MapReduce工作流程及Shuffle原理概述
引言:
虽然MapReduce计算框架简化了分布式程序设计,将所有的并行程序均需要关注的设计细节抽象成公共模块并交由系统实现,用户只需关注自己的应用程序的逻辑实现,提高了开发效率,但是开发如果对Mapreduce计算框架如何实现这样的魔术没有一个基本的了解,那么在面临多任务、大数据而出现大量数据倾斜,计算速度慢等问题时,将无法给出解决方案。也无法在设计MapReduce程序时根据框架的特性优化逻辑算法,所以了解MapReduce工作流程和Shuffle原理是学习MapReduce程序设计的必修课。在初学hadoop时,看过的书籍和课程都偏向于把Yarn和MapReduce的原理分开来介绍,这就像把厨师(Yarn)和做菜流程(MapReduce)分开介绍一样,初学者往往很难将两者结合起来,本文努力将厨师和如何制作每道菜的整个流程结合起来,介绍MapReduce和Yarn的工作原理。本人才疏学浅,此文为个人愚见,如有不正,希望各位不吝指正。
下文的逻辑不涉及源码:
Yarn是什么东西?
首先,Yarn由Resourcemanager、NodeManager、ApplicationMaster、Container等组件构成,他就像是一个分布式的操作系统,负责整个MapReduce程序计算过程中所有的数据和资源的调度,这种资源的调度表现在某一MapReduce任务进行到具体的某一阶段时,资源的调度就由Yarn某一具体的组件负责,你可以把他比作厨子在每道菜的制作进行到各个流程时,会使用不同的厨具。

对于Yarn的介绍就先到这一步,下面来介绍制作这道菜(MapReduce)需要哪些准备工作吧:
在使用API客户端提交MapReduce程序到Hadoop集群上的过程中,程序执行到 job.waitForCompletion(ture),首先调用connect方法,初始化Cluster对象,然后用这个对象创建JobRunner,如果获得的Cluster是Yarn集群集群的抽象,那么这个Cluster返回的JobRunner就是YarnRunner了,而如果获得的Cluster是本机文件系统的抽象,那么JobRunner就是LocalJobRunner(这里不再赘述LocalJobRunner以及本地运行模式是如何执行)。YarnRunner会向Resourcemanager节点发送一个Application,Resourcemanager收到(Application)申请后返回给申请所在节点一个hdfs上的路径(hdfs://.../.staging/)以及application_id,随后YarnRunner将数据的切片信息(job.split)、本次job的配置信息(job.xml)、MapReduce程序打成的jar包提交到hdfs://.../.staging/application_id/这个路径下。至此,食材(数据)准备好了,制作方案(job.xml)和食材的切法也准备好了,下面就开始制作了。
当job.split、job.xml、jar包都提交到hdfs://.../.staging/application_id/目录以后,YarnRunner会通知Resourcemanager资源提交完毕,进而向Resourcemanager申请一个MR ApplicationMaster,Resourcemanager将此次请求初始化为一个Task,并放入资源调度器中(老版本的资源调度器是一个单列的FIFO结构,现在的版本是多列FIFO结构)。此后空闲的某一NodeManager节点(大概率是被计算数据所在的节点)会从Resourcemanager节点的调度队列中领取此Task任务,领取到此Task后,会初始化一个MR ApplicationMaster并向Resourcemanager节点注册自己以表明身份信息,注册完成后创建Container用于保存抽象化的本地硬件资源(注意:并不是一个节点只能存在一个Container,而是当一个节点接收到一个MapReduce计算任务时,会为该任务所需的资源单独创建一个Container,如果一个节点处理多个MapReduce任务时,就会创建多个Container,所以我们说,MapReduce是运行在Container中的),这些资源包括CPU和RAM等等。