RocketMQ吐血总结
RocketMQ吐血总结
架构
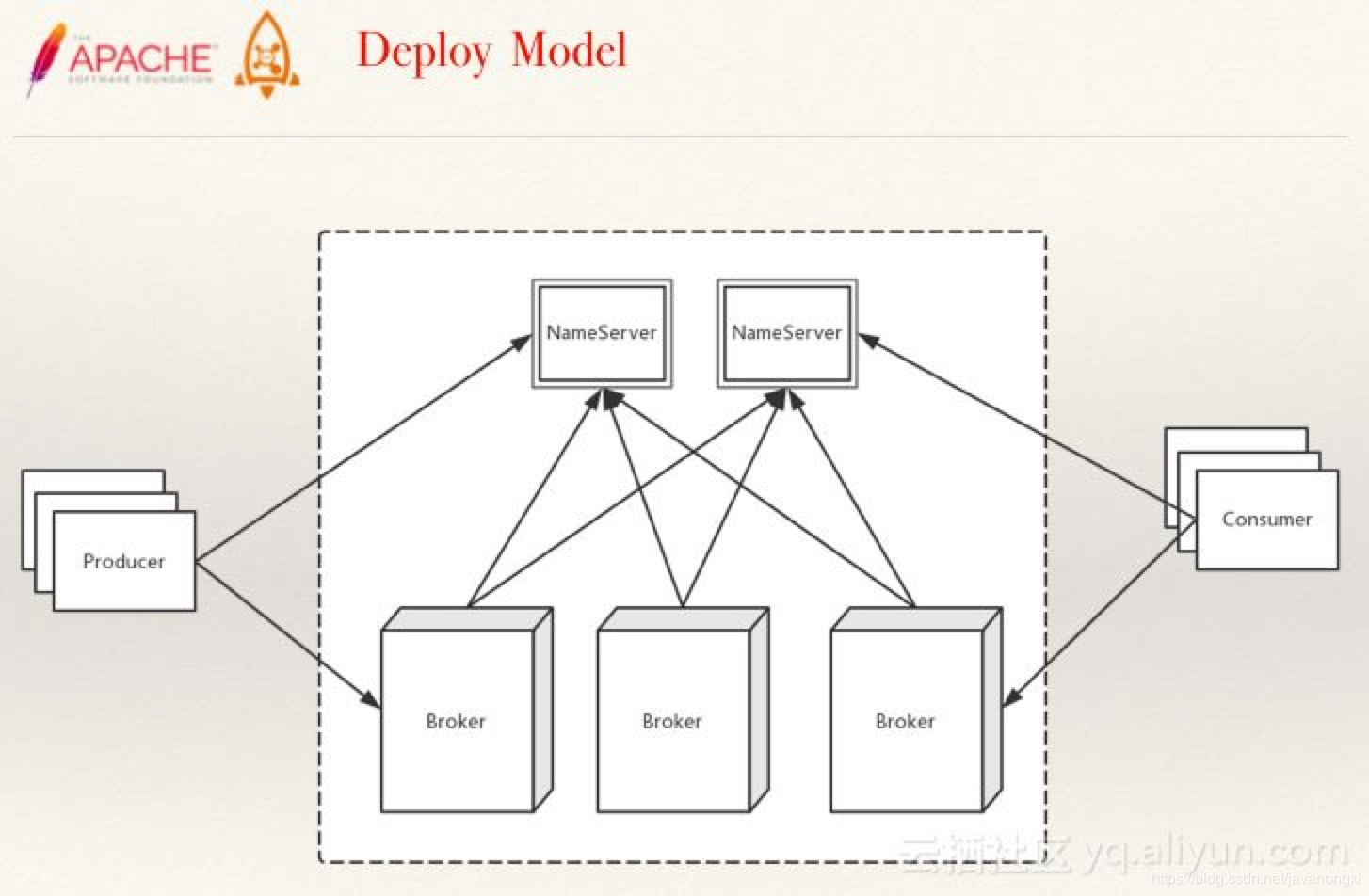
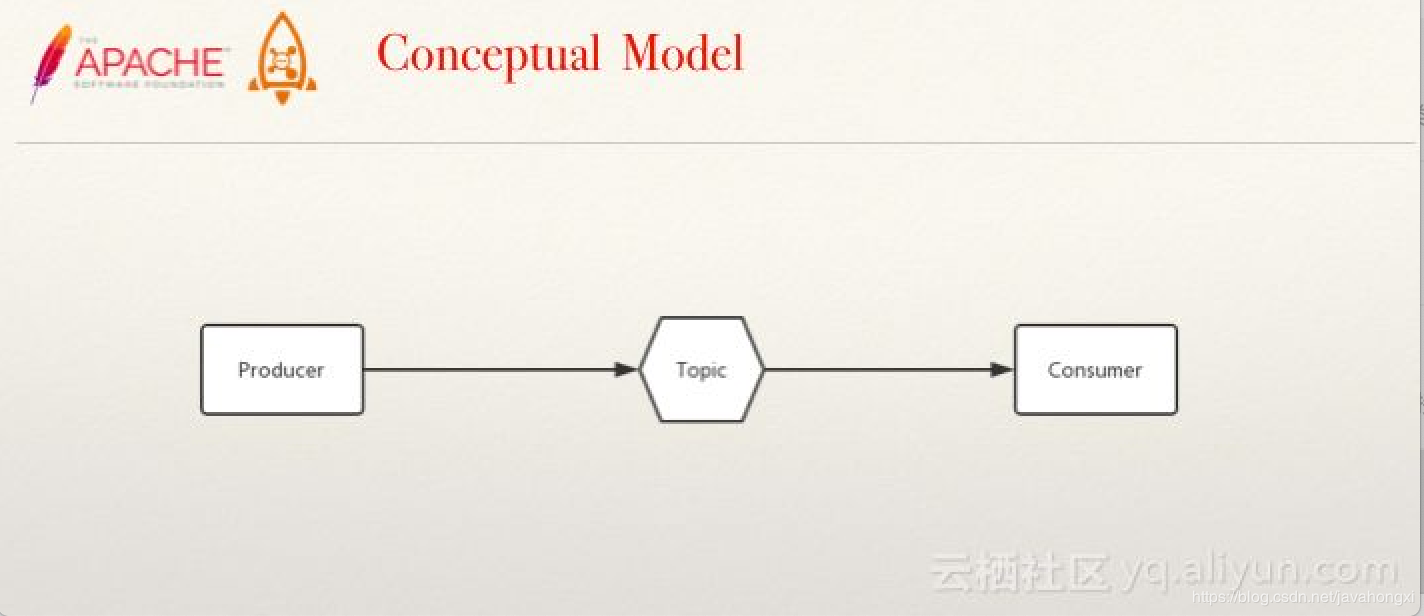
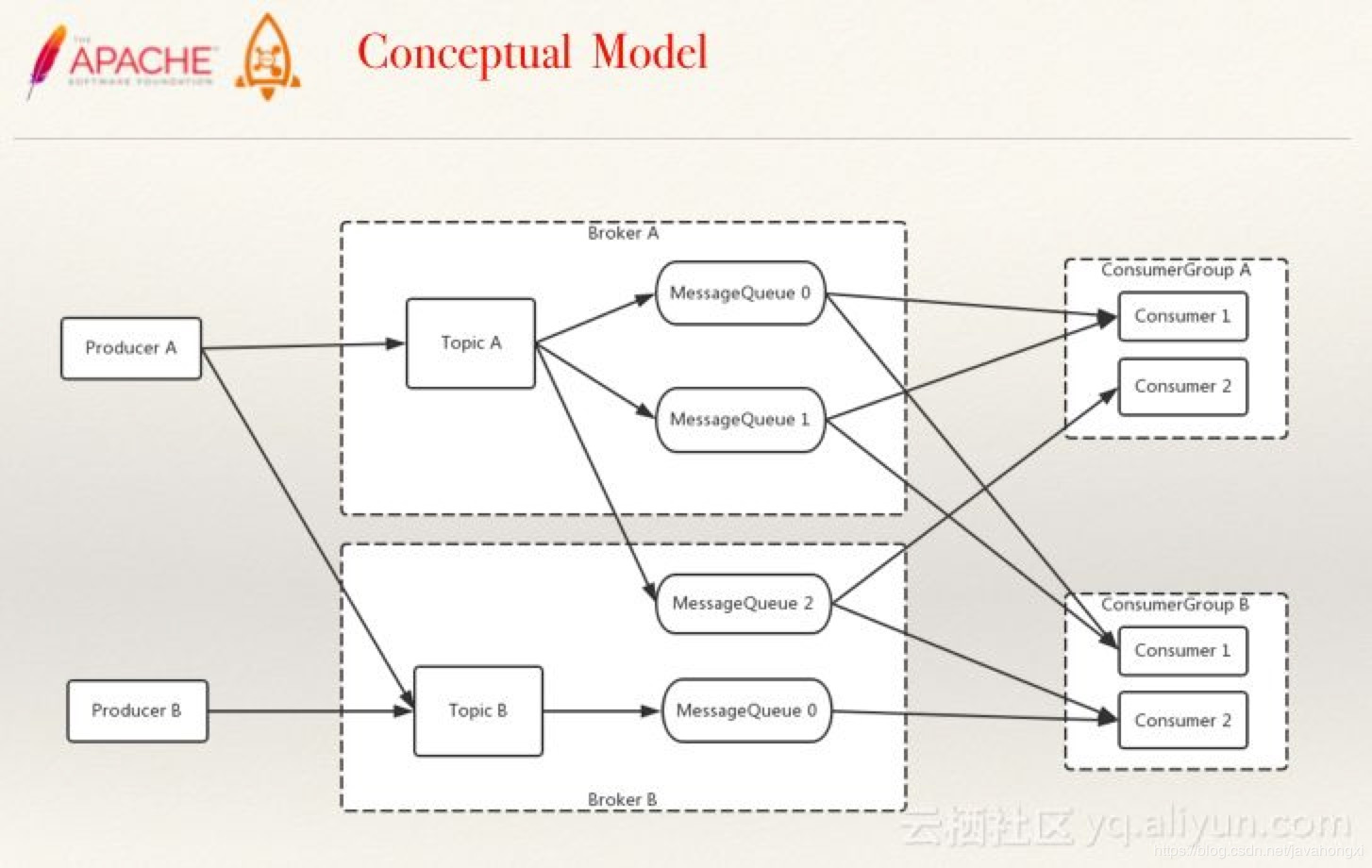
概念模型
最基本的概念模型与扩展后段概念模型
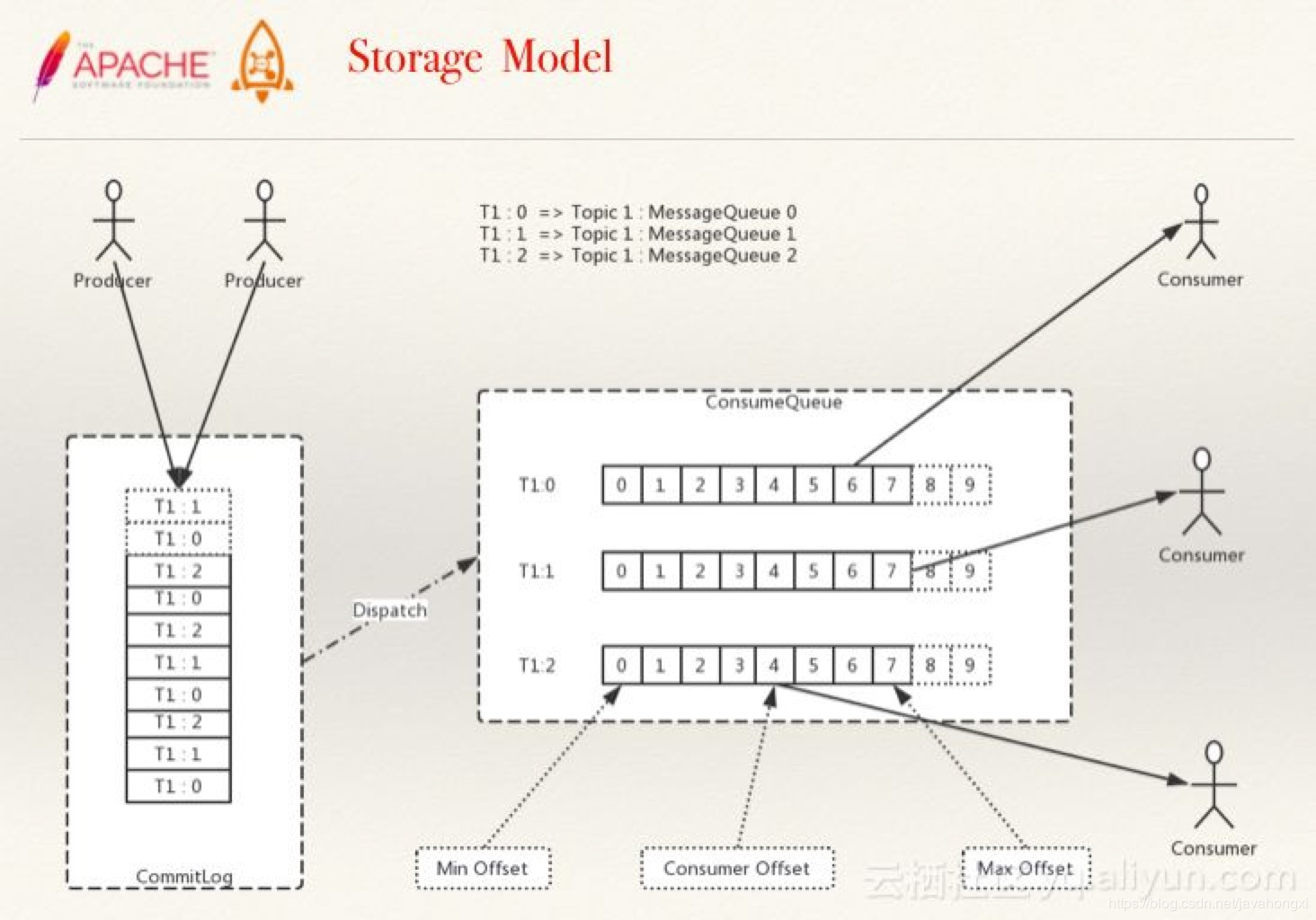
存储模型
RocketMQ吐血总结
User Guide
- RocketMQ是一款分布式消息中间件,最初是由阿里巴巴消息中间件团队研发并大规模应用于生产系统,满足线上海量消息堆积的需求, 在2016年底捐赠给Apache开源基金会成为孵化项目,经过不到一年时间正式成为了Apache顶级项目;早期阿里曾经基于ActiveMQ研发消息系统, 随着业务消息的规模增大,瓶颈逐渐显现,后来也考虑过Kafka,但因为在低延迟和高可靠性方面没有选择,最后才自主研发了RocketMQ, 各方面的性能都比目前已有的消息队列要好,RocketMQ和Kafka在概念和原理上都非常相似,所以也经常被拿来对比;RocketMQ默认采用长轮询的拉模式, 单机支持千万级别的消息堆积,可以非常好的应用在海量消息系统中。
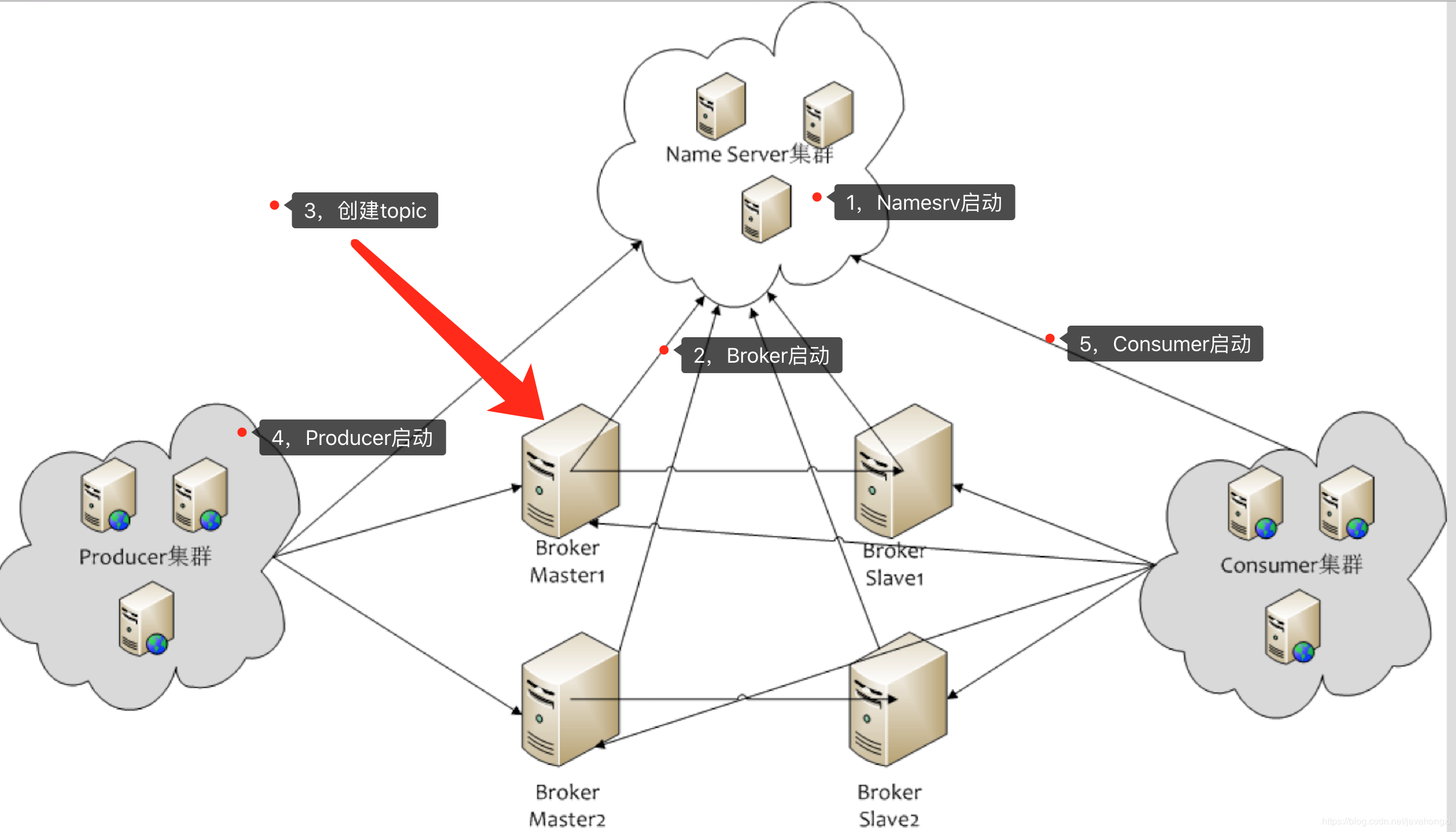
- NameServer可以部署多个,相互之间独立,其他角色同时向多个NameServer机器上报状态信息,从而达到热备份的目的。 NameServer本身是无状态的,也就是说NameServer中的Broker、Topic等状态信息不会持久存储,都是由各个角色定时上报并 存储到内存中的(NameServer支持配置参数的持久化,一般用不到)。
