python第十周:进程、协程、IO多路复用
多进程(multiprocessing):
多进程的使用
multiprocessing是一个使用类似于线程模块的API支持产生进程的包。 多处理包提供本地和远程并发,通过使用子进程而不是线程有效地侧向执行全局解释器锁。 因此,多处理模块允许程序员充分利用给定机器上的多个处理器。
多进程的使用与多线程的使用方法类似
p=multiprocessing.Process(group=None,target=None,name=None,args=0,kwargs=0)(实例化一个进程)
p.start()(启动一个进程)
p.join()(等待一个进程结束)
import multiprocessing
import time,os
def run(i):
print(i,os.getpid())
p_list = []
if __name__ == '__main__':
for i in range(5):
p = multiprocessing.Process(target=run,args=(i,)) #创建一个进程实例
p_list.append(p)
p.start() #启动一个进程
for p in p_list:
p.join() #等待p进程运行结束
print("processing end.....")
#output:
'''
0 9024
3 13172
1 14604
4 8084
2 10400
processing end.....
''
注:每一个进程都是由它的父进程启动的
'''
每一个进程都是由它的父进程启动的
'''
import multiprocessing
import os
def info(title):
print(title)
print("module name:",__name__)
print("parant progress:",os.getppid())
print("process id:",os.getpid())
print("\n\n")
def f(name):
info("\033[31;1mfunction f\033[0m")
print("hello",name)
if __name__ == '__main__':
info("\033[32;31mmain process line\033[0m")
p = multiprocessing.Process(target=f,args=("bob",))
p.start()
p.join()
#output:
'''
main process line
module name: __main__
parant progress: 14312
process id: 11168 #当前主程序的进程是由pycharm启动的 function f
module name: __mp_main__
parant progress: 11168
process id: 9060 #此进程由当前程序的进程启动 hello bob
'''
进程间的通讯
进程间的内存是相互独立的,进程之间如果要想相互通信,可以使用如下方法:
进程Queue(队列)
q = multiprocessing.Queue(maxsize=-1) #实例化一个进程队列
q.put() #将数据放入队列
q.get() #讲数据从队列中取出
def run1(q):
try:
while True:
data = q.get()
print(data)
except Exception as e:
pass
def run2(q):
for i in range(10):
q.put(i)
if __name__ == '__main__':
q = multiprocessing.Queue()
p = multiprocessing.Process(target=run1,args=(q,))
p1 = multiprocessing.Process(target=run2,args=(q,))
p.start()
p1.start() #output:
'''
0
1
2
3
4
5
6
7
8
9
'''
注:再父进程里创建一个queue,然后把queue作为参数传给子进程,这样父进程和子进程就可以通过这个queue实现数据传递。但是:子进程里的queue实际是父进程里的queue的一份拷贝,当子进程把一个数据放入这个queue时,这个数据会被pickle序列化保存在内存的某个区域,然后再反序列化打父进程里的queue中,这样父进程里的queue也有了这个数据
Pipes(管道)
在父进程和子进程之间建立管道,实现数据传递。
Pipe()返回的两个连接对象代表管道的两端。 每个连接对象都有send()和recv()方法(以及其他方法)。如果两个进程(或线程)同时尝试读取或写入管道的同一端,则管道中的数据可能会损坏。 当然,同时使用管道的不同端部的过程不存在损坏的风险。
parent_conn,child_conn = multiprocessing.Pipe(duplex=True) #返回两个连接对象,代表管道两边
parent_conn.send() #发送数据
child_conn.recv() #结束数据
parent_conn,close() #关闭连接
def run(child_conn):
data = child_conn.recv()
print(data)
child_conn.close()
if __name__ == '__main__':
parent_conn,child_conn = multiprocessing.Pipe(duplex=True)
p = multiprocessing.Process(target=run,args=(child_conn,))
p.start()
parent_conn.send("hello world,I am not a girl!")
parent_conn.close()
#output:
'''
hello world,I am not a girl!