完成Container的创建后,此NodeManager会将hdfs://.../.staging/application_id/下的本次job的数据信息(不是数据本体,而是包含了切片信息和数据所在节点的信息)下载到本节点。随后MR ApplicationMaster会根据split切片数量向Resourcemanager申请相应数量的节点作为计算节点(map节点),我们把用于map计算的节点称为MapTask容器。Resourcemanager收到申请后同样会在调度队列中创建Task,然后会有相应数量的节点(大概率是数据本体所在节点)成为MapTask容器,即map计算节点,MapTask也会为此MapReduce任务创建Container,当一个节点有能力并且同时处理多个MapReduce任务时,会为每一个任务所需的资源单独创建一个Container保存抽象的资源。Resourcemanager会把这些节点的地址通知给MR ApplicationMaster所在节点,随后,MR ApplicationMaster向map节点发送程序启动脚本。等map计算完成后(不严谨,事实上是部分的Map计算完成后就会启动ReduceTask,而非所有map),会将数据落到磁盘。最后MR ApplicationMaster会向Resourcemanager申请ReduceTask容器用于处理reduce计算,ReduceTask也会放入调度队列中。申请ReduceTask容器的数量是在客户端指定的,如果没有指定,则默认为一个ReduceTask。ReduceTask所在节点对从map节点中拷贝属于自己分区内的数据进行reduce操作。最后将计算结果输出给context,由OutputFormat格式化后保存到文件。
大概的工作流程如下图(下图忽略了map落盘reduce输出落盘):

这是这位厨师做菜的工作流程和用到的厨具,而具体每道菜的制作方案又不尽相同,有的要切细一点,有的要大块大块的制作,有的讲究特定的排放顺序以达到美观的效果,也有讲究一菜多盘以区分口味。同样,具体的MapReduce任务中可能出现复杂多变的需求,这也体现了数据清洗所包含的魅力 。
尽管MapReduce任务流程繁杂多变,却可以从宏观角度来研究单个进程:

上面介绍说:MR Applicationmaster根据hdfs://.../.staging/application_id/下的信息计算出切片数后,Resourcemanager会分配相应数量的机器MapTask节点做map计算。这里取其中一个MapTask为例,来研究一个map节点的工作细节:
MapTask1首先会使用InPutFormat对文件进行实质上的截取并使用RecordReader将文件数据转化为K-V对,这个阶段为format(格式化)阶段。格式化的意义在于将数据变成Mapper方法可以接收的K-V类型(即参数类型),map方法经处理后又以K-V对的形式将数据写回context中。然后由outputCollector将数据进行收集,outputCollector在将数据写到shuffle之前,会计算该数据(K-V)的分区号,然后将K-V和分区号一并写入shuffle中。默认情况下是按照Key的哈希值和Integer的最大值做与运算然后和RedueTask数量进行模运算,进而计算出分区数,但是这个ReduceTask的数量是可以在Driver中人为指定的,如果不指定则默认为1,也就说默认情况下(不指定分区方法和ReduceTask数量)所有的Key-Value只会计算出一个分区号。
上图所示为两个分区号,这是自定义分区和RedueTask数为2。但是注意,这里只是调用了ReduceTask的数值,还没有进入Reduce阶段,现阶段属于Map阶段。
你可能会问,这不也是固定的流程吗?怎么会体现“设计理念”呢?其实设计就体现在InputFormat、RecordReader、OutputCollector这些都是可以自定义的,由于自定义的InputFormat和RecordReader(事实上自定义InputFormat的核心就是自定义RecordReader),同样的数据会以不同的K-V形式输给map方法,数据处理自然也会有更多的灵活性,自定义OutputCollector中自定义分区计算方法,会让map输出的key-value对根据开发者的意愿计算出一个分区号,并交给shuffle处理,Shuffle会对带有同一分区号的数据进行区内排序,当数据排序完成后会溢写到磁盘中,溢写出的数据具有分区且区内有序的特点,而往往(并非绝对)数据的分区号也决定了该区号的数据最终交给哪一个ReduceTask处理。关于自定义InputFormat和OutputCollector不是本文的重点,这里不再赘述。
