关系型数据库为什么喜欢使用B+树作为索引结构? (转)
问题1. 数据库为什么要设计索引?
图书馆存了1000W本图书,要从中找到《架构师之路》,一本本查,要查到什么时候去?
于是,图书管理员设计了一套规则:
(1)一楼放历史类,二楼放文学类,三楼放IT类…
(2)IT类,又分软件类,硬件类…
(3)软件类,又按照书名音序排序…
以便快速找到一本书。
与之类比,数据库存储了1000W条数据,要从中找到name=”shenjian”的记录,一条条查,要查到什么时候去?
于是,要有索引,用于提升数据库的查找速度。
问题2. 哈希(hash)比树(tree)更快,索引结构为什么要设计成树型?
加速查找速度的数据结构,常见的有两类:
(1)哈希,例如HashMap,查询/插入/修改/删除的平均时间复杂度都是O(1);
(2)树,例如平衡二叉搜索树,查询/插入/修改/删除的平均时间复杂度都是O(lg(n));
可以看到,不管是读请求,还是写请求,哈希类型的索引,都要比树型的索引更快一些,那为什么,索引结构要设计成树型呢?
画外音:80%的同学,面试都答不出来。
索引设计成树形,和SQL的需求相关。
对于这样一个单行查询的SQL需求:
select * from t where name=”shenjian”;
确实是哈希索引更快,因为每次都只查询一条记录。
画外音:所以,如果业务需求都是单行访问,例如passport,确实可以使用哈希索引。
但是对于排序查询的SQL需求:
分组:group by
排序:order by
比较:<、>
…
哈希型的索引,时间复杂度会退化为O(n),而树型的“有序”特性,依然能够保持O(log(n)) 的高效率。
任何脱离需求的设计都是耍流氓。
多说一句,InnoDB并不支持哈希索引。
问题3. 数据库索引为什么使用B+树?
为了保持知识体系的完整性,简单介绍下几种树。
第一种:二叉搜索树
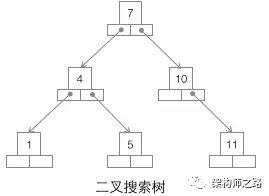
二叉搜索树,如上图,是最为大家所熟知的一种数据结构,就不展开介绍了,它为什么不适合用作数据库索引?
(1)当数据量大的时候,树的高度会比较高,数据量大的时候,查询会比较慢;
(2)每个节点只存储一个记录,可能导致一次查询有很多次磁盘IO;
画外音:这个树经常出现在大学课本里,所以最为大家所熟知。
第二种:B树
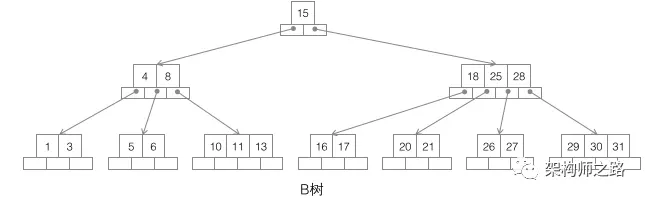
B树,如上图,它的特点是:
(1)不再是二叉搜索,而是m叉搜索;
(2)叶子节点,非叶子节点,都存储数据;
(3)中序遍历,可以获得所有节点;
画外音,实在不想介绍这个特性:非根节点包含的关键字个数j满足,(┌m/2┐)-1 <= j <= m-1,节点分裂时要满足这个条件。
B树被作为实现索引的数据结构被创造出来,是因为它能够完美的利用“局部性原理”。
什么是局部性原理?
局部性原理的逻辑是这样的:
(1)内存读写块,磁盘读写慢,而且慢很多;
(2)磁盘预读:磁盘读写并不是按需读取,而是按页预读,一次会读一页的数据,每次加载更多的数据,如果未来要读取的数据就在这一页中,可以避免未来的磁盘IO,提高效率;
画外音:通常,一页数据是4K。
(3)局部性原理:软件设计要尽量遵循“数据读取集中”与“使用到一个数据,大概率会使用其附近的数据”,这样磁盘预读能充分提高磁盘IO;
B树为何适合做索引?
