linux中awk工具的使用(转)
add by zhj: awk很强大,它是一个简单的编程语言,国外有本专门的书介绍它的用法。《effective awk programming》,它支持整型,字符串型,数组,变量在使用前不需要
定义,直接使用,因为每种数据类型都有默认的初始值。它还支持if/for等逻辑语句
原文:https://blog.51cto.com/13866901/2166164?tdsourcetag=s_pctim_aiomsg
运行环境:centos6 Vmware
一、awk简介
awk是一个非常好用的数据处理工具,相对于sed常常作用于一整个行的处理,awk则比较倾向于一行当中分成数个【字段】处理,因此,awk相当适合处理小型的数据数据处理。awk是一种报表生成器,就是对文件进行格式化处理的,这里的格式化不是文件系统的格式化,而是对文件内容进行各种“排版”,进而格式化显示;在linux中我们使用的是GNU awk简称gawk,并且gawk其实就是awk的链接文件,因此在系统上使用awk和gawk是一样的。
二、awk的基本用法
awk[OPTIONS]'program' FILE1 FILE2
program:PATTERN{ACTION STATEMENT}
program:编程语言 PATTERN:模式 ACTIONSTATEMENT:动作语句,可以是多个语句,但多个语句中间要使用分号分隔
OPTIONS:-F[] 指明输入字段分割符 ; -v VALUE 变量赋值;
举例说明:
cat /etc/passwd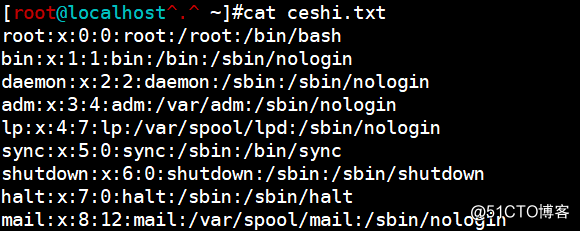
cat ceshi.txt |awk -v FS: '{print $1,$3}'(每行按冒号分割,输出第一个域和第三个域;默认为空格分割;注意:awk后续动作都要以单引号引起来)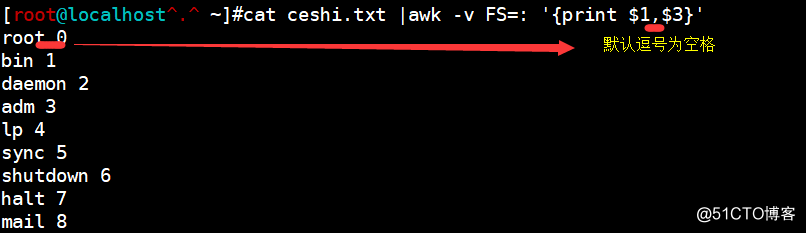
cat ceshi.txt |awk -v FS: '{print $1"XXXX"$3}'("XXXX"代表任意内容,必须用双引号引起来)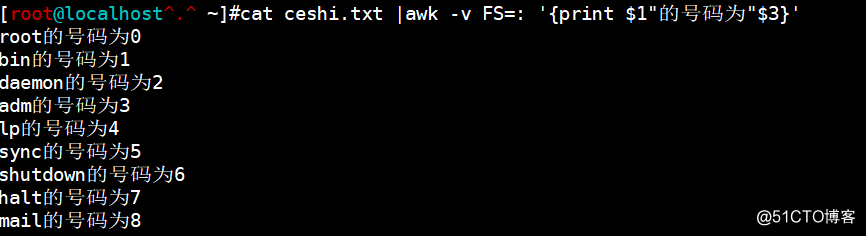
三、变量
1、内建变量
FS 输入字段分隔符,默认为空白
RS 输入的记录分隔符,默认为换行符
OFS 输出字段分割符,默认为空白字符
OFS 输出字段分隔符,默的认为换行符
NF 当前行的字段的数量
print NF 显示当前行的字段数
print $NF 显示当前行的第NF字段的值
NR 记录号
FNR 个文件分别计数,显示行号
FILENAME 当前文件名
ARGC 命令行参数的个数
