hadoop HA + HBase HA搭建:
hadoop HA搭建参考:https://www.cnblogs.com/NGames/p/11083640.html (本节:用不到YARN 所以可以不用考虑部署YARN部分)
Hadoop 使用分 布式文件系统,用于存储大数据,并使用 MapReduce 来处理。Hadoop 擅长于存储各种格式 的庞大的数据,任意的格式甚至非结构化的处理。
Hadoop 的限制:
Hadoop 只能执行批量处理,并且只以顺序方式访问数据。这意味着必须搜索整个数据集, 即使是最简单的搜索工作。这一点上,一个 新的解决方案,需要访问数据中的任何点(随机访问)单元。
Hadoop 随机存取数据库:HBase,Cassandra等...都是一些存储大量数据和 以随机方式访问数据的数据库
HBase简介:
使用环境:当您需要对大数据进行随机、实时的读/写访问时,请使用Apache HBase
HBase是Hadoop数据库,一个分布式、可伸缩的大数据存储。硬件集群上托管非常大的表(数十亿行X数百万列),Apache HBase是一个开源的、分布式的、版本化的、非关系数据库,以谷歌的Bigtable: A distributed Storage System for Structured Data为模型,由Chang等人开发。正如Bigtable利用了谷歌文件系统提供的分布式数据存储一样,Apache HBase在Hadoop和HDFS之上提供了类似Bigtable的功能。
Apache Hadoop 的数据库,是建 立在 HDFS 之上,被设计用来提供高可靠性、高性能、列存储、可伸缩、多版本的 NoSQL 的分布式数据存储系统,实现对大型数据的实时、随机的读写访问。
HBase 依赖于 HDFS 做底层的数据存储
HBase 依赖于 MapReduce 做数据计算
HBase 依赖于 ZooKeeper 做服务协调
HBase 与 关系型数据库(mysql) 表结构对比,图解
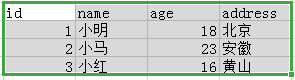 关系型数据库(mysql),一旦表的结构定义好了,扩展比较麻烦
关系型数据库(mysql),一旦表的结构定义好了,扩展比较麻烦

HBASE表结构:建表时,不需要限定表中的字段,只需要指定若干个列簇
插入数据是,列簇中可以存储任意多个列(KV,列名&列值)
要查询一个具体字段的值,需要指定的坐标:表名-->行键-->列簇:列名----->版本
版本,如:name:小红;晓红;晓红,每个版本查询的结果不同
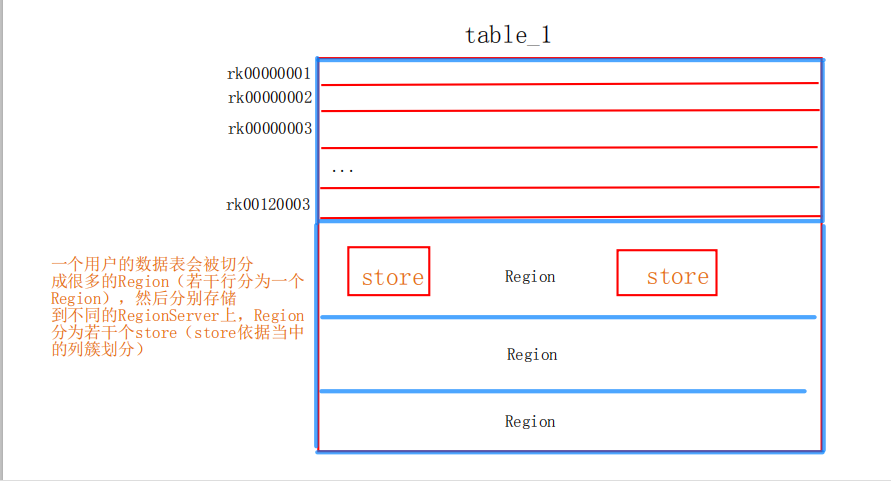
table_1表()---META表---ROOT表----zk
HBASE集群搭建:
| 主机名 | IP | 安装软件 | 运行进程 |
| hadoop01 | 192.168.109.137 | jdk、hadoop、hbase | namenode、DFSZKailoverController(zkfc)、HMaster |
| hadoop02 | 192.168.109.138 | jdk、hadoop、hbase | namenode、DFSZKailoverController(zkfc)、HMaster |
| hadoop05 | 192.168.109.141 | jdk、hadoop、zk、hbase | DataNode、JournalNode、QuorumPeerMain、HRegionServer |
| hadoop06 | 192.168.109.142 | jdk、hadoop、zk、hbase | DataNode、JournalNode、QuorumPeerMain、HRegionServer |
| hadoop07 | 192.168.109.143 | jdk、hadoop、zk、hbase | DataNode、JournalNode、QuorumPeerMain、HRegionServer |
wget http://mirror.bit.edu.cn/apache/hbase/2.2.0/hbase-2.2.0-bin.tar.gz (下载与你hadoop版本匹配的hbase::http://hbase.apache.org/book.html#configuration)
