【数据分析学习】016-numpy数据结构
- import numpy
- path = r'F:\数据分析专用\数据分析与机器学习\world_alcohol.txt'
- world_alchol = numpy.genfromtxt(path, delimiter=",", dtype=str)
- print(type(world_alchol))
- print(world_alchol)
- print(help(numpy.genfromtxt))
- <class 'numpy.ndarray'>
- [['Year' 'WHO region' 'Country' 'Beverage Types' 'Display Value']
- ['' 'Western Pacific' 'Viet Nam' 'Wine' '']
- ['' 'Americas' 'Uruguay' 'Other' '0.5']
- ...
- ['' 'Africa' 'Malawi' 'Other' '0.75']
- ['' 'Americas' 'Bahamas' 'Wine' '1.5']
- ['' 'Africa' 'Malawi' 'Spirits' '0.31']]
- Help on function genfromtxt in module numpy.lib.npyio:
- genfromtxt(fname, dtype=<class 'float'>, comments='#', delimiter=None, skip_header=0, skip_footer=0, converters=None, missing_values=None, filling_values=None, usecols=None, names=None, excludelist=None, deletechars=None, replace_space='_', autostrip=False, case_sensitive=True, defaultfmt='f%i', unpack=None, usemask=False, loose=True, invalid_raise=True, max_rows=None, encoding='bytes')
- Load data from a text file, with missing values handled as specified.
- Each line past the first `skip_header` lines is split at the `delimiter`
- character, and characters following the `comments` character are discarded.
- Parameters
- ----------
- fname : file, str, pathlib.Path, list of str, generator
- File, filename, list, or generator to read. If the filename
- extension is `.gz` or `.bz2`, the file is first decompressed. Note
- that generators must return byte strings in Python 3k. The strings
- in a list or produced by a generator are treated as lines.
- dtype : dtype, optional
- Data type of the resulting array.
- If None, the dtypes will be determined by the contents of each
- column, individually.
- comments : str, optional
- The character used to indicate the start of a comment.
- All the characters occurring on a line after a comment are discarded
- delimiter : str, int, or sequence, optional
- The string used to separate values. By default, any consecutive
- whitespaces act as delimiter. An integer or sequence of integers
- can also be provided as width(s) of each field.
- skiprows : int, optional
- `skiprows` was removed in numpy 1.10. Please use `skip_header` instead.
- skip_header : int, optional
- The number of lines to skip at the beginning of the file.
- skip_footer : int, optional
- The number of lines to skip at the end of the file.
- converters : variable, optional
- The set of functions that convert the data of a column to a value.
- The converters can also be used to provide a default value
- for missing data: ``converters = {3: lambda s: float(s or 0)}``.
- missing : variable, optional
- `missing` was removed in numpy 1.10. Please use `missing_values`
- instead.
- missing_values : variable, optional
- The set of strings corresponding to missing data.
- filling_values : variable, optional
- The set of values to be used as default when the data are missing.
- usecols : sequence, optional
- Which columns to read, with 0 being the first. For example,
- ``usecols = (1, 4, 5)`` will extract the 2nd, 5th and 6th columns.
- names : {None, True, str, sequence}, optional
- If `names` is True, the field names are read from the first line after
- the first `skip_header` lines. This line can optionally be proceeded
- by a comment delimeter. If `names` is a sequence or a single-string of
- comma-separated names, the names will be used to define the field names
- in a structured dtype. If `names` is None, the names of the dtype
- fields will be used, if any.
- excludelist : sequence, optional
- A list of names to exclude. This list is appended to the default list
- ['return','file','print']. Excluded names are appended an underscore:
- for example, `file` would become `file_`.
- deletechars : str, optional
- A string combining invalid characters that must be deleted from the
- names.
- defaultfmt : str, optional
- A format used to define default field names, such as "f%i" or "f_%02i".
- autostrip : bool, optional
- Whether to automatically strip white spaces from the variables.
- replace_space : char, optional
- Character(s) used in replacement of white spaces in the variables
- names. By default, use a '_'.
- case_sensitive : {True, False, 'upper', 'lower'}, optional
- If True, field names are case sensitive.
- If False or 'upper', field names are converted to upper case.
- If 'lower', field names are converted to lower case.
- unpack : bool, optional
- If True, the returned array is transposed, so that arguments may be
- unpacked using ``x, y, z = loadtxt(...)``
- usemask : bool, optional
- If True, return a masked array.