'''
Manager()
Manager()返回的管理器对象控制一个进程,该进程保存Python对象并允许其他进程使用代理操作它们。
Manager()返回的管理器将支持类型list,dict,Namespace,Lock,RLock,Semaphore,BoundedSemaphore,Condition,Event,Barrier,Queue,Value和Array。
manager = multiprogressing.Manager() #返回一个管理器对象
manager.dict() #进程字典,可在多个进程之间共享和传递
manager.list() #进程列表,可在多个进程之间共享和传递
def run(l,d,i):
d[i] = os.getpid()
l.append(os.getpid())
print(l)
if __name__ == '__main__':
manager = multiprocessing.Manager()
l = manager.list()
d = manager.list(range(100))
p_list = []
for i in range(10):
p = multiprocessing.Process(target=run,args=(l,d,i))
p_list.append(p)
p.start()
for p in p_list:
p.join()
print("列表:",l)
#output:
'''
[6196]
[6196, 1576]
[6196, 1576, 12968]
[6196, 1576, 12968, 5000]
[6196, 1576, 12968, 5000, 9548]
[6196, 1576, 12968, 5000, 9548, 13212]
[6196, 1576, 12968, 5000, 9548, 13212, 10572]
[6196, 1576, 12968, 5000, 9548, 13212, 10572, 14368]
[6196, 1576, 12968, 5000, 9548, 13212, 10572, 14368, 7580]
[6196, 1576, 12968, 5000, 9548, 13212, 10572, 14368, 7580, 8908]
列表: [6196, 1576, 12968, 5000, 9548, 13212, 10572, 14368, 7580, 8908]
'''
进程锁
目的是在同一时间只有一个进程享有屏幕打印
def run(lock,i):
lock.acquire()
print(i)
lock.release()
if __name__ == '__main__':
lock = multiprocessing.Lock()
for i in range(10):
p = multiprocessing.Process(target=run,args=(lock,i))
p.start()
进程池
进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进程,那么程序就会等待,直到进程池中有可用进程为止。
pool = multiprogressing.Pool(processes=None) #生成一个进程池实例
pool.apply_async(func,args=(),kwds=(),callback=None,error_callback=None)#callback时回调函数,执行完func后,可传入func返回的结果再执行回调函数,这个回调函数实际上是由父进程调用的,进程池中的进程是并发执行的
pool.apply(func,args=(),kwds={}) 进程池中的进程是串行的
pool.close() #关闭进程池,再join()
pool.join() #进程池中的进程执行完毕后再关闭,如果注释掉,那么程序直接关闭
def run(i):
time.sleep(1)
print(os.getpid())
return i def Bar(n):
'''由运行结果可知,回调函数是由父进程调用的'''
print("%s:%s"%(n,os.getppid())) if __name__ == '__main__':
pool = multiprocessing.Pool(processes=5)
for i in range(10):
pool.apply_async(func=run,args=(i,),callback=Bar)
pool.close()
pool.join()
#output:
'''
13532
0:13280
1740
1:13280
2040
3872
2:13280
3:13280
3692
4:13280
13532
5:13280
1740
6:13280
2040
3872
7:13280
3692
8:13280
9:13280
'''
协程:
协程,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程。
协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此:
协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态,换种说法:进入上一次离开时所处逻辑流的位置。
协程的优点:
*无需线程上下文切换的开销
*无需原子操作锁定及同步开销
*方便切换控制流,简化变成模型
*高并发+高扩展+低成本:一个CPU可支持上万的协程,所以很适合高并发处理
协程的缺点:
*无法利用多核资源:协程的本质是单线程,它不能同时将单个CPU的多个核用上,协程需要 和进程配合才能运行再多个CPU上。
*进行阻塞操作,会阻塞掉整个程序。
前面学习的yield其实就是一个协程:
def sing(name):
print("%s要开始唱歌了...."%name)
while True:
song_name = yield
print("%s正在唱[%s]/....."%(name,song_name))
def make_song(name):
singer = sing("周杰伦")
singer.__next__()
print("%s要开始创作歌曲了...."%name)
for i in range(10):
time.sleep(1)
print("%s创作出了一首歌曲:[%s]"%(name,i))
singer.send(i)
make_song("方文山")
#程序执行效果:
'''
周杰伦要开始唱歌了....
方文山要开始创作歌曲了....
方文山创作出了一首歌曲:[0]
周杰伦正在唱[0]/.....
方文山创作出了一首歌曲:[1]
周杰伦正在唱[1]/.....
方文山创作出了一首歌曲:[2]
周杰伦正在唱[2]/.....
方文山创作出了一首歌曲:[3]
周杰伦正在唱[3]/.....
