Task4.文本表示:从one-hot到word2vec
参考:https://blog.csdn.net/wxyangid/article/details/80209156
1.one-hot编码
中文名叫独热编码、一位有效编码。方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有其独立的寄存器位,并且任意时刻,有且仅有一个状态位是有效的。比如,手写数字识别,数字为0-9共10个,那么每个数字的one-hot编码为10位,数字i的第i位为1,其余为0,如数字2的one-hot表示为:[0,0,1,0,0,0,0,0,0,0]。
1.2one-hot在提取文本特征上的应用
one-hot在特征提取上属于词袋模型(bags of words)
假设语料库有这么三段话:
我爱中国
爸爸妈妈爱我
爸爸妈妈爱中国
对语料库分词并进行编号
1我;2爱;3爸爸;4妈妈;5中国
对每段话用onehot提取特征向量
则三段话由onehot表示为:
我爱中国 -> 1,1,0,0,1
爸爸妈妈爱我 ->1,1,1,1,0
爸爸妈妈爱中国 ->0,1,1,1,1
优点:可以将数据用onehot进行离散化,在一定程度上起到了扩充特征的作用
缺点:没有考虑词与词之间的顺序,并且假设词与词之间相互独立,得到的特征是离散稀疏的(如果365天用onehot,就是365维,会很稀疏)
