自学Python6.5-内置模块(re、collections )
自学Python之路-Python基础+模块+面向对象
自学Python之路-Python网络编程自学Python之路-Python并发编程+数据库+前端自学Python之路-django
自学Python6.5-内置模块(re、collections、)
13. re模块
正则表达式本身是一种小型的、高度专业化的编程语言,而在python中,通过内嵌集成re模块,程序员们可以直接调用来实现正则匹配。正则表达式模式被编译成一系列的字节码,然后由用C编写的匹配引擎执行。
14. collections 模块
在内置数据类型(dict、list、set、touple)基础上,collections模块还提供了几个人外的数据类型:
- 计数器(Counter),主要用来计数
- 双向队列(deque),双端队列,可以快速的从另外一侧追加和推出对象
- 默认字典(defaultdict),带默认值的字典
- 有序字典(OrderedDict)
- 可命名元组(namedtuple) ,生成可以使用名字来访问元素内容的tuple
14.1 计数器(Counter)
Counter作为字典dicit()的一个子类用来进行hashtable计数,将元素进行数量统计,计数后返回一个字典,键值为元素,值为元素个数
| most_common(int) | 按照元素出现的次数进行从高到低的排序,返回前int个元素的字典 |
| elements | 返回经过计算器Counter后的元素,返回的是一个迭代器 |
| update | 和set集合的update一样,对集合进行并集更新 |
| substract | 和update类似,只是update是做加法,substract做减法,从另一个集合中减去本集合的元素 |
| iteritems | 返回由Counter生成的字典的所有item |
| iterkeys | 返回由Counter生成的字典的所有key |
| itervalues | 返回由Counter生成的字典的所有value |
- from collections import Counter
- str = "abcbcaccbbad"
- li = ["a","b","c","a","b","b"]
- d = {"1":3, "3":2, "17":2}
- #1. Counter获取各元素的个数,返回字典
- print ("Counter(s):", Counter(str))
- print ("Counter(li):", Counter(li))
- print ("Counter(d):", Counter(d))
- #2. most_common(int)按照元素出现的次数进行从高到低的排序,返回前int个元素的字典
- d1 = Counter(str)
- print ("d1.most_common(2):",d1.most_common(2))
- #3. elements返回经过计算器Counter后的元素,返回的是一个迭代器
- print ("sorted(d1.elements()):", sorted(d1.elements()))
- print ('''("".join(d1.elements())):''',"".join(d1.elements()))
- #4. 若是字典的话返回value个key
- d2 = Counter(d)
- print("若是字典的话返回value个key:", sorted(d2.elements()))

14.2 双向队列(deque)
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储(有顺序的),数据量大的时候,插入和删除效率很低。
duque就是为了高效实现插入和删除操作的双向列表,适用于队列和栈。
- 堆栈:先进后出
- 队列queue:先进先出
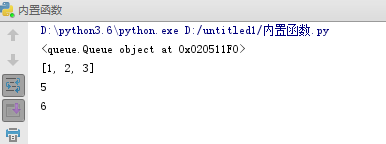
- #队列
- import queue
- q = queue.Queue()
- q.put([1,2,3])
- q.put(5)
- q.put(6)
- print(q) #
- print(q.get())
- print(q.get())
- print(q.get())
- print(q.get()) # 取完3个数之后,阻塞
- print(q.qsize()) # 取q的数值

- # 队列
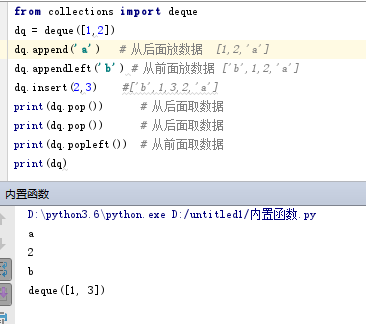
- from collections import deque
- dq = deque([1,2])
- dq.append('a') # 从后面放数据 [1,2,'a']
- dq.appendleft('b') # 从前面放数据 ['b',1,2,'a']
- dq.insert(2,3) #['b',1,3,2,'a']
- print(dq.pop()) # 从后面取数据 a
- print(dq.pop()) # 从后面取数据 2
- print(dq.popleft()) # 从前面取数据 b
- print(dq)
| append | 队列右边添加元素 |
| appendleft | 队列左边添加元素 |
| clear | 清空队列中的所有元素 |
| count | 返回队列中包含value的个数 |
| extend | 队列右边扩展,可以是列表、元组或字典,如果是字典则将字典的key加入到deque |
| extendleft | 同extend,在左边扩展 |
| pop | 移除并返回队列右边的元素 |
| popleft | 移除并返回队列左边的元素 |
| remove(value) | 移除队列第一个出现的元素 |
| reverse | 队列的所有元素进行反转 |
| rotate(n) | 对队列数进行移动 |
14.3 默认字典(defaultdict)
默认字典,字典的一个子类,继承所有字典的方法,默认字典在进行定义初始化的时候得指定字典值有默认类型。
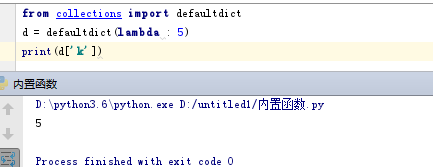
- from collections import defaultdict
- d = defaultdict(lambda : 5)
- print(d['k'])
14.4 有序字典(OrderedDict)
使用dict时,key是无序的,在对dict做迭代的时候,我们无法确定key的顺序。
如果要保持key的顺序,就可以采用orderedDict。
- from collections import OrderedDict
- od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
- print(od) # OrderedDict的Key是有序的
- print(od['a'])
- for k in od:
- print(k)