方文山创作出了一首歌曲:[4]
周杰伦正在唱[4]/.....
方文山创作出了一首歌曲:[5]
周杰伦正在唱[5]/.....
方文山创作出了一首歌曲:[6]
周杰伦正在唱[6]/.....
'''
greenlet
greenlet是一个用C实现的协程模块,相比与python自带的yield,它可以使你在任意函数之间随意切换,而不需把这个函数先声明为generator
注:遇到IO操作必须手动切换
gr = greenlet.greenlet(func) #生成一个greenlet协程实例
gr.switch() #启动\切换协程
import greenlet
def test1():
print("My Name Is DJ")
gr2.switch()
print("Hello World!")
def test2():
print("It Is A Good Time")
gr1.switch()
gr1 = greenlet.greenlet(test1)
gr2 = greenlet.greenlet(test2)
gr1.switch()
#output
'''
My Name Is DJ
It Is A Good Time
Hello World!
'''
gevent
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
gevent.joinall(greenlets,timeout=None,raise_error=False,count=None) #将要生成的greenlet放入其中
gevent.spawn(func) #相当于greenlet.greenlet(func) 生成一个协程
gevent.sleep(seconds=0,ref=True) #模拟IO操作
注:遇到IO操作能够自动切换
import gevent def func1():
print("my name is 22222")
gevent.sleep(2)
print("process down.....")
def func2():
print("my name is 11111")
gevent.sleep(1)
print("")
def func3():
print("my name is 44444")
gevent.sleep()
print("")
gevent.joinall([
gevent.spawn(func1),
gevent.spawn(func2),
gevent.spawn(func3),
])
#output:
'''
my name is 22222
my name is 11111
my name is 44444
555555555
333333333
process down.....
'''
用gevent实现一个多并发的socket_server
注:from gevent import monkey
monkey.patch_all() #把当前程序所有的io操作单独做上标记
server端:
import gevent,socket
from gevent import monkey
monkey.patch_all() #自动识别程序中所有的IO操作
def socket_server(port):
'''接收客户端的连接'''
server = socket.socket()
server.bind(("0.0.0.0",port))
server.listen()
while True:
conn,addr = server.accept()
gevent.spawn(handle_request,conn)
def handle_request(conn):
'''与客户端进行通信'''
try:
while True:
pass
except Exception as e:
print(e)
socket_server(9999)
用gevent做一个简单的爬虫
import gevent
from gevent import monkey
from urllib import request
monkey.patch_all() #把当前程序的所有的io操作单独做上标记
#gevent检测不到urlib进行的io操作
def get_url(url):
print("get:%s"%url)