在实际的机器学习的应用任务中,特征有时候并不总是连续值,有可能是一些分类值,如性别可分为“male”和“female”。在机器学习任务中,对于这样的特征,通常我们需要对其进行特征数字化,如下面的例子:
有如下三个特征属性:
性别:["male","female"] # 所有可能取值,0,1 两种情况
地区:["Europe","US","Asia"] #0,1,2 三种情况
浏览器:["Firefox","Chrome","Safari","Internet Explorer"] #0,1,2,3四种情况
所以样本的第一维只能是0或者1,第二维是0,1,2三种情况中的一种,第三维,是0,1,2,3四种情况中的一种。
对于某一个样本,如["male","US","Internet Explorer"],我们需要将这个分类值的特征数字化,最直接的方法,我们可以采用序列化的方式:[0,1,3]。但是这样的特征处理并不能直接放入机器学习算法中。
对上述问题,我们发现性别2维,地区3维,浏览器4维则我们进行onehot编码需要9维。对["male","US","Internet Explorer"]进行onehot编码为:[1,0,0,1,0,0,0,0,1]
下面看如何用代码实现:
from sklearn import preprocessing
oh = preprocessing.OneHotEncoder()
oh.fit([[0,0,3],[1,1,0],[0,2,1],[1,0,2]])#四个样本
oh.transform([[0,1,3]]).toarray()