- 为何不用ZooKeeper?ZooKeeper的功能很强大,包括自动Master选举等,RocketMQ的架构设计决定了它不需要进行Master选举, 用不到这些复杂的功能,只需要一个轻量级的元数据服务器就足够了。值得注意的是,NameServer并没有提供类似Zookeeper的watcher机制, 而是采用了每30s心跳机制。
- 心跳机制
- 单个Broker跟所有Namesrv保持心跳请求,心跳间隔为30秒,心跳请求中包括当前Broker所有的Topic信息。Namesrv会反查Broer的心跳信息, 如果某个Broker在2分钟之内都没有心跳,则认为该Broker下线,调整Topic跟Broker的对应关系。但此时Namesrv不会主动通知Producer、Consumer有Broker宕机。
- Consumer跟Broker是长连接,会每隔30秒发心跳信息到Broker。Broker端每10秒检查一次当前存活的Consumer,若发现某个Consumer 2分钟内没有心跳, 就断开与该Consumer的连接,并且向该消费组的其他实例发送通知,触发该消费者集群的负载均衡(rebalance)。
- 生产者每30秒从Namesrv获取Topic跟Broker的映射关系,更新到本地内存中。再跟Topic涉及的所有Broker建立长连接,每隔30秒发一次心跳。 在Broker端也会每10秒扫描一次当前注册的Producer,如果发现某个Producer超过2分钟都没有发心跳,则断开连接。
- Namesrv压力不会太大,平时主要开销是在维持心跳和提供Topic-Broker的关系数据。但有一点需要注意,Broker向Namesrv发心跳时, 会带上当前自己所负责的所有Topic信息,如果Topic个数太多(万级别),会导致一次心跳中,就Topic的数据就几十M,网络情况差的话, 网络传输失败,心跳失败,导致Namesrv误认为Broker心跳失败。
