python学习之socket&黏包
7.4 socket
【重要】
避免学习各层的接口,以及协议的使用, socket已经封装好了所有的接口,直接使用这些接口或者方法即可,方便快捷,提升开发效率。
socket在python中就是一个模块,通过使用学习模块提供的功能,建立两个进程之间的连接和通信(ip+port)。
流程图
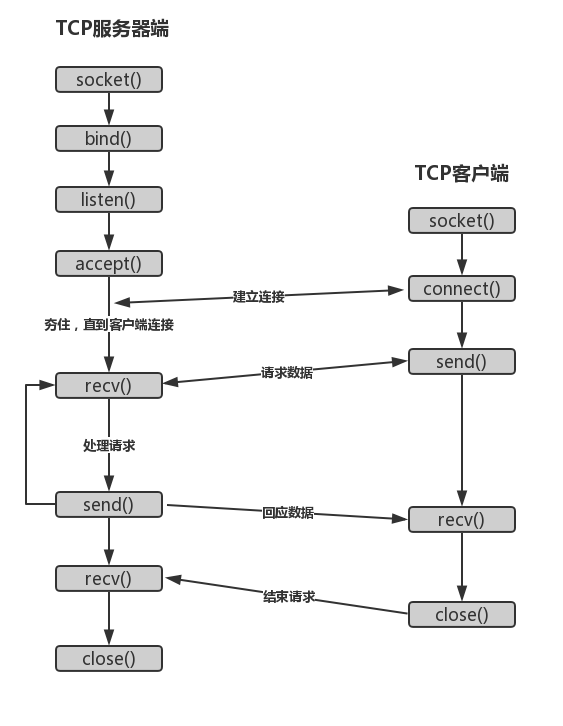
服务器端先初始化socket,然后绑定bind端口,对端口进行监听listen,调用accept夯住程序,等待客户端连接;客户端初始化socket,connect服务器,连接成功后,客户端向服务器端发送数据,服务器端接收后返回数据,客户端读取数据,请求关闭,一次交互结束。
socket模块
循环通信
# 服务器端
import socket
server = socket.socket() # 创建server服务端,可以不写,默认是socket.AF_INET,socket.SOCK_STREAM
server.bind(('127.0.0.1',8003)) # 绑定IP地址和端口
server.listen(5) # 设置最大连接数
print('listening')
conn,addr = server.accept() # 进入监听状态
while 1:
from_client_data = conn.recv(1024).decode('utf-8') # 设置最大字节数
if from_client_data.upper() == 'Q': #判断对方是否要求关闭连接
break
else:
print(f"来自{addr}的消息:\033[1;32m{from_client_data}\033[0m")
se = input('>>>').encode('utf-8')
conn.send(se)
conn.close() # 关闭连接
server.close() # 关闭服务端
# 客户端
import socket
client = socket.socket() # 可以不写,默认是socket.AF_INET,socket.SOCK_STREAM
client.connect(('127.0.0.1',8003)) # 与服务器建立连接,ip地址与端口号必须要与服务器端一致
while 1:
se = input('>>>')
if se.upper() == 'Q':
client.send('q'.encode('utf-8'))
break
client.send(se.encode('utf-8'))
from_server_data = client.recv(1024) # 设置最大字节数
print(f"来自服务器的消息:\033[1;32m {from_server_data.decode('utf-8')}\033[0m")
client.close()
服务器一直监听版【重要】
# 服务器端
import socket
server = socket.socket()
server.bind(('127.0.0.1',8003))
server.listen(5)
print('listening')
while 1:
conn,addr = server.accept()
while 1:
try :
from_client_data = conn.recv(1024).decode('utf-8')
if from_client_data.upper() == 'Q':
break
else:
print(f"来自{addr}的消息:\033[1;32m{from_client_data}\033[0m")
se = input('>>>').encode('utf-8')
conn.send(se)
except ConnectionResetError:
break
conn.close()
server.close()
# 客户端
import socket
client = socket.socket()
client.connect(('127.0.0.1',8003))
while 1:
se = input('>>>')
if se.upper() == 'Q':
client.send('q'.encode('utf-8'))
break
client.send(se.encode('utf-8'))
from_server_data = client.recv(1024).decode('utf-8')
print(f"来自服务器的消息:\033[1;32m{from_server_data}\033[0m")
client.close()
# 这里要注意多client同时访问server时,会按照顺序,断开一个连接后继续下一个连接
远程执行命令
subprocess应用,创建进程
import subprocess
obj = subprocess.Popen('dir',
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
print(obj.stdout.read().decode('gbk')) # 正确命令
print('error:',obj.stderr.read().decode('gbk')) # 错误命令
远程使用
import socket
import subprocess
server = socket.socket()
server.bind(('127.0.0.1',8004))
server.listen(5)
print('listening')
while 1:
conn,addr = server.accept()
while 1:
rec = conn.recv(1024).decode('utf-8')