ARGV 保存命令行所给定的各参数的数组
2、自定义变量
(1)-v VALUE (变量名称区分大小写)在这里文件ceshi.txt中有多少行就显示多少行变量的值
awk -v fan="cool" '{print fan}' ceshi.txt
(2)在program中自定义变量
awk 'BEGIN{FS=":";abc=1}{print $abc}' ceshi.txt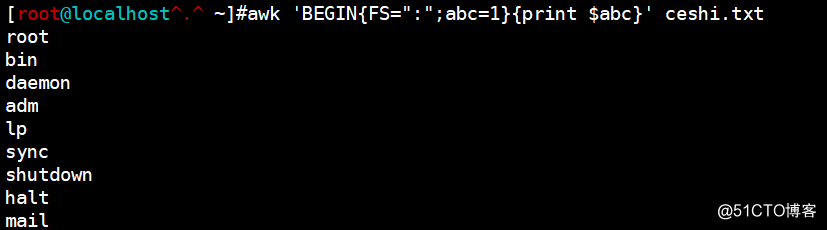
四、awk的格式化输出
语法 printf FORNAT,item1,item2
FORMAT必须提供
与print语句不同,printf不会自动换行,需要使用换行符\n
FORMAT中需要分别为后面的每个item指定一个格式符,否则item无法显示;
格式符介绍:
%c 显示字符的ASCII码
%d ,%i 显示为十进制整数
%e,%E 科学技术法显示数值
%f 显示为浮点数
%g,%G 以科学技术法或浮点数格式显示数值
%s 显示为字符串
%u 显示无符号整数
%% 当需要显示%号时需要连续打两个百分号
举例说明:
cat ceshi.txt |awk -F: '{printf "%-10s%s\n",$1,$3}'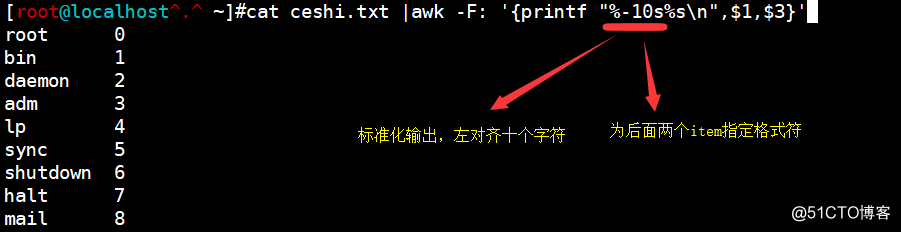
五、awk的操作符
算术操作符 如:A+B A-B A*B A/B
字符操作符 字符串链接
赋值操作符 如:== += /= %=
比较操作符 如:> >= < <=
模式匹配操作符 ~ 是否能由右侧指定的模式所匹配 !~是否不能由右侧指定的模式所匹配
逻辑操作符 && 与运算 || 或运算
条件表达式 selector?if-true-expression:if-ials-expreion
函数调用 调用函数来进行数据的处理
举例说明
通过df命令查看当前系统磁盘占用率,查出占用率大于等于百分之20的磁盘名称以及磁盘占用率
df|awk -v FS=% '$0 ~ "/dev/sd" {print $1}'|awk '$NF>=20 {printf "DevName:%-10s Used:%s%%\n",$1,$5}'
awk -v FS=: '{$3>=5?usertype="Big User":usertype="Small User";printf "UserName:%-15s Type:%s\n",$1,usertype}' ceshi.txt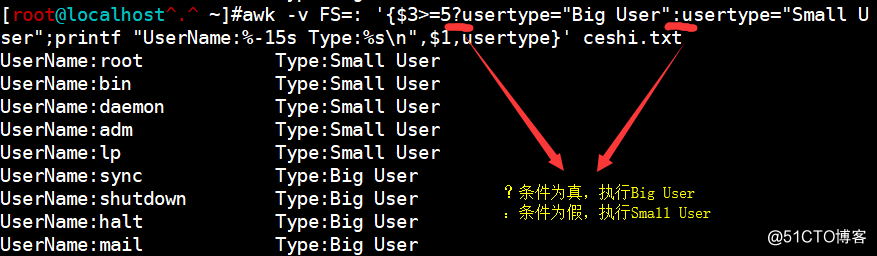
六、awk的控制语句
if(condition){statements}[else {statement}]
