kettle工具的设计模块
大家都知道,每个ETL工具都用不同的名字来区分不同的组成部分。kettle也不例外。
比如,在
Kettle的四大不同环境工具
本博客,是立足于kettle工具的设计模块的概念介绍。
1、转换
转换(transformation)是ETL解决方案中最主要的部分,它处理(抽取、转换、加载各阶段)各种对数据行的操作。转换包括一个或多个步骤(step),如读取文件、过滤输出行、数据清洗或将数据加载到数据库。
转换里的步骤通过跳(hop)来连接,跳定义了一个单向通道,允许数据从一个步骤向另一个步骤流动。在kettle里,数据的单位是行,数据流就是数据行从一个步骤到另一个步骤的移动。数据流也叫作记录流。
转换包括步骤、跳、注释、并行、数据行、数据转换和其他转换。
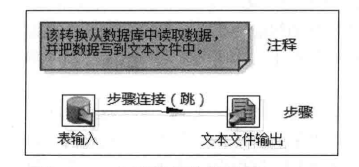
1.1 注释
注释是一个小的文本框,可以放在转换流程图的任何位置,注释的主要目的是使转换文档化。
1.2 步骤
步骤是转换的基本组成部分。它是以图标的方式来图形化展现。
- 步骤需要有一个名字,这个名字在转换范围内唯一。
- 每个步骤都会读、写数据行(唯一例外是“生成记录”步骤,该步骤只写数据)
- 步骤将数据写到与之相连的一个或多个输出跳(outgoing hops),再传送到跳的另一端的步骤。对另一端步骤来说这个跳就是一个输入跳(incoming hops),步骤通过输入跳接收数据
- 大多数的步骤都可以有多个输出跳。一个步骤的数据发送可以被设置为轮流发送和复制发送。轮流发送是将数据行依次发给每一个输出跳(round robin),复制发送是将全部数据行发送给所有输出跳。
- 在运行转换时,一个线程运行一个步骤和步骤的多份拷贝,所有步骤的线程几乎同时运行,数据行连续地流过步骤之间的跳。
1.3 跳
跳(hop)就是步骤之间带箭头的连线,跳定义了步骤之间的数据通路。跳实际上是两个步骤之间的被称为行集(row set)的数据行缓存(行集的大小可以在转换的设置里定义)。当行集满了,向行集写数据的步骤将停止写入,直到行集里又有了空间。当行集空了,从行集读取数据的步骤停止读取,直到行集里又有可读的数据行。
注意: 当创建新跳的时候,需要记住跳在转换里不能循环。因为在转换里每个步骤都依赖前一个步骤获取字段值。
1.4 并行
跳的这种基于行集缓存的规则允许每个步骤都由一个独立的线程运行,这样并发程序最高。这一规则也允许数据以最小消耗内存的数据流的方式来处理。在数据仓库里,我们经常要处理大量数据,所以这种并发低耗内存的方式也是ETL工具的核心需求。
对于Kettle,不可能定义一个执行顺序,不可能也没有必要确定一个起点和终点。因为所有步骤都以并发方式执行:当转换启动后,所有步骤都同时启动,从它们的输入跳中读取数据,并把处理过的数据写到输出跳,直到输入跳里不再有数据,就中止步骤的运行。当所有的步骤都中止了,整个转换就中止了。也就是说,从功能的角度来看,转换也有明确的起点和终点。
1.5 数据行
数据以数据行的形式沿着步骤移动。一个数据行是零到多个字段的集合,字段包括下面几种数据类型。
1.6 数据转换
1.7 其他转换
2、作业
大多数ETL项目都需要完成各种各样的维护工作。例如,当运行中发生错误,要做哪些操作;如何传送文件;验证数据库表是否存在等。而且这些操作要按照一定顺序完成 。因为转换以并行方式执行,就需要一个可以串行执行的作业来处理这些操作。
一个作业包括一个或多个作业项,这些作业项以某种顺序来执行。作业执行顺序由作业项之间的跳(job hop)和每个作业项的执行结果来决定。

3、转换或作业的元数据
。。
4、数据库连接
。。
5、工具
。。
6、资源库
。。
7、虚拟文件系统
。。
kettle工具的设计模块的更多相关文章
- kettle工具的设计原则
不多说,直接上干货! Kettle工具在设计初,就考虑到了一些设计原则.这些原则里借鉴了以前使用过的其他一些ETL工具积累下的经验和教训. 易于开发:作为数据仓库和ETL开发者,你只想把时间用在创建B ...