if rec.upper() == 'Q':
break
else:
obj = subprocess.Popen(rec,
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
se = obj.stdout.read().decode('gbk')+obj.stderr.read().decode('gbk')
conn.send(se.encode('utf-8'))
conn.close()
server.closed()
import socket
client = socket.socket()
client.connect(('127.0.0.1',8004))
while 1:
se = input('请输入命令')
if se.upper() == 'Q':
client.send('q'.encode('utf-8'))
break
else:
client.send(se.encode('utf-8'))
re = client.recv(1024).decode('utf-8')
print(re)
client.close()
# 如果返回的数据过多,会有黏包现象
7.5 黏包
产生原因
缓冲区
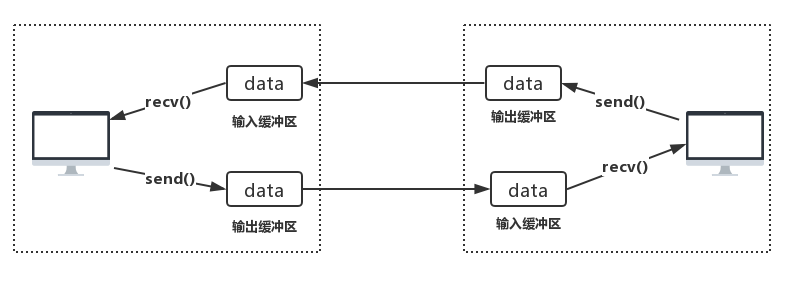
如果没有缓冲区,收发数据会受到网络波动的影响,影响数据的上传和下载
虽然缓冲区解决了上传下载的传输的效率问题,但是黏包问题
产生条件
1.recv会产生黏包。如果recv接受的数据 < 缓冲区的数据,缓冲区中接受不完的数据会与后边recv的数据黏在一起,流式数据
2.连续send少量的数据,先到缓存区。由于Nagle的算法,发送端发送的数据如果比较小,会暂存在缓冲区,再加上应用层给TCP传送数据很快的话,就会把两个应用层数据包黏在一起,TCP最后只发一个TCP数据包给接收端
解决方案
struct模块
按照指定的格式把一个python类型转换成固定长度的bytes字节流
| 格式 | C语言类型 | Python类型 | 标准尺寸 |
|---|---|---|---|
| x | 填充字节 | 没有值 | |
| c | char | string of length 1 | 1 |
| b | signed | integer | 1 |
| B | unsigned char | integer | 1 |
| ? | _Bool | bool | 1 |
| h | short | integer | 2 |
| H | unsigned short | integer | 2 |
| i | int | integer | 4 |
| I | unsigned int | integer | 4 |
| l | long | integer | 4 |
| L | unsigned long | long | 4 |
| q | long long | long | 8 |
| Q | unsigned long long | long | 8 |
| n | ssize_t | intter | |
| N | size_t | intter | |
| f | float | float | 4 |
| d | double | float | 8 |
| s | char[] | string | |
| p | char[] | string | |
| P | void * | long |
import struct
# 将一个数字转化成等长度的bytes类型。
ret = struct.pack('q', 154365400024634546545646546)
print(ret, type(ret), len(ret))
# 通过unpack反解回来
ret1 = struct.unpack('i',ret)[0]
print(ret1)
方案一:
1.在第二次向对方发送数据之前,先把缓冲区的数据全部取出
2.如何限制循环次数?当接收数据的总字节数数等于发送数据的总字节数时,停止循环;
3.服务端先send要发送数据的总字节数;
4.发送端制作报头,固定头部长度,使用struct模块,pack转换成等长度4个字节bytes类型,发送到接收端,接收端再使用unpack将字节数转换回来;
代码实现
服务器端
import socket
import subprocess
import struct
server = socket.socket()
server.bind(('127.0.0.1',8004))
server.listen(5)
print('listening')
# 接收连接
while 1:
conn,addr = server.accept()
while 1:
rec = conn.recv(1024).decode('utf-8')
obj = subprocess.Popen(rec,
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
se = obj.stdout.read().decode('gbk')+obj.stderr.read().decode('gbk')
# 制作报头
total_size = len(se)
# 将长度不固定的int类型报头,转成固定长度bytes4个字节
# 将一个数字转换成等长度的bytes类型
total_size_bytes = struct.pack('i',total_size)
# 发送报头
conn.send(total_size_bytes)
# 发送原始数据
conn.send(se.encode('gbk'))
conn.close()
server.closed()
客户端
