理解java容器底层原理--手动实现HashMap
HashMap结构
HashMap的底层是数组+链表,百度百科找了张图:

先写个链表节点的类
package com.xzlf.collection2;
public class Node {
int hash;
Object key;
Object value;
Node next;
}
自定义一个HashMap,实现了put方法增加键值对,并解决了键重复的时候覆盖相应的节点
package com.xzlf.collection2;
/**
* 自定义一个hashMap
* 实现了put方法增加键值对,并解决了键重复的时候覆盖相应的节点
* @author xzlf
*
*/
public class MyHashMap {
private Node[] table;//位桶 .bucket array
private int size;//存放键值对的个数
public MyHashMap() {
table = new Node[16];//长度一般定义成2的整数次幂
}
public void put(Object key, Object value) {
Node newNode = new Node();
newNode.hash = myHash(key.hashCode(), table.length);
newNode.key = key;
newNode.value = value;
Node tmp = table[newNode.hash];
Node iterLast = null;//正在遍历的最后一个元素
boolean keyRepeat = false;
if(tmp == null) {
//此处数组元素为空,则直接将新节点放进去
table[newNode.hash] = newNode;
}else {
//此处数组元素不为空。则遍历对应链表。。
while(tmp != null) {
// 判断是否有重复的键
if(key.equals(tmp.key)) {
keyRepeat = true;
// 键重复,直接覆盖value其他的值(hash,key,next)保持不变。
tmp.value = value;
break;
}else {
iterLast = tmp;
tmp = tmp.next;
}
}
if(!keyRepeat) {
//key没有重复的情况,则添加到链表最后。
iterLast.next = newNode;
}
}
}
public static int myHash(int v, int length) {
// System.out.println(v&(length - 1));
return v&(length - 1);// 位运算把元素散列到各位位置
}
我们在写个main() 方法测试一下:
目前还没有重写toString() 方法,我们先把计算位置的方法加一条打印语句,然后在最后的输出语句加上断点,用debug模式查看
public static int myHash(int v, int length) {
System.out.println(v&(length - 1));
return v&(length - 1);// 位运算把元素散列到各位位置
}
public static void main(String[] args) {
MyHashMap map = new MyHashMap();
map.put(10, "aa");
map.put(20, "bb");
map.put(30, "cc");
System.out.println(map);
}
debug模式运行代码,控制台输出了元素存放位置:

我们看下10 4 14 位置对应的值是否对应上 aa bb cc

debug模式中可以看到添加的变量,说明数据添加进去了
我们还要测试下键重复和桶位在同一位置情况
先用以下代码,找出在存放位置为索引8(可以自己定义)的键:
for (int i = 10; i < 100; i++) {
if (myHash(i,16) == 8) {
System.out.println(i + "---" + myHash(i, 16));//24, 40,56,72,88
}
}
找出来是24, 40,56,72,88:
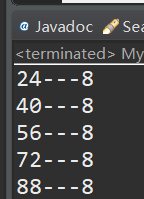
用以下代码测试键重复,和存放位置一直情况:
public static void main(String[] args) {
MyHashMap map = new MyHashMap();
map.put(10, "aa");
map.put(20, "bb");
map.put(30, "cc");
map.put(10, "ssss");
map.put(24, "dd");
map.put(56, "ee");
map.put(72, "ff");
map.put(56, "java");
System.out.println(map);
}
还是用debug模式测试:

8和10的位置都是预期效果。接下来我们可以去重写toString方法,以方便我们查看结果。
版本二:重写toString()
package com.xzlf.collection2;
/**
* 自定义一个hashMap
* 实现toString方法,方便查看Map中的键值对信息
* @author xzlf
*
*/
public class MyHashMap2 {
private Node[] table;//位桶 .bucket array
private int size;//存放键值对的个数
public MyHashMap2() {
table = new Node[16];//长度一般定义成2的整数次幂
}
public void put(Object key, Object value) {
Node newNode = new Node();
newNode.hash = myHash(key.hashCode(), table.length);
newNode.key = key;
newNode.value = value;
Node tmp = table[newNode.hash];
Node iterLast = null;//正在遍历的最后一个元素
boolean keyRepeat = false;
if(tmp == null) {
//此处数组元素为空,则直接将新节点放进去
table[newNode.hash] = newNode;
}else {
//此处数组元素不为空。则遍历对应链表。。