resp = request.urlopen(url)
data = resp.read()
print("%d bytes received from %s"%(len(data),url))
gevent.joinall([
gevent.spawn(get_url,"https://www.python.org/"),
gevent.spawn(get_url,"https://www.bilibili.com/"),
gevent.spawn(get_url,"https://github.com/"),
])
#output:
'''
get:https://www.python.org/
get:https://www.bilibili.com/
get:https://github.com/
70961 bytes received from https://www.bilibili.com/
80700 bytes received from https://github.com/
50008 bytes received from https://www.python.org/
'''
事件驱动与异步IO:
通常,我们在写服务器处理模型的程序时,有以下几种模型:
(1)每收到一个请求,创建一个新的进程,来处理该请求;
(2)每收到一个请求,创建一个新的线程,来处理这个请求;
(3)每收到一个请求,放入一个事件列表,让主进程通过非阻塞IO方式来处理请求;
比较:
(1)要创建新的进程的开销比较大,所以,会导致服务器性能比较差,但实现比较简单。
(2)要涉及线程同步,有可能会面临死锁等问题。
(3)在写应用程序代码时,逻辑比前面两种多要复杂。
所以综合各方面因素,一般普遍认为第(3)种方式时大多数网络服务器采用的方式
事件驱动模型
目前大部分的UI编程都是事件驱动模型,如很多平台UI平台都会提供onClick()事件,这个事件就代表鼠标按下事件。事件驱动模型的大体思路如下:
1.有一个事件队列
2.当有一个事件发生时,就往这个队列里增加一个事件
3.有一个循环,不断从队列取出事件,根据不同的事件,调用不同的函数,如onClick()、onKeyDown()等
4.事件一般都各自保存在各自的处理函数指针,这样,每个消息都有独立的处理函数
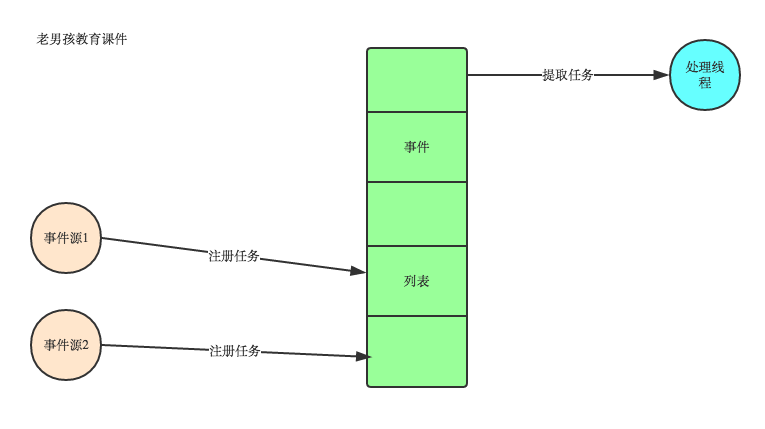
事件驱动编程是一种编程范式,这里程序的执行流由外部事件来决定。它的特点是包含一个事件循环,当外部事件发生时使用回调机制来触发相应的处理。另外两种常见的编程范式是单线程同步以及多线程编程。
在单线程同步模型中,任务按照顺序执行。如果某个任务因为I/O而阻塞,其他所有的任务都必须等待,直到它完成之后它们才能依次执行。这种明确的执行顺序和串行化处理的行为是很容易推断得出的。如果任务之间并没有互相依赖的关系,但仍然需要互相等待的话这就使得程序不必要的降低了运行速度。
在多线程版本中,这3个任务分别在独立的线程中执行。这些线程由操作系统来管理,在多处理器系统上可以并行处理,或者在单处理器系统上交错执行。这使得当某个线程阻塞在某个资源的同时其他线程得以继续执行。与完成类似功能的同步程序相比,这种方式更有效率,但程序员必须写代码来保护共享资源,防止其被多个线程同时访问。多线程程序更加难以推断,因为这类程序不得不通过线程同步机制如锁、可重入函数、线程局部存储或者其他机制来处理线程安全问题,如果实现不当就会导致出现微妙且令人痛不欲生的bug。
在事件驱动版本的程序中,3个任务交错执行,但仍然在一个单独的线程控制中。当处理I/O或者其他昂贵的操作时,注册一个回调到事件循环中,然后当I/O操作完成时继续执行。回调描述了该如何处理某个事件。事件循环轮询所有的事件,当事件到来时将它们分配给等待处理事件的回调函数。这种方式让程序尽可能的得以执行而不需要用到额外的线程。事件驱动型程序比多线程程序更容易推断出行为,因为程序员不需要关心线程安全问题。
当我们面对如下的环境时,事件驱动模型通常是一个好的选择:
- 程序中有许多任务,而且…
- 任务之间高度独立(因此它们不需要互相通信,或者等待彼此)而且…
- 在等待事件到来时,某些任务会阻塞。
当应用程序需要在任务间共享可变的数据时,这也是一个不错的选择,因为这里不需要采用同步处理。
网络应用程序通常都有上述这些特点,这使得它们能够很好的契合事件驱动编程模型。
那么程序如何知道自己注册地IO事件什么时候执行完毕呢?
