Python selenium PO By.XPATH定位元素报错
Python selenium PO By.XPATH定位元素报错
如下代码经常报错:
# 首页的“新建投放计划”按钮
new_ads_plan = (By.XPATH, "//*[text()='百度新闻']/..") print(type(self.new_ads_plan))
self.driver.find_element(self.new_ads_plan).click() 运行经常报错:
selenium.common.exceptions.WebDriverException: Message: invalid argument: 'using' must be a string
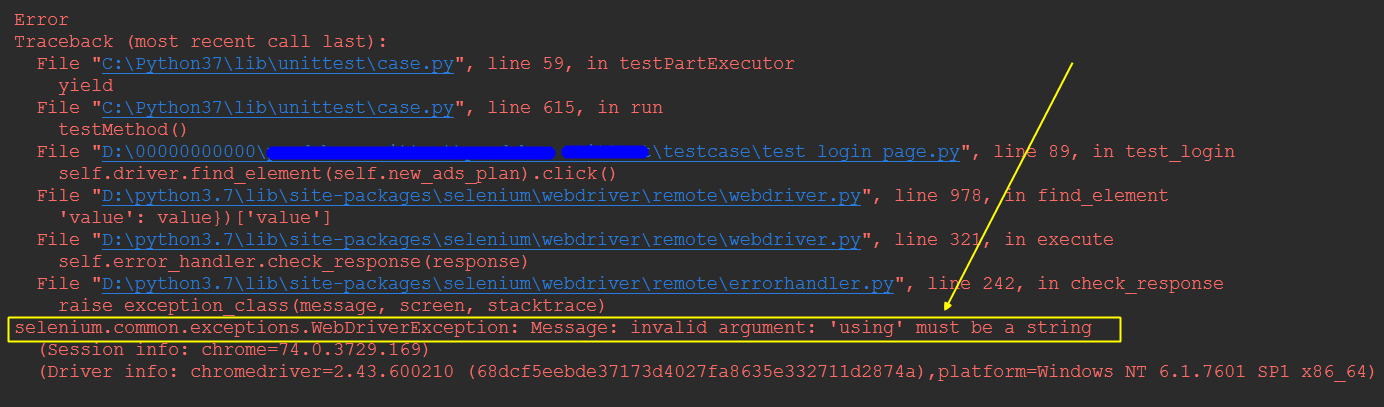
解决办法:
self.driver.find_element(*self.new_ads_plan).click()
在参数里面的元素定位 self 前加一个星号 *
=============================================================================================================================================================================================================================
new_ads_plan = (By.XPATH, "//*[text()='百度新闻']")
shouye = (By.XPATH, "//a[text()= '首页']")
zanTing = (By.XPATH, "//span[text()= '删 除']")
bianji = (By.XPATH, "//span[text()= '编 辑']")
addSuCai = (By.XPATH, "//span[text()= '添加']") def isElementExists(self, *loc):
flag = True
try:
for num in range(0, len(loc)):
print(str(loc[num]))
self.driver.find_element(*loc[num])
return flag
except:
flag = False
return flag # 判断元素是否显示
def is_ElementExists(self):
return self.isElementExists((self.new_ads_plan),
(self.shouye),
(self.zanTing),
(self.bianji),
(self.addSuCai)) # 此处必须将多个定位元素的入参以元祖的形式填入,每一个元素的定位参数都是一个数组。
Python selenium PO By.XPATH定位元素报错的更多相关文章
- python selenium框架的Xpath定位元素
我们工作中经常用到的定位方式有八大种:id name class_name tag_name link_text partial_link_text xpath css_selector 本篇内容主要 ...
- 『心善渊』Selenium3.0基础 — 6、Selenium中使用XPath定位元素
目录 1.Selenium中使用XPath查找元素 (1)XPath通过id,name,class属性定位 (2)XPath通过标签中的其他属性定位 (3)XPath层级定位 (4)XPath索引定位 ...
- python+selenium基础之XPATH定位(第一篇)
世界上最远的距离大概就是明明看到一个页面元素矗在那里,但是我却定位不到!! selenium定位元素的方法有很多种,像是通过id.name.class_name.tag_name.link_text等 ...