- 每个主题可设置队列个数,自动创建主题时默认4个,需要顺序消费的消息发往同一队列,比如同一订单号相关的几条需要顺序消费的消息发往同一队列, 顺序消费的特点的是,不会有两个消费者共同消费任一队列,且当消费者数量小于队列数时,消费者会消费多个队列。至于消息重复,在消 费端处理。RocketMQ 4.3+支持事务消息,可用于分布式事务场景(最终一致性)。
- 关于queueNums:
- 客户端自动创建,Math.min算法决定最多只会创建8个(BrokerConfig)队列,若要超过8个,可通过控制台创建/修改,Topic配置保存在store/config/topics.json
- 消费负载均衡的最小粒度是队列,Consumer的数量应不大于队列数
- 读写队列数(writeQueueNums/readQueueNums)是RocketMQ特有的概念,可通过console修改。当readQueueNums不等于writeQueueNums时,会有什么影响呢?
-
topicRouteData = this.mQClientAPIImpl.getDefaultTopicRouteInfoFromNameServer(defaultMQProducer.getCreateTopicKey(), 1000 * 3);
-
if (topicRouteData != null) {
-
for (QueueData data : topicRouteData.getQueueDatas()) {
-
int queueNums = Math.min(defaultMQProducer.getDefaultTopicQueueNums(), data.getReadQueueNums());
-
data.setReadQueueNums(queueNums);
-
data.setWriteQueueNums(queueNums);
-
}
-
}