结果:[[ 1. 0. 0. 1. 0. 0. 0. 0. 1.]]
[0,0,3] #表示是该样本是,male Europe Internet Explorer
[1,1,0] #表示是 female,us Firefox
[0,2,1]#表示是 male Asia Chrome
[1,0,2] #表示是 female Europe Safari
word2vec
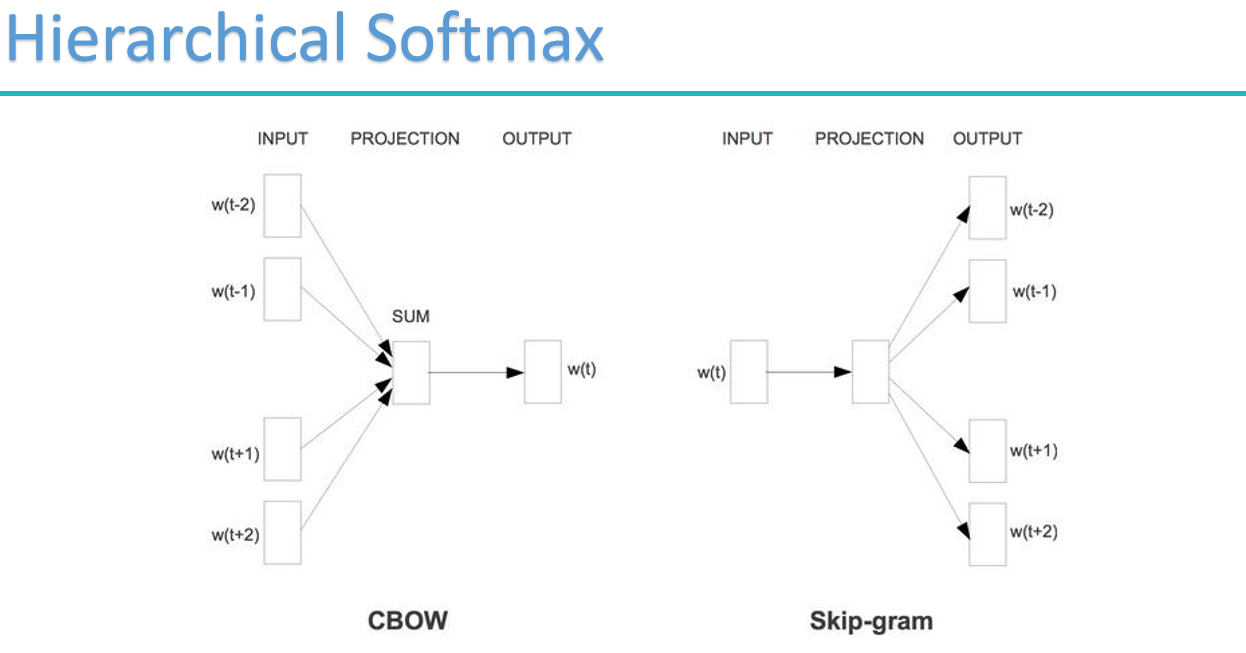
word2vec的两种重要模型:






梯度计算



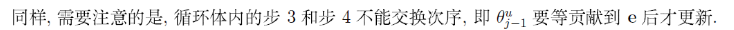

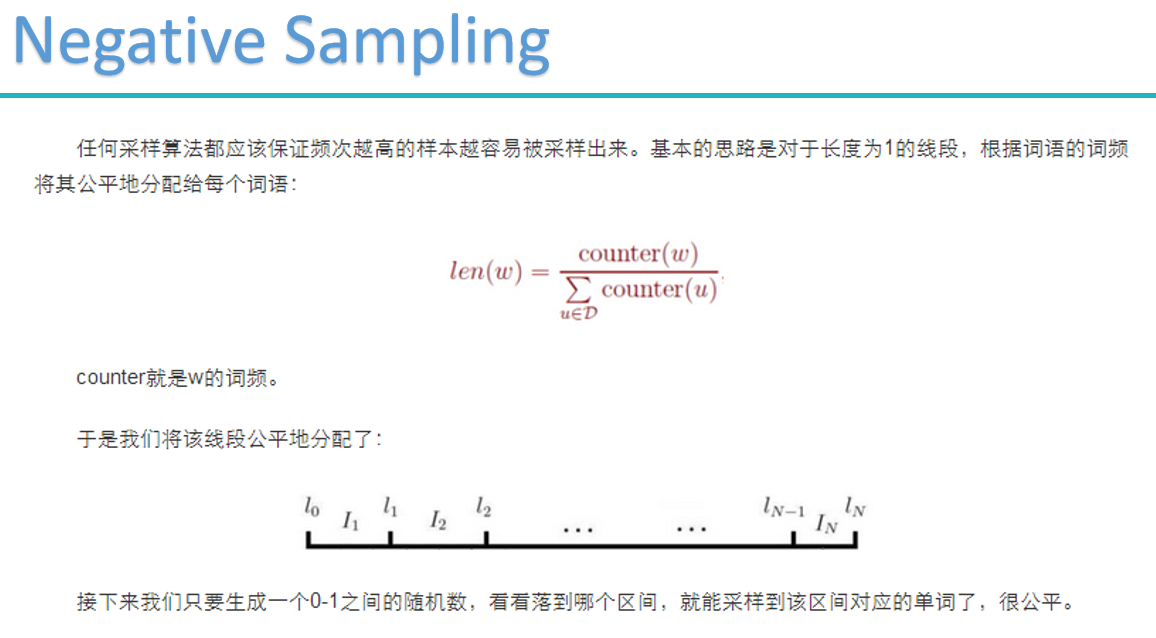



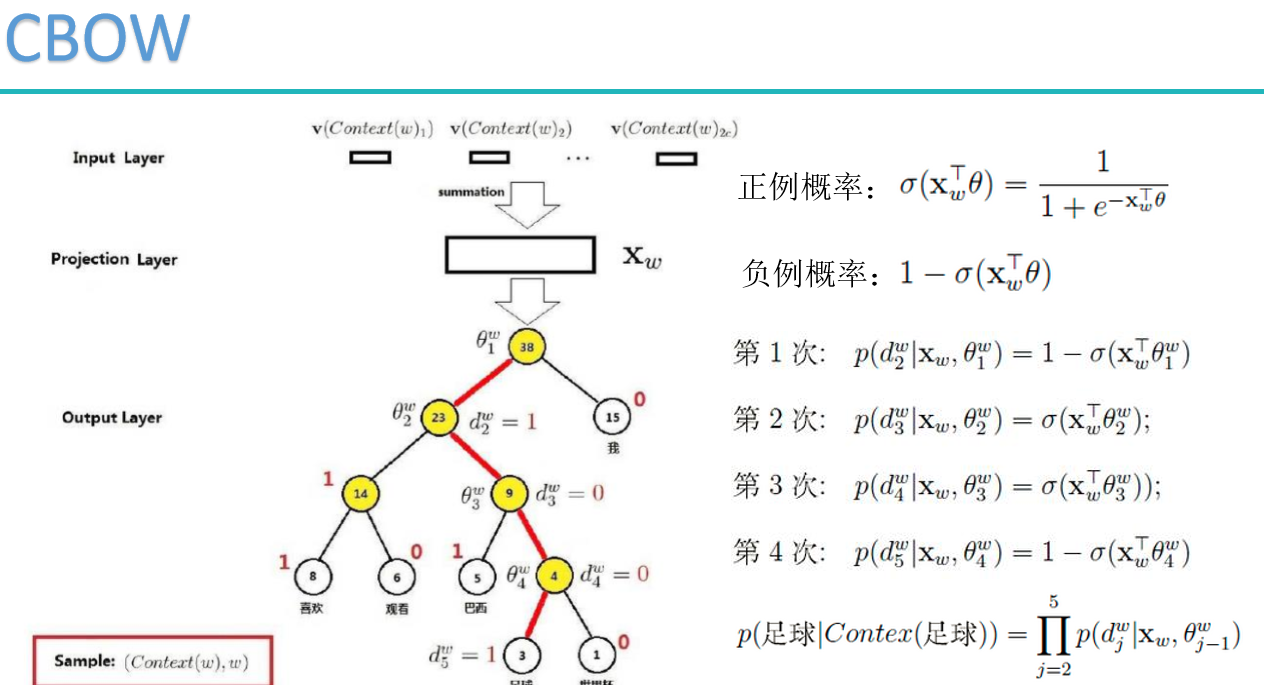
cbow:

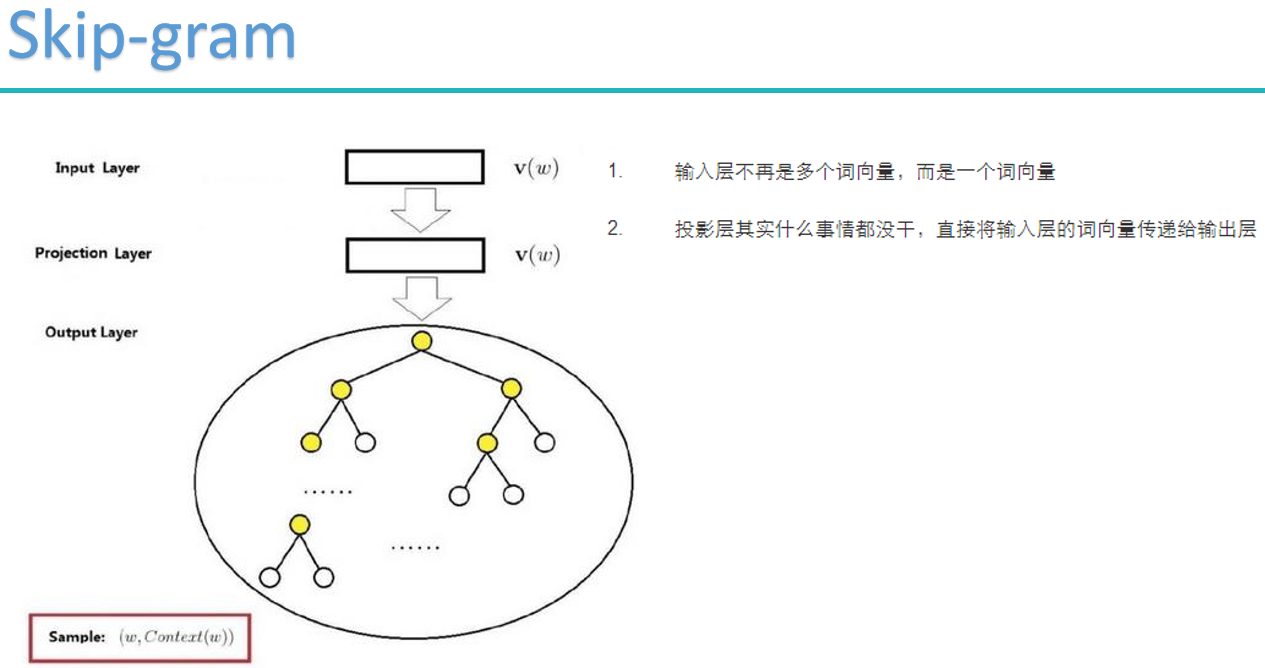
skip-gram




Task4.文本表示:从one-hot到word2vec的更多相关文章
- 文本情感分析(二):基于word2vec、glove和fasttext词向量的文本表示
上一篇博客用词袋模型,包括词频矩阵.Tf-Idf矩阵.LSA和n-gram构造文本特征,做了Kaggle上的电影评论情感分类题. 这篇博客还是关于文本特征工程的,用词嵌入的方法来构造文本特征,也就是用 ...