答:事件驱动模型的原理就是下面要讲的IO多路复用。
Select\Poll\Epoll 异步IO
进程的阻塞
正在执行的进程,由于期待的某些事件未发生,如请求系统资源失败、等待某种操作的完成、新数据尚未到达或无新工作做等,则由系统自动执行阻塞原语(Block),使自己由运行状态变为阻塞状态。可见,进程的阻塞是进程自身的一种主动行为,也因此只有处于运行态的进程(获得CPU),才可能将其转为阻塞状态。当进程进入阻塞状态,是不占用CPU资源的。
缓存 I/O
缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。在 Linux 的缓存 I/O 机制中,操作系统会将 I/O 的数据缓存在文件系统的页缓存( page cache )中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
缓存 I/O 的缺点:
数据在传输过程中需要在应用程序地址空间和内核进行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销是非常大的。
I/O模式
于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,它会经历两个阶段:
1. 等待数据准备 (Waiting for the data to be ready)
2. 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
正式因为这两个阶段,linux系统产生了下面五种网络模式的方案。
- 阻塞 I/O(blocking IO)
- 非阻塞 I/O(nonblocking IO)
- I/O 多路复用( IO multiplexing)
- 信号驱动 I/O( signal driven IO)
- 异步 I/O(asynchronous IO)
阻塞I/O(blocking IO)在Linux中,默认情况下所有的socket都是blocking,一个典型的操作流程大概是这样:
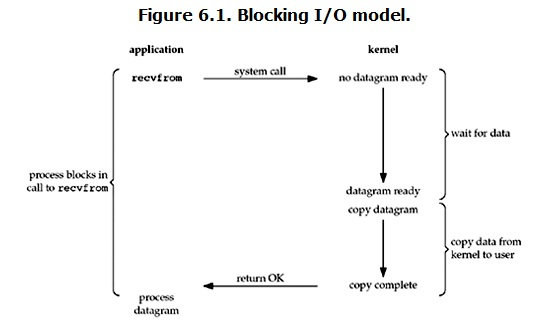
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据(对于网络IO来说,很多时候数据一开始还没有到达。比如,还没有接收一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统的内核缓冲区中是需要一个过程的。而在用户进程这边,整个进程会被阻塞(当然,是进程自己选择的阻塞)。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行两个阶段都被block了。
非阻塞I/O(nonblocking IO)
在Linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程如下:
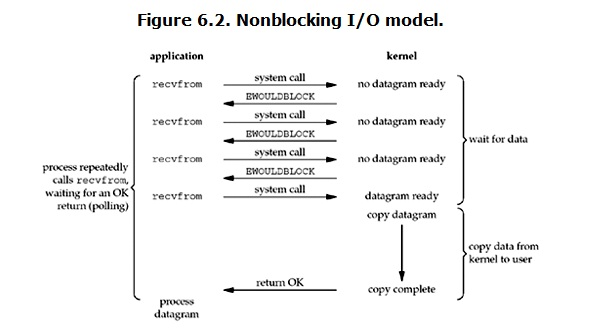
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度来讲,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果时一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到用户内存中,然后返回。
所以,nonblocking IO的特点是用户进程需要不断地主动询问kernel数据准备好了没有。
I/O 多路复用(IO multiplexing)IO multiplexing就是我们说的select,poll,epoll,有些地方也称这种IO方式为event driven IO。select/poll的好处就是在于单个的process就可以同时处理多个网络连接的的IO。它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。
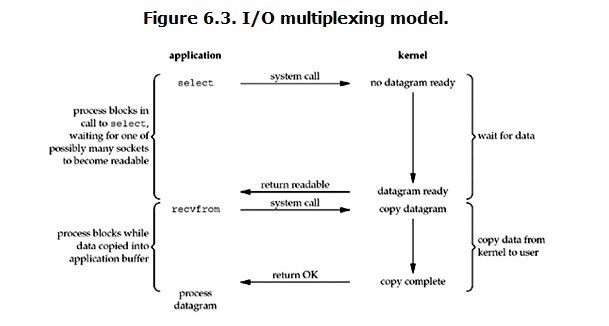
当用户进程调用了select,那么整个进程就会被block,而同时,kernel会“监视”所有select
负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户内存。
所以,I/O多路复用的特点就是通过一种机制一个进程能同时等待多个文件描述符,而这些文件描述符其中的任意一个进入读就绪状态,select()函数就可以返回。
select/epoll的优势并不是对单个连接处理的更快,而是在于能处理更多的连接。
事实上,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实一直都是被block的。只不过process是被select这个函数block,而不是被socket IO给block的。
异步 I/O(asynchronous IO)linux下的asynchronous IO其实用的很少。流程如下:
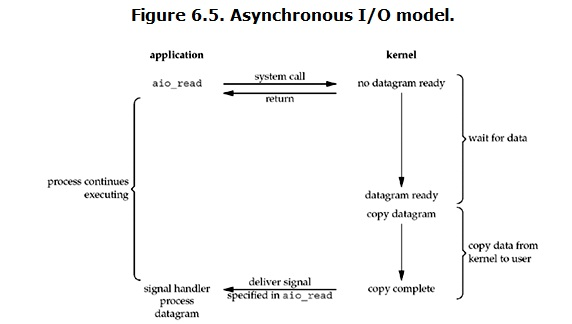
用户进程发起read操作之后,立刻就可以开始去做其他的事。而另一方面,从kernel的角度讲,当他收到一个asynchronous read之后,首先立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据可拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
各个IO MOdule 的比较如图所示:
select/poll/epoll
select,poll,epoll都是IO多路复用的机制。I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
selectselect(rlist,wlist,xlist,timeout=None)
select函数监视的文件描述符分三类,分别是writes、readfds、exceptfds。调用后select函数会阻塞,直到有描述符就绪(有数据 可读、可写、或者有except),或者超时(timeout指定等待时间),函数返回。当select函数返回后,可以通过遍历fdset,来找到就绪的描述符。