- Broker上存Topic信息,Topic由多个队列组成,队列会平均分散在多个Broker上。Producer的发送机制保证消息尽量平均分布到 所有队列中,最终效果就是所有消息都平均落在每个Broker上。
- RocketMQ的消息的存储是由ConsumeQueue和CommitLog配合来完成的,ConsumeQueue中只存储很少的数据,消息主体都是通过CommitLog来进行读写。 如果某个消息只在CommitLog中有数据,而ConsumeQueue中没有,则消费者无法消费,RocketMQ的事务消息实现就利用了这一点。
- CommitLog:是消息主体以及元数据的存储主体,对CommitLog建立一个ConsumeQueue,每个ConsumeQueue对应一个(概念模型中的)MessageQueue,所以只要有 CommitLog在,ConsumeQueue即使数据丢失,仍然可以恢复出来。
- ConsumeQueue:是一个消息的逻辑队列,存储了这个Queue在CommitLog中的起始offset,log大小和MessageTag的hashCode。每个Topic下的每个Queue都有一个对应的 ConsumeQueue文件,例如Topic中有三个队列,每个队列中的消息索引都会有一个编号,编号从0开始,往上递增。并由此一个位点offset的概念,有了这个概念,就可以对 Consumer端的消费情况进行队列定义。
- RocketMQ的高性能在于顺序写盘(CommitLog)、零拷贝和跳跃读(尽量命中PageCache),高可靠性在于刷盘和Master/Slave,另外NameServer 全部挂掉不影响已经运行的Broker,Producer,Consumer。
- 发送消息负载均衡,且发送消息线程安全(可满足多个实例死循环发消息),集群消费模式下消费者端负载均衡,这些特性加上上述的高性能读写, 共同造就了RocketMQ的高并发读写能力。