import struct
import socket
client = socket.socket()
client.connect(('127.0.0.1',8004))
# 发送消息
while 1:
se = input('请输入命令')
client.send(se.encode('utf-8'))
# 1-接收报头
head_bytes = client.recv(4)
# 2-将报头反解回int类型
total_size = struct.unpack('i',head_bytes)[0] #unpack返回的一个元组,里边只有一个反解的元素
# 3-循环接收数据
total_data = b'' #设定一个初始值
while len(total_data.decode('gbk')) < total_size:
total_data += client.recv(1024)
print(total_data.decode('gbk'))
client.close()
存在的问题:
数据量较大的数据,使用struct时会报错;
报头信息不可能只含有数据的大小;
方案二:
为了解决以上问题,我们引入方案二:
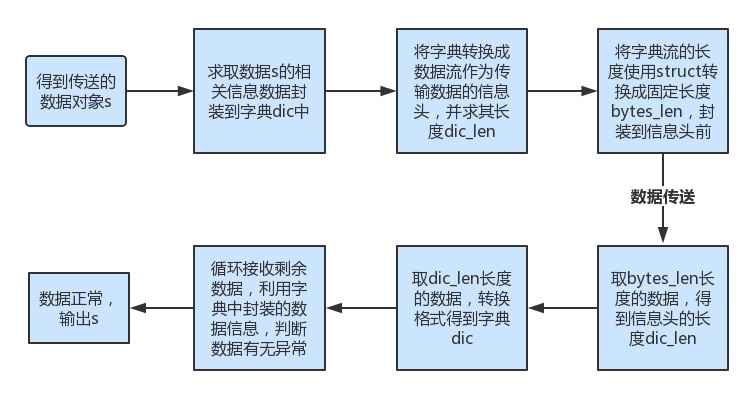
自定义一种传输报文:
- 将传送数据的信息汇集成字典,字典中记录了传输数据的MD5值,filename以及filesize,使用json模块把字典转换成bytes类型,将其加到传输数据流的字典头;
- 记录字典bytes的长度,使用struct模块转成4字节的固定长度,然后把它作为长度头加到数据流的最开始;
- 将 [长度头+字典头+传输数据] 一起发送给对方
- 对方接到数据流之后,首先取4个字节,求出字典头的长度;取字典头长度的数据,进行格式转换,得到字典;
- 循环接收数据,将得到的数据流与字典中的MD5进行校验,校验通过,转码显示数据,校验不通过,则不显示;
服务器端
while 1:
conn, addr = server.accept()
while 1:
try :
re = conn.recv(1024).decode('gbk')
obj = subprocess.Popen(re,
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
result = obj.stdout.read() + obj.stderr.read() # 获得的是gbk转码后的数据
size = len(result) #求原数据的大小
# 做一下文件校验的MD5序列
ret = hashlib.md5()
ret.update(result)
md5 = ret.hexdigest()
# 制作报头
head_dict = {
'md5':md5,
'filename':re,
'filesize':size
}
# 将报头字典转换成json序列
head_dict_json = json.dumps(head_dict)
# 将json字符串转换成bytes
head_dict_json_bytes = head_dict_json.encode('gbk')
# 获取报头的长度
head_len = len(head_dict_json_bytes)
# 将head_len转成固定长度
head_len_bytes = struct.pack('i',head_len)
# 发送固定的4个字节
conn.send(head_len_bytes)
# 发送字典报头
conn.send(head_dict_json_bytes)
# 发送文件
conn.send(result)
except Exception:
break
conn.close()
server.close()
客户端
import socket
import struct
import json
import hashlib
client = socket.socket()
client.connect(('127.0.0.1',8005))
while 1:
se = input('>>>').strip().encode('gbk')
client.send(se)
# 接受4个字节,获得头部的字典长度
head_bytes = client.recv(4)
# 将字典长度转成int类型
head_dic_len = struct.unpack('i',head_bytes)[0]
# 接收字典的数据流
head_dic_bytes = client.recv(head_dic_len).decode('gbk')
# 转换成字典模式
head_dict = json.loads(head_dic_bytes)
# 定义一个接收主内容的句柄
file = b''
while len(file) < head_dict['filesize']:
file += client.recv(1024)
# 计算一下file的MD5
ret = hashlib.md5()
ret.update(file)
md_5 = ret.hexdigest()
if md_5 == head_dict['md5']:
print('文件校验成功')
print(file.decode('gbk'))
else:
print('文件校验未通过')
break
client.close()
python学习之socket&黏包的更多相关文章
- Python学习笔记【第十四篇】:Python网络编程二黏包问题、socketserver、验证合法性
TCP/IP网络通讯粘包问题 案例:模拟执行shell命令,服务器返回相应的类容.发送指令的客户端容错率暂无考虑,按照正确的指令发送即可. 服务端代码 # -*- coding: utf- -*- # ...