awk -F: '{if($3>=5){printf "%-10s%s\n",$1,$3}}' ceshi.txt
while循环 while(condition){statements}
echo {1..10} |awk '{n=1;while(n<=NF){if($n%2==0){print $n,"oushuo"}else {print $n,"jishu"};n++}}'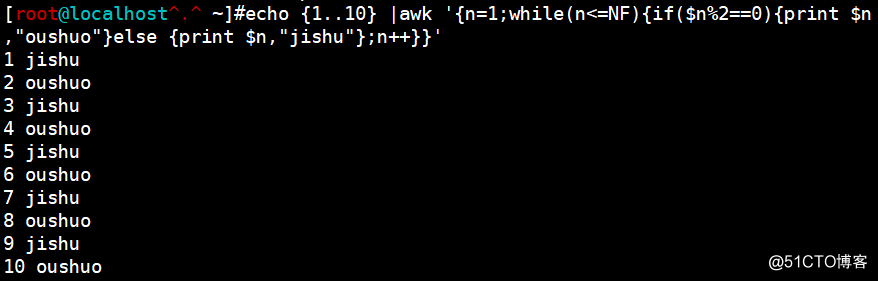
do-while循环
for循环
awk BEGIN'{for(i=1;i<=1000;i++){sum+=i};print sum}'
break
continue
delete array
exit
next 提前结束对本行文本的处理,而提前进入下一行的处理操作
awk -F: '{if($3%2==0)next;print $1,$3}' ceshi.txt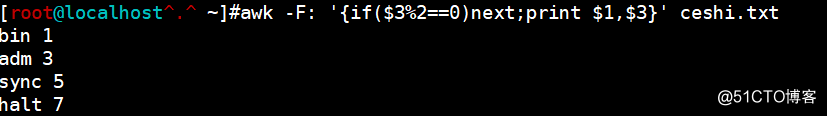
七、awk的性能测试
实验:从1加到100等于多少?
(1)time seq -s "+" 5000000 |bc

(2)time awk BEGIN'{for(i=1;i<=1000000;i++){sum+=i};print sum}'

(3)time awk BEGIN'{i=1;while(i<=1000000){sum+=i;i++};print sum}'

(4)time for ((i=1;i<=1000000;i++));do let sum+=i; done;echo $sum

八、awk数组
数组是一个包含一系列元素的表
格式如下:
abc[1]="libai"
abc[2]="lihei"
abc为数组名,[1][2]为数组下标,可以认为是数组的第一个元素,第二个元素,"libai""lihei"是元素的内容
举例说明:
awk 'BEGIN{fan[0]="libai";fan[1]="lihei";print fan[0]}'awk 'BEGIN{fan[0]="libai";fan[1]="lihei";print fan[1]}'
awk 'BEGIN{fan[0]="libai";fan[1]="lihei";for (i in fan)print i}'
awk -F: '{{fan[NR]=$1;}{print NR,fan[NR]}}' ceshi.txt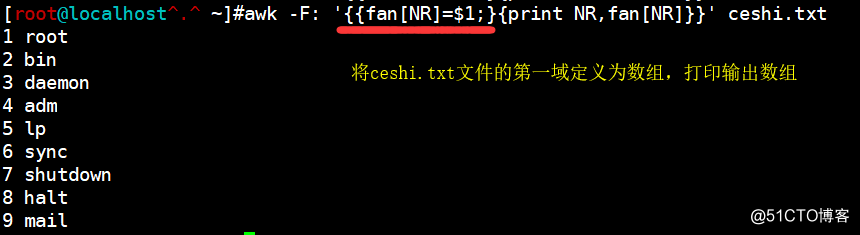
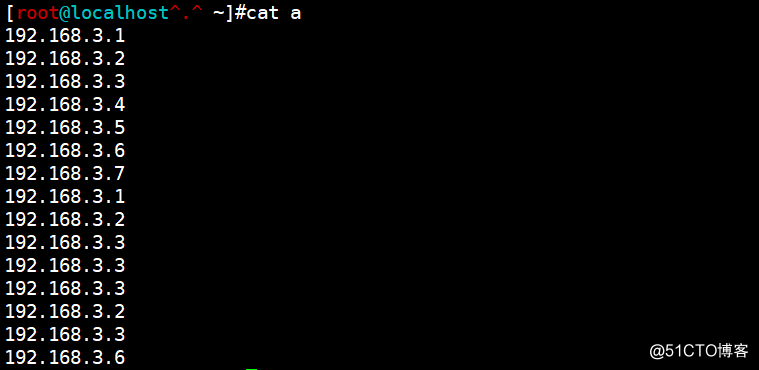