while(tmp != null) {
// 判断是否有重复的键
if(key.equals(tmp.key)) {
keyRepeat = true;
// 键重复,直接覆盖value其他的值(hash,key,next)保持不变。
tmp.value = value;
break;
}else {
iterLast = tmp;
tmp = tmp.next;
}
}
if(!keyRepeat) {
//key没有重复的情况,则添加到链表最后。
iterLast.next = newNode;
}
}
}
public static int myHash(int v, int length) {
// System.out.println(v&(length - 1));
return v&(length - 1);// 位运算把元素散列到各位位置
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder("{");
// 遍历位桶数组
for (int i = 0; i < table.length; i++) {
Node tmp = table[i];
//遍历链表
while(tmp != null) {
sb.append(tmp.key + ":" + tmp.value + ",");
tmp = tmp.next;
}
}
sb.setCharAt(sb.length() - 1, '}');
return sb.toString();
}
public static void main(String[] args) {
MyHashMap2 map = new MyHashMap2();
map.put(10, "aa");
map.put(20, "bb");
map.put(30, "cc");
map.put(10, "ssss");
map.put(24, "dd");
map.put(56, "ee");
map.put(72, "ff");
map.put(56, "java");
System.out.println(map);
}
}
运行测试:
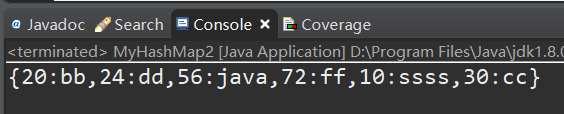
没有问题,继续添加get() 方法。
版本三:添加get方法
package com.xzlf.collection2;
/**
* 自定义一个hashMap
* 添加get方法
* @author xzlf
*
*/
public class MyHashMap3 {
private Node[] table;//位桶 .bucket array
private int size;//存放键值对的个数
public MyHashMap3() {
table = new Node[16];//长度一般定义成2的整数次幂
}
public void put(Object key, Object value) {
Node newNode = new Node();
newNode.hash = myHash(key.hashCode(), table.length);
newNode.key = key;
newNode.value = value;
Node tmp = table[newNode.hash];
Node iterLast = null;//正在遍历的最后一个元素
boolean keyRepeat = false;
if(tmp == null) {
//此处数组元素为空,则直接将新节点放进去
table[newNode.hash] = newNode;
}else {
//此处数组元素不为空。则遍历对应链表。。
while(tmp != null) {
// 判断是否有重复的键
if(key.equals(tmp.key)) {
keyRepeat = true;
// 键重复,直接覆盖value其他的值(hash,key,next)保持不变。
tmp.value = value;
break;
}else {
iterLast = tmp;
tmp = tmp.next;
}
}
if(!keyRepeat) {
//key没有重复的情况,则添加到链表最后。
iterLast.next = newNode;
}
}
}
public static int myHash(int v, int length) {
// System.out.println(v&(length - 1));
return v&(length - 1);// 位运算把元素散列到各位位置
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder("{");
// 遍历位桶数组
for (int i = 0; i < table.length; i++) {
Node tmp = table[i];
//遍历链表
while(tmp != null) {
sb.append(tmp.key + ":" + tmp.value + ",");
tmp = tmp.next;
}
}
sb.setCharAt(sb.length() - 1, '}');
return sb.toString();
}
public Object get(Object key) {
int hash = myHash(key.hashCode(), table.length);
Object value = null;
Node tmp = table[hash];
while(tmp != null) {
if(key.equals(tmp.key)) {//如果找到了,则返回对应的值
value = tmp.value;
break;
}else {
tmp = tmp.next;
}
}
return value;
}
public static void main(String[] args) {
MyHashMap3 map = new MyHashMap3();
map.put(10, "aa");
map.put(20, "bb");
map.put(30, "cc");
map.put(10, "ssss");
map.put(24, "dd");
map.put(56, "ee");
map.put(72, "ff");
map.put(56, "java");
System.out.println(map);
System.out.println(map.get(10));
System.out.println(map.get(30));
System.out.println(map.get(72));