(1)由于是m分叉的,高度能够大大降低;
(2)每个节点可以存储j个记录,如果将节点大小设置为页大小,例如4K,能够充分的利用预读的特性,极大减少磁盘IO;
第三种:B+树
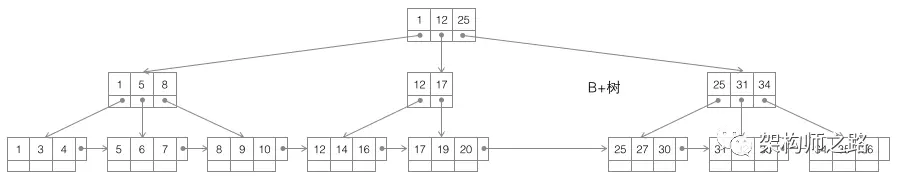
B+树,如上图,仍是m叉搜索树,在B树的基础上,做了一些改进:
(1)非叶子节点不再存储数据,数据只存储在同一层的叶子节点上;
画外音:B+树中根到每一个节点的路径长度一样,而B树不是这样。
(2)叶子之间,增加了链表,获取所有节点,不再需要中序遍历;
这些改进让B+树比B树有更优的特性:
(1)范围查找,定位min与max之后,中间叶子节点,就是结果集,不用中序回溯;
画外音:范围查询在SQL中用得很多,这是B+树比B树最大的优势。
(2)叶子节点存储实际记录行,记录行相对比较紧密的存储,适合大数据量磁盘存储;非叶子节点存储记录的PK,用于查询加速,适合内存存储;
(3)非叶子节点,不存储实际记录,而只存储记录的KEY的话,那么在相同内存的情况下,B+树能够存储更多索引;
最后,量化说下,为什么m叉的B+树比二叉搜索树的高度大大大大降低?
大概计算一下:
(1)局部性原理,将一个节点的大小设为一页,一页4K,假设一个KEY有8字节,一个节点可以存储500个KEY,即j=500
(2)m叉树,大概m/2<= j <=m,即可以差不多是1000叉树
(3)那么:
一层树:1个节点,1*500个KEY,大小4K
二层树:1000个节点,1000*500=50W个KEY,大小1000*4K=4M
三层树:1000*1000个节点,1000*1000*500=5亿个KEY,大小1000*1000*4K=4G
画外音:额,帮忙看下有没有算错。
可以看到,存储大量的数据(5亿),并不需要太高树的深度(高度3),索引也不是太占内存(4G)。
总结
数据库索引用于加速查询
虽然哈希索引是O(1),树索引是O(log(n)),但SQL有很多“有序”需求,故数据库使用树型索引
InnoDB不支持哈希索引
数据预读的思路是:磁盘读写并不是按需读取,而是按页预读,一次会读一页的数据,每次加载更多的数据,以便未来减少磁盘IO
局部性原理:软件设计要尽量遵循“数据读取集中”与“使用到一个数据,大概率会使用其附近的数据”,这样磁盘预读能充分提高磁盘IO
数据库的索引最常用B+树:
(1)很适合磁盘存储,能够充分利用局部性原理,磁盘预读;
(2)很低的树高度,能够存储大量数据;
(3)索引本身占用的内存很小;
(4)能够很好的支持单点查询,范围查询,有序性查询;
另一篇: Mysql索引原理
一、为什么要有索引
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。
索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句的优化显然是重中之重。说起加速查询,就不得不提到索引了。
二、索引的原理
一 索引原理
索引的目的在于提高查询效率,与我们查阅图书所用的目录是一个道理:先定位到章,然后定位到该章下的一个小节,然后找到页数。相似的例子还有:查字典,查火车车次,飞机航班等
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
数据库也是一样,但显然要复杂的多,因为不仅面临着等值查询,还有范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)等等。数据库应该选择怎么样的方式来应对所有的问题呢?我们回想字典的例子,能不能把数据分成段,然后分段查询呢?最简单的如果1000条数据,1到100分成第一段,101到200分成第二段,201到300分成第三段......这样查第250条数据,只要找第三段就可以了,一下子去除了90%的无效数据。
但如果是1千万的记录呢,分成几段比较好?稍有算法基础的同学会想到搜索树,其平均复杂度是lgN,具有不错的查询性能。
但这里我们忽略了一个关键的问题,复杂度模型是基于每次相同的操作成本来考虑的。而数据库实现比较复杂,一方面数据是保存在磁盘上的,另外一方面为了提高性能,每次又可以把部分数据读入内存来计算,因为我们知道访问磁盘的成本大概是访问内存的十万倍左右,所以简单的搜索树难以满足复杂的应用场景。
二 磁盘IO与预读
磁盘IO的性能开销远大于内存IO, 每次查找数据时把磁盘IO次数控制在一个很小的数量级,最好是常数数量级。
考虑到磁盘IO是非常高昂的操作,计算机操作系统做了一些优化,当一次IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。
每一次IO读取的数据我们称之为一页(page)。具体一页有多大数据跟操作系统有关,一般为4k或8k,也就是我们读取一页内的数据时候,实际上才发生了一次IO,这个理论对于索引的数据结构设计非常有帮助。
三、索引的数据结构
任何一种数据结构都不是凭空产生的,一定会有它的背景和使用场景,我们现在总结一下,我们需要这种数据结构能够做些什么,其实很简单,那就是:每次查找数据时把磁盘IO次数控制在一个很小的数量级,最好是常数数量级。那么我们就想到如果一个高度可控的多路搜索树是否能满足需求呢?就这样,b+树应运而生。
如上图,是一颗b+树,关于b+树的定义可以参见B+树,这里只说一些重点,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。
真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
b+树的查找过程
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。
真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
b+树性质
1.索引字段要尽量的小:通过上面的分析,我们知道IO次数取决于b+数的高度h,假设当前数据表的数据为N,每个磁盘块的数据项的数量是m,则有h=㏒(m+1)N,当数据量N一定的情况下,m越大,h越小;而m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。