当数据进入Shuffle后,又经历了什么呢?下面详细介绍上图红框内的工作流程:

首先,进入Shuffle的数据会在SHuffle中进行一次快排:

排序流程大致如下:Shuffle可以看作为内存中的一个环形集合,首尾相接,结构上类似于双向链表。当K-V带着分区号进入Shuffle后,Shuffle会将同一分区的数据进行一次快排,Shuffle分为两个部分,按图示,两个部分分别用于存储索引标识和K-V对。在排序时采用如下方案:假如索引为2的K-V大于索引为1的K-V值,就会将标识为2的K-V的索引放到第一位。也就是说:Shuffle排序并不对数据本身做移动,而是对数据体量较小的索引标识做移动,这样降低了IO压力。当数据排序完成并且Shuffle中存储的数据占了Shuffle空间(100mb)的80%时(这个可以自定义),会按照逆时针的顺序(2>1>4>3)将对应的K-V值溢写到磁盘中。溢写出来的数据的特点就是分区且区内有序。在数据量较大时,会发生多次溢写。
Shuffle排序的规则也可以由开发者自定义,很多情况下,key是用户自定义的Javabean类型,并且希望Shuffle在排序时按照该类型的一个或多个属性值进行排序,而不是用SHuffle原生的排序规则,就可以自定义排序器。
为了方便讲解,下面将使用案例的方式,【】内的数据为一个分区,分区号为从左往右由0开始数。
我们知道相同key的一组key-vlaue对会“组团”调用一次Reduce的ruduce方法。那么在数据从内存(Shuffle)溢写到磁盘的过程中<第一处可以引入Combiner的地方>可以加一个Combiner,其本质就是一个Reducer,会对数据进行一轮的合并,比如第一轮溢写出的两个分区内的数据为{【(a,1),(a,1),(c,1)】,【(B,1),(B,1),(D,1),(D,1)】},两个分区(本例以大小写分区)内的数据虽然有序,但是数据有冗余,当相同的K-V值数量很多时,会对IO造成不必要的压力,所以在此环节中引入Combiner将数据合并为{【(a,2),(c,1)】}、{【(B,2),(D,2)】}两个分区(默认情况下Combiner是不开启的,在不影响数据正确性的情况下建议开启),这样再将数据从内存写入硬盘时,IO压力就会降低。在默认情况下Combiner是不开启的,因为在很多业务场景中,Combiner可能会造成数据的误差。附:Combiner其实就是一个Reducer,他的工作和Reducer一样是对同一组的数据做处理,而且实现相同的接口(Reducer<>),所以很多情况(Combiner与某一Reducer逻辑相同)下,可以直接使用已经定义好Reducer作Combiner。

上图虽然将分区和排序从Shuffle环中画了出来,但实质上排序和分区都是在Shuffle中完成的,并且没有先后顺序。
多次溢写出多组数据,产生多个文件,假设第一组的结果如{【(a,2),(c,1)】}、{【(B,2),(D,2)】},第二轮溢写并合并的结果为{【(a,3),(c,2)】}、{【(B,1),(D,3)】}。那么进行归并排序后变成{【(a,2),(a,3),(c,1),(c,2)】},{【(B,2),(B,1),(D,2),(D,3)】}依旧会存在相同的Key的情况,那么也可以选择在归并排序时使用Combiner进行合并<第二处可以引入Combiner的地方>,结果为:{【(a,5),(c,3)】}、{【(B,3),(D,5)】},这是一个MapTask的工作结果,当存在多个MapTask时,会产生多组输出数据,假设存在第二个MapTask节点的输出结果为:{【(a,3),(c,4)】}、{【(B,2),(D,6)】}。至此MapTask的工作完成了。
map阶段结束。