System.out.println(map.get(78));
}
}
运行测试:

也没问题。
现在已经把hashMap的核心功能get put 实现了。
最后完善一下。
版本四:添加泛型,完善size计数
Node添加泛型:
package com.xzlf.collection2;
public class Node2<K, V> {
int hash;
K key;
V value;
Node2 next;
}
自定义hashmap添加泛型并完善size计数:
package com.xzlf.collection2;
/**
* 自定义一个hashMap
* 增加泛型,修复部分bug
* @author xzlf
*
*/
public class MyHashMap4<K, V> {
private Node2[] table;//位桶 .bucket array
private int size;//存放键值对的个数
public MyHashMap4() {
table = new Node2[16];//长度一般定义成2的整数次幂
}
public void put(K key, V value) {
Node2 newNode2 = new Node2();
newNode2.hash = myHash(key.hashCode(), table.length);
newNode2.key = key;
newNode2.value = value;
Node2 tmp = table[newNode2.hash];
Node2 iterLast = null;//正在遍历的最后一个元素
boolean keyRepeat = false;
if(tmp == null) {
//此处数组元素为空,则直接将新节点放进去
table[newNode2.hash] = newNode2;
size++;
}else {
//此处数组元素不为空。则遍历对应链表。。
while(tmp != null) {
// 判断是否有重复的键
if(key.equals(tmp.key)) {
keyRepeat = true;
// 键重复,直接覆盖value其他的值(hash,key,next)保持不变。
tmp.value = value;
break;
}else {
iterLast = tmp;
tmp = tmp.next;
}
}
if(!keyRepeat) {
//key没有重复的情况,则添加到链表最后。
iterLast.next = newNode2;
size++;
}
}
}
public static int myHash(int v, int length) {
// System.out.println(v&(length - 1));
return v&(length - 1);// 位运算把元素散列到各位位置
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder("{");
// 遍历位桶数组
for (int i = 0; i < table.length; i++) {
Node2 tmp = table[i];
//遍历链表
while(tmp != null) {
sb.append(tmp.key + ":" + tmp.value + ",");
tmp = tmp.next;
}
}
sb.setCharAt(sb.length() - 1, '}');
return sb.toString();
}
public V get(K key) {
int hash = myHash(key.hashCode(), table.length);
V value = null;
Node2 tmp = table[hash];
while(tmp != null) {
if(key.equals(tmp.key)) {//如果找到了,则返回对应的值
value = (V) tmp.value;
break;
}else {
tmp = tmp.next;
}
}
return value;
}
public static void main(String[] args) {
MyHashMap4<Integer, String> map = new MyHashMap4<>();
map.put(10, "aa");
map.put(20, "bb");
map.put(30, "cc");
map.put(10, "ssss");
map.put(24, "dd");
map.put(56, "ee");
map.put(72, "ff");
map.put(56, "java");
System.out.println(map);
System.out.println(map.get(10));
System.out.println(map.get(30));
System.out.println(map.get(72));
System.out.println(map.get(78));
}
}
运行测试:

泛型完毕。
至于扩容和remove方法可以参考我的另外两篇:
理解java容器底层原理–手动实现ArryList
https://mp.csdn.net/console/editor/html/105032218
和
理解java容器底层原理–手动实现LinkedList
理解java容器底层原理--手动实现HashMap的更多相关文章
- 理解java容器底层原理--手动实现HashSet
HashSet的底层其实就是HashMap,换句话说HashSet就是简化版的HashMap. 直接上代码: package com.xzlf.collection2; import java.uti ...
- 理解java容器底层原理--手动实现LinkedList
Node java 中的 LIinkedList 的数据结构是链表,而链表中每一个元素是节点. 我们先定义一下节点: package com.xzlf.collection; public class ...
- 理解java容器底层原理--手动实现ArrayList
为了照顾初学者,我分几分版本发出来 版本一:基础版本 实现对象创建.元素添加.重新toString() 方法 package com.xzlf.collection; /** * 自定义一个Array ...
- Java面试底层原理
面试发现经常有些重复的面试问题,自己也应该学会记录下来,最好自己能做成笔记,在下一次面的时候说得有条不紊,深入具体,面试官想必也很开心.以下是我个人总结,请参考: HashSet底层原理:(问了大几率 ...
