机器学习——k-均值算法(聚类)
k-均值(k-means)聚类
1、k-均值算法
k-均值算法是一种无监督学习,是一种“基于原型的聚类”(prototype-based clustering)方法,给定的数据是不含标签的D={x(1),x(2),...,x(i)}D=\{{x^{(1)},x^{(2)},...,x^{(i)}}\}D={x(1),x(2),...,x(i)},目标是找出数据的模式特征进行分类。如社交网络分析,通过用户特征进行簇划分,分出不同群体。
(图源网络,侵删)
2、k-均值算法的代价函数
给定数据集D={x(1),x(2),...,x(i)}D=\{{x^{(1)},x^{(2)},...,x^{(i)}}\}D={x(1),x(2),...,x(i)},k-均值聚类算法的代价函数(基于欧式距离的平方误差)为:
J=m1∑i=1m∣∣x(i)−uc(i)∣∣2J=\frac{m}{1}\sum_{i=1}^{m}||x^{(i)}-u_{c^{(i)}}||^2J=1mi=1∑m∣∣x(i)−uc(i)∣∣2
其中,c(i)c^{(i)}c(i)是训练样例x(i)x^{(i)}x(i)分配的聚类序号;uc(i)u_{c^{(i)}}uc(i)是 x(i)x^{(i)}x(i)所属聚类的中心点 。k-均值算法的代价函数函数的物理意义就是,训练样例到其所属的聚类中心点的距离的平均值。
3、k-均值算法步骤
k-均值算法主要包括:根据聚类中心分配样本类别——>更新聚类中心
- 随机选择K个聚类中心u1,u2,...,uKu_1,u_2,...,u_Ku1,u2,...,uK;
- 从1~m中遍历所有的数据集,计算x(i)x^{(i)}x(i)分别到u1,u2,...,uKu_1,u_2,...,u_Ku1,u2,...,uK的距离,记录距离最短的聚类中心点uku_kuk,然后把x(i)x^{(i)}x(i)这个点分配给这个簇,即令 c(i)=kc^{(i)}=kc(i)=k;
- 从1~k中遍历所有的聚类中心,移动聚类中心的新位置到这个簇的均值处,即uk=1ck∑j=1ckx(j)u_k=\frac{1}{c_k}\sum_{j=1}^{c_k}x^{(j)}uk=ck1∑j=1ckx(j),其中ckc_kck表示这个簇的样本数;
- 重复步骤2,直到聚类中心不再移动。
4、初始化聚类中心点和聚类个数
