pandas分组运算(groupby)
1. groupby()
import pandas as pd
df = pd.DataFrame([[1, 1, 2], [1, 2, 3], [2, 3, 4]], columns=["A", "B", "C"])
print(df)

g = df.groupby('A').mean() # 按A列分组(groupby),获取其他列的均值
print(g)

# 方法1
b = df['B'].groupby(df['A']).mean() # 按A列分组,获取B列的均值
print(b) # 方法2
b = df.ix[:,1].groupby(df.ix[:, 0]).mean() # 按A列分组(0对应A列,1对应B列),获取B列的均值
print(b) # 方法3
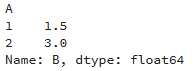
m = df.groupby('A')
b = m['B'].mean()
print(b)
2. 聚合方法size()和count()
size跟count的区别: size计数时包含NaN值,而count不包含NaN值
import pandas as pd
import numpy as np df = pd.DataFrame({"Name":["Alice", "Bob", "Mallory", "Mallory", "Bob" , "Mallory"],
"City":["Seattle", "Seattle", "Portland", "Seattle", "Seattle", "Portland"],
"Val":[4,3,3,np.nan,np.nan,4]})
print(df)
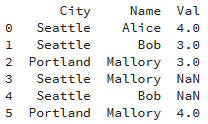
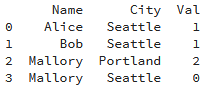
count()
a = df.groupby(["Name", "City"], as_index=False)['Val'].count()
print(a)
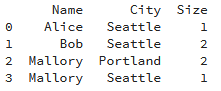
size()
b = df.groupby(["Name", "City"])['Val'].size().reset_index(name='Size')
print(b)
来自:https://blog.csdn.net/m0_37870649/article/details/80979809
pandas分组运算(groupby)的更多相关文章
- pandas聚合和分组运算——GroupBy技术(1)
数据聚合与分组运算——GroupBy技术(1),有需要的朋友可以参考下. pandas提供了一个灵活高效的groupby功能,它使你能以一种自然的方式对数据集进行切片.切块.摘要等操作.根据一个或多个 ...
- Pandas分组运算(groupby)修炼
Pandas分组运算(groupby)修炼 Pandas的groupby()功能很强大,用好了可以方便的解决很多问题,在数据处理以及日常工作中经常能施展拳脚. 今天,我们一起来领略下groupby() ...
- Pandas分组(GroupBy)
任何分组(groupby)操作都涉及原始对象的以下操作之一.它们是 - 分割对象 应用一个函数 结合的结果 在许多情况下,我们将数据分成多个集合,并在每个子集上应用一些函数.在应用函数中,可以执行以下 ...
- pandas学习(数据分组与分组运算、离散化处理、数据合并)
pandas学习(数据分组与分组运算.离散化处理.数据合并) 目录 数据分组与分组运算 离散化处理 数据合并 数据分组与分组运算 GroupBy技术:实现数据的分组,和分组运算,作用类似于数据透视表 ...
- 【学习】数据聚合和分组运算【groupby】
分组键可以有多种方式,且类型不必相同 列表或数组, 某长度与待分组的轴一样 表示DataFrame某个列名的值 字典或Series,给出待分组轴上的值与分组名之间的对应关系 函数用于处理轴索引或索引中 ...
- Python数据聚合和分组运算(1)-GroupBy Mechanics
前言 Python的pandas包提供的数据聚合与分组运算功能很强大,也很灵活.<Python for Data Analysis>这本书第9章详细的介绍了这方面的用法,但是有些细节不常用 ...
- python库学习笔记——分组计算利器:pandas中的groupby技术
最近处理数据需要分组计算,又用到了groupby函数,温故而知新. 分组运算的第一阶段,pandas 对象(无论是 Series.DataFrame 还是其他的)中的数据会根据你所提供的一个或多个键被 ...
- 利用Python进行数据分析-Pandas(第六部分-数据聚合与分组运算)
对数据集进行分组并对各组应用一个函数(无论是聚合还是转换),通常是数据分析工作中的重要环节.在将数据集加载.融合.准备好之后,通常是计算分组统计或生成透视表.pandas提供了一个灵活高效的group ...
- python中pandas数据分析基础3(数据索引、数据分组与分组运算、数据离散化、数据合并)
//2019.07.19/20 python中pandas数据分析基础(数据重塑与轴向转化.数据分组与分组运算.离散化处理.多数据文件合并操作) 3.1 数据重塑与轴向转换1.层次化索引使得一个轴上拥 ...
随机推荐
- openstack mitaka开启三层网络vxlan
在这之前,先把之前基于flat模式创建的虚机,全部删除 控制节点: 配置 修改/etc/neutron/neutron.conf的[DEFAULT]区域 将 core_plugin = ml2 ser ...
- 2.flask模板--jinja2
1.jinja2模板介绍和查找路径 import os from flask import Flask, render_template # 之前提到过在渲染模板的时候,默认会从项目根目录下的temp ...
- nginx服务学习第一章
一.ubuntu系统安装nginx服务 # apt-get install nginx 二.nginx.config配置文件详解 配置文件结构: 全局块(全局变量) events{ } http{ h ...
- Ubuntu中出现“Could not get lock /var/lib/dpkg/lock”的解决方法
在运行Ubuntu安装软件,使用命令sudo apt-get install时,有时会出现以下的错误: E: Could not get lock /var/lib/dpkg/lock - open ...
- javascript join以及slice,push函数
1.join定义和用法 join() 方法用于把数组中的所有元素放入一个字符串. 元素是通过指定的分隔符进行分隔的. arrayObject.join(separator) separator:可选. ...
- 转(static final 和final的区别)
学习java的时候常常会被修饰符搞糊涂,这里总结下static final和final的区别. 1.static 强调只有一份,final 说明是一个常量,final定义的基本类型的值是不可改变的,但 ...
- POJ2449 K短路模板
#include <iostream> #include <cstring> #include <cstdlib> #include <cstdio> ...
- Django学习系列17:在模板中渲染待办事项
前面提到的问题中在表格中显示多个待办事项 是最后一个容易解决的问题.要编写一个新单元测试,检查模板是否也能显示多个待办事项: lists/tests.py def test_displays_all_ ...
- 文件操作相关函数(POSIX 标准 open,read,write,lseek,close)
POSIX标准 open函数属于Linux中系统IO,用于“打开”文件,代码打开一个文件意味着获得了这个文件的访问句柄. int fd = open(参数1,参数2,参数3): int fd = op ...
- spring ObjectFactory
AspectJAwareAdvisorAutoProxyCreator implements PostProcessor postProcessorAfterInitialization(Object ...