【最新】 ELK之 logstash 同步数据库数据到Elasticsearch
cd /usr/local
下载logstash 6.4.3版本
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.4.3.tar.gz
解压
tar -zxvf logstash-6.4.3.tar.gz
下载input和output插件
cd logstash-6.4.3 bin/logstash-plugin install logstash-input-jdbc bin/logstash-plugin install logstash-output-elasticsearch
新建logstash.conf
vi /usr/local/logstash-6.4.3/config/logstash.conf
内容输入案例
input {
jdbc {
jdbc_driver_library => "/usr/local/sql/mysql-connector-java-5.1.46.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/test"
jdbc_user => "root"
jdbc_password => "root"
schedule => "* * * * *"
statement => "SELECT * FROM user WHERE update_time >= :sql_last_value"
use_column_value => true
tracking_column_type => "timestamp"
tracking_column => "update_time"
last_run_metadata_path => "syncpoint_user"
}
}
output {
elasticsearch {
# ES的IP地址及端口
hosts => ["172.31.73.140:9200","172.31.73.140:9201"]
# 索引名称 可自定义
index => "user"
# 需要关联的数据库中有有一个id字段,对应类型中的id
document_id => "%{user_id}"
document_type => "user"
}
stdout {
# JSON格式输出
codec => json_lines
}
}
注意:这里边需要先安装下mysql-connector-java-5.1.46.jar包,存放到以上指定位置
配置pipelines.yml
vi /usr/local/logstash-6.4.3/config/pipelines.yml
在文件底部添加
- pipeline.id: user
path.config: "/usr/local/logstash-6.4.3/config/logstash.conf"
启动logstash
cd /usr/local/logstash-6.4.3 ./bin/logstash -f
命令行启动(-e的意思允许命令行启动)
bin/logstash -e 'input { stdin {} } output { stdout {} }'
启动后输入hello world
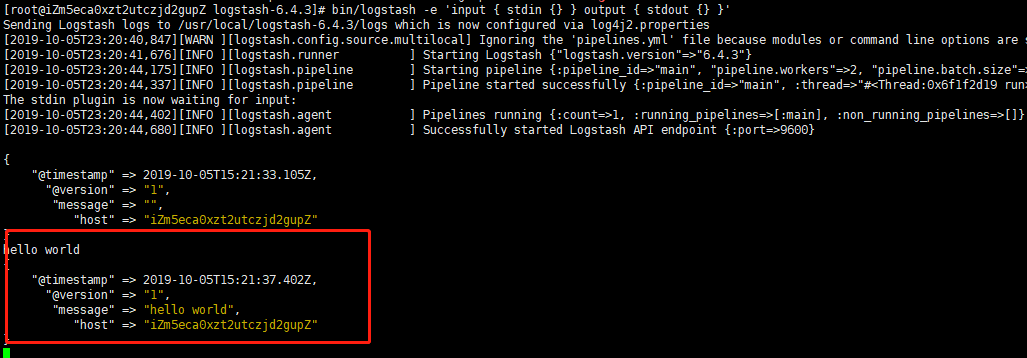
logstash 默认读取文件位置为
/usr/local/logstash-6.4.3/config/pipelines.yml
当然,你也可以新建文件 启动时候指定一下
./bin/logstash -f filename
命令行参数解释
-e 执行一段字符串脚本
-f 或–config 指定配置, logstash -f /etc/logstash.d/会自动读取该目录下所有文件文本,拼接成完整的大配置,各小配置会以字母排序加载,因此最后以数字编号方式命令配置文件
-t 测试配置文件是否能正常解析
-l或–log ,logstash默认输出日志到标准错误。该选项可指定日志输出位置,如 bin/logstash -l logs/logstash.log
–pipeline-workers或-w, 运行filter和output的pipline线程数量,默认是cpu核数
–pipeline-batch-size或-b, 每个logstash pipline线程,在执行具体filter和output函数之前,最多能累积的日志条数,默认125条,越大性能越好,消耗jvm内存也越大
–pipline-batch-delay或-u, 每个线程在打包批量日志的时候,最多等到几毫秒,默认5ms
–pluginpath或-P, bin/logstash –pluginpath /path/to/own/plugins加载插件
–verbose, 输出一定调试日志
–debug输出更多调试日志
启动自动配置加载
bin/logstash -f first-pipeline.conf --config.reload.automatic
--config.reload.automatic选项的意思是启用自动配置加载,以至于每次你修改完配置文件以后无需停止然后重启Logstash
&符号 保证关闭当前窗口程序依旧运行
bin/logstash &
【最新】 ELK之 logstash 同步数据库数据到Elasticsearch的更多相关文章
- 【记录】ELK之logstash同步mysql数据到Elasticsearch ,配置文件详解
本文出处:https://my.oschina.net/xiaowangqiongyou/blog/1812708#comments 截取部分内容以便学习 input { jdbc { # mysql ...