利用数组统计每个ip地址访问量(编辑一个文件,该文件存储ip地址)
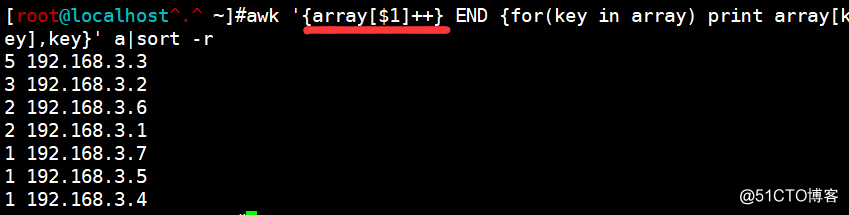
awk '{array[$1]++} END {for(key in array) print array[key],key}' a|sort -r关于array[$1]++
(1)awk在读取第一行的时候,会读取这个数组,此时的数组是这样的,array["第一行的内容"]++
(2)此时该数组的值还没有定义,但后面有运算符号++,所以awk会将数字0自动赋值给array["第一行的值"]做++运算,所以得到的值为1.
(3)在读到与array["第一行的内容"]相同的时候继续++运算,也就意味着,运算了多少次,就是出现了多少次。
九、awk函数
1、内键函数
(1)数值处理 rand() 返回0至1之间的一个随机数
awk 'BEGIN{print rand()}'
从这张图中我们发现了一个问题,通过使用rand函数生成随机数,但是rand函数返回的值一直不变,所以我们需要配合srand函数
awk 'BEGIN{srand();print rand()}'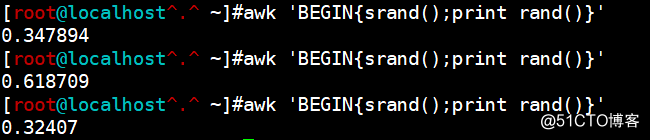
从这张图中我们发现生成的随机数产生了变化,但生成的随机数都是小于1的小数,如果我们想要生成整数随机数,我们可以利用int整数函数截取整数部分的值
awk 'BEGIN{srand();print 100*rand()}'awk 'BEGIN{srand();print int(100*rand())}'
(2)字符串函数
length([s]) 返回指定的字符串的长度
举例说明
awk '{print $0 length()}' abc.txt (每一行全部字符长度)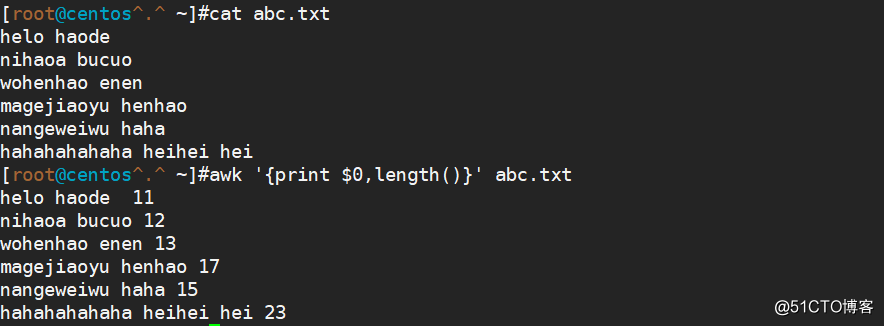
awk '{for(i=1;i<=NF;i++){print $i,length($i)}}' abc.txt(指定字符长度)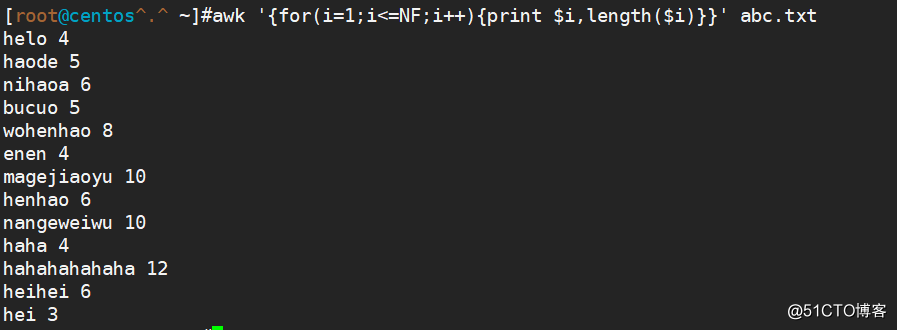
gsub(r,s[,t])基于r所表示的模式来匹配字符串t中的内容,将其所有被匹配到的内容均替换为s所表示的字符串
举例说明
awk '{gsub("h","H",$1);print $0}' abc.txt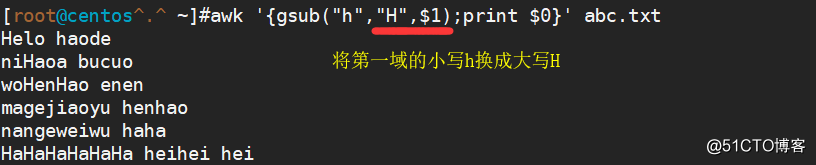
awk '{gsub("h","H",$0);print $0}' abc.txt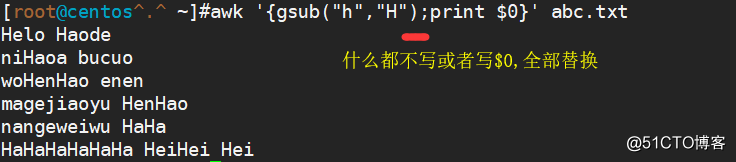
