Kafka安装教程(详细过程)
安装前期准备:
1,准备三个节点(根据自己需求决定)
2,三个节点上安装好zookeeper(也可以使用kafka自带的zookeeper)
3,关闭防火墙
chkconfig iptables off
一、下载安装包
Kafka官网下载安装包 http://kafka.apache.org/downloads.html
我们下载第二种(已经被编译过的),将安装包存在在 /software/ 下

二、解压安装包
我选择将kafka安装在 /usr/local/ 这个目录下。
tar -zxvf /software/ kafka_2.11-0.9.0.1.tar.gz –C /usr/local/
三、修改配置文件
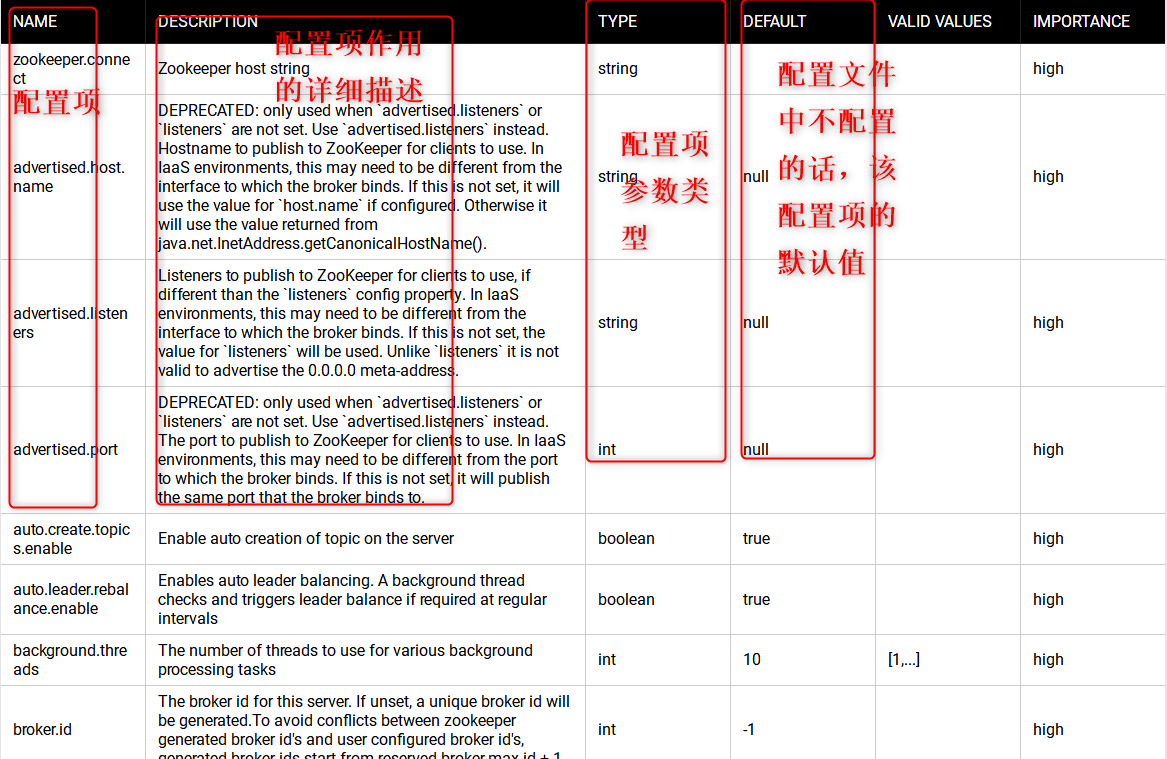
备注:以下的配置文件是我自己的配置文件,你自己配置的时候根据自己的需求进行配置,并且以下只是部分配置项,可以根据自己的需求添加符合自己需求的配置项。官网有详细的配置解释,以下是官网部分配置项截图。
其实整个安装kafka的过程很简单,主要就是修改配置文件。配置文件在 /usr/local/kafka_2.11-0.9.0.1/config 这里
cd /usr/local/kafka_2.11-0.9.0.1/config
1, 修改server.properties
#broker的全局唯一编号,不能重复
broker.id=0
#用来监听链接的端口,producer或consumer将在此端口建立连接
port=9092
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接受套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka消息存放的路径
log.dirs=/home/servers-kafka/logs/kafka
#topic在当前broker上的分片个数
num.partitions=2
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#滚动生成新的segment文件的最大时间
log.roll.hours=168
#日志文件中每个segment的大小,默认为1G
log.segment.bytes=1073741824
#周期性检查文件大小的时间
log.retention.check.interval.ms=300000
#日志清理是否打开
log.cleaner.enable=true
#broker需要使用zookeeper保存meta数据