select目前几乎在所有的平台上支持。select的一个缺点在于其单个线程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,可以通过修改宏定义甚至重新编译内核的方式提升这一限制,但是这样也会造成效率的降低。
poll
int poll (struct pollfd *fds, unsigned int nfds, int timeout)
不同与select使用三个位图来表示三个fdset的方式,poll使用一个 pollfd的指针实现。
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events to watch */
short revents; /* returned events witnessed */
};
pollfd结构包含了要监视的event和发生的event,不再使用select“参数-值”传递的方式。同时,pollfd并没有最大数量限制(但是数量过大后性能也是会下降)。 和select函数一样,poll返回后,需要轮询pollfd来获取就绪的描述符。
从上面看,select和poll都需要在返回后,通过遍历文件描述符来获取已经就绪的socket。事实上,同时连接的大量客户端在一时刻可能只有很少的处于就绪状态,因此随着监视的描述符数量的增长,其效率也会线性下降。
epoll
epoll是在2.6内核中提出的,是之前的select和poll的增强版本。相对于select和poll来说,epoll更加灵活,没有描述符限制。epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
一 epoll操作过程
epoll操作过程需要三个接口,分别如下:
|
1
2
3
|
int epoll_create(int size);//创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout); |
1. int epoll_create(int size);
创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大,这个参数不同于select()中的第一个参数,给出最大监听的fd+1的值,参数size并不是限制了epoll所能监听的描述符最大个数,只是对内核初始分配内部数据结构的一个建议。
当创建好epoll句柄后,它就会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。
2. int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
函数是对指定描述符fd执行op操作。
- epfd:是epoll_create()的返回值。
- op:表示op操作,用三个宏来表示:添加EPOLL_CTL_ADD,删除EPOLL_CTL_DEL,修改EPOLL_CTL_MOD。分别添加、删除和修改对fd的监听事件。
- fd:是需要监听的fd(文件描述符)
- epoll_event:是告诉内核需要监听什么事
3. int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
等待epfd上的io事件,最多返回maxevents个事件。
参数events用来从内核得到事件的集合,maxevents告之内核这个events有多大,这个maxevents的值不能大于创建epoll_create()时的size,参数timeout是超时时间(毫秒,0会立即返回,-1将不确定,也有说法说是永久阻塞)。该函数返回需要处理的事件数目,如返回0表示已超时。
epoll:
#_*_coding:utf-8_*_
__author__ = 'Alex Li' import socket, logging
import select, errno logger = logging.getLogger("network-server") def InitLog():
logger.setLevel(logging.DEBUG) fh = logging.FileHandler("network-server.log")
fh.setLevel(logging.DEBUG)
ch = logging.StreamHandler()
ch.setLevel(logging.ERROR) formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
ch.setFormatter(formatter)
fh.setFormatter(formatter) logger.addHandler(fh)
logger.addHandler(ch) if __name__ == "__main__":
InitLog() try:
# 创建 TCP socket 作为监听 socket
listen_fd = socket.socket(socket.AF_INET, socket.SOCK_STREAM, 0)
except socket.error as msg:
logger.error("create socket failed") try:
# 设置 SO_REUSEADDR 选项
listen_fd.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
except socket.error as msg:
logger.error("setsocketopt SO_REUSEADDR failed") try:
# 进行 bind -- 此处未指定 ip 地址,即 bind 了全部网卡 ip 上
listen_fd.bind(('', 2003))
except socket.error as msg:
logger.error("bind failed") try:
# 设置 listen 的 backlog 数
listen_fd.listen(10)
except socket.error as msg:
