Java学习:集合双列Map
数据结构
数据结构:
数据结构_栈:先进后出
- 入口和出口在同一侧
数据结构_队列:先进先出
- 入口和出口在集合的两侧
数据结构_数组:
- 查询快:数组的地址是连续的,我们通过数组的首地址可以找到数组,通过数组的索引可以快速的查找某一个元素。
- 增删慢:数组的长度是固定的,我们想要增加/删除一个元素,必须创建一个新数组,把原数组的数据复制过来
例:
int[] arr = new int[]{1,2,3,4};
要把数组索引是3的元素删除
- 必须创建一个新的数组,长度是原数组的长度-1
- 把原数组的其它元素复制到新数组中
- 在新数组的地址赋值给变量arr
- 原数组会在内存中被销毁(垃回收收)
数据结构_链表:
- 查询慢:链表中地址不是连续的,每次查询元素,都必须从头开始查询。
- 增删快:链结构,增加/删除一个元素,对链的整体结构没有影响,所以增删快
链表中的每一个元素也称之为一个节点
一个节点包含了一个数据源(存储数组),两指针域(存储地址)
- 单向链:链中只有一条链,不能保证元素的顺序(存储元素和取出元素的顺序可能不一致)
- 双向链:链中有两链,有一条链是专门记录元素的顺序,是一个有序的集合
二叉树:分支不能超过两
- 排序树/查找树:在二叉树的基础上,元素是有大小顺序的(左子树小,右子树大)
- 平衡树:左孩子和右孩子相等
- 不平衡树:左孩子和右孩子不相等
红黑树:
特点:趋近于平衡树,查询的速度非常的快,查询叶子节点最大次数和最小次数不能超过2倍
约束:
- 节点可以是红色的或者是黑色的
- 根节点是黑色的
- 叶子节点(空节点)是黑色的
- 每个红色的节点的子节点都是黑色的
- 任何一个节点到其每一个叶子节点的所有路径上黑色节点数相等
List接口
java.util.list接口 extends Collection接口
List接口的特点:
- 有序的集合,存储元素和取出元素的顺序是一致的(存储123 取出123)
- 有索引,包含了一些带索引的方法
- 允许存储重复的元素
List接口中带索引的方法(特有):
public void add(int index,E element):将指定的元素,添加到该集合中的指定位置上。
public E get(int index):返回集合中指定位置的元素。
public E remove(int index):移除列表中指定位置的元素,返回的是被移除的元素。
public E set(int index,E element):用指定元素替换集合中指定位置的元素,返回值的更新前的元素。
注意:
操作索引的时候,一定要防止索引越界异常
- IndexOutOfBoundsException:索引越界异常,集合会报
- ArrayIndexOutOfBoundsException:数组索引越界异常
- StringIndexOutOfBoundsException:字符串索引越界异常
//创建一个List集合对象,多态
List<String> list = new ArrayList<>();
{
//public void add(int index,E element):将指定的元素,添加到该集合中的指定位置上。
//在索引2和索引3之间添加一个cainiao
list.add(3,"cainiao");//{a,b,c,d}-->{a,b,c,cainiao,d}
//移除元素
String removeE = list.remove(2)
//替换元素
String setE = list.set(4,"A");
}
List的子类
- ArrayList集合
java.util.ArrayList集合数据存储的结构是数组结构。元素增删慢,查找快,由于日常开发中使用最多的功能为查询数据、遍历数据,所以ArrayList是最常用的集合。
- LinkedList集合
java.util.LinkedList集合数据存储的结构是链结构。方便元素添加,删除的集合。
java.util.LinkedList集合 implements List接口
ArrayList集合的特点:
- 底层是一个链的结构:查询慢,增删快
- 里边包含了大量操作首尾元素的方法
注意:
使用ArrayList集合特有的方法,不能使用多态
- public void addFirst(E e):将指定元素插入此列表的开头
- public void addLast(E e):将指定元素添加到此列表的结尾
- public void addpush(E e):将元素推如此列表所表示的推栈
- public E getFirst():返回此列表的第一个元素。
- public E getLast():返回此列表的最后一个元素。
- public E removeFirst():移除并返回此列表的第一个元素。
- public E removeLast():移除并返回此列表的最后一个元素。
