logstash之OutPut插件
output插件是经过了input,然后过滤结构化数据之后,接下来我们需要借助output传到我们想传到的地方.output相当于一个输出管道。
2.3.1: 将采集数据标准输出到控制台
配置示例:
output {
stdout {
codec => rubydebug
}
}
Codec 来自 Coder/decoder
两个单词的首字母缩写,Logstash 不只是一个input | filter | output 的数据流,
而是一个input | decode | filter | encode | output 的数据流,codec 就是用来decode、encode 事件的。
简单说,就是在logstash读入的时候,通过codec编码解析日志为相应格式,从logstash输出的时候,通过codec解码成相应格式。
演示:
input {stdin{}}
output {
stdout {
codec => rubydebug
}
}
启动:bin/logstash -f /usr/local/elk/logstash-5.5.2/conf/template/stdout.conf
展示:

2.3.2:将采集数据保存到file文件中
通过日志收集系统将分散在数百台服务器上的数据集中存储在某中心服务器上,这是运维最原始的需求;
需求:将数据采集到logstash的日志文件中,区分业务和采集日期(哪天采集的)
input {stdin{}}
output {
file {
path => "/home/angel/logstash-5.5.2/logs/stdout/mobile-collection/%{+YYYY-MM-dd}-%{host}.txt"
codec => line {
format => "%{message}"
}
gzip => true
}
}
启动:
bin/logstash -f /home/angel/servers/logstash-5.5.2/logstash_conf/stdout_file.conf
2.3.3:将采集数据保存到elasticsearch
Logstash可以直接将采集到的信息下沉到elasticsearch中
input {stdin{}}
output {
elasticsearch {
hosts => ["hadoop01:9200"]
index => "logstash-%{+YYYY.MM.dd}" #这个index是保存到elasticsearch上的索引名称,如何命名特别重要,因为我们很可能后续根据某些需求做查询,所以最好带时间,因为我们在中间加上type,就代表不同的业务,这样我们在查询当天数据的时候,就可以根据类型+时间做范围查询
flush_size => 20000 #表示logstash的包数量达到20000个才批量提交到es.默认是500
idle_flush_time => 10 #多长时间发送一次数据,flush_size和idle_flush_time以定时定量的方式发送,按照批次发送,可以减少logstash的网络IO请求
user => elastic
password => changeme
}
}
启动:bin/logstash -f /usr/local/elk/logstash-5.5.2/conf/template/stdout_es.conf
向控制台中输入6条数据:
192.168.77.1 - - [10/Apr/2018:00:44:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 505 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.2 - - [10/Apr/2018:00:45:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 460 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.3 - - [10/Apr/2018:00:46:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 510 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.4 - - [10/Apr/2018:00:47:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 112 