Kafka学习笔记(2)----Kafka的架构
1. 架构图
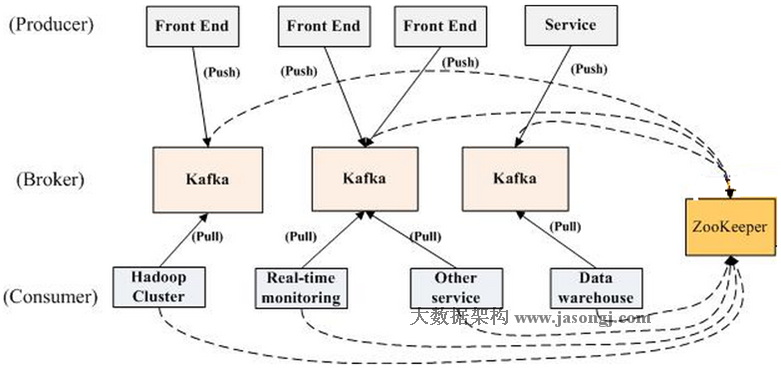
一个Kafka集群中包含若干个Broker(消息实例),Kafka支持Broker横向扩展,Broker越多,吞吐量越大,同时也包含了若干个Producer(可以是web前端产生的Page View,或者是服务器日志,系统CPU、Memory等)和若干个Consumer(消费者)以及一个zookeeper集群,Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
2. Topic和Partition


Topic:是一个逻辑的概念,它可以认为类似于其他中间件中queue的概念,作为一组消息的一个集合,跟其他的消息中间件一样,每个消息的发送或者是消费都必须要指定Topic,表明将消息存在哪个Topic中。一个Topic可以接受多个Producer发送的消息和被多个Consumer消费。
Partition:了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件,同意Topic下不同分区包含的消息是不同的,当每个消息发送到分区时,都会分配到一个offset(偏移量)它是消息在此分区中的唯一编号,kafka通过offset保证消息在分区内的顺序,offset的顺序不跨分区,即kafka只保证在同一个分区内的消息是有序的;Partition是以文件的形式存储在文件系统中,存储在kafka-log目录下,命名规则为<topic_name>-<partition_id>,如新建一个Topic,