- 刷盘和主从同步均为异步(默认)时,broker进程挂掉(例如重启),消息依然不会丢失,因为broker shutdown时会执行persist。 当物理机器宕机时,才有消息丢失的风险。另外,master挂掉后,消费者从slave消费消息,但slave不能写消息。
- RocketMQ具有很好动态伸缩能力(非顺序消息),伸缩性体现在Topic和Broker两个维度。
- Topic维度:假如一个Topic的消息量特别大,但集群水位压力还是很低,就可以扩大该Topic的队列数,Topic的队列数跟发送、消费速度成正比。
- Broker维度:如果集群水位很高了,需要扩容,直接加机器部署Broker就可以。Broker起来后向Namesrv注册,Producer、Consumer通过Namesrv 发现新Broker,立即跟该Broker直连,收发消息。
- Producer: 失败默认重试2次;sync/async;ProducerGroup,在事务消息机制中,如果发送消息的producer在还未commit/rollback前挂掉了,broker会在一段时间后回查ProducerGroup里的其他实例,确认消息应该commit/rollback
- Consumer: DefaultPushConsumer/DefaultPullConsumer,push也是用pull实现的,采用的是长轮询方式;CLUSTERING模式下,一条消息只会被ConsumerGroup里的一个实例消费,但可以被多个不同的ConsumerGroup消费,BROADCASTING模式下,一条消息会被ConsumerGroup里的所有实例消费。