tar -zcf hbase-2.2.0-bin.tar.gz -C /home/apps/
rm -rf /home/apps/hbase-2.2.0/docs/*
cd /home/apps/hbase-2.2.0/conf
vim /home/apps/hbase-2.2.0/conf/hbase-env.sh 添加jak
export JAVA_HOME=/usr/local/soft/jdk
# export HBASE_MANAGES_ZK=true 自带的zk管理开关,我打开注释并改为false关闭自带的,用我们的zk集群
vim /home/apps/hbase-2.2.0/conf/hbase-site.xml
<configuration>
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns1/hbase</value>
</property>
<!-- 指定hbase是分布式的 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zk的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop05:2181,hadoop06:2181,hadoop07:2181</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
vim /home/apps/hbase-2.2.0/conf/regionservers
hadoop05
hadoop06
hadoop07
vim /home/apps/hbase-2.2.0/conf/backup-masters 注意:俩台主备互为热主备
hadoop02
注意:上面 hbase-site.sh指定的<value>hdfs://ns1/hbase</value>;要想读取到,我们可以将hadoop下的
core-site.xml 和 hdfs-site.xml 拷贝到Hbase配置下
cp /home/apps/hadoop-3.2.0/etc/hadoop/{core-site.xml,hdfs-site.xml} /home/apps/hbase-2.2.0/conf/
配置完毕,将目录同步到其他机器(hadoop02,hadoop05,hadoop06,hadoop07)
cd /home/apps/
rsync -avz --progress -e ssh ./hbase-2.2.0 hadoop02:/home/apps/
...
...
...
1.zk集群起起来
2.HDFS起起来:start-dfs.sh
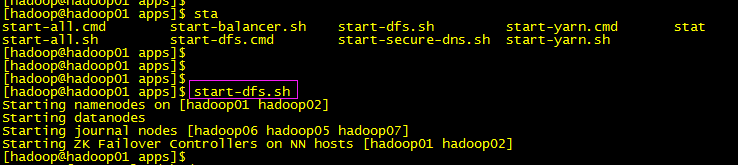
自我检测对应的进程是否完成,日志稍微看看
3.启动hbase集群
可以将hbase环境加入主机环境(略)
启动:/home/apps/hbase-2.2.0/bin/start-hbase.sh

启动完毕查看启动日志过程,各节点jps查看进程
页面查看:
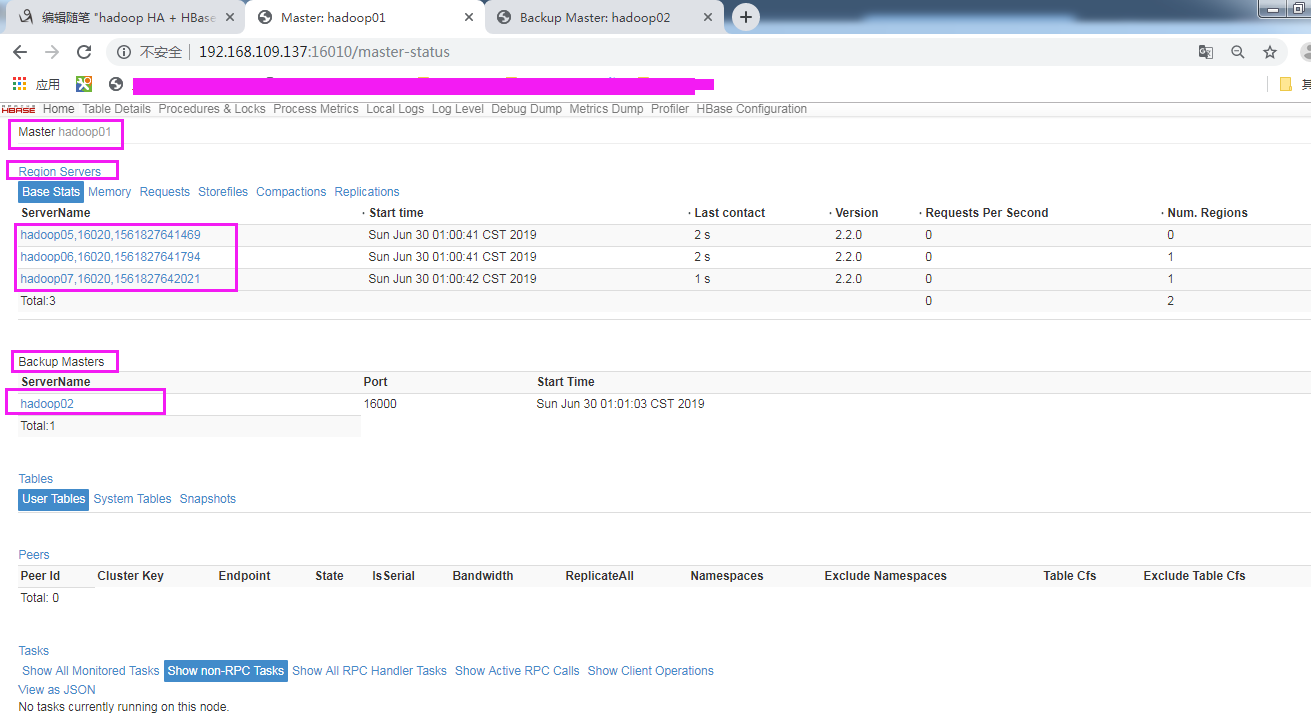
测试:
1.手动kill进程测试HA正常
使用:
命令客户端:/home/apps/hbase-2.2.0/bin/hbase shell
nosql语法上网查
hadoop HA + HBase HA搭建:的更多相关文章
- Hadoop + ZK + HBase 环境搭建
Hadoop 环境搭建 参考资料: http://hadoop.apache.org/docs/r2.4.1/hadoop-project-dist/hadoop-common/ClusterSetu ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop zookeeper hbase spark phoenix (HA)搭建过程
环境介绍: 系统:centos7 软件包: apache-phoenix-4.14.0-HBase-1.4-bin.tar.gz 下载链接:http://mirror.bit.edu.cn/apac ...
