es之分词器和分析器
Elasticsearch这种全文搜索引擎,会用某种算法对建立的文档进行分析,从文档中提取出有效信息(Token)
对于es来说,有内置的分析器(Analyzer)和分词器(Tokenizer)
1:分析器
ES内置分析器
| standard | 分析器划分文本是通过词语来界定的,由Unicode文本分割算法定义。它删除大多数标点符号,将词语转换为小写(就是按照空格进行分词) |
|---|---|
| simple | 分析器每当遇到不是字母的字符时,将文本分割为词语。它将所有词语转换为小写。 |
| keyword | 可以接受任何给定的文本,并输出与单个词语相同的文本 |
| pattern | 分析器使用正则表达式将文本拆分为词语,它支持小写和停止字 |
| language | 语言分析器 |
| whitespace | (空白)分析器每当遇到任何空白字符时,都将文本划分为词语。它不会将词语转换为小写 |
| custom | 自定义分析器 |
测试simple Analyzer:
POST _analyze
{
"analyzer": "simple",
"text": "today is 2018year 5month 1day."
}
custom(自定义)分析器接受以下的参数:
tokenizer |
内置或定制的标记器(也就是需要使用哪种分析器)。<br/>(需要) |
|---|---|
char_filter |
内置或自定义字符过滤器的可选阵列。 |
filter |
可选的内置或定制token过滤器阵列。 |
position_increment_gap |
在索引文本值数组时,Elasticsearch会在一个词的最后一个位置和下一个词的第一个位置之间插入“间隙”,以确保短语查询与不同数组元素的两个术语不匹配。 默认为100.有关更多信息 |
测试:
PUT /my_index/groups/1
{
"names": [ "John Abraham", "Lincoln Smith"]
}
做一下普通查询:
GET /my_index/groups/_search
{
"query": {
"match_phrase": {
"names": "Abraham Lincoln"
}
}
}
然后删除索引,重新添加:
PUT my_index
{
"mappings": {
"my_type": {
"properties": {
"names": {
"type": "text",
"position_increment_gap": 0
}
}
}
}
}
然后倒入数据:
PUT /my_index/groups/1
{
"names": [ "John Abraham", "Lincoln Smith"]
}
在做查询操作:
GET /my_index/groups/_search
{
"query": {
"match_phrase": {
"names": "Abraham Lincoln"
}
}
}
2:更新分析器
1:要先关闭索引
2:添加分析器
3:打开索引
1、 关闭索引
POST my_index/_close
2、 添加分析器
PUT my_index/_settings
{
"analysis": {
"analyzer": {
"my_custom_analyzer3": {
"type": "custom",
"tokenizer": "standard",
"char_filter": [
"html_strip"
],
"filter": [
"lowercase",
"asciifolding"
]
}
}
}
}
3、打开索引
POST my_index/_open
4、测试:
POST my_index/_analyze
{
"analyzer": "my_custom_analyzer",
"text": "Is this <b>网页 </b>?"
}
3:分词器
Es中也支持非常多的分词器
| Standard | 默认的分词器根据 Unicode 文本分割算法,以单词边界分割文本。它删除大多数标点符号。<br/>它是大多数语言的最佳选择 |
|---|---|
| Letter | 遇到非字母时分割文本 |
| Lowercase | 类似 letter ,遇到非字母时分割文本,同时会将所有分割后的词元转为小写 |
| Whitespace | 遇到空白字符时分割位文本 |
Standard例子:
POST _analyze
{
"tokenizer": "standard",
"text": "this is standard tokenizer!!!!."
}
Letter例子:
POST _analyze
{
"tokenizer": "letter",
"text": "today is 2018year-05month"
}
Whitespace例子:
POST _analyze
{
"tokenizer": "whitespace",
"text": "this is t es t."