- Python网络编程之黏包问题
二.解决黏包问题 2.1 解决黏包方法1 计算消息实体的大小 服务端接受两次,一次时消息大小,二次是消息实体,解决消息实体黏包 客户端发送两次,一次是消息大小,一次是消息实体 在两次收发之间加入一次多 ...
- day 24 socket 黏包
socket 套接字的使用: tcp是基于链接的,必须先启动服务端,然后再启动客户端去链接服务端 server 端 import socket sk = socket.socket() # 实例化一个 ...
- python学习笔记 - socket通信
socket socket通常也称作"套接字",用于描述IP地址和端口,是一个通信链的句柄,应用程序通常通过"套接字"向网络发出请求或者应答网络请求. sock ...
- Python学习-day8 socket进阶
还是继续socket网络编程的学习. socket.socket(family=AF_INET, type=SOCK_STREAM, proto=0, fileno=None) Socket Fami ...
- 百万年薪python之路 -- socket粘包问题解决
socket粘包问题解决 1. 高大上版解决粘包方式(自定制包头) 整体的流程解释 整个流程的大致解释: 我们可以把报头做成字典,字典里包含将要发送的真实数据的描述信息(大小啊之类的),然后json序 ...
- python学习笔记-socket
socket socket通常也称作"套接字",用于描述IP地址和端口,是一个通信链的句柄,应用程序通常通过"套接字"向网络发出请求或者应答网络请求. sock ...
- python学习记录-socket模块
主要使用的模块是socket模块,在这个模块中可以找到socket()函数,该函数用于创建套接字对象.套接字也有自己的方法集,这些方法可以实现基于套接字的网络通信. 1.socket类型 构造函数: ...
- Python学习之==>Socket网络编程
一.计算机网络 多台独立的计算机通过网络通信设备连接起来的网络.实现资源共享和数据传递.在同一台电脑上可以将D盘上的一个文件传到C盘,但如果想从一台电脑传一个文件到另外一台电脑上就要通过计算机网络 二 ...
随机推荐
- UVA - 11996 Jewel Magic (Treap+二分哈希)
维护一个01序列,一共四种操作: 1.插入一个数 2.删除一个数 3.反转一个区间 4.查询两个后缀的LCP 用Splay或者Treap都可以做,维护哈希值,二分求LCP即可. 注意反转序列的时候序列 ...
- 【hiho1715】树的联通问题
题目大意:给定一棵 1~n 标号的树.Tree[L,R]表示最少需要选择的边的数量使得 L~R 号点两两连通.求: \[ \sum_{L=1}^{n} \sum_{R=L}^{n} \operator ...
- PowerDesigner 生成SQL Server 注释脚本
--生成数据表的注释EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=[%R%?[N]]%.q:COMMENT% , @l ...
- IDEA中方法的快捷键及自定义方法
1. 字母组合联想到对应的方法 ·ps联想到public static方法和成员 ·输入psvm联想到主方法 ·输入psf联想到用public static final 等 · pc联想到clone和 ...
- fedora29 下一款截图工具shutter的安装和调试
运行命令安装shutter sudo yum install shutter 如果使用过程中出现花屏 sudo vim /etc/gdm/custom.conf 把 #WaylandEnabled=f ...
- python连接mysql操作(1)
python连接mysql操作(1) import pymysql import pymysql.cursors # 连接数据库 connect = pymysql.Connect( host='10 ...
- MySQL--关于MySQL练习过程中遇到的AVG()函数处理空值的问题
最近正准备面试,所以本来不怎么熟悉的SQL语句迫切需要练习,学习一下 在此感谢 笨鸟先飞-天道酬勤 大佬的博客:https://blog.csdn.net/dehu_zhou/article/deta ...
- “==”与equals方法
“==”操作符 基本类型比较值:判断两个变量的值相等. 引用类型比较引用(是否指向同一个对象):只有指向同一个对象时才相等. 用“==”进行比较时,两边的数据类型必须兼容(可自动转换的基本数据类型除外 ...
- Java枚举类的7种常用的方法
转载于:https://www.cnblogs.com/xhlwjy/p/11314368.html
- .netcore mongodb 分页+模糊查询+多条件查询
.netcore MongoDB.Driver 版本才2.8 与aspnet差距太大,网上找很多资料没有现成的代码. public override async Task<PagerList&l ...