现在进入ReduceTask阶段,假设我们设定了两个ReduceTask,并且自定义了分区规划:将分区一(key小写字母的一组)交给ReduceTask1来处理,将分区2交给ReduceTask2处理,那么所有MapTask输出结果中的分区1的数据都会进入ReduceTask1中(分区2的数据进入ReduceTask2中,不论是哪一个MapTask产生的),先进行一轮归并排序,然后按照相同的Key分组,比如分区1分为两组:【(a,5),(a,3)】、【(c,3),(c,4)】,然后一组一组的调用Reducer的reduce方法【即相同的Key作为一组数据调用一次reduce方法,把values保存在reduce方法的values数组中,然后循环反序列化,将一对一对的序列化K-V值反序列化注入(set方法)到注入到reduce内自定义的key和value对象中,从始至终用于接收反序列化结果的key—value对象固定不变,但是循环反序列过程中自定义的对象的属性值却依次的按照本次处理的数据集合(values)内元素的顺序而改变】,最后reduce方法将(a,8)、(c,7)写回context中,交给OutputFormat处理,最终输出两个输出文件。
注意1:此外,当存在多个ReduceTask时,默认情况下一个ReduceTask只处理一个分区的数据,但是可以通过自定义Partitioner的方式(继承HashPartitioner重写getPartition方法)将具体的一个或多个分区路由给某一ReduceTask处理,也可以将一个分区内的一部分数据路由给某个ReduceTask处理。
注意2:虽然默认情况下是key相同的作为一组调用一次reduce方法,即以key为传入key,以value组成的列表values传入reduce方法,下一组key相同的再调用一次reduce方法,每组key-values分开调用。但是可以通过自定义GroupingComparator(k,knext)的方式“欺骗”reduce方法,强制的将不同的key划分成一组,调用一次reduce方法。事实上这只是改变了原有的分组方案。
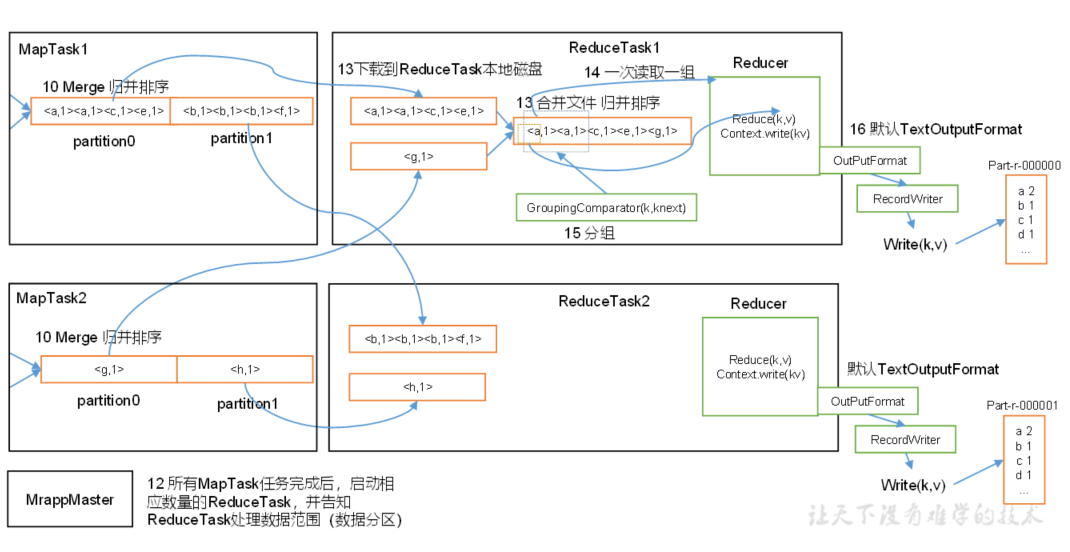
ReduceTask工作完成后,会将数据写回context,至此reduce阶段就结束了。由于存在两个ReduceTask,会产生两个输出文件。
需要额外补充:分区规划是可以自定义的,我们可以自定义哪些key进入同一分区,也可以自定义哪一分区交给那个ReduceTask处理,但需要注意,如果在指定某一分区交给一个不存在的ReduceTask时,会报错,如果自定义了较多的ReduceTask,而实际用于处理固定分区的ReduceTask又较小,就会产生节点资源的浪费,并且最终输出几个空文件。当某一Reducer节点接收的数据量大于其他Reducer节点时,计算速度会明显慢于其他节点,这就是数据倾斜,解决数据倾斜的方法就是合理的分区,尽量使各分区内的数据量保持均衡。
最后OutputFormat以固定的格式将context中的数据写到文件中,这个OutputFormat也可以自定义,与自定义InPutFormat相同,自定义OutputFormat的核心是自定义RecordWriter,是RecordWriter决定以什么样的K-V格式写到文件中的。
MapReduce虽然将分布式计算的流程封装成一个框架,让用户使用单线程的开发模式开发分布式程序,但是作为框架,MapReduce却提供了比较高的灵活性。从自定义数据输入格式化InputFormat、RecordReader,到Mapper处理数据,到OutPutCollector自定义分区规则改变分区方案平衡各区数据量,到自定义Shuffle排序比较器改变排序方案,到自定义分组比较器改变分组方案“组团”调用reduce方法,到reduce方法处理数据,最后自定义OutputFormat改变输出数据的格式。从始至终,MapReduce提供的灵活性和遍历性让大规模数据的处理变得简单易行。
MapReduce工作流程及Shuffle原理概述的更多相关文章
- MapReduce Shuffle 和 Spark Shuffle 原理概述
Shuffle简介 Shuffle的本意是洗牌.混洗的意思,把一组有规则的数据尽量打乱成无规则的数据.而在MapReduce中,Shuffle更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规 ...