这就是为什么每个数据项,即索引字段要尽量的小,比如int占4字节,要比bigint8字节少一半。这也是为什么b+树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于1时将会退化成线性表。
2.索引的最左匹配特性(即从左往右匹配):当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;
但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
四、Mysql索引管理
一、功能
- 索引的功能就是加速查找。
- mysql中的primary key,unique,联合唯一也都是索引,这些索引除了加速查找以外,还有约束的功能。
二、MySQL的索引分类
- 普通索引index :加速查找
- 唯一索引
- 主键索引:primary key :加速查找+约束(不为空且唯一)
- 唯一索引:unique:加速查找+约束 (唯一)
- 联合索引
- -primary key(id,name):联合主键索引
- -unique(id,name):联合唯一索引
- -index(id,name):联合普通索引
- 全文索引fulltext :用于搜索很长一篇文章的时候,效果最好。
- 空间索引spatial :了解就好,几乎不用
三、 索引的两大类型hash与btree
- 我们可以在创建上述索引的时候,为其指定索引类型,分两类
- hash类型的索引:查询单条快,范围查询慢
- btree类型的索引:b+树,层数越多,数据量指数级增长(我们就用它,因为innodb默认支持它)
- 不同的存储引擎支持的索引类型也不一样
- InnoDB 支持事务,支持行级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
- MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
- Memory 不支持事务,支持表级别锁定,支持 B-tree、Hash 等索引,不支持 Full-text 索引;
- NDB 支持事务,支持行级别锁定,支持 Hash 索引,不支持 B-tree、Full-text 等索引;
- Archive 不支持事务,支持表级别锁定,不支持 B-tree、Hash、Full-text 等索引;
四 添加索引,必须遵循原则
1.最左前缀匹配原则,非常重要的原则,
create index ix_name_email on s1(name,email,)
- 最左前缀匹配:必须按照从左到右的顺序匹配
select * from s1 where name='egon'; #可以
select * from s1 where name='egon' and email='asdf'; #可以
select * from s1 where email='alex@oldboy.com'; #不可以
mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,
比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,
d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
3.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),
表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、
性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,
这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录
4.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,
但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。
所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
count(1)或count(列) 代替 count(*)
- 创建表时尽量时 char 代替 varchar
- 表的字段顺序固定长度的字段优先
- 组合索引代替多个单列索引(经常使用多个条件查询时)
- 尽量使用短索引
- 使用连接(JOIN)来代替子查询(Sub-Queries)
- 连表时注意条件类型需一致
- 索引散列值(重复少)不适合建索引,例:性别不适合
五、慢查询优化的基本步骤
- 先运行看看是否真的很慢,注意设置SQL_NO_CACHE
- where条件单表查,锁定最小返回记录表。这句话的意思是把查询语句的where都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高
- explain查看执行计划,是否与1预期一致(从锁定记录较少的表开始查询)
- order by limit 形式的sql语句让排序的表优先查
- 了解业务方使用场景
- 加索引时参照建索引的几大原则
- 观察结果,不符合预期继续从0分析
关系型数据库为什么喜欢使用B+树作为索引结构? (转)的更多相关文章
- B-/B+树 MySQL索引结构
索引 索引的简介 简单来说,索引是一种数据结构 其目的在于提高查询效率 可以简单理解为“排好序的快速查找结构” 一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在中磁 ...
- 数据库为什么要用B+树结构--MySQL索引结构的实现(转)
B+树在数据库中的应用 { 为什么使用B+树?言简意赅,就是因为: 1.文件很大,不可能全部存储在内存中,故要存储到磁盘上 2.索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数(为什么使用B-/ ...