- DefaultPushConsumer: Broker收到新消息请求后,如果队列里没有新消息,并不急于返回,通过一个循环不断查看状态,每次waitForRunning一段时间(5s),然后在check。当一直没有新消息,第三次check时,等待时间超过suspendMaxTimeMills(15s),就返回空结果。在等待的过程中,Broker收到了新的消息后会直接调用notifyMessageArriving返回请求结果。“长轮询”的核心是,Broker端Hold住(挂起)客户端客户端过来的请求一小段时间,在这个时间内有新消息到达,就利用现有的连接立刻返回消息给Consumer。“长轮询”的主动权还是掌握在Consumer手中,Broker即使有大量消息积压,也不会主动推送给Consumer。长轮询方式的局限性,是在Hold住Consumer请求的时候需要占用资源,它适合用在消息队列这种客户端连接数可控的场景中。
- DefaultPullConsumer: 需要用户自己处理遍历MessageQueue、保存Offset,所以PullConsumer有更多的自主性和灵活性。
- 对于集群模式的非顺序消息,消费失败默认重试16次,延迟等级为3~18。(messageDelayLevel = "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h")
- MQClientInstance是客户端各种类型的Consumer和Producer的底层类,由它与NameServer和Broker打交道。如果创建Consumer或Producer 类型的时候不手动指定instanceName,进程中只会有一个MQClientInstance对象,即当一个Java程序需要连接多个MQ集群时,必须手动指定不同的instanceName。需要一提的是,当消费者(不同jvm实例)都在同一台物理机上时,若指定instanceName,消费负载均衡将失效(每个实例都将消费所有消息)。另外,在一个jvm里模拟集群消费时,必须指定不同的instanceName,否则启动时会提示ConsumerGroup已存在。