zookeeper.connect=hadoop02:2181,hadoop03:2181,hadoop04:2181
#zookeeper链接超时时间
zookeeper.connection.timeout.ms=6000
#partion buffer中,消息的条数达到阈值,将触发flush到磁盘
log.flush.interval.messages=10000
#消息buffer的时间,达到阈值,将触发flush到磁盘
log.flush.interval.ms=3000
#删除topic需要server.properties中设置delete.topic.enable=true否则只是标记删除
delete.topic.enable=true
#此处的host.name为本机IP(重要),如果不改,则客户端会抛出:Producerconnection to localhost:9092 unsuccessful 错误!
host.name=hadoop02
2、修改producer.properties
#指定kafka节点列表,用于获取metadata,不必全部指定
metadata.broker.list=hadoop02:9092,hadoop03:9092
# 指定分区处理类。默认kafka.producer.DefaultPartitioner,表通过key哈希到对应分区
#partitioner.class=kafka.producer.DefaultPartitioner
# 是否压缩,默认0表示不压缩,1表示用gzip压缩,2表示用snappy压缩。压缩后消息中会有头来指明消息压缩类型,故在消费者端消息解压是透明的无需指定。
compression.codec=none
# 指定序列化处理类
serializer.class=kafka.serializer.DefaultEncoder
# 如果要压缩消息,这里指定哪些topic要压缩消息,默认empty,表示不压缩。
#compressed.topics=
# 设置发送数据是否需要服务端的反馈,有三个值0,1,-1
# 0: producer不会等待broker发送ack
# 1: 当leader接收到消息之后发送ack
# -1: 当所有的follower都同步消息成功后发送ack.
request.required.acks=0
#在向producer发送ack之前,broker允许等待的最大时间 ,如果超时,broker将会向producer发送一个error ACK.意味着上一次消息因为某种原因未能成功(比如follower未能同步成功)