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.5 - - [10/Apr/2018:00:48:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 455 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.6 - - [10/Apr/2018:00:49:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 653 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
2.3.4:将采集的数据保存到redis
配置:
input { stdin {} }
output {
redis {
host => "hadoop01"
data_type => "list"
db => 2
port => "6379"
key => "logstash-chan-%{+yyyy.MM.dd}"
}
}
数据落地到redis的优化:
• 批处理类(仅用于data_type为list)
o batch:设为true,通过发送一条rpush命令,存储一批的数据
o 默认为false:1条rpush命令,存储1条数据
o 设为true之后,1条rpush会发送batch_events条数据
o batch_events:一次rpush多少条
o 默认50条
o batch_timeout:一次rpush最多消耗多少s
o 默认5s
• 拥塞保护(仅用于data_type为list)
o congestion_interval:每隔多长时间进行一次拥塞检查
o 默认1s
o 设为0,表示对每rpush一个,都进行检测
o congestion_threshold:list中最多可以存在多少个item数据
o 默认是0:表示禁用拥塞检测
o 当list中的数据量达到congestion_threshold,会阻塞直到有其他消费者消费list中的数据
o 作用:防止OOM
启动redis 将数据打入logstash控制台:
192.168.77.1 - - [10/Apr/2018:00:44:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 505 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.2 - - [10/Apr/2018:00:45:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 460 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.3 - - [10/Apr/2018:00:46:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 510 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.4 - - [10/Apr/2018:00:47:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 112 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.5 - - [10/Apr/2018:00:48:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 455 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.6 - - [10/Apr/2018:00:49:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 653 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
去redis上做认证,查看是否已经存储redis中:
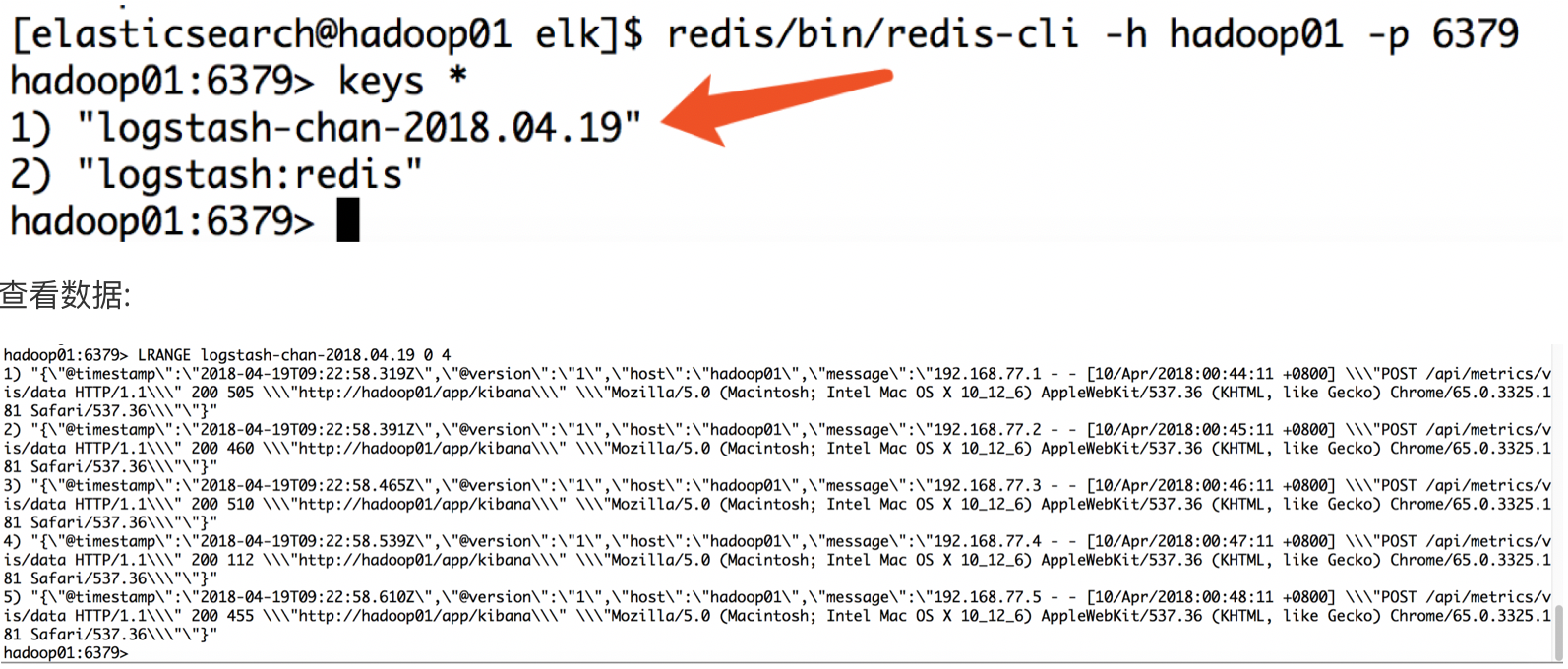
logstash之OutPut插件的更多相关文章
- logstash的output插件
logstash 的output插件 nginx,logstash和redis在同一台机子上 yum -y install redis,vim /etc/redis.conf 设置bind 0.0.0 ...