查看kafka_log目录

3. kafka高吞吐量的原因
因为每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证。
对于传统的message queue而言,一般会删除已经被消费的消息,而Kafka集群会保留所有的消息,无论其被消费与否。当然,因为磁盘限制,不可能永久保留所有数据(实际上也没必要),因此Kafka提供两种策略删除旧数据。一是基于时间,二是基于Partition文件大小。例如可以通过配置$KAFKA_HOME/config/server.properties,让Kafka删除一周前的数据,也可在Partition文件超过1GB时删除旧数据,配置如下所示。
#The minimum age of a log file to be eligible for deletion
log.retention.hours=
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=
# The interval at which log segments are checked to see if they can be deleted according to the retention policies
log.retention.check.interval.ms=
# If log.cleaner.enable=true is set the cleaner will be enabled and individual logs can then be marked for log compaction.
log.cleaner.enable=false
因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除过期文件与提高Kafka性能无关。选择怎样的删除策略只与磁盘以及具体的需求有关。另外,Kafka会为每一个Consumer Group保留一些metadata信息——当前消费的消息的position,也即offset。这个offset由Consumer控制。正常情况下Consumer会在消费完一条消息后递增该offset。当然,Consumer也可将offset设成一个较小的值,重新消费一些消息。因为offset由Consumer控制,所以Kafka broker是无状态的,它不需要标记哪些消息被哪些消费过,也不需要通过broker去保证同一个Consumer Group只有一个Consumer能消费某一条消息,因此也就不需要锁机制,这也为Kafka的高吞吐率提供了有力保障。
在异步消息发送模式中,kafka允许进行批量发送,也就是先讲消息缓存到内存中,然后一次请求批量发送出去。这样减少了磁盘频繁io以及网络IO造成的性能瓶颈。
零拷贝也是提高吞吐量的一个点。
Kafka学习笔记(2)----Kafka的架构的更多相关文章
- Kafka学习笔记之Kafka背景及架构介绍
0x00 概述 本文介绍了Kafka的创建背景,设计目标,使用消息系统的优势以及目前流行的消息系统对比.并介绍了Kafka的架构,Producer消息路由,Consumer Group以及由其实现的不 ...
- Kafka学习笔记(三)——架构深入
之前搭建好了Kafka的学习环境,了解了具体的配置文件内容,并且测试了生产者.消费者的控制台使用方式,也学习了基本的API.那么下一步,应该学习一下具体的内部流程~ 1.Kafka的工作流程 大致的工 ...
- Kafka学习笔记之Kafka性能测试方法及Benchmark报告
0x00 概述 本文主要介绍了如何利用Kafka自带的性能测试脚本及Kafka Manager测试Kafka的性能,以及如何使用Kafka Manager监控Kafka的工作状态,最后给出了Kafka ...
- Kafka学习笔记之Kafka三款监控工具
0x00 概述 在之前的博客中,介绍了Kafka Web Console这 个监控工具,在生产环境中使用,运行一段时间后,发现该工具会和Kafka生产者.消费者.ZooKeeper建立大量连接,从而导 ...
- Kafka学习笔记之Kafka Consumer设计解析
0x00 摘要 本文主要介绍了Kafka High Level Consumer,Consumer Group,Consumer Rebalance,Low Level Consumer实现的语义,以 ...
- 【kafka学习笔记】kafka的基本概念
在了解了背景知识后,我们来整体看一下kafka的基本概念,这里不做深入讲解,只是初步了解一下. kafka的消息架构 注意这里不是设计的架构,只是为了方便理解,脑补的三层架构.从代码的实现来看,kaf ...
- Kafka学习笔记之Kafka High Availability(下)
0x00 摘要 本文在上篇文章基础上,更加深入讲解了Kafka的HA机制,主要阐述了HA相关各种场景,如Broker failover,Controller failover,Topic创建/删除,B ...
- Kafka学习笔记之Kafka High Availability(上)
0x00 摘要 Kafka在0.8以前的版本中,并不提供High Availablity机制,一旦一个或多个Broker宕机,则宕机期间其上所有Partition都无法继续提供服务.若该Broker永 ...
- Kafka学习笔记1——Kafka的安装和启动
一.准备工作 1. 安装JDK 可以用命令 java -version 查看版本
- Kafka学习笔记之Kafka自身操作日志的清理方法(非Topic数据)
0x00 概述 本文主要讲Kafka自身操作日志的清理方法(非Topic数据),Topic数据自己有对应的删除策略,请看这里. Kafka长时间运行过程中,在kafka/logs目录下产生了大量的ka ...
随机推荐
- 最佳实践 | 源码升级gcc
1.下载升级包所需软件 boost_1_60_0.tar.gz http://www.boost.org/users/history/version_1_60_0.html gcc-4.8.0.tar ...
- JavaScript 事件代理绑定
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- git分支合并概念
git merge命令用于合并指定分支到当前分支. git merge命令用于合并指定分支到当前分支. git merge命令用于合并指定分支到当前分支. 创建与合并分支 阅读: 931277 在版本 ...
- 这篇文章关于两阶段提交和Paxos讲的很好
http://blog.chinaunix.net/uid-16723279-id-3803058.html <两阶段提交协议与paxos投票算法> 点评:2PC绝对是CP的死党,是分布式 ...
- HDU 5191
好端端的被HACK掉了...应该是在两端都要补W个0才对,之前只想到要在后面补足0,没想到前面也应该补足,因为前面即便存在0也可能使得移动的积木数最少.. T_T #include <iostr ...
- [Cypress] Get started with Cypress
Adding Cypress to a project is a simple npm install away. We won’t need any global dependencies beyo ...
- 用Java做的类似皇家守卫战的游戏
最近因为数据结构的课设缘故,所以用Java做了一款类似皇家守卫战(本人最钟情的一款PC兼手游的塔防游戏)的游戏.现在把这个游戏放出来,可以下载下来 玩耍 学习,代码中我也做了大量的注释.(运行游戏得带 ...
- Linux命令(三)——用户、群组管理命令
一.用户和群组的配置文件 1./etc/passwd文件 该文件存储了所有用户的一些基本属性. /etc/passwd文件中所存信息的具体含义如下: 用户名:x表示必须使用密码登录:uid用户标识符: ...
- C# 尝试读取或写入受保护的内存 。这通常指示其他内存已损坏。
在C#中调用别人的DLL的时候有时候出现 尝试读取或写入受保护的内存 .这通常指示其他内存已损坏. 在传值的时候还是用指针,再在C#中做转换就好了. 解决办法: [DllImport("AP ...
- Amazon宣布将MXNet作为AWS的深度学习框架——貌似性能比tf高啊
Amazon公司的Werner Vogels于上周宣布Amazon深度学习框架将会正式选用MXNet,并且AWS将会通过增加源代码贡献.改进文档以及支持来自其它框架的可视化.开发以及迁移工具,为实现M ...