- public E pop():从此列表所表示的推栈处弹出一个元素。相当于removeFirst
- public boolean isEmpty():如果列表不包含元素,则返回true
Vector集合
Vector 类可以实现可增长的对象数组。
与新collection不同,Vector是同步的。
Set接口
java.util.Set接口 extends Collection接口
Set接口的特点:
- 不允许存储重复的元素
- 没有索引,没有带索引的方法,也不能使用普通的for循环遍历
java.util.HashSet集合 implements Set接口
HashSet特点:
- 不允许存储重复的元素
- 没有索引,没有带索引的方法,也不能使用普通的for循环遍历
- 是一个无序的集合,存储元素和取出元素的顺序有可能不一致
- 底层是一个哈希表结构(查询的速度非常快)
Set<Integer> set = new HashSet<>();
//使用add方法往集合中添加元素
set.add(1);
set.add(3);
set.add(2);
set.add(1);
//使用迭代器遍历Set集合
Iterator<Integer> it = set.iterator();
while(it.hasNext(){
Iterator n = it.next();
System.out.println(n);//1,2,3 无序且不重复
}
HashSet集合存储数据的结构(哈希表)
哈希值:是一个十进制的整数,由系统随机给出(就是对象的地址值,是一个逻辑地址,是模拟出来得到的地址,不是数据实际存储的物理地址)
在Object类有一个方法,可以获取对象的哈希值
int hashCode() 返回该对象的哈希码值。
HashCode方法的源码:
public native int hashCode();
native:代表该方法调用的是本地操作系的的方法
哈希表
哈希表:hashSet集合存储数据的结构
jdk1.8版本之前:哈希表 = 数组+链表
jdk1.8版本之后:
- 哈希表 = 数组+链表;
- 哈希表 = 数组+红黑树(提高查询的速度)
哈希表的特点:速度快
存储数据到集合中,先计算元素的哈希值
- abc:96354 在数组的存储位置
- 重地——通话:1179395 两元素不同,但是哈希值相同 哈希冲突
数组结构:把元素进行了分组(相同哈希值的元素是一组)
链表/红黑树结构:把相同哈希值的元素连到一起(如何链表的长度超过了8位,那么就会把链转换位红黑树(提高查询的速度))
Set集合存储元素不重复的原理
Set集合存储元素不重复的元素的前提:
前提:存储的元素必须重写hashCode方法和equals方法
//创建HashSet集合对象
HashSet<String> set = new HashSet<>();//哈希表:数组+链表/红黑树
String s1 = new String("abc");
String s2 = new String("abc"); set.add(s1);
set.add(s2);
set.add("重地");
set.add("通话");
set.add("abc");
System.out.println(set);/[重地,通话,abc]
原因:
Set集合在调用add方法的时候,add方法会调用元素hashCode方法和equals方法,判断元素是否重复
HashSet存储自定义类型元素
Set集合报错元素原因:
存储的元素(String,Integer,...Student,Person...),必须重写hashCode方法和equals方法
LinkedHashSet集合
java.util.LinkedHashSet集合 extends HashSet集合
LinkedHashSet集合特点:
底层是一个哈希表(数组+链表/红黑树+链表:多了一条链(记录元素的存储顺序),保存元素有序
HashSet<String> set = new HashSet<>();//[]无序,不允许重复
LinkedHashSet<String> set = new LinkedHashSet<>();[]//有序,不允许重复
可变参数
可变参数:是JDK1.5 之后出现的新特性
使用前提:
- 当方法的参数列表数据类型已经确定,但是参数的个数不确定,就可以使用可变参数。
使用格式:定义方法时使用
- 修饰符 返回值类型 方法名(数据类型...变量名){}
可变参数的原理:
- 可变参数底层就是一个数组,根据传递参数个数不同,会创建不同长度的数组,来存储这些参数
- 传递的参数个数,可以是0个 (不传递),1,2...多个
可变参数的注意事项:
- 一个方法的参数列表,只能有一个可变参数
- 如果方法的参数有多个,那么可变参数必须写在参数列表的末尾