- 2020-05-18:MYSQL为什么用B+树做索引结构?平时过程中怎么加的索引?
福哥答案2020-05-18:此答案来自群员:因为4.0成型那个年代,B树体系大量用于文件存储系统,甚至当年的Longhorn的winFS都是基于b树做索引,开源而且好用的也就这么个体系了.B+树的磁 ...
- 数据库为什么要用B+树结构--MySQL索引结构的实现
原理: http://blog.csdn.net/cangchen/article/details/44818485 http://blog.csdn.net/kennyrose/article/de ...
- MySQL系列(十二)--如何设计一个关系型数据库(基本思路)
设计一个关系型数据库,也就是设计RDBMS(Relational Database Management System),这个问题考验的是对RDBMS各个模块的划分, 以及对数据库结构的了解.只要讲述 ...
- 关系型数据库和非关系型数据库区别、oracle与mysql的区别
一.关系型数据库 关系型数据库,是指采用了关系模型来组织数据的数据库. 关系模型是在1970年由IBM的研究员E.F.Codd博士首先提出的,在之后的几十年中,关系模型的概念得到了充分的发展并逐 ...
- 非关系型数据库(NoSql)
最近了解了一点非关系型数据库,刚刚接触,觉得这是一个很好的方向,对于大数据 方面的处理,非关系型数据库能起到至关重要的地位.这里我主要是整理了一些前辈的经验,仅供参考. 关系型数据库的特点 1.关系型 ...
- NoSQL:从关系型数据库到非关系型数据库
关系型数据库 所谓关系型数据库,,就是指采用了关系模型来组织数据的数据库. 什么是关系模型,简单说,关系模型就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织. 关系模 ...
- Google的分布式关系型数据库F1和Spanner
F1是Google开发的分布式关系型数据库,主要服务于Google的广告系统.Google的广告系统以前使用MySQL,广告系统的用户经常需要使用复杂的query和join操作,这就需要设计shard ...
随机推荐
- BZOJ 4488: [Jsoi2015]最大公约数 暴力 + gcd
Description 给定一个长度为 N 的正整数序列Ai对于其任意一个连续的子序列 {Al,Al+1...Ar},我们定义其权值W(L,R )为其长度与序列中所有元素的最大公约数的乘积,即W(L, ...
- Luogu P3408 恋爱
题目链接:Click here Solution: 设f[x]表示要使x向它的父亲写信需要花的最少的钱,per[x]为要使x向它的父亲写信最少要多少人 则\(f[x]=\sum_{i=1}^{per[ ...
- 容器————map
序列容器是管理数据的宝贵工具,但对大多数应用程序而言,序列容器不提供方便的数据访问机制.一种典型的方法是通过名称来寻找地址.如果记录保存在序列容器中,就只能通过搜索得到这些数据.相比而言,map 容器 ...
- 浅谈 Catalan number——卡特兰数
一.定义: 卡特兰数是一组满足下面递推关系的数列: 二.变形: 首先,设h(n)为Catalan数的第n+1项,令h(0)=1,h(1)=1,Catalan数满足递推式: h(n)= h(0)*h(n ...
- Oracle删除表空间报ORA01548
由于undo表空间设置了自动增长,导致替换了好几个undo表空间,就想把原先的undo表空间删掉腾出空间 但删的时候报错 SQL> drop tablespace undotbs1 includ ...
- [CSP-S模拟测试]:表达式密码(模拟)
题目传送门(内部题87) 输入格式 从文件$expression.in$中读入数据.输入一行,一个字符串$S$,表示原表达式,保证为合法表达式 输出格式 输出到文件$expression.out$中. ...
- jdbcType="DATE"和jdbcType=" TIMESTAMP"的区别
原文: https://www.cnblogs.com/fswhq/p/jdbcType.html 当传入null值时,jdbcType 会防止null空指针异常报错 Mybatis 中jdbcTyp ...
- linux下插入U盘自动挂载后,用C获取其挂载点(cat /proc/mounts)
现在已经能够通过libudev获取U盘插入时它的节点名(通过函数udev_device_get_devnode()),是/dev/sdb1 我现在的做法是读取/proc/mounts文件,找到有/de ...
- leetcode 206 反转链表 Reverse Linked List
C++解法一:迭代法,使用前驱指针pre,当前指针cur,临时后继指针nxt: /** * Definition for singly-linked list. * struct ListNode { ...
- Microsoft:Team Foundation Server 20XX Release Notes
ylbtech-Microsoft:Team Foundation Server 2017 Release Notes 1.返回顶部 1. https://docs.microsoft.com/en- ...