- 五十八.Kibana使用 、 Logstash配置扩展插件
1.导入数据 批量导入数据并查看 1.1 导入数据 1) 使用POST方式批量导入数据,数据格式为json,url 编码使用data-binary导入含有index配置的json文件 ]# ...
- 使用logstash的grok插件解析springboot日志
使用logstash的grok插件解析springboot日志 一.背景 二.解决思路 三.前置知识 四.实现步骤 1.准备测试数据 2.编写`grok`表达式 3.编写 logstash pipel ...
- logstash的output配置中指定elasticsearch的template
转自:https://blog.csdn.net/felix_yujing/article/details/78930389 之前采用的是通过filebeat收集nginx的日志,直接到elastic ...
- ELK 学习笔记之 Logstash之output配置
Logstash之output配置: 输出到file 配置conf: input{ file{ path => "/usr/local/logstash-5.6.1/bin/spark ...
- logstash之multiline插件,匹配多行日志
在外理日志时,除了访问日志外,还要处理运行时日志,该日志大都用程序写的,比如log4j.运行时日志跟访问日志最大的不同是,运行时日志是多行,也就是说,连续的多行才能表达一个意思. 在filter中,加 ...
- logstash 安装zabbix插件
<pre name="code" class="html">[root@xxyy yum.repos.d]# yum install ruby Lo ...
- Logstash使用grok插件解析Nginx日志
grok表达式的打印复制格式的完整语法是下面这样的: %{PATTERN_NAME:capture_name:data_type}data_type 目前只支持两个值:int 和 float. 在线g ...
- logstash实战filter插件之grok(收集apache日志)
有些日志(比如apache)不像nginx那样支持json可以使用grok插件 grok利用正则表达式就行匹配拆分 预定义的位置在 /opt/logstash/vendor/bundle/jruby/ ...
随机推荐
- 小记---------maxwell启动闪退问题
日志报错信息如下:大致是说因为maxwell在对接mysql时伪装成一个从库slave,但是uuid重复.猜想是其他部门同事也在同时使用maxwell,都使用的是maxwell默认的uuid ,从而导 ...
- 小记------mongodb数据库如何进行模糊查询
// 模糊匹配createTime 是以 2019-07-23 开头 db.getCollection('driver_online_record').find({"createTime ...
- 设计模式之单例模式(Singleton Pattern)
单例模式是最简单的设计模式之一.属于创建型模式,它提供了一种创建对象的最佳方式.使应用中只存在一个对象的实例,并且使这个单实例负责所有对该对象的调用.这种模式涉及到一个单一的类,该类负责创建自己的对象 ...
- HDU-3714 Error Curves(凸函数求极值)
Error Curves Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Tota ...
- RabbitMQ入门教程(十三):虚拟主机vhost与权限管理
原文:RabbitMQ入门教程(十三):虚拟主机vhost与权限管理 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://b ...
- sql server 对数运算函数log(x)和log10(x)
--LOG(x)返回x的自然对数,x相对于基数e的对数 --LOG10(x)返回x的基数为10的对数 示例:select LOG(3),LOG(6),LOG10(1),LOG10(100),LOG10 ...
- linux复习4:文件和目录
7一.linux文件 1.linux文件的扩展名:文件扩展名是文件名最后一个点之后的部分,下面列出了其中一部分 (1)压缩文件和归档文件 压缩和归档的文件扩展名及其含义如下. .bz2:使用bzip2 ...
- 深入理解java虚拟机(2)
一.对象的访问 ----------------------------------------------------- 1.对象的访问与java栈.堆和方法区之间的关联关系. eg:Object ...
- redis、rabitmq对比
redis.rabitmq对比 原文地址 简要介绍 RabbitMQ RabbitMQ是实现AMQP(高级消息队列协议)的消息中间件的一种,最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性 ...
- Linux安装FastDFS~Nginx~
确保Linux联网,我这里使用的是CentOS7操作,联网教程 https://www.cnblogs.com/taopanfeng/p/10978752.html 先把指定的四个文件放入指定目录 安 ...