,这个路径可以指向一个文 ...
- AJ学IOS(15)UI之曾经大热的打砖块小游戏
AJ分享,必须精品 先看效果图 代码 // ViewController.m // 打砖块 // // Created by liufan on 13-8-17. // Copyright (c) 2 ...
- 使用Jmeter测试java请求
1.性能测试过程中,有时候开发想对JAVA代码进行性能测试,Jmeter是支持对Java请求进行性能测试,但是需要自己开发.打包好要测试的代码,就能在Java请求中对该java方法进行性能测试2.本文 ...