logger.error(msg) try:
# 创建 epoll 句柄
epoll_fd = select.epoll()
# 向 epoll 句柄中注册 监听 socket 的 可读 事件
epoll_fd.register(listen_fd.fileno(), select.EPOLLIN)
except select.error as msg:
logger.error(msg) connections = {}
addresses = {}
datalist = {}
while True:
# epoll 进行 fd 扫描的地方 -- 未指定超时时间则为阻塞等待
epoll_list = epoll_fd.poll() for fd, events in epoll_list:
# 若为监听 fd 被激活
if fd == listen_fd.fileno():
# 进行 accept -- 获得连接上来 client 的 ip 和 port,以及 socket 句柄
conn, addr = listen_fd.accept()
logger.debug("accept connection from %s, %d, fd = %d" % (addr[0], addr[1], conn.fileno()))
# 将连接 socket 设置为 非阻塞
conn.setblocking(0)
# 向 epoll 句柄中注册 连接 socket 的 可读 事件
epoll_fd.register(conn.fileno(), select.EPOLLIN | select.EPOLLET)
# 将 conn 和 addr 信息分别保存起来
connections[conn.fileno()] = conn
addresses[conn.fileno()] = addr
elif select.EPOLLIN & events:
# 有 可读 事件激活
datas = ''
while True:
try:
# 从激活 fd 上 recv 10 字节数据
data = connections[fd].recv(10)
# 若当前没有接收到数据,并且之前的累计数据也没有
if not data and not datas:
# 从 epoll 句柄中移除该 连接 fd
epoll_fd.unregister(fd)
# server 侧主动关闭该 连接 fd
connections[fd].close()
logger.debug("%s, %d closed" % (addresses[fd][0], addresses[fd][1]))
break
else:
# 将接收到的数据拼接保存在 datas 中
datas += data
except socket.error as msg:
# 在 非阻塞 socket 上进行 recv 需要处理 读穿 的情况
# 这里实际上是利用 读穿 出 异常 的方式跳到这里进行后续处理
if msg.errno == errno.EAGAIN:
logger.debug("%s receive %s" % (fd, datas))
# 将已接收数据保存起来
datalist[fd] = datas
# 更新 epoll 句柄中连接d 注册事件为 可写
epoll_fd.modify(fd, select.EPOLLET | select.EPOLLOUT)
break
else:
# 出错处理
epoll_fd.unregister(fd)
connections[fd].close()
logger.error(msg)
break
elif select.EPOLLHUP & events:
# 有 HUP 事件激活
epoll_fd.unregister(fd)
connections[fd].close()
logger.debug("%s, %d closed" % (addresses[fd][0], addresses[fd][1]))
elif select.EPOLLOUT & events:
# 有 可写 事件激活
sendLen = 0
# 通过 while 循环确保将 buf 中的数据全部发送出去
while True:
# 将之前收到的数据发回 client -- 通过 sendLen 来控制发送位置
sendLen += connections[fd].send(datalist[fd][sendLen:])
# 在全部发送完毕后退出 while 循环
if sendLen == len(datalist[fd]):
break
# 更新 epoll 句柄中连接 fd 注册事件为 可读
epoll_fd.modify(fd, select.EPOLLIN | select.EPOLLET)
else:
# 其他 epoll 事件不进行处理
continue epoll socket echo server
事件驱动模型、Select\Poll\Epoll 异步IO参考:http://www.cnblogs.com/alex3714/p/4372426.html
python第十周:进程、协程、IO多路复用的更多相关文章
- day 35 协程 IO多路复用
0.基于socket发送Http请求 import socket import requests # 方式一 ret = requests.get('https://www.baidu.com/s?w ...
- 协程IO多路复用
协程:单线程下实现并发并发:伪并行,遇到IO就切换,单核下多个任务之间切换执行,给你的效果就是貌似你的几个程序在同时执行.提高效率任务切换 + 保存状态并行:多核cpu,真正的同时执行串行:一个任务执 ...
- Python学习笔记整理总结【网络编程】【线程/进程/协程/IO多路模型/select/poll/epoll/selector】
一.socket(单链接) 1.socket:应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口.在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socke ...