- 基于HBase0.98.13搭建HBase HA分布式集群
在hadoop2.6.0分布式集群上搭建hbase ha分布式集群.搭建hadoop2.6.0分布式集群,请参考“基于hadoop2.6.0搭建5个节点的分布式集群”.下面我们开始啦 1.规划 1.主 ...
- Hadoop双namenode配置搭建(HA)
配置双namenode的目的就是为了防错,防止一个namenode挂掉数据丢失,具体原理本文不详细讲解,这里只说明具体的安装过程. Hadoop HA的搭建是基于Zookeeper的,关于Zookee ...
- HBase HA分布式集群搭建
HBase HA分布式集群搭建部署———集群架构 搭建之前建议先学习好HBase基本构架原理:https://www.cnblogs.com/lyywj170403/p/9203012.html 集群 ...
- Apache版本的Hadoop HA集群启动详细步骤【包括Zookeeper、HDFS HA、YARN HA、HBase HA】(图文详解)
不多说,直接上干货! 1.先每台机器的zookeeper启动(bigdata-pro01.kfk.com.bigdata-pro02.kfk.com.bigdata-pro03.kfk.com) 2. ...
- hadoop 集群HA高可用搭建以及问题解决方案
hadoop 集群HA高可用搭建 目录大纲 1. hadoop HA原理 2. hadoop HA特点 3. Zookeeper 配置 4. 安装Hadoop集群 5. Hadoop HA配置 搭建环 ...
- hadoop ha集群搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 zookeeper-3.4.8 linux系统环境:Centos6.5 3台主机:master.slave01.slave02 Hado ...
随机推荐
- mac 电脑设置密码可以直接使用 passwd 这个命令
mac 电脑设置密码可以直接使用 passwd 这个命令 说明:这个命令行级别的设置会直接影响到我们登录.
- HDU6715 算术(莫比乌斯反演)
HDU6715 算术 莫比乌斯反演的变形. 对 \(\mu(lcm(i,j))\) 变换,易得 \(\mu(lcm(i,j)) = \mu(i)\cdot\mu(j)\cdot \mu(gcd(i,j ...
- Qualcomm 8X camera过程解析【转】
本文转载自:http://blog.csdn.net/gabbzang/article/details/19906687 http://www.01yun.com/mobile_development ...
- 网络处理器(Network Processor)
网络处理器(Network Processor,简称NP),又可以称为交换芯片,专用于实现核心交换机高速转发功能. 根据网络处理器会议(Network Processors Conference)的定 ...
- UART协议详解
UART(Universal Asynchronous Receiver/Transmitter)是一种异步全双工串行通信协议,由Tx和Rx两根数据线组成,因为没有参考时钟信号,所以通信的双方必须约定 ...
- VS Project Property Manage
概念:Project Property 和 Property Sheet. Project Property:项目属性,是你当前项目的属性配制,保存在你工程的配制文件中,rojectName.vcxp ...
- Js dom 学习
节点类型 文档节点: 一棵DOM树的顶端是文档节点,它呈现为整个页面(相当于document对象),当需要访问任何元素.属性或文本节点时,都需要通过文档节点来进行导航.(document.) 元素节点 ...
- beego 注解路由无效问题分析
问题描述:学习 beego 框架发现注解路由无效,除了不能找到路由外,未见任何异常. 问题解决:将配置文件中的 runmode 更改为 dev 模式. 问题分析: 如果没有设置过 runmode 不会 ...
- fastdfs集群安装过程_学习笔记
最终效果 初始化为6个节点 在/usr/local/software 目录下上传需要用到tar包,分别在各个节点上传 使用scp 将本地software目录复制到其他节点上 73.74为 tracke ...
- git的忽略文件语法规范
忽略文件语法规范 空行或是以 # 开头的行即注释行将被忽略. 可以在前面添加正斜杠 / 忽略当前路径文件,但不包括子目录的同名文件. 可以在后面添加正斜杠 / 来忽略文件夹. 可以使用 ! 来否定忽略 ...