1、在实际应用的过程中,聚类结果会和我们初始化的聚类中心相关,因为代价函数可能会收敛在一个局部最优解上,而不是全局最优解。我们的解决方法是多次初始化,然后选取代价函数最小的。
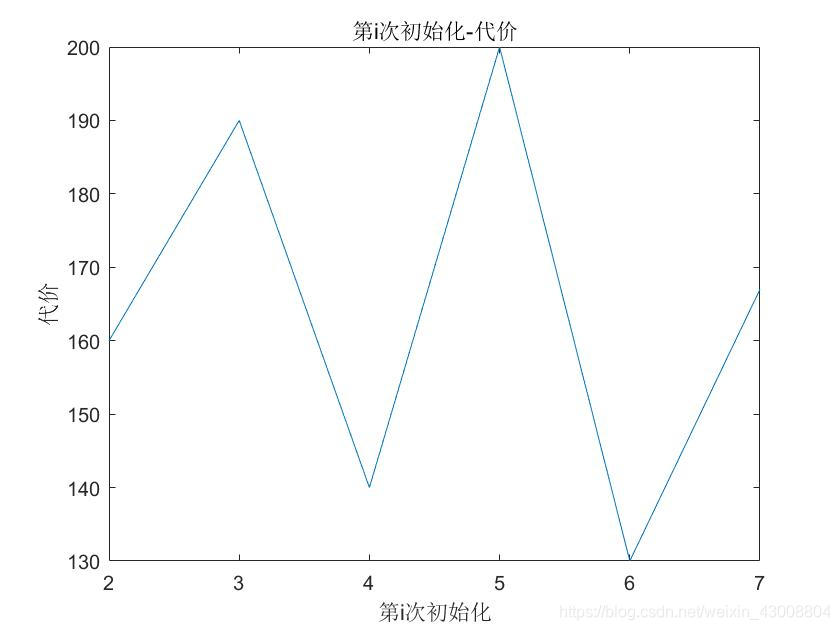
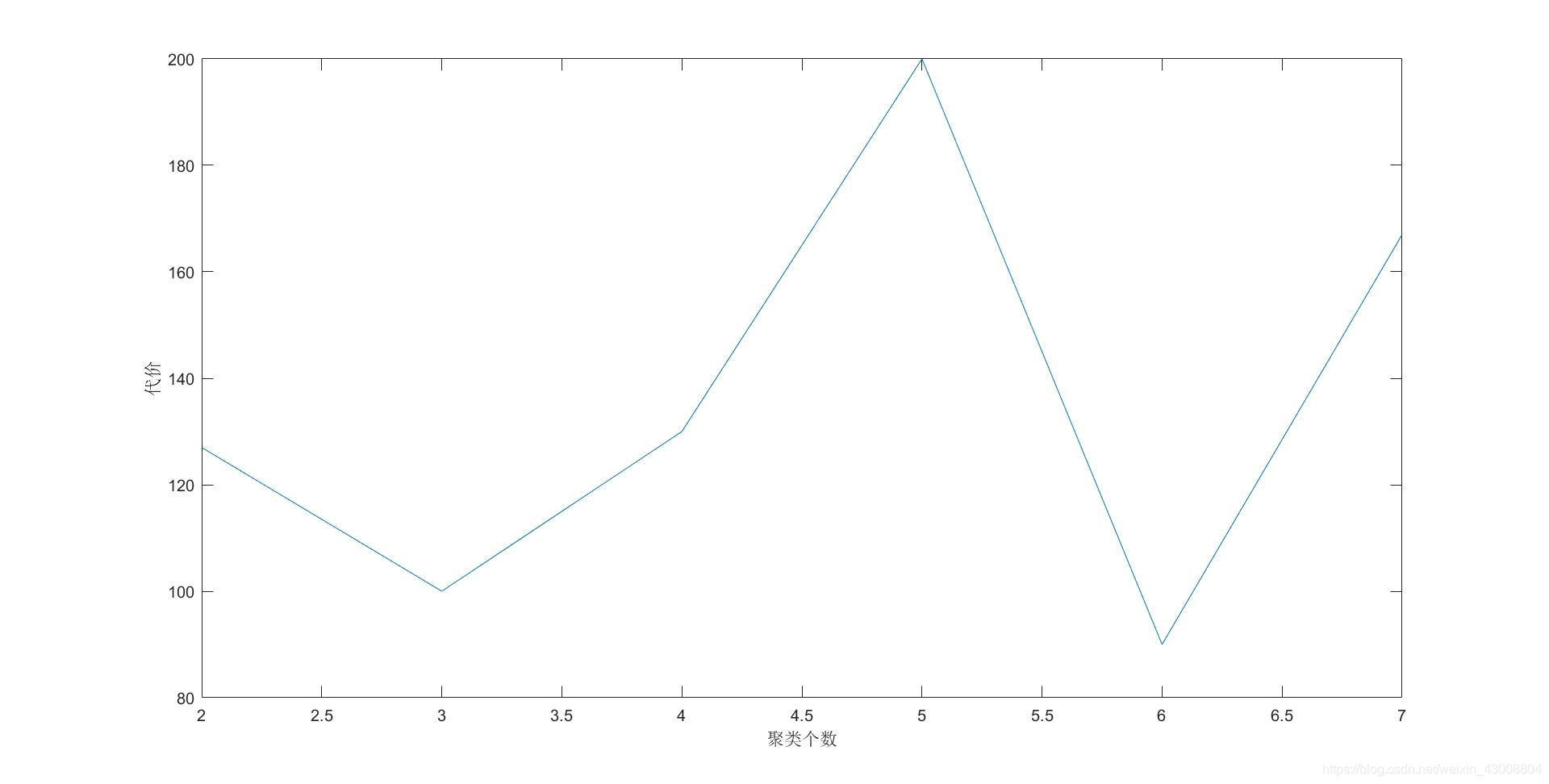
2、如果没有特别的业务要求,聚类个数如何选取?我们可以把聚类个数作为横坐标,代价函数作为纵坐标,找出拐点。
5、sklearn实现k-means算法
推荐一篇博文: 聚类效果评价
主函数KMeans
sklearn.cluster.KMeans(n_clusters=8,
init='k-means++',
n_init=10,
max_iter=300,
tol=0.0001,
precompute_distances='auto',
verbose=0,
random_state=None,
copy_x=True,
n_jobs=1,
algorithm='auto'
)
参数解释:
- n_clusters:簇的个数,即你想聚成几类
- init: 初始簇中心的获取方法
- n_init: 获取初始簇中心的更迭次数,为了弥补初始质心的影响,算法默认会初始10次质心,实现算法,然后返回最好的结果。
- max_iter: 最大迭代次数(因为kmeans算法的实现需要迭代)
- tol: 容忍度,即kmeans运行准则收敛的条件
- precompute_distances:是否需要提前计算距离,这个参数会在空间和时间之间做权衡,如果是True 会把整个距离矩阵都放到内存中,auto 会默认在数据样本大于featurs*samples 的数量大于12e6 的时候False,False 时核心实现的方法是利用Cpython 来实现的
- verbose: 冗长模式(不太懂是啥意思,反正一般不去改默认值)
- random_state: 随机生成簇中心的状态条件。
- copy_x: 对是否修改数据的一个标记,如果True,即复制了就不会修改数据。bool 在scikit-learn 很多接口中都会有这个参数的,就是是否对输入数据继续copy 操作,以便不修改用户的输入数据。这个要理解Python 的内存机制才会比较清楚。
- n_jobs: 并行设置