- 15.python并发编程(线程--进程--协程)
一.进程:1.定义:进程最小的资源单位,本质就是一个程序在一个数据集上的一次动态执行(运行)的过程2.组成:进程一般由程序,数据集,进程控制三部分组成:(1)程序:用来描述进程要完成哪些功能以及如何完 ...
- Python之路--协程/IO多路复用
引子: 之前学习过了,线程,进程的概念,知道了在操作系统中进程是资源分配的最小单位,线程是CPU调度的最小单位.按道理来说我们已经算是把CPU的利用率提高很多了.但是我们知道无论是创建多进程还是创建多 ...
- 12_进程,线程,协程,IO多路复用的区别
1.进程 1.进程可以使用计算机多核 2.进程是资源分配的单位 3.进程的创建要比线程消耗更多的资源效率很低 4.进程空间独立,数据安全性跟好操作有专门的进程间通信方式 5.一个进程可以包含多个线程, ...
- 流畅的python第十六章协程学习记录
从句法上看,协程与生成器类似,都是定义体中包含 yield 关键字的函数.可是,在协程中,yield 通常出现在表达式的右边(例如,datum = yield),可以产出值,也可以不产出——如果 yi ...
- 协程 IO多路复用
-----------------------------------------------------------------试试并非受罪,问问并不吃亏.善于发问的人,知识丰富. # # ---- ...
- 文成小盆友python-num11-(1) 线程 进程 协程
本节主要内容 线程补充 进程 协程 一.线程补充 1.两种使用方法 这里主要涉及两种使用方法,一种为直接使用,一种为定义自己的类然后继承使用如下: 直接使用如下: import threading d ...
- python并发编程之gevent协程(四)
协程的含义就不再提,在py2和py3的早期版本中,python协程的主流实现方法是使用gevent模块.由于协程对于操作系统是无感知的,所以其切换需要程序员自己去完成. 系列文章 python并发编程 ...
随机推荐
- URAL 1196. History Exam (二分)
1196. History Exam Time limit: 1.5 second Memory limit: 64 MB Professor of history decided to simpli ...
- storm 并行度
1个worker进程运行的是1个topology的子集(注:不会出现1个worker为多个topology服务).1个worker进程会启动1个或多个executor线程来运行1个topology的c ...
- Ambarella SDK build 步骤解析
Make Target Options make命令如下: make <Tab> <Tab> /*列出所有支持的目标(命令行输入make, 再按两下Tab键)*/ make & ...
- ubuntu使用ssh连接远程电脑的方法
目前,大多数linux distributions都预先安装了ssh的客户端,即可以连接别人的电脑.但也有例外的情况,所以,下面先把ssh的客户端与服务端的安装一并讲了吧. ssh客户端及服务端的安装 ...
- Catalan数(卡特兰数)
Catalan数(卡特兰数) 卡特兰数:规定h(0)=1,而h(1)=1,h(2)=2,h(3)=5,h(4)=14,h(5)=42,h(6)=132,h(7)=429,h(8)=1430,h(9)= ...
- C# 你什么让程序员寂寞成酱紫 (男生版 娱乐中学习 抽象类 接口 继承 实现方法 )
你什么让程序员寂寞成酱紫 (男生版 娱乐中学习 抽象类 接口 继承 实现方法 ) 一个家庭 相当于 一个空间,这个空间里 有 很多元素,比如 爱,爱这个抽象事物,可能有很多动作,接吻.交流,对于一 ...
- PCB MS SQL 小写转大写
由于SQL Server允许为小写进入 ,导致数据库中存在小写,在数据集成到MES或ERP时报错,Oracle要求大写导致, 需转换为大写,可通过以下语句,查询所有小写数据,再更新.
- ul和li里面的list-style
对ul list-type 只是设置ul的样式对li list-type 是对li的综合样式设定 语法是 li-style:list-style-type/list-style-imag ...
- 阿里云centos系统上安装ftp
最近需要在一台阿里云的云服务器上搭建FTP服务器,在这篇博文中分享一下我们根据实际需求进行的一些配置. ftp软件用的是vsftpd. vsftpd是一款在Linux发行版中最受推崇的FTP服务器程序 ...
- 【Leetcode】376. Wiggle Subsequence
Description: A sequence of numbers is called a wiggle sequence if the differences between successive ...