}
4:更新分词器
我们在创建索引之后可以添加分词器,比如想要按照空格的方式进行分词
【注意】
添加分词器步骤:
1:要先关闭索引
2:添加分词器
3:打开索引
POST school/_close
PUT school/_settings
{
"analysis" :
{
"analyzer" :
{
"content" : {"type" : "custom" , "tokenizer" : "whitespace"}
}
}
}
POST school/_open
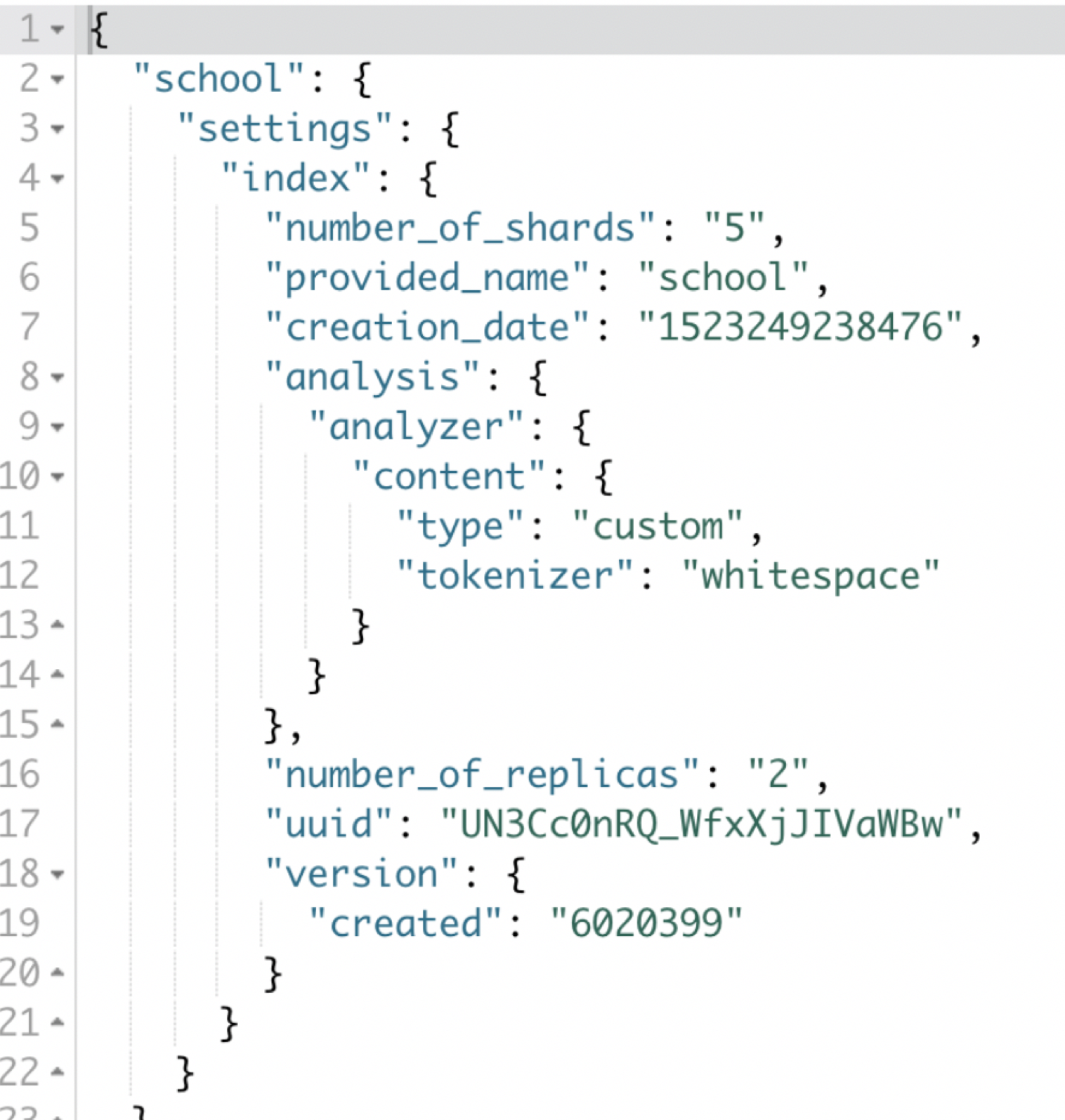
获取索引的配置:
索引中包含了非常多的配置参数,我们可以通过命令进行查询
GET school/_settings
es之分词器和分析器的更多相关文章
- Elasticsearch(ES)分词器的那些事儿
1. 概述 分词器是Elasticsearch中很重要的一个组件,用来将一段文本分析成一个一个的词,Elasticsearch再根据这些词去做倒排索引. 今天我们就来聊聊分词器的相关知识. 2. 内置 ...
- es的分词器analyzer
analyzer 分词器使用的两个情形: 1,Index time analysis. 创建或者更新文档时,会对文档进行分词2,Search time analysis. 查询时,对查询语句 ...
