java(集合框架)(转)
前言
集合①只能存放对象,存放基本类型会自动转成对应的对象②可以存放不同类型的对象(如果不使用泛型的话),且不限数量③集合中存放的只是对象的引用
集合详解


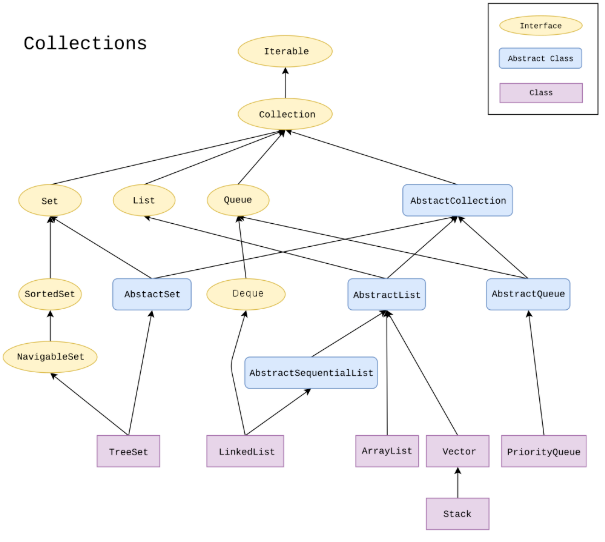
Iterable接口(java.lang包)
Collection继承了该接口,所以Collection的实现类都可以使用Iterator()方法来获得迭代器,从而遍历集合
public interface Iterable<E> {
Iterator<E> iterator();//return a Iterator Object
}
Iterator接口(迭代器,java.util包)
迭代器可以使用for-each代替。迭代器相当于一个在两个元素之间的指针(首尾元素除外),使用remove()删除元素之前,需要先调用next()越过该元素。如果调用next()之后,集合发生了改变,再接着调用remove()则会抛出异常。
public interface Iterator<E>{
E next();//返回迭代器刚越过的元素的引用
boolean hasNext();//判断容器内是否还有可供访问的元素
void remove();//删除迭代器刚越过的元素,所以要删除则必须先越过
}
ListIterator接口
ListIterator接口继承了Iterator接口,并添加了一些方法,使得可以向前和向后遍历。
add
set//修改越过的元素
previous
hasPrevious
nextIndex//返回下一次调用next方法返回的元素的索引
previousIndex
获取迭代器默认其指针是在第一个元素的前面,可以通过给定一个参数n来指定指针位置为第n个元素的前面(ListIterator有,Iterator没有这个),不过获取这样的迭代器消耗的时间比默认状态的迭代器要高一些。另外需要注意的是remove依赖迭代器的状态,add只依赖迭代器的位置
Collection
Collection接口定义了很多方法,开发者如果要开发自己的集合类,可以继承AbstractCollection抽象类,该类实现了Collection的很多方法,但是还有size()和Iterator()没实现
| 方法 | 描述 |
|---|---|
iterator() |
获取迭代器 |
size() |
元素个数 |
isEmpty() |
判断有无元素 |
clear() |
清空集合 |
contains() |
是否包含给定元素 |
containsAll() |
是否包含给定集合所有元素 |
add() |
添加元素 |
addAll() |
添加给定集合所有元素 |
remove() |
删除元素 |
removeAll() |
删除给定集合中所有元素 |
retainAll() |
删除给定集合中不存在的元素,即取交集 |
toArray() |
返回集合的对象数组 |
toArray(array) |
同上,不过指定一个数组参数 |
List
List可以获得ListIterator迭代器,List可以有重复的元素,元素可以按照使用者的意愿排序,元素的位置跟元素的值没有关系,因此称为有序
- ArrayList
底层数据结构是数组,查询快,增删慢,线程不安全,效率高。ArrayList维护封装了一个动态分配的对象数组,可以通过索引快速访问/修改元素,也可以通过迭代器 - LinkedList
底层数据结构是链表,查询慢,增删快,线程不安全,效率高;链表不能像数组那样通过索引来随机访问/修改元素,必须从头开始,越过一个个元素。链表增删元素是通过ListIterator迭代器来操作。LinkedList还是双端队列
addFirst
addLast
getFirst
getLast
removeFirst
removeLast
- Vector
底层数据结构是数组,查询快,增删慢,线程安全,效率低,几乎已经淘汰
Set
Set不可以有重复的元素,只能用Iterator迭代器,不能使用ListIterator迭代器
- HashSet(散列集)
不允许重复,判断重复的标准是equals为true,且hashCode相等,允许null(最多一个),无序。元素的位置是由元素本身的hashCode来决定的,也就是说元素的位置是跟元素的值相关的,使用者无法决定(改变),更直白地说,一个元素的值确定了,它的位置就基本确定了,元素的值改变了,其在散列集中的位置也会改变,因此我们称其为无序的。HashSet中的元素需要重写equals和hashCode方法,并确保equals返回true,则它们的hashCode必须相等。散列集底层数据结构是链表数组,每个链表称为桶(bucket),标准库中桶的数量是2的幂次方,默认为16,也可以自己指定。当添加一个元素的时候,用元素的散列码对桶数求余,余数即为该元素的桶的索引,也就是说求余结果相同的元素都位于同一个桶中,再将元素与该桶中的元素进行equals比较,如果为true,说明已经存在相同的元素,则不添加,如果为false,则添加;散列表中的元素占散列表空间的比例称为装载因子(load factor,size/桶数),当比例超过装载因子时,散列表就会用双倍的桶数自动进行再散列。一般装载因子为0.75就可以了,跟桶数一样,装载因子可以在构造散列表的时候设置 - TreeSet