request.timeout.ms=10000
# 同步还是异步发送消息,默认“sync”表同步,"async"表异步。异步可以提高发送吞吐量,
也意味着消息将会在本地buffer中,并适时批量发送,但是也可能导致丢失未发送过去的消息
producer.type=sync
# 在async模式下,当message被缓存的时间超过此值后,将会批量发送给broker,默认为5000ms
# 此值和batch.num.messages协同工作.
queue.buffering.max.ms = 5000
# 在async模式下,producer端允许buffer的最大消息量
# 无论如何,producer都无法尽快的将消息发送给broker,从而导致消息在producer端大量沉积
# 此时,如果消息的条数达到阀值,将会导致producer端阻塞或者消息被抛弃,默认为10000
queue.buffering.max.messages=20000
# 如果是异步,指定每次批量发送数据量,默认为200
batch.num.messages=500
# 当消息在producer端沉积的条数达到"queue.buffering.max.meesages"后
# 阻塞一定时间后,队列仍然没有enqueue(producer仍然没有发送出任何消息)
# 此时producer可以继续阻塞或者将消息抛弃,此timeout值用于控制"阻塞"的时间
# -1: 无阻塞超时限制,消息不会被抛弃
# 0:立即清空队列,消息被抛弃
queue.enqueue.timeout.ms=-1
# 当producer接收到error ACK,或者没有接收到ACK时,允许消息重发的次数
# 因为broker并没有完整的机制来避免消息重复,所以当网络异常时(比如ACK丢失)
# 有可能导致broker接收到重复的消息,默认值为3.
message.send.max.retries=3
# producer刷新topicmetada的时间间隔,producer需要知道partitionleader的位置,以及当前topic的情况
# 因此producer需要一个机制来获取最新的metadata,当producer遇到特定错误时,将会立即刷新
#(比如topic失效,partition丢失,leader失效等),此外也可以通过此参数来配置额外的刷新机制,默认值600000
topic.metadata.refresh.interval.ms=60000
3、修改consumer.properties
# zookeeper连接服务器地址
zookeeper.connect=hadoop02:2181,hadoop03:2181,hadoop04:2181
# zookeeper的session过期时间,默认5000ms,用于检测消费者是否挂掉
zookeeper.session.timeout.ms=5000
#当消费者挂掉,其他消费者要等该指定时间才能检查到并且触发重新负载均衡
zookeeper.connection.timeout.ms=10000
# 指定多久消费者更新offset到zookeeper中。注意offset更新时基于time而不是每次获得的消息。一旦在更新zookeeper发生异常并重启,将可能拿到已拿到过的消息
zookeeper.sync.time.ms=2000
#指定消费组
group.id=xxx
# 当consumer消费一定量的消息之后,将会自动向zookeeper提交offset信息
# 注意offset信息并不是每消费一次消息就向zk提交一次,而是现在本地保存(内存),并定期提交,默认为true
auto.commit.enable=true
# 自动更新时间。默认60 * 1000
auto.commit.interval.ms=1000
# 当前consumer的标识,可以设定,也可以有系统生成,主要用来跟踪消息消费情况,便于观察
conusmer.id=xxx
# 消费者客户端编号,用于区分不同客户端,默认客户端程序自动产生
client.id=xxxx
# 最大取多少块缓存到消费者(默认10)
queued.max.message.chunks=50
# 当有新的consumer加入到group时,将会reblance,此后将会有partitions的消费端迁移到新 的consumer上,如果一个consumer获得了某个partition的消费权限,那么它将会向zk注册"Partition Owner registry"节点信息,但是有可能此时旧的consumer尚没有释放此节点, 此值用于控制,注册节点的重试次数.
rebalance.max.retries=5
# 获取消息的最大尺寸,broker不会像consumer输出大于此值的消息chunk 每次feth将得到多条消息,此值为总大小,提升此值,将会消耗更多的consumer端内存
fetch.min.bytes=6553600
# 当消息的尺寸不足时,server阻塞的时间,如果超时,消息将立即发送给consumer
fetch.wait.max.ms=5000