- MapReduce 工作流程
1. Map 阶段 ============================================= 2. Reduce 阶段
- MapReduce工作流程
- Hadoop(六)MapReduce的入门与运行原理
一 MapReduce入门 1.1 MapReduce定义 Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架: Mapreduce核心功能是将用 ...
- Spark Shuffle原理、Shuffle操作问题解决和参数调优
摘要: 1 shuffle原理 1.1 mapreduce的shuffle原理 1.1.1 map task端操作 1.1.2 reduce task端操作 1.2 spark现在的SortShuff ...
- <转>MapReduce工作原理图文详解
转自 http://weixiaolu.iteye.com/blog/1474172前言: 前段时间我们云计算团队一起学习了hadoop相关的知识,大家都积极地做了.学了很多东西,收获颇丰.可是开学 ...
- MapReduce简述、工作流程及新旧API对照
什么是MapReduce? 你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查而且数出有多少张是黑桃. MapReduce方法则是: 1. 给在座的全部玩家中分配这摞牌. 2. 让每一个玩家数自己手 ...
- 【生活现场】从打牌到map-reduce工作原理解析(转)
原文:http://www.sohu.com/a/287135829_818692 小史是一个非科班的程序员,虽然学的是电子专业,但是通过自己的努力成功通过了面试,现在要开始迎接新生活了. 对小史面试 ...
- MapReduce工作原理详解
文章概览: 1.MapReduce简介 2.MapReduce有哪些角色?各自的作用是什么? 3.MapReduce程序执行流程 4.MapReduce工作原理 5.MapReduce中Shuffle ...
随机推荐
- 四轴飞行器飞行原理与双闭环PID控制
四轴轴飞行器是微型飞行器的其中一种,相对于固定翼飞行器,它的方向控制灵活.抗干扰能力强.飞行稳定,能够携带一定的负载和有悬停功能,因此能够很好地进行空中拍摄.监视.侦查等功能,在军事和民用上具备广泛的 ...
- 前端每日实战:86# 视频演示如何用纯 CSS 创作一个方块旋转动画
效果预览 按下右侧的"点击预览"按钮可以在当前页面预览,点击链接可以全屏预览. https://codepen.io/comehope/pen/gjgyWm 可交互视频 此视频是可 ...
- pycharm安装第三方库失败module 'pip' has no attribute 'main'
用的pycharm2017.3,新创建一个项目,在安装appium-python-client时报错module 'pip' has no attribute 'main'.通过强大的度娘,知道是pi ...
- shiro框架在springboot项目中的应用
地址:https://blog.csdn.net/taojin12/article/details/88343990 地址2:https://blog.csdn.net/bicheng4769/art ...
- macOS gcc g++ c++ cc
安装完Xcode之后,系统中默认的编译器不再是Gcc系列,编译一些库的时候经常产生问题. 在PATH变量中设置symbol link,把gcc,g++,c++,cc全链接到Gcc系列.
- 【HDOJ6629】string matching(exkmp)
题意:给定一个长为n的字符串,求其每个位置开始于其自身暴力匹配出相同或不同的结果的总比较次数 n<=1e6 思路:exkmp板子 #include<bits/stdc++.h> us ...
- 20180813-Java 重写(Override)与重载(Overload)
Java 重写(Override)与重载(Overload) class Animal{ public void move(){ System.out.println("动物可以移动&quo ...
- css浮动现象及清除浮动的方法
css浮动现象及清除浮动的方法 首先先明确浮动最初的定义及使用场景:实现文本环绕图片的效果. 除了用浮动外,目前暂无其他方法实现文本环绕 再来看看浮动的具体定义: 浮动的框可以左右移动,直至它 ...
- ORA-00020: maximum number of processes (800) exceeded
[oracle@db04-1 ~]$ sqlplus -prelim / as sysdba SQL*Plus: Release 11.2.0.3.0 Production on 星期四 8月 31 ...
- C#-概念-类库:类库
ylbtech-C#-概念-类库:类库 1.返回顶部 1. 类库(Class Library)是一个综合性的面向对象的可重用类型集合,这些类型包括:接口.抽象类和具体类.类库可以解决一系列常见编程任务 ...