More
- RocketMQ架构模块解析
- RocketMQ高并发读写
- RocketMQ消费失败重试深入分析
- 《RocketMQ实战与原理解析》
douban.com - 代码实战 https://github.com/javahongxi/whatsmars/tree/master/whatsmars-mq
原文总结:https://blog.csdn.net/javahongxi/article/details/84931747
RocketMQ吐血总结的更多相关文章
- 常用FTP命令 1. 连接ftp服务器
1. 连接ftp服务器 格式:ftp [hostname| ip-address]a)在linux命令行下输入: ftp 192.168.1.1 b)服务器询问你用户名和密码,分别输入用户名和相应密码 ...
- 消息队列面试题、RabbitMQ面试题、Kafka面试题、RocketMQ面试题 (史上最全、持续更新、吐血推荐)
文章很长,建议收藏起来,慢慢读! 疯狂创客圈为小伙伴奉上以下珍贵的学习资源: 疯狂创客圈 经典图书 : <Netty Zookeeper Redis 高并发实战> 面试必备 + 大厂必备 ...
- JVM面试题(史上最强、持续更新、吐血推荐)
文章很长而且持续更新,建议收藏起来,慢慢读! 高并发 发烧友社群:疯狂创客圈(总入口) 奉上以下珍贵的学习资源: 疯狂创客圈 经典图书 : 极致经典 + 社群大片好评 < Java 高并发 三部 ...
- Java基础面试题(史上最全、持续更新、吐血推荐)
文章很长,建议收藏起来,慢慢读! 疯狂创客圈为小伙伴奉上以下珍贵的学习资源: 疯狂创客圈 经典图书 : <Netty Zookeeper Redis 高并发实战> 面试必备 + 大厂必备 ...