- ES中文分词器安装以及自定义配置
之前我们创建索引,查询数据,都是使用的默认的分词器,分词效果不太理想,会把text的字段分成一个一个汉字,然后搜索的时候也会把搜索的句子进行分词,所以这里就需要更加智能的分词器IK分词器了. ik分词 ...
- ES ik分词器使用技巧
match查询会将查询词分词,然后对分词的结果进行term查询. 然后默认是将每个分词term查询之后的结果求交集,所以只要分词的结果能够命中,某条数据就可以被查询出来,而分词是在新建索引时指定的,只 ...
- Elasticsearch(10) --- 内置分词器、中文分词器
Elasticsearch(10) --- 内置分词器.中文分词器 这篇博客主要讲:分词器概念.ES内置分词器.ES中文分词器. 一.分词器概念 1.Analysis 和 Analyzer Analy ...
- ElasticSearch最全分词器比较及使用方法
介绍:ElasticSearch 是一个基于 Lucene 的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful web 接口.Elasticsearch 是用 Java 开 ...
- Solr6.5配置中文分词器
Solr作为搜索应用服务器,我们在使用过程中,不可避免的要使用中文搜索.以下介绍solr自带的中文分词器和第三方分词器IKAnalyzer. 注:下面操作在Linux下执行,所添加的配置在windo ...
- ElasticSearch中文分词器-IK分词器的使用
IK分词器的使用 首先我们通过Postman发送GET请求查询分词效果 GET http://localhost:9200/_analyze { "text":"农业银行 ...
- Elasticsearch系列---倒排索引原理与分词器
概要 本篇主要讲解倒排索引的基本原理以及ES常用的几种分词器介绍. 倒排索引的建立过程 倒排索引是搜索引擎中常见的索引方法,用来存储在全文搜索下某个单词在一个文档中存储位置的映射.通过倒排索引,我们输 ...
随机推荐
- 银河麒麟v4.0.2 安装gscloud的简单过程
1. 本来想用 tar包安装 redis 结果总是报错, 提示需要make test 但是我已经make test 了 所以还是使用 apt-get来安装. 2. 方式 apt-get update ...
- Requests的基本使用
Requests库 r=requests.get(url) #返回一个包含服务器资源的Response对象 #构造一个向服务器请求资源的Request对象 格式:requests.get(url,pa ...
- [HDU 3712] Fiolki (带边权并查集+启发式合并)
[HDU 3712] Fiolki (带边权并查集+启发式合并) 题面 化学家吉丽想要配置一种神奇的药水来拯救世界. 吉丽有n种不同的液体物质,和n个药瓶(均从1到n编号).初始时,第i个瓶内装着g[ ...
- [BZOJ 3930] [CQOI 2015]选数(莫比乌斯反演+杜教筛)
[BZOJ 3930] [CQOI 2015]选数(莫比乌斯反演+杜教筛) 题面 我们知道,从区间\([L,R]\)(L和R为整数)中选取N个整数,总共有\((R-L+1)^N\)种方案.求最大公约数 ...
- mac下安装php zookeeper扩展
安装步骤 php-zookeeper依赖libzookeeper,所以需要先安装libzookeeper 安装libzookeeper cd /usr/local/src/ wget http://m ...
- 常用的 Python 标准库都有哪些?
标准库:os 操作系统,time 时间,random 随机,pymysql 连接数据库,threading 线程,multiprocessing进程,queue 队列. 第三方库:django 和 f ...
- w3c之js学习总结
①JavaScript:改变 HTML 内容 <p id="demo">JavaScript 能改变 HTML 元素的内容.</p> <script& ...
- 03.AutoMapper 之反向映射与逆向扁平化(Reverse Mapping and Unflattening)
https://www.jianshu.com/p/d72400b337e0 AutoMapper现在支持更丰富的反向映射支持. 假设有以下实体: public class Order { publi ...
- mysqldump: [Warning] Using a password on the command line interface can be insecure.
MySQL 5.6 警告信息 command line interface can be insecure 修复 在命令行输入密码,就会提示这些安全警告信息. Warning: Using a pas ...
- java复习(6)String、StringBuffer以及StringBuilder
0.常见的编码表 ASC||:美国标准信息交换码,用一个字节的7位可以表示. ISO8859-1:拉丁码表.欧洲码表,用一个字节的8位来表示.无法存储汉字,或者只取了汉字的一半使用 GB2312:中文 ...