public static void method(String b, double c ,int d ,int...a){}
//可变参数的特殊(终极)写法
public static void method(Object...obj){}
Collections集合工具类的方法
java.util.Collections是集合工具类,用来对集合进行操作。部分方法如下:
public static <T> void sort(List<T> List ,Comparator<? super T>):将集合中元素按照指定规则排序。
Comparator和Comparable的区别
Comparable:自己(this)和别人(参数)比较,自己需要实现Comparable接口,重写比较的规则compareTo方法
Comparator:相当于找一个第三方的裁判,比较两
Comparator的排序规则:
o1-o2:升序
Map集合
Collection接口: 定义了单列集合规范 Collection<E>
- 每次存储一个元素 单个元素
Map接口:定义了双列集合的规范 Map<K,V>
- 每次存储一对元素
java.util.Map<K,V>集合
Map集合的特点:
- Map集合是一个双列集合,一个元素包含两值(一个key,一个value)
- Map集合中的元素,key和value的数据类型可以相同,也可以不同
- Map集合中的元素,key是不允许重复的,value是可以重复的
- Map集合中的元素,key和value是一一对应的
java.util.HashMap<K,V>集合 implements Map<K,V>接口
HashMap集合的特点:
1.HashMap集合底层是哈希值:查询的速度特别的快
- JDK.8之前:数组+单向链表
- JDK.8之后:数组+单向链表/红黑树(链表的长度超过8):提高查询的速度
2.HashMap集合是一个无序的集合,存储元素和取出元素的顺序有可能不一致
java.util.LinkedHashMap<k,v>集合 extends HashMap<K,V>集合
LinkedHashMap的特点:
- LinkedHashMap集合底层是哈希表+链表(保证迭代的顺序)
- LinkedHashMap集合是一个有序的集合,存储元素和取出元素的顺序是一致的
Map接口中的常用方法
public V put (K key,V value):把指定的键与指定的值添加到Map集合中。
返回值:v
- 存储键值对的时候,key不重复,返回值V是null
- 存储键值对的时候,key重复,会使用新的value替换map中重复的value,返回被替换的value值
public V remove(Object key):把指定的值 所对应的键值对元素 在Map集合中删除,返回被删除元素的值。
返回值:V
- key存在,v返回被删除的值
- key不存在,v返回null
public V get(Object key)根据指定的键,在Map集合中获取对应的值。
返回值:
- key存在,返回对应的value值
- key不存在,返回null
boolean containsKey(Object key) 判断集合中是否包含指定的键
- 包含返回true,不包含返回false
Map集合的第一种遍历方式:通过键找值的方式
Map集合中的方法:
- Set<K> keySet() 返回此映射中包含的键的 Set 视图。
实现步骤:
- 使用Map集合中的方法keySet(),把Map集合所有的key取出来,存储到一个Set集合中。
- 遍历Set集合,获取Map集合中的每一个Key
- 通过Map集合中的方法get(key),通过key找到value
Entry键值对对象
Map.Entry<K,V>:在Map接口中有一个内部接口Entry
作用:当Map集合一创建,那么就会在Map集合中创建一个Entry对象,用来记录键与值(键值对对象,键与值的映射关系)
Map集合遍历的第二种方式:使用Entry对象遍历
Set<Map.Entry<K,V> entrySet() 返回此映射中包含的键的 Set 视图。
实现步骤:
- Set<Map.Entry<K,V>> entrySet(): 把Map集合内部的多个Entry对象取出来存储到一个Set集合中
- 遍历Set集合:获取Set集合中的每一个Enter对象
- 获取Entry对象中的方法:getKey()获取key,getValue() 获取value
HashMap存储自定义类型键值
key:Person类型
- Person类型必须重写hashCode方法和equals方法,以保证key唯一
value:String类型
- 可以重复
java.util.linkedHashMap<K,V> extends HashMap<K,V>
Map 接口的哈希表和链表列表实现,具有可预知的迭代顺序。
