Linux内核链表复用实现队列

有了前面Linux内核复用实现栈的基础,使用相同的思想实现队列,也是非常简单的。普通单链表复用实现队列,总会在出队或入队的时候有一个O(n)复杂度的操作,大多数采用增加两个变量,一个head,一个tail来将O(n)降成O(1)。但是在内核链表中,天然的双向循环链表,复用实现队列,无论出队还是入队,都是O(1)时间复杂度。
/* main.c */ #include <stdio.h>
#include <stdlib.h> #include "queue.h" struct person
{
int age;
struct list_head list;
}; int main(int argc,char **argv)
{
int i;
int num =;
struct person *p;
struct person head;
struct person *pos,*n; queue_creat(&head.list); p = (struct person *)malloc(sizeof(struct person )*num); for (i = ;i < num;i++) {
p->age = i*;
in_queue(&p->list,&head.list);
p++;
}
printf("original==========>\n");
list_for_each_entry_safe(pos,n,&head.list,list) {
printf("age = %d\n",pos->age);
}
printf("size = %d\n",get_queue_size(&head.list));
struct person test;
test.age = ;
printf("out_queue %d\n",get_queue_head(pos,&head.list,list)->age);
out_queue(&head.list);
printf("out_queue %d\n",get_queue_head(pos,&head.list,list)->age);
out_queue(&head.list);
printf("in_queue %d\n",test.age);
in_queue(&test.list,&head.list); printf("current==========>\n");
list_for_each_entry_safe(pos,n,&head.list,list) {
printf("age = %d\n",pos->age);
}
printf("size = %d\n",get_queue_size(&head.list));
printf("all member out_queue\n");
list_for_each_entry_safe(pos,n,&head.list,list) {
out_queue(&head.list);
}
printf("size = %d\n",get_queue_size(&head.list));
if (is_empt_queue(&head.list)) {
printf("is_empt_queue\n");
} return ;
}
/* queue.c */ #include "queue.h" void queue_creat(struct list_head *list)
{
INIT_LIST_HEAD(list);
} void in_queue(struct list_head *new, struct list_head *head)
{
list_add_tail(new,head);
} void out_queue(struct list_head *head)
{
struct list_head *list = head->next; /* 保存链表的最后节点 */ list_del(head->next);/* 头删法 */ INIT_LIST_HEAD(list); /* 重新初始化删除的最后节点,使其指向自身 */ } int get_queue_size(struct list_head *head)
{
struct list_head *pos;
int size = ; if (head == NULL) {
return -;
} list_for_each(pos,head) {
size++;
} return size; } bool is_empt_queue(struct list_head *head)
{
return list_empty(head);
}
/* queue.h */ #ifndef _QUEUE_H_
#define _QUEUE_H_ #include <stdbool.h>
#include "list.h" #define get_queue_head(pos, head, member) \
list_entry((head)->next, typeof(*pos), member) void queue_creat(struct list_head *list);
void in_queue(struct list_head *new, struct list_head *head);
void out_queue(struct list_head *entry);
int get_queue_size(struct list_head *head);
bool is_empt_queue(struct list_head *head); #endif /* _QUEUE_H_ */
运行结果:
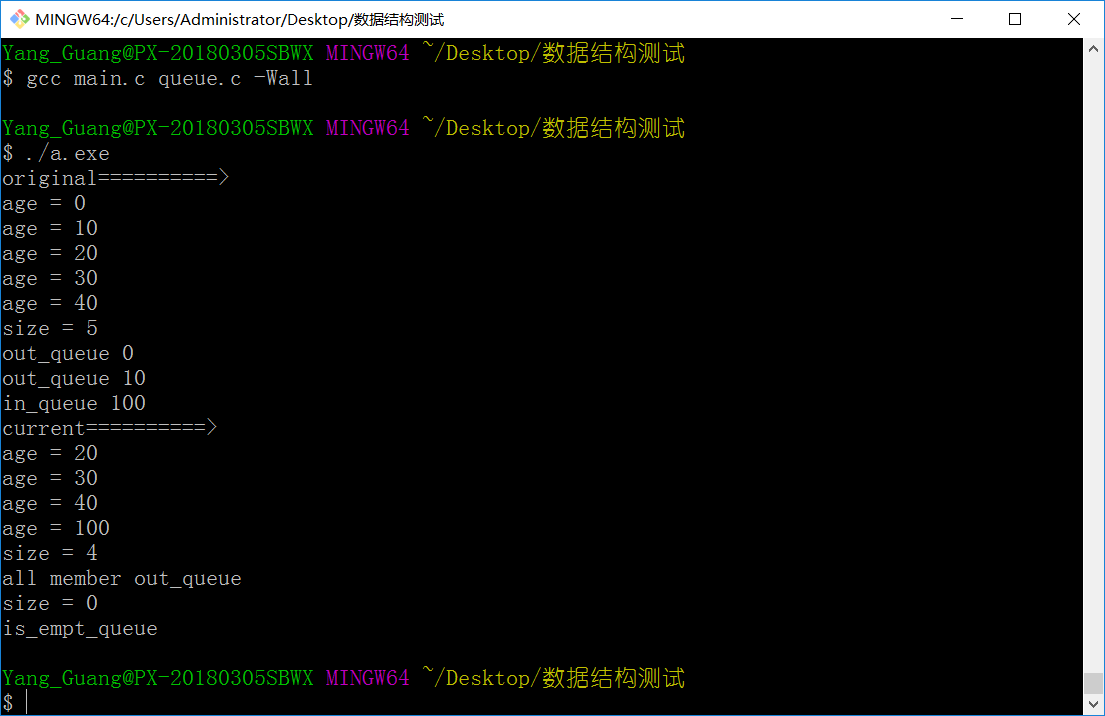
复用Linux内核链表实现队列,时间复杂可以很简单的实现O(1),当然,其中的遍历队列长度是O(n),不过这个在之前的随笔中也说到了,根据具体的应用场景,可以在入队的时候在头结点中size+1,出队的时候在头结点中size-1,获取队列大小的函数就可以直接返回size了,是可以很轻易做到O(1)的时间复杂度的。掌握了Linux内核链表,链表,栈和队列这样的数据结构,就可以很容易的实现复用,并且可以应用在实际项目中。
Linux内核链表复用实现队列的更多相关文章
- Linux内核链表复用实现栈
我们当然可以根据栈的特性,向实现链表一样实现栈.但是,如果能够复用已经经过实践证明的可靠数据结构来实现栈,不是可以更加高效吗? so,今天我们就复用Linux内核链表,实现栈这样的数据结构. 要实现的 ...