- If False, return a regular array.
- loose : bool, optional
- If True, do not raise errors for invalid values.
- invalid_raise : bool, optional
- If True, an exception is raised if an inconsistency is detected in the
- number of columns.
- If False, a warning is emitted and the offending lines are skipped.
- max_rows : int, optional
- The maximum number of rows to read. Must not be used with skip_footer
- at the same time. If given, the value must be at least 1. Default is
- to read the entire file.
- .. versionadded:: 1.10.0
- encoding : str, optional
- Encoding used to decode the inputfile. Does not apply when `fname` is
- a file object. The special value 'bytes' enables backward compatibility
- workarounds that ensure that you receive byte arrays when possible
- and passes latin1 encoded strings to converters. Override this value to
- receive unicode arrays and pass strings as input to converters. If set
- to None the system default is used. The default value is 'bytes'.
- .. versionadded:: 1.14.0
- Returns
- -------
- out : ndarray
- Data read from the text file. If `usemask` is True, this is a
- masked array.
- See Also
- --------
- numpy.loadtxt : equivalent function when no data is missing.
- Notes
- -----
- * When spaces are used as delimiters, or when no delimiter has been given
- as input, there should not be any missing data between two fields.
- * When the variables are named (either by a flexible dtype or with `names`,
- there must not be any header in the file (else a ValueError
- exception is raised).
- * Individual values are not stripped of spaces by default.
- When using a custom converter, make sure the function does remove spaces.
- References
- ----------
- .. [1] NumPy User Guide, section `I/O with NumPy
- <http://docs.scipy.org/doc/numpy/user/basics.io.genfromtxt.html>`_.
- Examples
- ---------
- >>> from io import StringIO
- >>> import numpy as np
- Comma delimited file with mixed dtype
- >>> s = StringIO("1,1.3,abcde")
- >>> data = np.genfromtxt(s, dtype=[('myint','i8'),('myfloat','f8'),
- ... ('mystring','S5')], delimiter=",")
- >>> data
- array((1, 1.3, 'abcde'),
- dtype=[('myint', '<i8'), ('myfloat', '<f8'), ('mystring', '|S5')])
- Using dtype = None
- >>> s.seek(0) # needed for StringIO example only
- >>> data = np.genfromtxt(s, dtype=None,
- ... names = ['myint','myfloat','mystring'], delimiter=",")
- >>> data
- array((1, 1.3, 'abcde'),
- dtype=[('myint', '<i8'), ('myfloat', '<f8'), ('mystring', '|S5')])
- Specifying dtype and names
- >>> s.seek(0)
- >>> data = np.genfromtxt(s, dtype="i8,f8,S5",
- ... names=['myint','myfloat','mystring'], delimiter=",")
- >>> data
- array((1, 1.3, 'abcde'),
- dtype=[('myint', '<i8'), ('myfloat', '<f8'), ('mystring', '|S5')])
- An example with fixed-width columns
- >>> s = StringIO("11.3abcde")
- >>> data = np.genfromtxt(s, dtype=None, names=['intvar','fltvar','strvar'],
- ... delimiter=[1,3,5])
- >>> data
- array((1, 1.3, 'abcde'),
- dtype=[('intvar', '<i8'), ('fltvar', '<f8'), ('strvar', '|S5')])
- None
用array输入数组
- vector = numpy.array([5, 10, 15, 20])
- matrix = numpy.array([[5, 10, 15], [20, 25, 30], [35, 40, 45]])
- print(vector)
- print(matrix)
输出结果
- vector = numpy.array([1, 2, 3, 4])
- print(vector.shape)
- matrix = numpy.array([[5, 10, 15], [20, 25, 30]])
- print(matrix.shape)
- import numpy
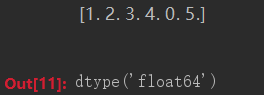
- numbers = numpy.array([1, 2, 3, 4, 0, 5.0])
- print(numbers)
- numbers.dtype
- world_alchol = numpy.genfromtxt(path, delimiter=',', dtype=str, skip_header=1)
- print(world_alchol)
文件读取

输出的是一个列表,那么读取的时候就可以根据切片读取出列表的值
- uruguay_other_1986 = world_alchol[1, 4]
- third_country = world_alchol[2, 2]
- print(uruguay_other_1986)
- print(third_country)
切片取值
【数据分析学习】016-numpy数据结构的更多相关文章
- Python数据分析学习之Numpy
Numpy的简单操作 import numpy #导入numpy包 file = numpy.genfromtxt("文件路径",delimiter=" ",d ...