- centos7配置Logstash同步Mysql数据到Elasticsearch
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中.个人认为这款插件是比较稳定,容易配置的使用Logstash之前,我们得明确 ...
- Centos8 部署 ElasticSearch 集群并搭建 ELK,基于Logstash同步MySQL数据到ElasticSearch
Centos8安装Docker 1.更新一下yum [root@VM-24-9-centos ~]# yum -y update 2.安装containerd.io # centos8默认使用podm ...
- Logstash同步Oracle数据到ElasticSearch
最近在项目上应用到了ElasticSearch和Logstash,在此主要记录了Logstash-input-jdbc同步Oracle数据库到ElasticSearch的主要步骤,本文是对环境进行简单 ...
- 实战ELK(6)使用logstash同步mysql数据到ElasticSearch
一.准备 1.mysql 我这里准备了个数据库mysqlEs,表User 结构如下 添加几条记录 2.创建elasticsearch索引 curl -XPUT 'localhost:9200/user ...
- 使用logstash同步mysql数据到elasticsearch
下载 logstash tar -zxvf https://artifacts.elastic.co/downloads/logstash/logstash-6.3.2.tar.gz .tar.gz ...
- logstash同步mongodb数据到elasticsearch
一.安装logstash 二.安装mongodb插件 cd D:\Software\ELK5.5.0\logstash-5.5.0\bin logstash-plugin install logsta ...
- 使用logstash同步MySQL数据到ES
使用logstash同步MySQL数据到ES 版权声明:[分享也是一种提高]个人转载请在正文开头明显位置注明出处,未经作者同意禁止企业/组织转载,禁止私自更改原文,禁止用于商业目的. https:// ...
- Logstash学习之路(四)使用Logstash将mysql数据导入elasticsearch(单表同步、多表同步、全量同步、增量同步)
一.使用Logstash将mysql数据导入elasticsearch 1.在mysql中准备数据: mysql> show tables; +----------------+ | Table ...
随机推荐
- hdu1257最少拦截系统 贪心
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1257 某国为了防御敌国的导弹袭击,发展出一种导弹拦截系统.但是这种导弹拦截系统有一个缺陷:虽 然它的第 ...
- Hibernate与 MyBatis的区别
第一章 Hibernate与MyBatis Hibernate 是当前最流行的O/R mapping框架,它出身于sf.net,现在已经成为Jboss的一部分. Mybatis 是另外一种优秀 ...
- Sass--混合宏的不足
混合宏在实际编码中给我们带来很多方便之处,特别是对于复用重复代码块.但其最大的不足之处是会生成冗余的代码块.比如在不同的地方调用一个相同的混合宏时.如: @mixin border-radius{ - ...
- java 字符串的截取、转换、分割
1.截取 package java07; /* 字符串的截取方法: public String substring(int index):截取从参数位置一直到字符串末尾,返回新字符串 public S ...
- 几种IO机制区别
IO的方式通常分为几种,同步阻塞的BIO.同步非阻塞的NIO.异步非阻塞的AIO. 一.BIO 在JDK1.4出来之前,我们建立网络连接的时候采用BIO模式,需要先在服务端启动一个ServerSock ...
- 阿里腾讯校招Java面试题总结及答案
阿里校招java面试题汇总 1.HashMap和HashTable的区别,及其实现原理. Hashtable继承自Dictionary类,而HashMap是Java1.2引进的,继承自Abstract ...
- shell编程程序实例
1.计算器 #!/bin/bash #test #by authors hdc 2018 function add(){ #实现加法 c=$[ $a + $b ] #相加 echo $c } func ...
- centos6 / centos7 安装apache
=================centos6.1 安装apache===================== 安装: yum -y install httpd 启动 /etc/init.d/htt ...
- vfs的super block
super block这个数据结构,乃至super block在磁盘上的位置,是哪里的规定? 没规定,1k偏移只是ext文件系统.但是像fat,它们第0扇区后就是保留扇区,但linux一样要识别它们. ...
- python学习笔记(二)列表操作
列表及列表操作: 列表是最常用的数据类型之一,列表也叫数组,列表定义,使用[]即可:列表里面可以再套列表,一个里面套一个列表,叫二维数组:一个里面套一个列表,里面的列表再套一个列表,这个叫三位数组,套 ...