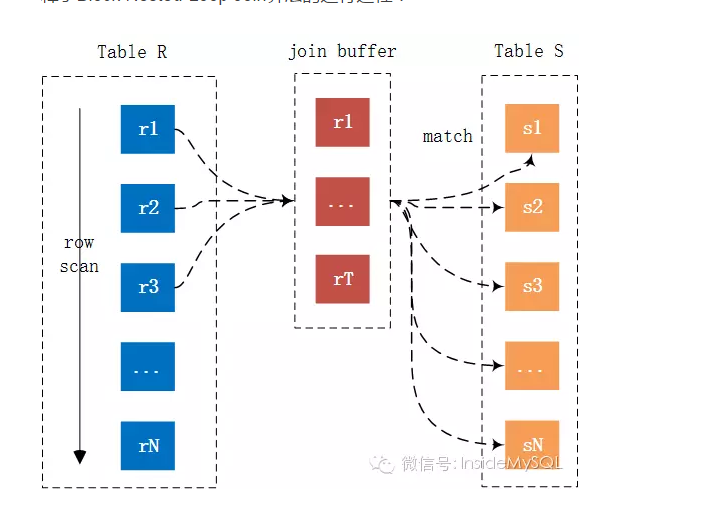
MySQL JOIN原理(转)
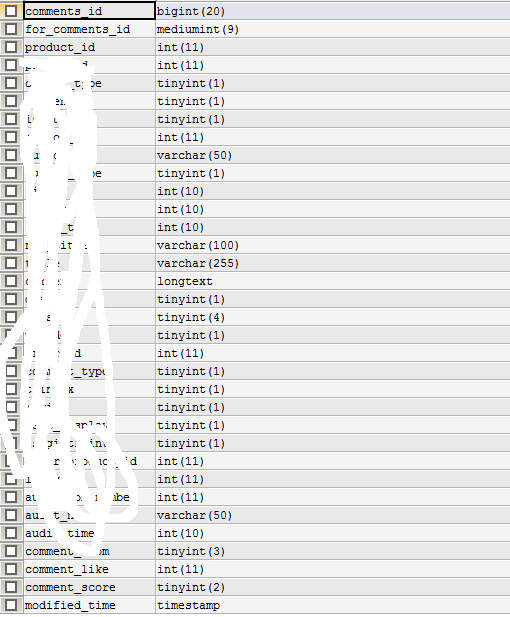
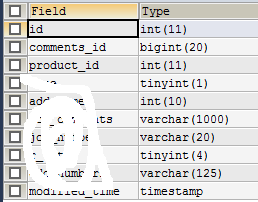
先看一下实验的两张表:
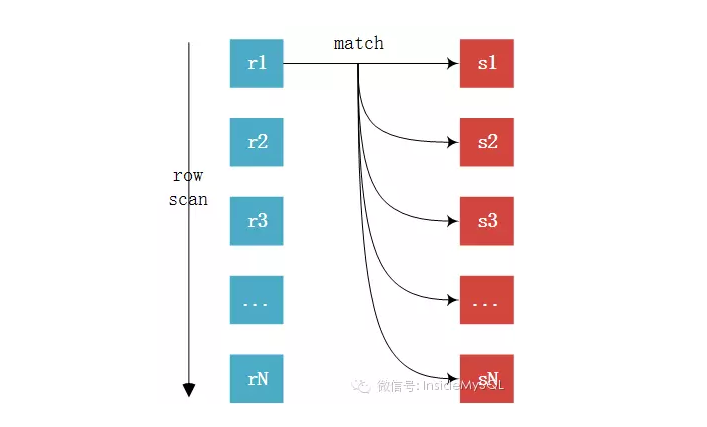
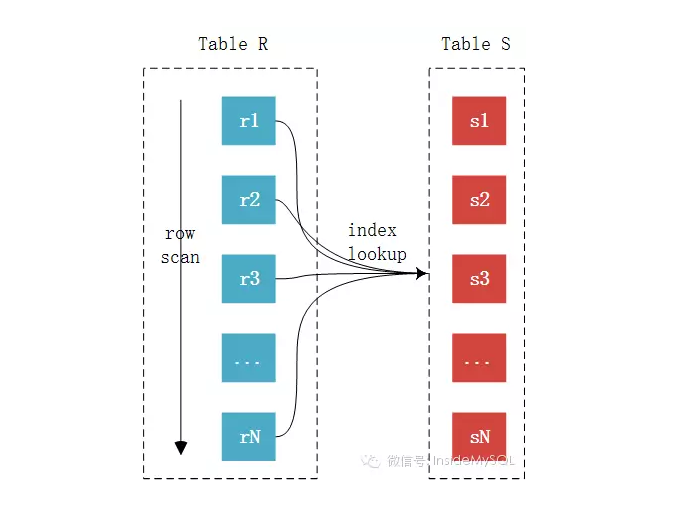
EXPLAIN SELECT * FROM comments gc
JOIN comments_for gcf ON gc.comments_id=gcf.comments_id;