- Linux 内核 链表 的简单模拟(1)
第零章:扯扯淡 出一个有意思的题目:用一个宏定义FIND求一个结构体struct里某个变量相对struc的编移量,如 struct student { int a; //FIND(struct stu ...
- 链表的艺术——Linux内核链表分析
引言: 链表是数据结构中的重要成员之中的一个.因为其结构简单且动态插入.删除节点用时少的长处,链表在开发中的应用场景许多.仅次于数组(越简单应用越广). 可是.正如其长处一样,链表的缺点也是显而易见的 ...
- C语言 Linux内核链表(企业级链表)
//Linux内核链表(企业级链表) #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include<stdlib.h> ...
- 深入分析 Linux 内核链表--转
引用地址:http://www.ibm.com/developerworks/cn/linux/kernel/l-chain/index.html 一. 链表数据结构简介 链表是一种常用的组织有序数据 ...
- Linux 内核链表
一 . Linux内核链表 1 . 内核链表函数 1.INIT_LIST_HEAD:创建链表 2.list_add:在链表头插入节点 3.list_add_tail:在链表尾插入节点 4.list_d ...
- linux内核链表分析
一.常用的链表和内核链表的区别 1.1 常规链表结构 通常链表数据结构至少应包含两个域:数据域和指针域,数据域用于存储数据,指针域用于建立与下一个节点的联系.按照指针域的组织以及各个节 ...
- 深入分析 Linux 内核链表
转载:http://www.ibm.com/developerworks/cn/linux/kernel/l-chain/ 一. 链表数据结构简介 链表是一种常用的组织有序数据的数据结构,它通过指 ...
- Linux 内核 链表 的简单模拟(2)
接上一篇Linux 内核 链表 的简单模拟(1) 第五章:Linux内核链表的遍历 /** * list_for_each - iterate over a list * @pos: the & ...
随机推荐
- FFMPEG 命令行工具- ffmpeg
ffmpeg 简介 ffmpeg 用于转码的应用程序,命令格式: ffmpeg [options] [[infile options] -i infile]... {[outfile options] ...
- ARM处理器基础知识
1.ARM处理器的寄存器,ARM与Thumb状态,7中运行模式 http://blog.chinaunix.net/uid-28458801-id-3494646.html 2.ARM的7种工作模式. ...
- 浅谈原子操作、volatile、CPU执行顺序
浅谈原子操作.volatile.CPU执行顺序 在计算机发展的鸿蒙年代,程序都是顺序执行,编译器也只是简单地翻译指令,随着硬件和软件的飞速增长,原来的工具和硬件渐渐地力不从心,也逐渐涌现出各路大神在原 ...
- Pat 1003 甲级
#include <cstdlib> #include <cstring> #include <iostream> #include <cstdio> ...
- jmeter压测学习2-linux运行jmeter环境
前言 使用jmeter做压测的时候,在windows上不太稳定,所有一直在linux服务器上使用jmeter做压力测试. 本篇记录下linux上搭建jmeter环境,以及运行jmeter脚本,查看报告 ...
- python基础知识-列表的排序问题
def main(): f=['orange','zoo','apple','internationalization','blueberry'] #python 内置的排序方式默认为升序(从小到大) ...
- 利用反射与dom4j读取javabean生成对应XML
项目中需要自定义生成一个xml,要把Javabean中的属性拼接一个xml,例如要生成以下xml <?xml version="1.0" encoding="gb2 ...
- React.js Tutorial: React Component Lifecycle
Introduction about React component lifecycle. 1 Lifecycle A React component in browser can be any of ...
- 牛客挑战赛32 E. 树上逆序对
对于一对 $(x, y)$,能成为逆序对的取决于绝对值大的那个数的符号.假如 $a[x] > a[y]$,当 $a[x]$ 为正时,不管 $a[y]$ 取不取负号都比 $a[x]$ 小.当 $a ...
- Windows下PHP7/5.6以上版本 如何连接Oracle 12c,并使用PDO
https://blog.csdn.net/houpanqi/article/details/78841928 首先,本篇文章重点分享的是:在Win平台下,如何使用PHP7连接Oracle 12C,所 ...