- 文本分类实战(一)—— word2vec预训练词向量
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- NLP点滴——文本相似度
[TOC] 前言 在自然语言处理过程中,经常会涉及到如何度量两个文本之间的相似性,我们都知道文本是一种高维的语义空间,如何对其进行抽象分解,从而能够站在数学角度去量化其相似性.而有了文本之间相似性的度 ...
- 重磅︱文本挖掘深度学习之word2vec的R语言实现
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:2013年末,Google发布的 w ...
- 文本分类实战(十)—— BERT 预训练模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本分类实战(九)—— ELMO 预训练模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本分类实战(八)—— Transformer模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本分类实战(七)—— Adversarial LSTM模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本分类实战(六)—— RCNN模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
随机推荐
- C++中让人忽视的左值和右值
前言 为了了解C++11的新特性右值引用,不得不重新认识一下左右值.学习之初,最快的理解,莫过于望文生义了,右值那就是赋值号右边的值,左值就是赋值号左边的值.在中学的数学的学习中,我们理解的是,左值等 ...
- sc 使用了配置中心后,如何设置远程和本地配置的优先级
在 spring 中,如何获取一个 key 的值? applicationContext.getEnvironment().getProperty("swagger.show") ...
- 阶段1 语言基础+高级_1-3-Java语言高级_1-常用API_1_第3节 Random类_8-Random概述和基本使用
用来产生随即数字 构造方法有一个是为空的 每次运行数值都不一样
- 微服务架构spring cloud - gateway网关限流
1.算法 在高并发的应用中,限流是一个绕不开的话题.限流可以保障我们的 API 服务对所有用户的可用性,也可以防止网络攻击. 一般开发高并发系统常见的限流有:限制总并发数(比如数据库连接池.线程池). ...
- 剑指offer(2):字符串
C语言中的字符串 C语言中字符串的存储方式和数组类似,都是连续定长的内存块.字符串数组以\0结尾,所以会比正常数组多一位,char str3[5] = "1234"; //此处赋值 ...
- 应用安全 - 代码审计 - Python
flask客户端session导致敏感信息泄露 flask验证码绕过漏洞 CodeIgniter 2.1.4 session伪造及对象注入漏洞 沙箱逃逸
- MySql-8.0.16版本部分安装问题修正
本帖参考网站<https://blog.csdn.net/lx318/article/details/82686925>的安装步骤,并对8.0.16版本的部分安装问题进行修正 在MySQL ...
- Java-多线程第四篇线程池
1.什么是线程池. 线程池在系统启动的时候即创建大量的空闲的线程,程序将一个Runnable对象或者Callable对象传给线程池,线程池就会启动一个线程来执行它们的run()或者call()方法,当 ...
- Vue源码详细解析:transclude,compile,link,依赖,批处理...一网打尽,全解析!
用了Vue很久了,最近决定系统性的看看Vue的源码,相信看源码的同学不在少数,但是看的时候却发现挺有难度,Vue虽然足够精简,但是怎么说现在也有10k行的代码量了,深入进去逐行查看的时候感觉内容庞杂并 ...
- [2019杭电多校第四场][hdu6623]Minimal Power of Prime
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6623 题目大意为求一个数的唯一分解的最小幂次.即120=23*31*51则答案为1. 因为数字太大不能 ...