搭建hadoop单机版
一、准备工作
1.申请机器
1)修改配置:
申请虚拟机下来了,通过xshell连接进入,
主机名还是默认的,修改下,不然看着不习惯
>hostname 查看主机名
>vim /etc/sysconfig/network
按i、 I 、a、 A其中一个,进入输入模式
HOSTNAME=master 改成自己想要的名字
按Esc退出输入模式
:wq 保存并退出
要想改的名字生效,执行reboot,这个过程可能需要几分钟,然后再xshell连接
2、准备软件
1)安装java 1.8
java -version 发现有了,不用安装了,此步省略
2)python 也有了,不用安装了
3)上传文件
rz命令上传文件
bash: rz: command not found
发现rz命令不能用,需要安装
>rpm -qa lrzsz 查看安装版本,发现是空的,没安装
>yum -y install lrzsz 安装上传下载命令工具
>mkdir soft 新建存在文件目录
>cd soft
>rz 命令,执行文件上传,选择要上传的文件 hadoop-2.8.4.tar.gz
>tar -xvf hadoop-2.8.4.tar.gz 解压hadoop文件
在根目录创建hadoop目录,
将解压的hadoop文件夹移动到创建的hadoop目录
>mv hadoop-2.8.4 /hadoop
二、安装配置
1.java环境变量配置
>vim /etc/profile
JAVA_HOME=/opt/java/jdk1.8.0_181
JRE_HOME=/opt/java/jdk1.8.0_181/jre
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=.:$JAVA_HOME/bin:$PATH
>source /etc/profile 使配置生效
2.hadoop环境变量配置
>vim /etc/profile
export HADOOP_HOME=/hadoop/hadoop-2.8.4
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH
>source /etc/profile 使配置生效
3.hadoop配置文件修改
在修改配置文件之前,创建hadoop临时目录
[root@master ~]# mkdir /root/hadoop
[root@master ~]# mkdir /root/hadoop/tmp
[root@master ~]# mkdir /root/hadoop/var
[root@master ~]# mkdir /root/hadoop/dfs
[root@master ~]# mkdir /root/hadoop/dfs/name
[root@master ~]# mkdir /root/hadoop/dfs/data
>cd /hadoop/hadoop-2.8.4/etc/hadoop 切换到hadoop配置文件目录
1)修改core-site.xml文件
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
<description>hadoop tmp dir</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
2)修改 hadoop-env.sh
>vi hadoop-env.sh
将export JAVA_HOME=${JAVA_HOME}中${JAVA_HOME}修改成java具体安装目录
export JAVA_HOME=/opt/java/jdk1.8.0_181
3)修改hdfs-site.xml
>vi hdfs-site.xml
<property>
<name>dfs.name.dir</name>
<value>/root/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>true</value>
<description>need not permissions</description>
</property>
dfs.permissions配置为false后,可以允许不要检查权限就生成dfs上的文件,方便倒是方便了,但是你需要防止误删除,请将它设置为true,或者直接将该property节点删除,因为默认就是true
4)修改mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/root/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置文件配置完成。
三、启动hadoop
1.首次启动,需要初始化(格式化)
>cd /hadoop/hadoop-2.8.4/bin 切换到安装bin目录
>./hadoop namenode -format
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
提示方法过时了,但不影响
conf.Configuration: error parsing conf mapred-site.xml
org.xml.sax.SAXParseException; systemId: file:/hadoop/hadoop-2.8.4/etc/hadoop/mapred-site.xml; lineNumber: 5; columnNumber: 2; The markup in the document following the root element must be well-formed.
报错了,看报错信息是mapred-site.xml文件没配置好,去看下发现没配置<configuration></configuration>根标签,加上根标签,去bin目录,重新执行
>./hadoop namenode -format
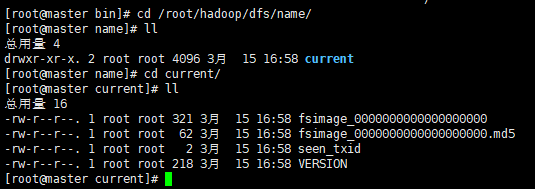
没报错就是格式化好了。
初始化成功后,可以在/root/hadoop/dfs/name 目录下(该路径在hdfs-site.xml文件中进行了相应配置,并新建了该文件夹)新增了一个current 目录以及一些文件。
2.启动hadoop:主要是启动HDFS和YARN
切换到sbin目录
>cd /hadoop/hadoop-2.8.4/sbin/
>start-dfs.sh 启动HDFS
Are you sure you want to continue connecting (yes/no)?