底层原理:
- 哈希表+链表(记录元素的顺序)
Hashtable集合
java.util.Hashtable<K,V>集合 implements Map<k,V>接口
- Hashtable:底层也是一个哈希表,是一个线程安全的集合,是单线程集合,速度慢
- HashMap:底层是一个哈希表,是一个线程不安全的集合,是多线程的集合,速度快
- HashMap集合(之前学的所有集合):可以存储null值,null键
- Hashtable集合:不能存储null值,null键
- Hashtable集合和Vector集合一样,在jdk1.2版本之后被更先进的集合(HashMap,ArrayList)取代了
- Hashtable的子类properties依然活跃在历舞台
- Properties集合是一个唯一和I/O流相结合的集合
练习:
- 计算一个字符串中每一个字符出现的次数
分析:
1.使用Scanner获取用户输入的字符串
2.创建Map集合,key是字符串中的字符,value是字符的个数
3.遍历字符串,获取每一个字符
4.使用获取到的字符,去Map集合判断key是否存在
- key存在:
通过字符(key),获取value(字符个数)
value++
put(key,value)把新的value存储到Map集合中
- Key不存在:
put(key,1)
5.遍历Map集合,输出结果
public class CaiNiao{
public static void main(String[] args){
//1.使用Scanner获取用户输入的字符串
Scanner sc = new Scanner(System.in);
System.out.println("请输入一个字符串:");
String str = sc.next();
//2.创建Map集合,key是字符串中的字符,value是字符的个数
HashMap<Character.Integer> map = new HashMap<>();
//3.遍历字符串,获取每一个字符
for(char c : str.toCharArray()){
//4.使用获取到的字符,去Map集合判断key是否存在
if(map.containsKey(c)){
//key存在
Integer value = map.get(c);
value++;
map.put(c,value);
}else{
//key不存在
map.put(c,1);
}
}
//5.遍历Map集合,输出结果
for(Character key : map.keySet(){
Integer value = map.get(key);
System.out.println(key+"="+value);
}
}
}
JDK9对集合添加的优化
JDK9的新特性:
- list接口,Set接口,Map接口:里边增加了一个静态的方法of,可以给集合一次性添加多个元素
- static <E> List<E> of (E... elements)
使用前提:
- 当集合中存储的元素的个数已经确定了,不在改变时使用
注意:
- of方法只适用于list接口,set接口,Map接口,不适用于接口的实现类
- 2of方法的返回值是一个不能改变的集合,集合不能再使用add,put方法添加元素,会抛出异常
- 3Set接口和Map接口在调用of方法的时候,不能有重复的元素,否则会抛出异常
Debug追踪
Debug调试程序:
- 可以让代码逐行执行,查看代码执行的过程,调试程序中出现的bug
使用方式:
- 在行号的右边,鼠标左键单击,添加断点(每个方法的第一行,哪里有bug添加到哪里)
- 右键,选择Debug执行程序
- 程序就会停留在添加的第一个断点处
执行程序:
- f8:逐行执行程序
- f7:进入到方法中
- shift + f8:跳出方法
- f9:跳到下一个断点,如果没有下一个断点,那么就结束程序
- ctrl + f2:退出debug模式,停止程序
斗地主综合案例:有序版本(双列)
- 1.准备牌
- 2.洗牌
- 3.发牌
- 4.排序
- 5.看牌
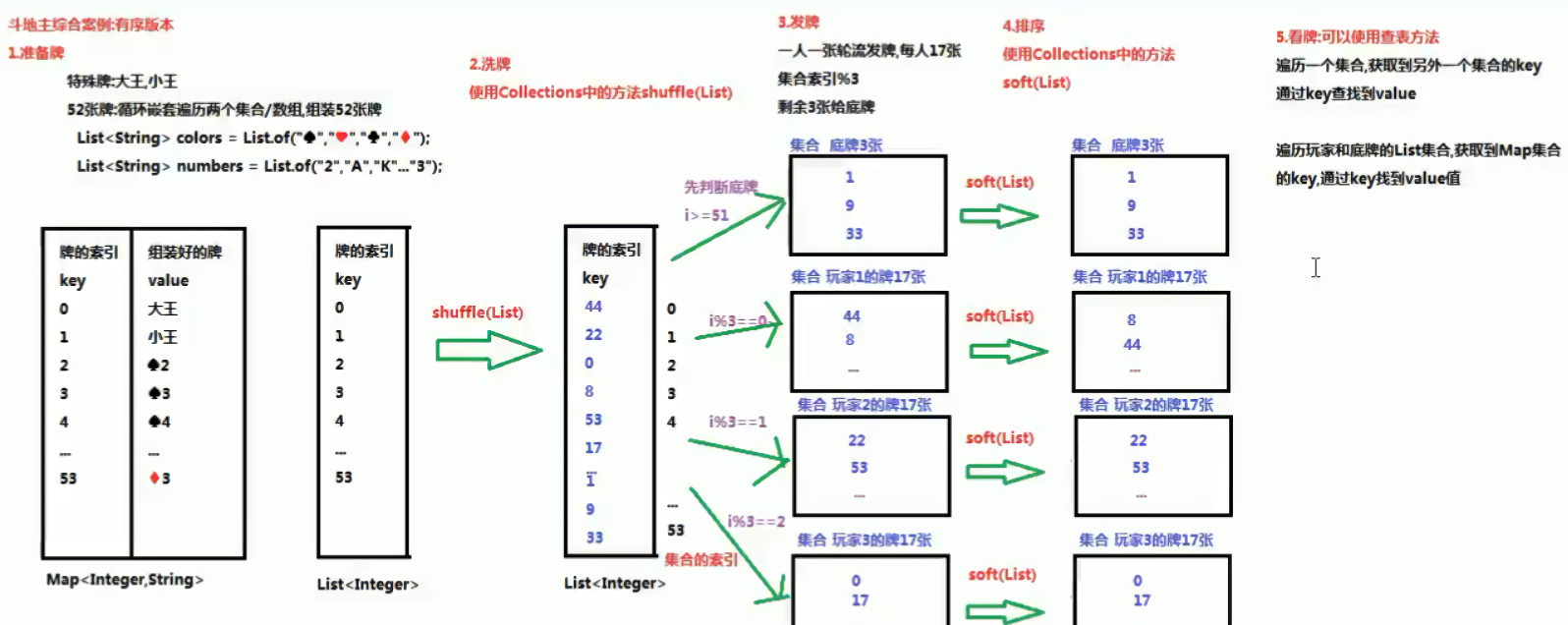
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List; public class CaiNiao{
public static void main(String[] args){
//1.准备牌
//创建一个Map集合,存储牌的索引和组装好的牌
HashMap<Integer,String> poker = new HashMap<>();
//创建一个List集合,存储花色和牌索引
ArrayList<Integer> pokerIndex = new ArrayList<>();