- Python数据分析学习目录
python数据分析学习目录 Anaconda的安装和更新 矩阵NumPy pandas数据表 matplotlib-2D绘图库学习目录
- 个人永久性免费-Excel催化剂功能第100波-透视多行数据为多列数据结构
在数据处理过程中,大量的非预期格式结构需要作转换,有大家熟知的多维转一维(准确来说应该是交叉表结构的数据转二维表标准数据表结构),也同样有一些需要透视操作的数据源,此篇同样提供更便捷的方法实现此类数据 ...
- Python数据分析学习(二):Numpy数组对象基础
1.1数组对象基础 .caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { bord ...
- Python数据分析学习(一):Numpy与纯Python计算向量加法速度比较
import sys from datetime import datetime import numpy as np def numpysum(n): a = np.arange(n) ** 2 b ...
- python数据分析学习(2)pandas二维工具DataFrame讲解
目录 二:pandas数据结构介绍 下面继续讲解pandas的第二个工具DataFrame. 二:pandas数据结构介绍 2.DataFarme DataFarme表示的是矩阵的数据表,包含 ...
- python数据分析学习(1)pandas一维工具Series讲解
目录 一:pandas数据结构介绍 python是数据分析的主要工具,它包含的数据结构和数据处理工具的设计让python在数据分析领域变得十分快捷.它以NumPy为基础,并对于需要类似 for循环 ...
- 数据分析学习(zhuan)
http://www.zhihu.com/question/22119753 http://www.zhihu.com/question/20757000 ********************** ...
- [python]-数据科学库Numpy学习
一.Numpy简介: Python中用列表(list)保存一组值,可以用来当作数组使用,不过由于列表的元素可以是任何对象,因此列表中所保存的是对象的指针.这样为了保存一个简单的[1,2,3],需要有3 ...
随机推荐
- tp5 权限设置
============================== <?php/** * Created by PhpStorm. * User: 14155 * Date: 2018/11/10 * ...
- RONOJ——PID204 / 特种部队 ☆
题目描述 某特种部队接到一个任务,需要潜入一个仓库.该部队士兵分为两路,第一路士兵已经在正面 牵制住了敌人,第二路士兵正在悄悄地从后方秘密潜入敌人的仓库. 当他们到达仓库时候,发现这个仓库的锁是一把很 ...
- atomikos实现多数据源支持分布式事务管理(spring、tomcat、JTA)
原文链接:http://iteye.blog.163.com/blog/static/1863080962012102945116222/ Atomikos TransactionsEssenti ...
- HDU 5402 Travelling Salesman Problem (模拟 有规律)(左上角到右下角路径权值最大,输出路径)
Travelling Salesman Problem Time Limit: 3000/1500 MS (Java/Others) Memory Limit: 65536/65536 K (J ...
- Android 5.0 怎样正确启用isLoggable(二)__原理分析
前置文章 <Android 5.0 怎样正确启用isLoggable(一)__使用具体解释> 概要 在上文<Android 5.0 怎样正确启用isLoggable(一)__使用具体 ...
- 关于使用chrome插件改动全部的站点的响应responseHeaders头的注意
1 眼下我掌握的调试技巧非常不方便,如今使用的是浏览器动作,每次都须要点击那个popup页面弹出,然后右键->查看元素,才干显示它的调试面板.一点击某些位置它又没有了; 2 改动响应报头的值时, ...
- Composer 很重要很重要 内核 原理
话题先攒着,过来再来写 先来一张原理图 composer的原理和其他的包管理工具都是一样的,只是实现的细节有些不同,例如yum,例如brew,例如apt-get还有packets. 使用自己的comp ...
- Java缓存server调优
搜索降级方案中xmn開始使用bizer默认的128M,很慢. 偶然改成1G,效果立刻上来,可是xmx调大并没有明显效果. 100并发 200并 ...
- MySQL调优 —— Using temporary
DBA发来一个线上慢查询问题. SQL例如以下(为突出重点省略部分内容): select distinct article0_.id, 等字段 from article_table article ...
- 深入Session
早上考虑Spring MVC和Structs2项目共用时看到一个问题,如何保持session一致?Session是怎么样被服务器处理的呢,Spring MVC中是如何封装处理Session并在不同请求 ...