SELECT * FROM comments gc
JOIN comments_for gcf ON gc.comments_id=gcf.comments_id
WHERE gc.comments_id =2056

EXPLAIN SELECT * FROM comments gc
JOIN comments_for gcf ON gc.order_id=gcf.product_id

EXPLAIN SELECT * FROM comments gc
LEFT JOIN comments_for gcf ON gc.comments_id=gcf.comments_id

EXPLAIN SELECT * FROM comments_for gcf
LEFT JOIN comments gc ON gc.comments_id=gcf.comments_id
WHERE gcf.comments_id =2056
 此,join基本上已经很明了了,未完待续中,欢迎大家指出错误,我会认真改正。。。。
此,join基本上已经很明了了,未完待续中,欢迎大家指出错误,我会认真改正。。。。MySQL JOIN原理(转)的更多相关文章
- MySQL JOIN原理
先看一下实验的两张表: 表comments,总行数28856 表comments_for,总行数57,comments_id是有索引的,ID列为主键. 以上两张表是我们测试的基础,然后看一下索引,co ...
- 由一个场景分析Mysql的join原理
背景 这几天同事写报表,sql语句如下 select * from `sail_marketing`.`mk_coupon_log` a left join `cp0`.`coupon` c on c ...
- MySQL索引原理及慢查询优化
原文:http://tech.meituan.com/mysql-index.html 一个慢查询引发的思考 select count(*) from task where status=2 and ...
- (转)MySQL索引原理及慢查询优化
转自美团技术博客,原文地址:http://tech.meituan.com/mysql-index.html 建索引的一些原则: 1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到 ...
- MySQL索引原理及慢查询优化 转载
原文地址: http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能 ...
- MySQL索引原理及慢查询优化(转)
add by zhj:这是美团点评技术团队的一篇文章,讲的挺不错的. 原文:http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰 ...
- 【转载】MySQL索引原理及慢查询优化
原文链接:美团点评技术团队:http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型 ...
- MySQL查询原理及其慢查询优化案例分享(转)
MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能出色,但所谓“好马配好鞍”,如何能够更 好的使用它,已经成为开发工程师的必修课,我们经常会从职 ...
- MySQL索引原理与慢查询优化
索引目的 索引的目的在于提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql.如果没有索引,那么你可能需要把所有单词看一遍才 ...
随机推荐
- OpenStack Neutron单网卡桥接模式访问外网
环境配置: * Exsi一台 * Exsi创建的单网卡虚拟机一台 * Ubuntu 14LTS 64位操作系统 * OpenStack Liberty版本 * 使用Neutron网络而非Nova网络 ...
- OutOfMemoryError异常——Java堆溢出。
https://blog.csdn.net/en_joker/article/details/79726975 (将堆的最小值-Xms参数与最大值-Xmx参数设置为一样即可避免堆自动扩展),通过参数- ...
- Swift自定义AlertView
今天项目加新需求,添加积分过期提醒功能: 第一反应就用系统的UIAlertViewController,但是message中积分是需要红色显示. // let str = "尊敬的顾客,您有 ...
- 端口占用问题:java.net.BindException: Address already in use: bind
解决方法 方法一:换一个端口 若仍然想要使用该端口,则可以将占用该端口的进程杀死即可. 方法二:杀死占用该端口的进程 若仍然想要使用该端口,则可以将占用该端口的进程杀死即可 查找端口被占用的进程id ...
- Django框架之DRF get post put delete 使用简单示例 (利用序列化反序列化)
路由配置 # 路由 from django.conf.urls import url from django.contrib import admin from app01 import views ...
- SQL——BETWEEN操作符
一.BETWEEN操作符的基本用法 BETWEEN操作符用于选取两个值范围内的值. 语法格式如下: SELECT 列名1,列名2... FROM 表名 WHERE 列名 BETWEEN 值1 AND ...
- HTML-点击Div读取本地文件内容
<!DOCTYPE html> <html> <div id="container" onclick="choosefile();" ...
- Go 协程
Go 协程 协程与传统的系统级线程和进程相比,协程的优势在于其"轻量级",可以轻松创建上百万个协程而不会导致系统资源衰竭,所以协程也叫做轻量级线程. 在Go中goroutine就是 ...
- shell中通过eval执行一个字符串命令
#!/bin/bash echo "Switch Directory : /home/pktgen-2.9.0" dir="/home/pktgen-2.9.0" ...
- 【LEETCODE】39、第561题 Array Partition I
package y2019.Algorithm.array; /** * @ProjectName: cutter-point * @Package: y2019.Algorithm.array * ...