yes
root@master's password: ******

启动过程中,可以看到,先启动namenode服务,再启动datanode服务,最后启动secondarynamenode服务
HDFS启动成功了。
启动YARN
>start-yarn.sh

从打印日志中,可以看到启动yarn实际是启动yarn的daemons守护进程,再启动nodemanager节点管理器
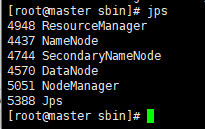
通过 jps命令查看hadoop服务是否启动成功:
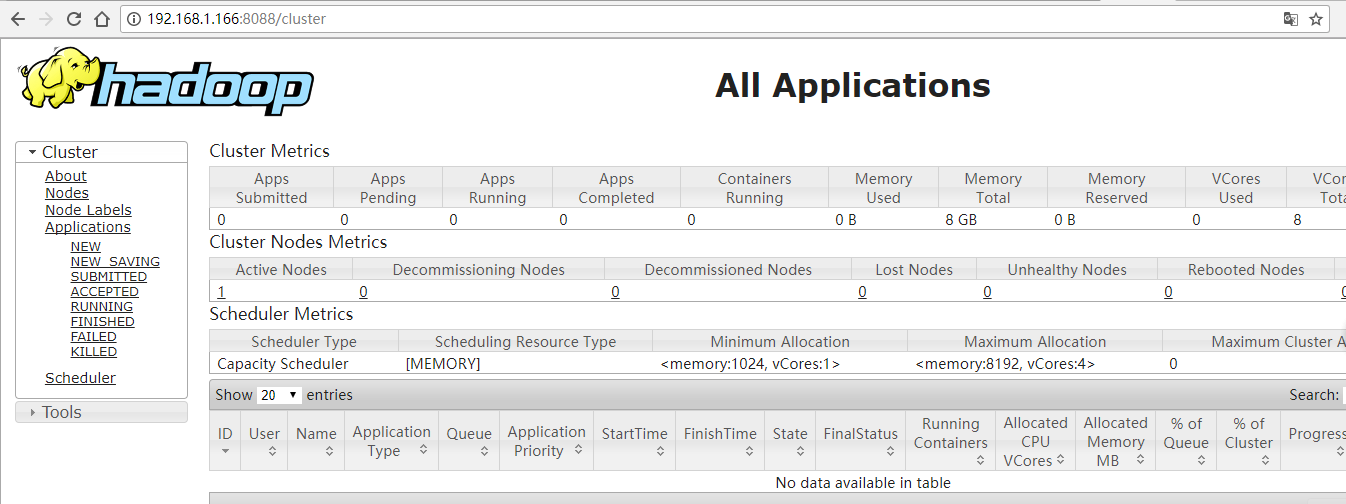
在浏览器中可以访问:
http://192.168.1.1**:8088/cluster
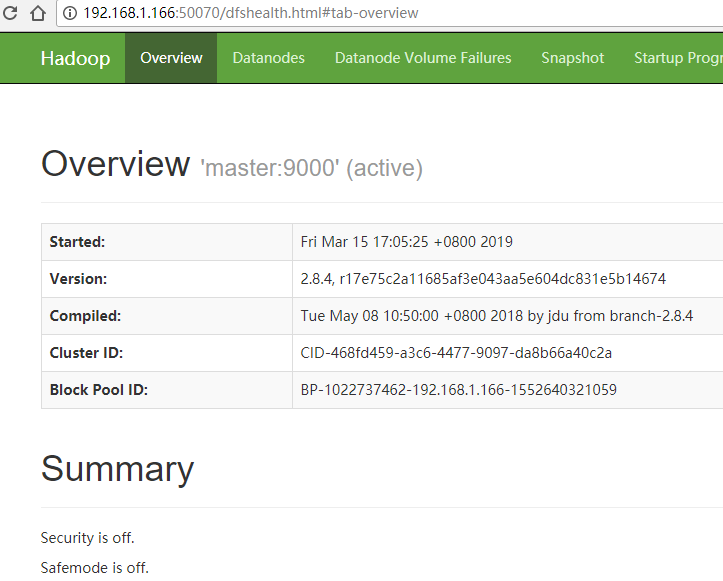
到此部署成功了。
http://192.168.1.1**:50070
搭建hadoop单机版的更多相关文章
- Ubuntu 12.04搭建hadoop单机版环境
前言: 本文章是转载的,自己又加上了一些自己的笔记整理的 详细地址请查看Ubuntu 12.04搭建hadoop单机版环境 Hadoop的三种运行模式 独立模式:无需任何守护进程,所有程序都在单个JV ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) (转载)
Hadoop在处理海量数据分析方面具有独天优势.今天花了在自己的Linux上搭建了伪分布模式,期间经历很多曲折,现在将经验总结如下. 首先,了解Hadoop的三种安装模式: 1. 单机模式. 单机模式 ...