不允许重复,判断重复的标准是CompareTo或compare返回0,不允许null,有序。底层数据结构是红黑树,擅长于范围查询。要求元素实现了Comparable接口(compareTo方法自然排序),也可以在构造树集的时候提供一个实现了Comparator接口(compare方法)的比较器,则树集将会按照提供的比较器的规则进行排序,将一个元素添加到TreeSet的速度要比HashSet的速度慢一点,查找新元素的正确位置的平均时间为log2(n),比元素添加到数组和链表中的正确位置(指按同一种规定的顺序)要快很多 LinkedHashSet
不可以重复,判断重复的标准是equals为true,且hashCode相等,有序(记录了插入顺序)。因为底层采用链表和哈希表的算法。链表保证元素的添加顺序,哈希表保证元素的唯一性 LinkedHashSet.png
LinkedHashSet.png

队列和双端队列
队列可以有效的在队列尾部添加元素,头部删除元素。双端队列可以同时在尾部和头部添加和删除元素,不过不可以在中间。ArrayDeque和LinkedList实现了双端队列
优先级队列PriorityQueue
底层数据结构是堆(heap)。典型示例为任务调度。优先级队列跟TreeSet一样,需要元素实现Comparable接口或在构造时提供Comparator比较器。无论以什么顺序插入,remove()的总是优先级队列里最小的元素,然而优先级队列并没有对所有元素进行排序,只是确保了remove出来的是最小的元素
阻塞队列BlockingQueue
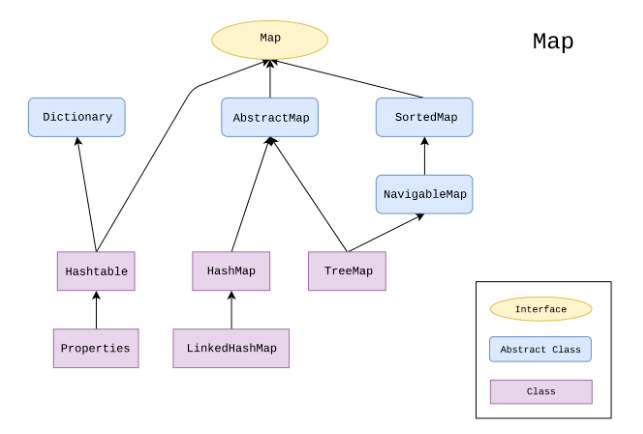
映射表Map
映射表存储的是键值对,Map不能使用for-each循环进行遍历,因为它既不是Collection系列,也没继承Iterable接口
//Map的方法
put
get
putAll
containsKey
containsValue
Set<Map.Entry<K,V>> entrySet()//后面3个方法返回的是Map的视图,可以通过这三个集修改和删除元素,则Map中也会相应改变,但是不能添加元素
Set<K> keySet()
Collection<V> values()
//Entry的方法
getKey
getValue
setValue
HashMap
对键进行散列,键不允许重复,允许为null(最多一个),判断键重复的标准是键的equals为true,且键的hashCode相等TreeMap
对键进行排序,用键的顺序对元素进行排序,键不允许重复,判断键重复的标准是键compareTo或compare为0LinkedHashMap
与HashMap类似,只是多了链表保证键有序(记录了访问顺序,每次因调用了get/set方法受到影响的元素都会从当前链表位置删除,放到链表末尾,但注意在桶中的位置是不会受影响的)WeakHashMap
弱散列映射表Hashtable
与HashMap一样,不过线程安全,性能低Properties
Hashtable的子类,要求键值都是字符串,一般用于配置文件
Set和Map
都有几个类型的集合。HashMap 和 HashSet ,都采哈希表算法;TreeMap 和 TreeSet 都采用 红-黑树算法;LinkedHashMap 和 LinkedHashSet 都采用 哈希表算法和红-黑树算法。分析 Set 的底层源码,我们可以看到,Set 集合 就是 由 Map 集合的 Key 组成,只不过Value是同一个Object对象

常用的hashCode方法

线程安全解决
- Set
Set set = Collections.synchronizedSet(Set 对象) - Map
Map map= Collections.synchronizedSet(Map对象)
集合和数组转换
- 数组转集合
Arrays.asList()
String[] strs = new String[10];
List<String> list = Arrays.asList(strs);//list是原数组的视图
集合转数组
toArray(数组)
HashSet<String> staff = new HashSet<>(...);
String[] strs = staff.toArray();//error
String[] strs = staff.toArray(new String[]);//ok
String[] strs = staff.toArray(new String[staff.size()]);//ok
数组复制方法
- clone
clone方法是从Object类继承来的,对于基本类型的数组可以直接使用,String类数组也可以使用,因为String是不可变类,对于可变类,clone方法是浅拷贝
int[] a1 = {1, 3};
int[] a2 = a1.clone();
a1[0] = 666;
System.out.println(Arrays.toString(a1)); //[666, 3]
System.out.println(Arrays.toString(a2)); //[1, 3]
String[] s1 = {"a1", "a2"};
String[] s2 = s1.clone();
a1[0] = "b1"; //更改a1数组中元素的值