- Java算法面试题(史上最强、持续更新、吐血推荐)
文章很长,建议收藏起来,慢慢读! 疯狂创客圈为小伙伴奉上以下珍贵的学习资源: 疯狂创客圈 经典图书 : <Netty Zookeeper Redis 高并发实战> 面试必备 + 大厂必备 ...
- SpringBoot面试题 (史上最全、持续更新、吐血推荐)
文章很长,建议收藏起来,慢慢读! 疯狂创客圈为小伙伴奉上以下珍贵的学习资源: 疯狂创客圈 经典图书 : <Netty Zookeeper Redis 高并发实战> 面试必备 + 大厂必备 ...
- Redis 面试题 - 收藏版 (持续更新、吐血推荐)
文章很长,建议收藏起来,慢慢读! 疯狂创客圈为小伙伴奉上以下珍贵的学习资源: 疯狂创客圈 经典图书 : <Netty Zookeeper Redis 高并发实战> 面试必备 + 大厂必备 ...
- Zookeeper 面试题(持续更新、吐血推荐)
文章很长,建议收藏起来,慢慢读! 疯狂创客圈为小伙伴奉上以下珍贵的学习资源: 疯狂创客圈 经典图书 : <Netty Zookeeper Redis 高并发实战> 面试必备 + 大厂必备 ...
- Linux面试题(史上最全、持续更新、吐血推荐)
文章很长,建议收藏起来,慢慢读! 疯狂创客圈为小伙伴奉上以下珍贵的学习资源: 疯狂创客圈 经典图书 : <Netty Zookeeper Redis 高并发实战> 面试必备 + 大厂必备 ...
随机推荐
- oracle 获取时间
1.获取当前时间的前24小时的各小时时间段 select to_char(to_date(to_char(sysdate ) ,'yyyy-mm-dd hh24') || ':00:00','yyyy ...
- vue中使用iconfont和在旧有的iconfont中添加新的图标
todo 使用参考:https://blog.csdn.net/qq_34802010/article/details/81451278 大体步骤是正确的,具体可参考官方文档和下载下来的代码中的dem ...
- C++入门经典-例6.2-将二维数组进行行列对换
1:一维数组的初始化有两种,一种是单个逐一赋值,一种是使用聚合方式赋值.聚合方式的例子如下: int a[3]={1,2,3}; int a[]={1,2,3};//编译器能够获得数组元素的个数 in ...
- JS基础_Null和Undefind
1.Null Null类型的值只有一个值,就是null null专门用来表示一个为空的对象 var a=null; console.log(a);//nulltypeof a //object 2.U ...
- 【Spark机器学习速成宝典】模型篇02逻辑斯谛回归【Logistic回归】(Python版)
目录 Logistic回归原理 Logistic回归代码(Spark Python) Logistic回归原理 详见博文:http://www.cnblogs.com/itmorn/p/7890468 ...
- 一起学vue指令之v-html
一起学vue指令之v-html 一起学 vue指令 v-html 指令可看作标签属性 某些情况下,我们点击百度搜索下一页,服务器应该就返回下一页的数据页面,包含其他资源链接等. 返回的数据的本质是一 ...
- String 类源码分析
String 源码分析 String 类代表字符序列,Java 中所有的字符串字面量都作为此类的实例. String 对象是不可变的,它们的值在创建之后就不能改变,因此 String 是线程安全的. ...
- Ubuntu16.04小白入门分享之 玩转Ruby你需要安装什么软件(持续更新)
Ubuntu提示功能很强大,一般如果你想安装什么软件,可以直接输入名字,然后会有提示,安装格式一般为: sudo apt install 名字 Ubuntu14.04/16.04命令行快速安装Ruby ...
- apache虚拟目录配置实例
apache虚拟目录配置实例 一.首先,开启虚拟主机配置 在文件httpd.conf中找到: include conf/extra/httpd-vhosts.conf #开启 二.对httpd-vho ...
- 数据测试002:利用Jmeter推送测试数据(上)
数据测试002:利用Jmeter推送测试数据(上) 刚才用Jmeter配置一下MySQL数据库花了点时间,好在最后都解决了,注意下面几个问题: 1)没有配置 “Cannot load JDBC dr ...