14.5 可命名元组(namedtuple)
我们知道tuple是不可变集合,例如,一个点的二维坐标可以表示成p=(1,2),但是这样很难看出是一个点的坐标,所有这时可采用namedtuple。
- from collections import namedtuple
- Point = namedtuple('point',['x','y','z'])
- p1 = Point(1,2,3)
- p2 = Point(3,2,1)
- print(p1.x)
- print(p1.y)
- print(p1,p2)

- #花色和数字
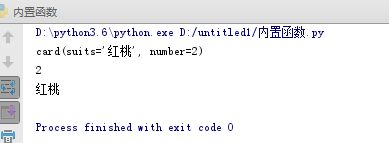
- from collections import namedtuple
- Card = namedtuple('card',['suits','number'])
- c1 = Card('红桃',2)
- print(c1)
- print(c1.number)
- print(c1.suits)
15. 模块
自学Python6.5-内置模块(re、collections )的更多相关文章
- 自学Python6.1-模块简介
自学Python之路-Python基础+模块+面向对象自学Python之路-Python网络编程自学Python之路-Python并发编程+数据库+前端自学Python之路-django 自学Pyth ...
- 自学Python6.3-内置模块(1)
自学Python之路-Python基础+模块+面向对象自学Python之路-Python网络编程自学Python之路-Python并发编程+数据库+前端自学Python之路-django 自学Pyth ...
- 自学Python6.2-类、模块、包
自学Python之路-Python基础+模块+面向对象自学Python之路-Python网络编程自学Python之路-Python并发编程+数据库+前端自学Python之路-django 自学Pyth ...
- 自学Python6.4-内置模块(2)
自学Python之路-Python基础+模块+面向对象自学Python之路-Python网络编程自学Python之路-Python并发编程+数据库+前端自学Python之路-django 自学Pyth ...
- python内置模块之collections(六)
前言 collections是Python内建的一个集合模块,提供了许多有用的集合类. 系列文章 python模块分析之random(一) python模块分析之hashlib加密(二) python ...
- day36-常见内置模块五(collections、xml模块)
一.collections模块 在内置数据类型(dict.list.set.tuple)的基础上,collections模块还提供了几个额外的数据类型:namedtuple.deque.Counter ...
- python学习笔记:第21天 常用内置模块之collections和time
目录 一.collections模块 二.时间模块 也可以在我的个人博客上阅读 一.collections模块 1. Counter Counter是⼀个计数器,主要⽤统计字符的数量,之前如果我们要统 ...
- 自学Python5.3-内置模块(1)
内置模块(1)内置模块是Python自带的功能,在使用内置模块相应的功能时,需要 先导入 再 使用 1.OS模块 用于提供系统级别的操作: os.getcwd() 获取当前工作目录,即 ...
- 自学Python5.1-模块简介
模块简介 在C语言中如果要引用sqrt这个函数,必须用语句"#include<math.h>"引入math.h这个头文件,否则是无法正常进行调用的.那么在Python中 ...
随机推荐
- kvm热迁移(4)
一.迁移简介 迁移分为热迁移和冷迁移,冷迁移是在机器关机的状态下进行迁移,具体操作在之前的博客有体现.热迁移是在机器处于开机状态进行迁移,本次博客主要讲解热迁移. 系统的迁移是指把源主机上的操作系统和 ...
- Oracle:常用操作(定时作业,逻辑导入,数据泵导入)
1.逻辑导入: /*第1步:创建临时表空间 **/ create temporary tablespace user_temp1 tempfile 'D:\app\Administrator\orad ...
- AI测试——旅程的终点
在2019年6月,我产生了一个想法,即人工智能探索测试AIET(Artificial intelligence exploration test),大概用了一周时间来思考怎么把人工智能应用到测试领域, ...
- java8 stream多字段排序
注:转载请注明出处!!!!!!! 很多情况下sql不好解决的多表查询,临时表分组,排序,尽量用java8新特性stream进行处理 使用java8新特性,下面先来点基础的 List<类> ...
- 通过java 来实现对多个文件的内容合并到一个文件中
现在有多个txt文本文件,需要把这么多个文件的内容都放到一个文件中去 以下是实现代码 package com.SBgong.test; import java.io.*; public class F ...
- 【基本优化实践】【1.1】IO优化——把文件迁移到不同物理磁盘
[1]概念 把不同数据文件移动到不同的物理磁盘,无疑是一个提高IO的有效办法 在资源可以的情况下,尽量把 temp .数据库的主数据文件(mdf).数据库的从数据数据(ndf).数据库的事务日志文件( ...
- vue组件添加事件@click.native
1,给vue组件绑定事件时候,必须加上native ,否则会认为监听的是来自Item组件自定义的事件 2,等同于在子组件中: 子组件内部处理click事件然后向外发送click事件:$emit(&q ...
- myeclipse使用db-brower连接到sqlserver2012踩坑经历
myeclipse使用db-brower连接到sqlserver踩坑经历 首先得建立个角色 右键->创建登录名 权限开大点 连接设置 Driver template选择我选这个,格式按照我的写 ...
- Codeforces 1196E. Connected Component on a Chessboard
传送门 注意到棋盘可以看成无限大的,那么只要考虑如何构造一个尽可能合法的情况 不妨假设需要的白色格子比黑色格子少 那么容易发现最好的情况之一就是白色排一排然后中间黑的先连起来,剩下黑色的再全部填白色周 ...
- Scala学习一——基础
一.使用Scala解释器 如果以命令行的方式运行,输出的结果会把类型带上,且结果名默认为res0递增.且Scala解释器读到一个解释器求值打印然后读取下一个(这个过程为读取-求值-打印-循环[REPL ...