//定义两个数组,一个数组存储牌的花色,一个数组存储牌的序号
String[] colors = {"?","?","?","??"};
String[] numbers = {"2","A","K","Q","J","10","9","8","7","6","5","4","3"};
//先把大王和小王存储到集合中
//定义一个牌的索引
int index = 0;
poker.put(index,"大王");
pokerIndex.add(index);
index++;
poker.put(index,"小王");
pokerIndex.add(index);
index++; //循环嵌套遍历两个数组,组装52张牌
for(String numbers:numbers){
for (String color : colors){
poker.put(index.color+number);
pokerIndex.add(index);
index++;
}
}
// System.out.println(poker);
// System.out.println(pokerIndex); /*
2.洗牌
使用集合的工具类Collections中的方法
static void shuffle(List<?> list) 使用默认的随机源对指定列表进行置换。 */
Collections.shuffle(poker);
//System.out.println(poker); /*
3.发牌
*/
//定义4 个集合,存储玩家的牌和底牌
ArrayList<String> player01 = new ArrayList<>();
ArrayList<String> player02 = new ArrayList<>();
ArrayList<String> player03 = new ArrayList<>();
ArrayList<String> dipai = new ArrayList<>();
/*
遍历poker集合,获取每一张牌
使用poker集合的索引%3给3个玩家轮流发牌
剩余3张牌给底牌
注意:
先判断底牌(i>51),否则牌就发没了 */
for(int i = 0;i<poker.size();i++){
//获取每一张牌
String p = poker.get(i);
//轮流发牌
if(i>=51){
//给底牌发牌
diPai.add(p);
}else if (i%3==0){
//给玩家1发牌
player01.add(p);
}else if (i%3==1){
//给玩家2发牌
player02.add(p);
}else if(i%3==2){
//给玩家3发牌
player03.add(p);
}
} /*
4.排序
使用Collectio中的方法sort(List)
默认是升序排序
*/
Collection.sort(player01);
Collection.sort(player02);
Collection.sort(player03);
Collection.sort(dipai); //5.看牌
lookpoker("刘德华:",poker,player01);
lookpoker("周润发:",poker,player02);
lookpoker("周星驰:",poker,player03);
lookpoker("底牌 :",poker,dipai); }
/*
定义一个看牌方法,提高代码的复用性
参数:
String name:玩家名称
HashMap<Integer,String> poker:存储牌的poker集合
ArrayList<Integer> List:存储玩家和底牌的list集合
查表法:
遍历玩家或者底牌集合,获取牌的索引
使用牌的索引,去Map集合中,找到对应的牌 */ public static void lookpoker(String name ,HashMap<Integer,String> poker,ArrayList<Integer> list){
//输出玩家名称,不换行
System.out.println(name + ";");
//遍历玩家或者底牌集合,获取牌的索引
for(Integer key : list){
//使用牌的索引,去Map集合中,找到对应的牌
String value = poker.get(key);
System.out.println(value+"");
}
System.out.println();//打印完每一个玩家的牌,换行
} }
Java学习:集合双列Map的更多相关文章
- Map集合(双列集合)
Map集合(双列集合)Map集合是键值对集合. 它的元素是由两个值组成的,元素的格式是:key=value. Map集合形式:{key1=value1 , key2=value2 , key3=val ...