- algorithm: kmeans的实现算法,有:‘auto’, ‘full’, ‘elkan’, 其中 'full’表示用EM方式实现
代码:
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 20 18:52:21 2019
@author: 1
"""
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
df=pd.read_csv('D:\\workspace\\python\machine learning\\data\\iris.csv',sep=',')
data=df.iloc[:,0:3]
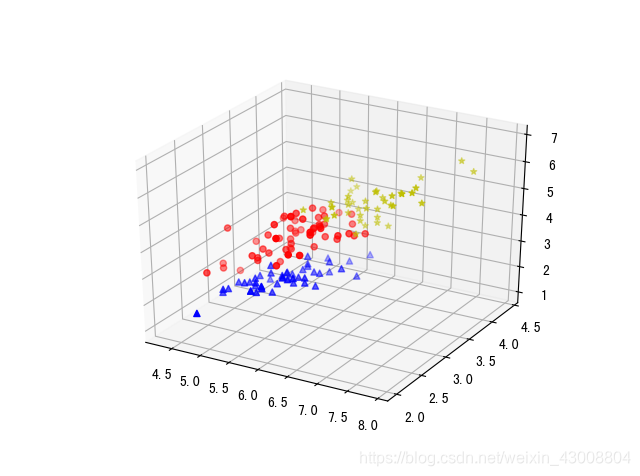
kmeans=KMeans(n_clusters=3) #n_clusters:number of cluster
kmeans.fit(data)
labels=kmeans.labels_#聚类标签
centres=kmeans.cluster_centers_#聚类中心
#画三维聚类结果图
markers=['o','^','*']
colors=['r','b','y']
data['labels']=labels
ax = plt.subplot(111, projection='3d') # 创建一个三维的绘图工程
data_new,X,Y,Z=[[]]*3,[[]]*3,[[]]*3,[[]]*3
for i in range(3):
data_new[i]=data.loc[data['labels']==i]
X[i],Y[i],Z[i]=data_new[i].iloc[:,0],data_new[i].iloc[:,1],data_new[i].iloc[:,2]
ax.scatter(X[i],Y[i],Z[i],marker=markers[i],c=colors[i])
聚类结果:
机器学习——k-均值算法(聚类)的更多相关文章
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- 机器学习算法之Kmeans算法(K均值算法)
Kmeans算法(K均值算法) KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑 ...
- 使用K均值算法进行图片压缩
K均值算法 上一期介绍了机器学习中的监督式学习,并用了离散回归与神经网络模型算法来解决手写数字的识别问题.今天我们介绍一种机器学习中的非监督式学习算法--K均值算法. 所谓非监督式学习,是一种 ...
- K 均值算法-如何让数据自动分组
公号:码农充电站pro 主页:https://codeshellme.github.io 之前介绍到的一些机器学习算法都是监督学习算法.所谓监督学习,就是既有特征数据,又有目标数据. 而本篇文章要介绍 ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
- KMeans (K均值)算法讲解及实现
算法原理 KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标 ...
随机推荐
- Codeforces Round #545 (Div. 2) E 强连通块 + dag上求最大路径 + 将状态看成点建图
https://codeforces.com/contest/1138/problem/E 题意 有n个城市(1e5),有m条单向边(1e5),每一周有d天(50),对于每个城市假如在某一天为1表示这 ...
- [THUPC2018]生生不息(???)
SB题,写来放松身心. 首先 $n,m\le 5$,这是可以打表的. 本地怎么对于一个 $n,m$ 求答案?此时虽然复杂度不需要太优,但是还是得够快. 一个想法是枚举每个初始状态,不停模拟.因为总状态 ...
- [LeetCode] 642. Design Search Autocomplete System 设计搜索自动补全系统
Design a search autocomplete system for a search engine. Users may input a sentence (at least one wo ...
- Cipolla算法学习笔记
学习了一下1个$\log$的二次剩余.然后来水一篇博客. 当$p$为奇素数的时候,并且$(n, p) \equiv 1 \pmod{p}$,用Cipolla算法求出$x^2 \equiv n \pmo ...
- JVM系列之六:内存溢出、内存泄漏 和 栈溢出
1. OOM && SOF OutOfMemoryError异常: 除了程序计数器外,虚拟机内存的其他几个运行时区域都有发生OutOfMemoryError(OOM)异常的可能, 内存 ...
- 三大类sql语句——该记录是本人以前微博上的文章
一.DML语句二.DDL语句三.事务控制语句一.DML语句-Data Mulipulation LanguageDML语句数据操作野菊执行后会生成一个事务,事务需要提交才能够永久生效,在commit前 ...
- CentOS7 SUDO 笔记--没配置sudoer,为什么有的账号能用sudo命令,有的不能用
原来: 一.安装linux 创建的用户(管理员打钩)默认在 wheel组里. 1. 使用 cat /etc/passwd 查看用户所在组.中间那个数字是 groupid 不太好看 2.使用 cat / ...
- 关于stm32f10x_conf.h文件
简介 stm32f10x_conf.h文件有2个作用:①提供对assert_param运行时参数检查宏函数的定义.②将开发者用到的标准外设头文件集中在这个文件里面,而stm32f10x_conf.h又 ...
- 《 .NET并发编程实战》实战习题集 - 3 - CRUD项目中使用FP
先发表生成URL以印在书里面.等书籍正式出版销售后会公开内容.
- centos切换php版本
centos服务器上安装了php5.3到php7.2版本的php,默认使用php -v,查看到的php版本信息为: 修改环境变量文件:vim /etc/profile shift+g跳转到最后一行环境 ...