socket.receive.buffer.bytes=655360
# 如果zookeeper没有offset值或offset值超出范围。那么就给个初始的offset。有smallest、largest、anything可选,分别表示给当前最小的offset、当前最大的offset、抛异常。默认largest
auto.offset.reset=smallest
# 指定序列化处理类
derializer.class=kafka.serializer.DefaultDecoder
四,分发安装包到其他节点
以上的步骤我们操作了一个节点,还有两个节点,我们可以直接将刚刚配置好的直接分发到其它两个节点。因为配置文件都是一样的,唯一不同的是 borker.id不同就行。(以下的命令中,hadoop03和hadoop04是我另外两个节点的别名,如果你们没起别名,可以用节点的ip代替。)
scp –r /usr/local/ kafka_2.11-0.9.0.1 hadoop03:/usr/local
scp –r /usr/local/ kafka_2.11-0.9.0.1 hadoop04:/usr/local
修改其他两个节点中的server.properties中的 broker.id,分别设置为 0,1,2
4.配置启动
a. 启动zookeeper
#启动zookeeper 指定 zookeeper 配置文件
./bin/zookeeper-server-start.sh ./config/zookeeper.properties
b. 启动kafka
#打开kafka配置文件,开启监听端口
$ vim server.properties
listeners=PLAINTEXT://localhost:9092
#启动kafka 服务
$ ./bin/kafka-server-start.sh ./config/server.properties
注意 kafka基于zookeeper,必须先启动zookeeper ,再启动kafka
c.启动消费者
$ ./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
d.启动生产者
$ ./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
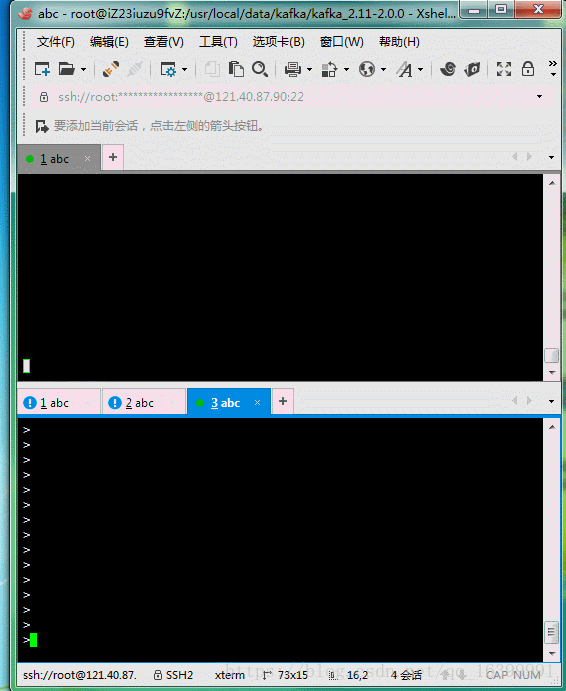
整体效果如下图,窗口上是我启动的消费窗口 ,窗口下是我启动的生产者窗口:
五,启动集群
先启动zookeeper,再依次在各自节点上启动kafka
启动命令:nohup bin/kafka-server-start.sh config/server.properties &
备注:为了方便启动kafka。可以自己写个脚本同时启动多台kafka。以下是我自己写的,同时启动多台kafka的脚本。
cat /usr/local/kafka_2.11-0.9.0.1/bin/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;nohup /usr/local/kafka_2.11-0.9.0.1/bin/kafka-server-start.sh /usr/local/kafka_2.11-0.9.0.1/config/server.properties >/dev/null 2>&1 &"
}&
wait
done
~
六、总结
其实整个安装步骤很简单
1、下载安装包
2、解压安装包
3、修改配置文件
4、另外的两个节点和上面三步一样操作,唯一不同的是修改各自的broker.id
————————————————
版权声明:本文为CSDN博主「后知后觉的肖邦」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Poppy_Evan/article/details/79415460
Kafka安装教程(详细过程)的更多相关文章
- 【Oracle RAC】Linux系统Oracle11gR2 RAC安装配置详细过程V3.1(图文并茂)
[Oracle RAC]Linux系统Oracle11gR2 RAC安装配置详细过程V3.1(图文并茂) 2 Oracle11gR2 RAC数据库安装准备工作2.1 安装环境介绍2.2 数据库安装软件 ...
- Linux系统CentOS6.2版本下安装JDK7详细过程
Linux系统CentOS6.2版本下安装JDK7详细过程 分类: Linux 2014-08-25 09:17 1933人阅读 评论(0) 收藏 举报 前言: java 是一种可以撰写 ...
- iOS安装CocoaPods详细过程
iOS安装CocoaPods详细过程 一.简介 什么是CocoaPods CocoaPods是OS X和iOS下的一个第三类库管理工具,通过CocoaPods工具我们可以为项目添加被称为“Pods”的 ...