- Java中集合List,Map和Set的区别
Java中集合List,Map和Set的区别 1.List和Set的父接口是Collection,而Map不是 2.List中的元素是有序的,可以重复的 3.Map是Key-Value映射关系,且Ke ...
- Java中集合List,Map和Set的差别
Java中集合List,Map和Set的差别 1.List和Set的父接口是Collection.而Map不是 2.List中的元素是有序的,能够反复的 3.Map是Key-Value映射关系,且Ke ...
- java oop 单列 双列 集合, 迭代器 的使用和说明
一.集合(Collection) (1)集合的由来? 我们学习的是Java -- 面向对象 -- 操作很多对象 -- 存储 -- 容器(数组和StringBuffer) -- 数组 而数组的长度固定, ...
- java学习——集合框架(泛型,Map)
泛型: ... Map:一次添加一对元素.Collection 一次添加一个元素. Map也称为双列集合,Collection集合称为单列集合. 其实map集合中存储的就是键值对. map集合中必须保 ...
- Map集合——双列集合
双列集合<k, v> Map: Map 和 HashMap是无序的: LinkedHashMap是有序的: HashMap & LinkedHashMap: put方法: 其中,可 ...
- Java学习-集合(转)
在编写java程序中,我们最常用的除了八种基本数据类型,String对象外还有一个集合类,在我们的的程序中到处充斥着集合类的身影!java中集合大家族的成员实在是太丰富了,有常用的ArrayList. ...
- 十七、Java基础---------集合框架之Map
前两篇文章中介绍了Collection框架,今天来介绍一下Map集合,并用综合事例来演示. Map<K,V> Map<K,V>:Map存储的是键值对形式的元素,它的每一个元素, ...
- Java学习笔记24(Map集合)
Map接口: Map接口与Collection接口无继承关系. 区别:Collection中的元素是孤立的,一个一个存进去的. Map作为一个映射集合,每一个元素包含Key-value对(键-值对). ...
随机推荐
- WPE 过滤器 高级滤镜
与普通滤镜区别就是: 普通滤镜固定位置 高级滤镜固定数值 普通滤镜 指定位置1~6,对应发送数据的固定1~6字节 高级滤镜 首先,勾选高级-自发现有连锁位置 记得,偏移001对应修改000位置,也可称 ...
- leetcode 学习心得 (4)
645. Set Mismatch The set S originally contains numbers from 1 to n. But unfortunately, due to the d ...
- logger(二)logback简介及其实现原理
一.logback简介 logback是log4j创始人写的,性能比log4j要好,目前主要分为3个模块 logback-core:核心代码模块 logback-classic:log4j的一个改良版 ...
- CDA数据分析【数据处理工具SPSS】
一.概述 SPSS[Statistical Package for the Social Science]社会科学统计软件包.SPSS统计软件在社会学.经济学.心理学.教育学等多个学科的研究工作和通信 ...
- Windows 2016 & Windows 10 中IIS安装和配置PHP的步骤
Windows 2016 和 Windows 10 内核是相同的,我们首先需要安装 Internet Information Services (IIS),当然 Win2016 跟 Win10 安装 ...
- Zabbix监控服务器磁盘I/O
一.场景说明: 需要使用Zabbix监控服务器上各个磁盘的I/O使用率,当zabbix自身带的item无法满足我们的时候,则需自定义item. 包括: 磁盘读的次数 磁盘读的毫秒数 磁盘写的次 ...
- linux后台运行相关命令
1.nohup & 让程序后台运行,nohup 命令 & 2.jobs 查看当前有多少在后台运行的命令 jobs -l选项可显示所有任务的PID,jobs的状态可以是running, ...
- HDU - 5126: stars (求立方体内点数 CDQ套CDQ)
题意:现在给定空空的三维平面,有加点操作和询问立方体点数. 思路:考虑CDQ套CDQ.复杂度是O(NlogN*logN*logN),可以过此题. 具体的,这是一个四维偏序问题,4维分别是(times, ...
- wordpress怎么用AMP加速器呢
AMP项目(Accelerated Mobile Pages)是一个开放源代码计划,旨在为所有人打造更好的网络体验.借助该项目,用户可以打造出在各种设备和分发平台上都能始终如一地快速加载且效果出色的精 ...
- Java 字符流读写文件
据说,java读写文件要写很多,贼麻烦,不像c艹,几行代码就搞定.只能抄抄模板拿来用了. 输入输出流分字节流和字符流.先看看字符流的操作,字节转化为字符也可读写. 一.写入文件 1.FileWrite ...