sub(r,s[,t]) 基于r所表示的模式来匹配字符串t中的内容,将其第一次被匹配到的内容替换为s所表示的字符串
举例说明
awk '{sub("h","H");print $0}' abc.txt(只替换指定范围第一次匹配到的符合条件的字符)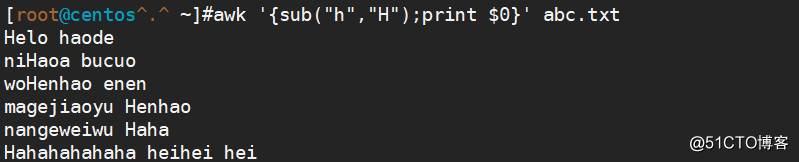
split(s,a[,r]) 以r为分隔符去切割字符串s,并将切割后的结果保存至a表示的数组中
举例说明
awk -v aa="李大;李二;李三" 'BEGIN{split(aa,lishijiazu,";");for(i in lishijiazu){print lishijiazu[i]}}'
awk -v aa="cc;ff;dd;ee" 'BEGIN{split(aa,lishijiazu,";");for(i in lishijiazu){print lishijiazu[i]}}'
从上图中我们发现数组元素输出顺序可能与字符串中字符的顺序不同,我们可以采用下面的办法
awk -v aa="cc;ff;dd;ee" 'BEGIN{ abc=split(aa,lishijiazu,";");for(i=1;i<=abc;i++){print i,lishijiazu[i]}}'
2、用户自定义函数
函数是程序的基本组成部分,awk允许我们定义自己的函数,一个大的程序可以分为多个函数并且每个函数可以独立测试
用户自定义函数的一般格式为:
function function_name(argument1,argument2,...)
{
function body
}function_name是用户定义函数的名称,函数名称应以字符的字母并且其余部分可以是数字,字母或下划线的任意组合,awk的保留字不能用作函数名字;函数可以接受以逗号分隔的多个参数,参数不是强制性的,我们也可以创建一个用户定义的函数不带任何参数;函数体由一个或多个awk语句组成。
linux中awk工具的使用(转)的更多相关文章
- [转帖]Linux中awk工具的使用
Linux中awk工具的使用 2018年10月09日 17:26:20 谢公子 阅读数 2170更多 分类专栏: linux系统安全 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权 ...
- linux中awk工具的使用(转载)
awk是一个非常好用的数据处理工具.相较于sed常常一整行处理,awk则比较倾向于一行当中分成数个“字段”处理,awk处理方式如下: $ awk '条件类型1{动作1} 条件类型2{动作2} ...' ...