- 利用代码生成工具Database2Sharp设计数据编辑界面
在Winform程序开发中,界面部分的开发工作量一般是比较大的,特别是表的字段数据比较多的情况下,数据编辑界面所需要的繁琐设计和后台逻辑处理工作量更是直线上升,而且稍不注意,可能很多处理有重复或者错误 ...
- kettle工具二次开发-代码启动JOB
kettle工具是一款优秀的数据同步.数据处理的BI工具,收到了很多人的青睐.kettle软件通过可视化的图标可以让我们很轻易的能完成数据同步.处理的开发工作.但是使用kettle可视化界面在跑JOB ...
- 第八章| 3. MyAQL数据库|Navicat工具与pymysql模块 | 内置功能 | 索引原理
1.Navicat工具与pymysql模块 在生产环境中操作MySQL数据库还是推荐使用命令行工具mysql,但在我们自己开发测试时,可以使用可视化工具Navicat,以图形界面的形式操作MySQL数 ...
- Navicat工具、pymysql模块 sql注入
cls超 Navicat工具.pymysql模块 阅读目录 一 IDE工具介绍 二 pymysql模块 一 IDE工具介绍(Navicat) 生产环境还是推荐使用mysql命令行,但为了方便我们测试, ...
- 基于WebServices简易网络聊天工具的设计与实现
基于WebServices简易网络聊天工具的设计与实现 Copyright 朱向洋 Sunsea ALL Right Reserved 一.项目内容 本次课程实现一个类似QQ的网络聊天软件的功能:服务 ...
- Atitit qzone qq空间博客自动点赞与评论工具的设计与实现
Atitit qzone qq空间博客自动点赞与评论工具的设计与实现 Qzone发送评论的原理 首先,有个a标签, <a class="c_tx3" href="j ...
- kettle工具实现报表导出的初步搭建
1.下载kettle 国外网站:http://kettle.pentaho.org/需要FQ,下载慢 2.下载完成启动(windows)-->spoon.bat 3.进入界面,两个主要的tab页 ...
- 【转】使用kettle工具遇到的问题汇总及解决方案
使用kettle工具遇到的问题汇总及解决方案 转载文章版权声明:本文转载,原作者薄海 ,原文网址链接 http://blog.csdn.net/bohai0409/article/details/ ...
随机推荐
- 在nodejs使用Redis缓存和查询数据及Session持久化(Express)
在nodejs使用Redis缓存和查询数据及Session持久化(Express) https://segmentfault.com/a/1190000002488971
- oracle数据泵备份与还原
完整的常用的一套oracle备份以及还原方案 --在新库中新建数据目录,我没有特别说明在哪执行的语句都可在plsql中执行 CREATE OR REPLACE DIRECTORY dump_dir A ...
- Linux下编译安装Memcache
需要gcc,make,cmake,autoconf,libtool等工具,联网后,yum install -y gcc,make,cmake,autoconf,libtool 编译安装libevent ...
- IP地址转化为数字,charindex ,SUBSTRING
SET NOCOUNT ON; declare @I_PCity table ( IPStart nvarchar(), Area nvarchar(), CityID int, IPID int ) ...
- Authrize特性登录验证
- (转)GPT磁盘与MBR磁盘区别
摘要: Windows 2008磁盘管理器中,在磁盘标签处右击鼠标,随磁盘属性的不同会出现“转换到动态磁盘”,“转换到基本磁盘”“转换成GPT磁盘”,“转换成MBR磁盘”等选项,在此做简单介绍.部 ...
- submile 安装,汉化,插件
/*删除以前配置文件*/ 删除以前版本sublime后,在删除以前版本的配置信息:直接在C盘 查询里面输入 Roming 然后查找里面的 sublime 文件夹,把他给删除掉 ----------- ...
- elasticsearch集群添加节点
最简配置文件: cluster.name: your_cluster_name node.name: your_ip network.host: 0.0.0.0 http.port: your_p ...
- table标签 在谷歌和ie浏览器下不同的表现效果
在项目中有了一个这样的需求: 我需要利用vue的模板语法v-for循环生成tr,这个tr是需要双重循环来确定其个数的, 我的实现: 我在tr外面包了一个template标签, 效果: 谷歌浏览器下实现 ...
- C# 基础复习 一 数据类型
数据类型分为:值类型和引用类型 值类型:byte.short/char.int.long.float.double.decimal.enum.struct 引用类型:string.object.int ...