- centos7.3 安装oracle 详细过程
centos7.3安装oracle详细过程1.下载Oracle安装包:linux.x64_11gR2_database_1of2.zip 和 linux.x64_11gR2_database_2of2 ...
- mysql安装图解 mysql图文安装教程(详细说明)
MySQL5.0版本的安装图解教程是给新手学习的,当前mysql5.0.96是最新的稳定版本. mysql 下载地址 http://www.jb51.net/softs/2193.html 下面的是M ...
- mysql安装图解 mysql图文安装教程(详细说明)-[转]
很多朋友刚开始接触mysql数据库服务器,下面是网友整理的一篇mysql的安装教程,步骤明细也有详细的说明. MySQL5.0版本的安装图解教程是给新手学习的,当前mysql5.0.96是最新的稳定版 ...
- Linux下安装mongodb详细过程
本次安装mongodb使用yum.repo方式.详细过程请参考,也列出一些安装过程中的错误,欢迎指正. mongodb版本:3.0 先在linux下cd 到 /etc/yum.repos.d/ 新建脚 ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- kafka安装教程
今天需要在新机器上安装一个kafka集群,其实kafka我已经装了十个不止了,但是没有一个是为生产考虑的,因此比较汗颜,今天好好地把kafka的安装以及配置梳理一下: 1,kafka版本选取: 现在我 ...
随机推荐
- Docker 0x03:Install Docker
目录 Install Docker Centos yum 安装 运行docker-daemon并开机自启动 运行hello-world应用docker容器中 Ubn Install Docker do ...
- PHP fsockopen 异步写入文件
b.php <?php $url = 'http://fsc.com/a.php'; $param = array( 'name'=>'fdipzone', 'gender'=>'m ...
- dfs 解决八皇后问题 以及其他图搜索问题
33. N皇后问题 中文 English n皇后问题是将n个皇后放置在n*n的棋盘上,皇后彼此之间不能相互攻击(任意两个皇后不能位于同一行,同一列,同一斜线). 给定一个整数n,返回所有不同的n皇后问 ...
- python笔记44-HTTP对外接口sign签名
前言 一般公司对外的接口都会用到sign签名,对不同的客户提供不同的apikey ,这样可以提高接口请求的安全性,避免被人抓包后乱请求. sign签名是一种很常见的方式 sign签名 签名参数sign ...
- 团队项目评审&课程学习总结
一:实验名称:团队项目评审&课程学习总结 二:实验目的与要求 (1)掌握软件项目评审会流程: (2)反思总结课程学习内容. 三:实验步骤 任务一:按照团队项目结对评审名单,由项目组扮演乙方,结 ...
- jsbridge与通信模型
三层通信模型: 应用层.解释层.会话层: 通信协议: 通信原语: 报文格式: 网络层: _evaluateJavascript 会话层: #define kQueueHasMessage @&qu ...
- jdk是什么
jdk是对java基础环境和相应开发平台标准和工具包的封装(zip) 开发平台 j2se j2ee j2me; 基础环境: 虚拟机.运行环境 JDK是整个JAVA的核心,包括了Java运行环境JRE( ...
- Word中同样行间距,同样字号,同样字体,但是肉眼看起来行距不一样
感谢博主转载:https://blog.csdn.net/hongweigg/article/details/47130009 困扰了我好久,直接上解决办法: 然后选择 自定义页边距 选择 无网络(N ...
- 2019湖南省赛H题——概率转移&&逆矩阵
题意 题目链接 Bobo有一个 $n+m$ 个节点的有向图,编号分别为 $1 \sim n$,他还有一个 $n$ 行 $n+m$ 列的矩阵 $P$. 如果在 $t$ 时刻他位于节点 $u(1 \leq ...
- docker 服务无法启动
重装以后仍然不行,dockerd可以运行,但是systemctl start docker.service不行,后来在编辑一个文件时,提示没有空间可以保存,结果一查,发现服务器空间基本占满了, 通过 ...