- linux中awk工具的使用
awk是一个非常好用的数据处理工具.相较于sed常常一整行处理,awk则比较倾向于一行当中分成数个“字段”处理,awk处理方式如下: $ awk '条件类型1{动作1} 条件类型2{动作2} ...' ...
- linux中awk工具
awk sed以行为单位处理文件,awk比sed强的地方在于不仅能以行为单位还能以列为单位处理文件.awk缺省的行分隔符是换行,缺省的列分隔符是连续的空格和Tab,但是行分隔符和列分隔符都可以自定义, ...
- linux中awk的使用
在linux中awk绝对是核心工具,特别是在查找搜索这一领域,和掌握sed命令一样重要 下面为awk的一些基本知识,基于这些知识,可以让你随意操控一个文件: 在awk中:()括号为条件块,{}为执行的 ...
- linux中awk命令(最全面秒懂)
目录 一:linux中awk命令 1.awk命令简介 2.awk作用 3.awk的语法格式 4.解析awk使用方法 5.参数 6.awk的生命周期 二:awk中的预定义变量 三:awk运行处理规则的执 ...
- linux中awk命令详解(最全面秒懂)
一:linux中awk命令 1.awk命令简介 AWK 是一种处理文本文件的语言,是一个强大的文本分析工具. 之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinber ...
- Linux中awk后面的RS, ORS, FS, OFS 用法
Linux中awk后面的RS, ORS, FS, OFS 含义 一.RS 与 ORS 差在哪 我们经常会说,awk是基于行列操作文本的,但如何定义“行”呢?这就是RS的作用. 默认情况下,RS的 ...
- linux中awk 详解
一.awk简介 awk是一个非常好用的数据处理工具,相对于sed常常作用于一整个行的处理,awk则比较倾向于一行当中分成数个[字段]处理,因此,awk相当适合处理小型的数据数据处理.awk是一种报表生 ...
随机推荐
- Vue入门篇
Vue-cli开发环境搭建 1. 安装nodejs 2. 设置缓存文件夹 $ npm config set cache "D:\vueProject\nodejs\node_cache&qu ...
- loadrunner安装和应用
问题:1.负载测试流程 2.为什么实现性能测试自动化 3.设置场景 (场景定义) 4.事物响应时间,吞吐量和吞吐率,正在运行vuser,windows资源,每秒点击次数,每秒http响应数. 5.i ...
- ta和夏天一起来了
目录 ta和夏天一起来了 上半年,过去的就让去过去,遗憾的也别再遗憾. 下半年,拥有的请好好珍惜,想要的请努力去追. ta和夏天一起来了 转眼结束了2019的上半年,在这个月末, 季度末, 周末, ...
- SqlServer数据库优化之索引、临时表
问题:工作是查询一张500万多条数据的表时,查询总是很慢,于是进行优化. --查询表所有索引 use RYTreasureDB EXEC Sp_helpindex [RecordDrawScore] ...
- Canny算法检测边缘
Canny算法是边缘检测的一个经典算法,比单纯用一些微分算子来检测的效果要好很多,其优势有以下几点: 边缘误检与漏检率低. 边缘定位准确,且边界较细. 自带一定的滤噪功能,或者说,对噪声的敏感度要比单 ...
- pandas 之 groupby 聚合函数
import numpy as np import pandas as pd 聚合函数 Aggregations refer to any data transformation that produ ...
- office viso 2007根据现有数据库建立数据库模型图
当数据库表很多的时候,表之间的关系就变得很复杂.光凭记忆很难记住,尤其是数据库键值没有外键约束时. 所以有个数据库模型图各个表之间的关系就显而易见了. 打开 office viso 2007 文件&g ...
- python处理excel函数xlrd、xlwt
https://www.jianshu.com/p/f2c9dff344c6 https://www.cnblogs.com/ilovepython/p/11068841.html 行列操作:http ...
- Hbase优化:(待重点研究)
一.服务端调优 1.参数配置 1).hbase.regionserver.handler.count:该设置决定了处理RPC的线程数量,默认值是10,通常可以调大,比如:150,当请求内容很大(上MB ...
- 爬虫-lxml用法
安装 pip install lxml 用法 # coding=utf-8 from lxml import etree text = ''' <div> <ul> <l ...