- python+selenium:点击页面元素时报错:WebDriverException: Message: Element is not clickable at point (1372.5, 9.5). Other element would receive the click: <li style="display: list-item;" id="tuanbox"></li>
遇到一个非常郁闷的问题,终于解决了, 问题是这样的,NN网站的价格计划,每一个价格计划需要三连击才能全部点开,第一个房型的价格计划是可以正确三连击打开的,可是第二个房弄就不行了,报错说不是可点击的 ...
- python+selenium 批量执行时出现随机报错问题【已解决】
出现场景:用discover方法批量执行py文件,出现随机性的报错(有时a.py报错,有时b.py报错...),共同特点:均是打开新窗口后,切换最新窗口,但定位不到新窗口的元素,超时报错.由于个人项目 ...
- 使用python处理selenium中的xpath定位元素的模糊匹配问题
# 用contains,寻找页面中style属性值包含有sp.gif这个关键字的所有div元素,其中@后面可以跟该元素任意的属性名. self.driver.find_element_by_xpath ...
- Python+Selenium之断言对应的元素是否获取以及基础知识回顾
# coding=utf-8 from selenium import webdriver driver = webdriver.Firefox() driver.maximize_window () ...
- Selenium-Python学习——通过XPath定位元素
用Xpath定位元素的方法总是记不住,经常要翻出各种文档链接参考,干脆把需要用到的内容整到这个笔记中方便查找. Xpath是在XML文档中定位节点的语言.使用 XPath 的主要原因之一是当想要查找的 ...
- Robot Framework与Web界面自动化测试学习笔记:利用xpath定位元素
在rf中,利用selinum2的关键字进行用例编写时,很多关键字的参数是html元素的定位标识. 最简单的方式,是通过id 或name来描述元素定位信息,如 click button id=l ...
随机推荐
- java-Ehcache缓存
springmvc配置文件: <beans .... xmlns:cache="http://www.springframework.org/schema/cache" xs ...
- IDEA 阿里巴巴代码规范检查插件
1.问题概要 大家都想写出规范的代码,可规范的标准是什么勒,估计每个人心中的标准都不是完全一致的 在分工合作越来越精细化的时代,我们需要一个最大程度接近公认的规范,这里我们以阿里巴巴的代码规范作为参考 ...
- Python 软件安装
安装Python解释器 Python目前已支持所有主流操作系统,在Linux,Unix,Mac系统上自带Python环境,在Windows系统上需要安装一下,超简单 打开官网https://www.p ...
- wget详解
wget命令用来从指定的URL下载文件.wget非常稳定,它在带宽很窄的情况下和不稳定网络中有很强的适应性,如果是由于网络的原因下载失败,wget会不断的尝试,直到整个文件下载完毕.如果是服务器打断下 ...
- MySQL/MariaDB数据库的复制过滤器
MySQL/MariaDB数据库的复制过滤器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.复制过滤器概述 1>.复制器过滤器功能 让从节点仅复制指定的数据库,或指 ...
- react-native npm install
--create project react-native init myapp --version 0.55.4 cd myapp -- react ui npm i react-native-el ...
- 烦人的警告 Deprecated: convertStrings was not specified when starting the JVM
python 调用java代码: Deprecated: convertStrings was not specified when starting the JVM. The default beh ...
- 2、Python的IDE之PyCharm的使用
一.Python集成开发环境-Pycharm介绍 PyCharm是一款功能强大的,用于编写复杂需要结构化的功能代码,下面介绍一下 在Windows下如何安装PyCharm . 操作系统:Windows ...
- Oracle中INSTR函数与SQL Server中CHARINDEX函数
Oracle中INSTR函数与SQL Server中CHARINDEX函数 1.ORACLE中的INSTR INSTR函数格式:INSTR(源字符串, 目标字符串, 起始位置, 匹配序号) 说明:返回 ...
- 闷声发大财,中国 App 出海编年史及方法论
https://zhuanlan.zhihu.com/p/26700406 第一代 iPhone 发布于 2007 年初,至今已有十年有余.中国互联网公司出海的新篇章,也正始于这 iPhone / A ...