- (转)超详细单机版搭建hadoop环境图文解析
超详细单机版搭建hadoop环境图文解析 安装过程: 一.安装Linux操作系统 二.在Ubuntu下创建hadoop用户组和用户 三.在Ubuntu下安装 ...
- Linux下搭建Hadoop集群
本文地址: 1.前言 本文描述的是如何使用3台Hadoop节点搭建一个集群.本文中,使用的是三个Ubuntu虚拟机,并没有使用三台物理机.在使用物理机搭建Hadoop集群的时候,也可以参考本文.首先这 ...
- VM+CentOS+hadoop2.7搭建hadoop完全分布式集群
写在前边的话: 最近找了一个云计算开发的工作,本以为来了会直接做一些敲代码,处理数据的活,没想到师父给了我一个课题“基于质量数据的大数据分析”,那么问题来了首先要做的就是搭建这样一个平台,毫无疑问,底 ...
- 基于《Hadoop权威指南 第三版》在Windows搭建Hadoop环境及运行第一个例子
在Windows环境上搭建Hadoop环境需要安装jdk1.7或以上版本.有了jdk之后,就可以进行Hadoop的搭建. 首先下载所需要的包: 1. Hadoop包: hadoop-2.5.2.tar ...
- Windows环境下搭建Hadoop(2.6.0)+Hive(2.2.0)环境并连接Kettle(6.0)
前提:配置JDK1.8环境,并配置相应的环境变量,JAVA_HOME 一.Hadoop的安装 1.1 下载Hadoop (2.6.0) http://hadoop.apache.org/release ...
- [Hadoop] 在Ubuntu系统上一步步搭建Hadoop(单机模式)
1 Hadoop的三种创建模式 单机模式操作是Hadoop的默认操作模式,当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,会保守地选择最小配置,即单机模式.该模式主要用于开发调试M ...
- 使用Windows Azure的VM安装和配置CDH搭建Hadoop集群
本文主要内容是使用Windows Azure的VIRTUAL MACHINES和NETWORKS服务安装CDH (Cloudera Distribution Including Apache Hado ...
随机推荐
- [iOS]UIWebView返回和NSURLErrorDomain-999
1.UIWebView实现返回不崩溃: -(BOOL)webView:(UIWebView *)webView shouldStartLoadWithRequest:(NSURLRequest *)r ...
- 【Python开发】Python:itertools模块
Python:itertools模块 itertools模块包含创建有效迭代器的函数,可以用各种方式对数据进行循环操作,此模块中的所有函数返回的迭代器都可以与for循环语句以及其他包含迭代器(如生成器 ...
- Prometheus 和 Alertmanager实战配置
Prometheus时序数据库 一.Prometheus 1.Prometheus安装 1)源码安装 prometheus安装包最新版本下载地址:https://prometheus.io/downl ...
- AcWing登山
这是2006北大举办的ACM的一道题. 题意为:给定景点海拔高度,队员们不去游览相同高度的景点,一开始往上爬,一但往下爬就不能再向上爬,求最多可以游览多少个景点.那么我们可以得到一个结论:以一个最高点 ...
- 安装Composer与PsySH
Windows安装Composer 需要开启 openssl 配置:打开 php 目录下的 php.ini,将 extension=php_openssl.dll 前面的分号去掉就可以了. https ...
- python-day42(正式学习)
目录 数据库 卸载 安装 连接数据库 用户信息查看 数据库的基本操作 表的基本操作 记录的基本操作 复习 今日内容 数据库配置 数据库修改信息 用户操作:重点 表的修改 创建表的完整语法 数据库表的引 ...
- java基础: synchronized与Lock的区别
主要区别 1. 锁机制不一样:synchronized是java内置关键字,是在JVM层面实现的,系统会监控锁的释放与否,lock是JDK代码实现的,需要手动释放,在finally块中释放.可以采用非 ...
- Codeforces 1194C. From S To T
传送门 首先贪心, $S$ 能和 $T$ 匹配就要尽量匹配,剩下的才让 $P$ 来补 在 $S$ 全部匹配上的情况下,看看 $P$ 是否有足够的字符即可 #include<iostream> ...
- 使用TableSnapshotInputFormat读取Hbase快照数据
根据快照名称读取hbase快照中的数据,在网上查了好多资料,很少有资料能够给出清晰的方案,根据自己的摸索终于实现,现将代码贴出,希望能给大家有所帮助: public void read(org.apa ...
- php过滤微信昵称中的表情
function filterNickname($nickname) { $nickname = preg_replace('/[\x{1F600}-\x{1F64F}]/u', '', $nickn ...