- (前篇:NIO系列 推荐阅读) Java NIO 底层原理
出处: Java NIO 底层原理 目录 1.1. Java IO读写原理 1.1.1. 内核缓冲与进程缓冲区 1.1.2. java IO读写的底层流程 1.2. 四种主要的IO模型 1.3. 同步 ...
- Java 容器 & 泛型:五、HashMap 和 TreeMap的自白
Writer:BYSocket(泥沙砖瓦浆木匠) 微博:BYSocket 豆瓣:BYSocket Java 容器的文章这次应该是最后一篇了:Java 容器 系列. 今天泥瓦匠聊下 Maps. 一.Ma ...
- 10分钟看懂, Java NIO 底层原理
目录 写在前面 1.1. Java IO读写原理 1.1.1. 内核缓冲与进程缓冲区 1.1.2. java IO读写的底层流程 1.2. 四种主要的IO模型 1.3. 同步阻塞IO(Blocking ...
- 深入理解Java容器——HashMap
目录 存储结构 初始化 put resize 树化 get 为什么equals和hashCode要同时重写? 为何HashMap的数组长度一定是2的次幂? 线程安全 参考 存储结构 JDK1.8前是数 ...
- java容器的数据结构-ArrayList,LinkList,HashMap
ArrayList: 初始容量为10,底层实现是一个数组,Object[] elementData 自动扩容机制,当添加一个元素时,数组长度超过了elementData.leng,则会按照1.5倍进行 ...
随机推荐
- WePY的开发环境的安装
2020-03-24 1.安装Node.js 官网:https://nodejs.org/ 两个版本 LTS为稳定的长期支持版本 Current为最新的版本 安装完毕后,cmd下输入 node -v ...
- 自适应线性神经网络Adaline
自适应线性神经网络Adaptive linear network, 是神经网络的入门级别网络. 相对于感知器, 采用了f(z)=z的激活函数,属于连续函数. 代价函数为LMS函数,最小均方算法,Lea ...
- 模块 collections 高级数据类型
collections模块 原文来自cnblog 的 Eva-J Eva-J 介绍了collections模块的常用方法,和演示实例 在 Python cookbook 的第一章中还有一些 更加好玩的 ...
- Redis启动出现creating server tcp listening socket错误
错误如图所示 解决方法 在命令行中运行 redis-cli.exe 127.0.0.1:6379>shutdown not connected>exit 然后重新运行redis-serve ...
- js对象中in和hasOwnProperty()区别
记录学习中容易混淆的一些方法. prop in object prop一个字符串类型或者 symbol 类型的属性名或者数组索引(非symbol类型将会强制转为字符串). objectName检查它( ...
- ML-Agents(六)Tennis
目录 ML-Agents(六)Tennis 一.Tennis介绍 二.环境与训练参数 三.场景基本结构 四.代码分析 环境初始化脚本 Agent脚本 Agent初始化与重置 矢量观测空间 Agent动 ...
- LeetCode | 第180场周赛--5356矩阵中的幸运数
给你一个 m * n 的矩阵,矩阵中的数字 各不相同 .请你按 任意 顺序返回矩阵中的所有幸运数. 幸运数是指矩阵中满足同时下列两个条件的元素: 在同一行的所有元素中最小 在同一列的所有元素中最大 示 ...
- Java反射中getDeclaredField和getField的区别
getDeclaredField是可以获取一个类的所有字段. getField只能获取类的public 字段. public Field getDeclaredField(String name) t ...
- 通过operator函数将字符串转换回运算符
需求 由于某些需要,将一些运算符做了列表,以便后续的程序判断传入的字符串中是否包含该列表中的某一个运算符,如果包含,就用该运算符做运算. 但该运算符已经转换是字符串了,没有办法做运算符用,经过全网搜索 ...
- Aactivity跳转到Bactivity之后再返回Aactivity的几种操作
一个主界面(主Activity)通过意图跳转至多个不同子Activity上去,当子模块的代码执行完毕后再次返回主页面,将子activity中得到的数据显示在主界面/完成的数据交给主Activity处理 ...