System.out.println(Arrays.toString(s1)); //[b1, a2]
System.out.println(Arrays.toString(s2)); //[a1, a2]
System.arraycopy
System.arraycopy是一个本地方法,源码定义如下
public static native void arraycopy(Object src, int srcPos, Object dest, int desPos, int length)
//参数含义(原数组, 原数组的开始位置, 目标数组, 目标数组的开始位置, 拷贝长度)
Arrays.copyOf
Arrays.copyOf底层其实也是用的System.arraycopy ,参数含义(原数组,拷贝长度)源码如下:
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
Arrays.copyOfRange
Arrays.copyOfRange底层其实也是用的System.arraycopy,只不过封装了一个方法,参数含义(原数组,开始位置,拷贝长度)
public static <T,U> T[] copyOfRange(U[] original, int from, int to, Class<? extends T[]> newType) {
int newLength = to - from;
if (newLength < 0)
throw new IllegalArgumentException(from + " > " + to);
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, from, copy, 0,
Math.min(original.length - from, newLength));
return copy;
}
深拷贝
- 简单类
数据域为基本类型或不可变类,实现Cloneable接口,并重写clone方法,注意一个类不实现这个接口,直接使用clone方法是编译通不过的
@Override
public Cat clone() throws CloneNotSupportedException {
Cat cat = (Cat) super.clone();
return dog;
}
如果一个类里面,又引用其他的类,其他的类又有引用别的类,那么想要深度拷贝必须所有的类及其引用的类都得实现Cloneable接口,重写clone方法,这样以来非常麻烦,简单的方法是让所有的对象实现序列化接口(Serializable,该接口仅是一个标记,没有方法),然后通过序列化-反序列化的方法来深度拷贝对象。
public Cat myClone() {
Cat cat = null;
try {
//将对象序列化成为流,因为现在流是对象的一个拷贝
//而原始对象仍然存在于JVM中,所以利用这个特性可以实现深拷贝
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);
objectOutputStream.writeObject(this);
//将流序列化为对象
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(byteArrayOutputStream.toByteArray());
ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream);
cat = (Cat) objectInputStream.readObject();
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
return cat;
}
java(集合框架)(转)的更多相关文章
- Java集合框架List,Map,Set等全面介绍
Java集合框架的基本接口/类层次结构: java.util.Collection [I]+--java.util.List [I] +--java.util.ArrayList [C] +- ...
- Java集合框架练习-计算表达式的值
最近在看<算法>这本书,正好看到一个计算表达式的问题,于是就打算写一下,也正好熟悉一下Java集合框架的使用,大致测试了一下,没啥问题. import java.util.*; /* * ...
- 【集合框架】Java集合框架综述
一.前言 现笔者打算做关于Java集合框架的教程,具体是打算分析Java源码,因为平时在写程序的过程中用Java集合特别频繁,但是对于里面一些具体的原理还没有进行很好的梳理,所以拟从源码的角度去熟悉梳 ...
- Java 集合框架
Java集合框架大致可以分为五个部分:List列表,Set集合.Map映射.迭代器.工具类 List 接口通常表示一个列表(数组.队列.链表 栈),其中的元素 可以重复 的是:ArrayList 和L ...
- Java集合框架之map
Java集合框架之map. Map的主要实现类有HashMap,LinkedHashMap,TreeMap,等等.具体可参阅API文档. 其中HashMap是无序排序. LinkedHashMap是自 ...
- 22章、Java集合框架习题
1.描述Java集合框架.列出接口.便利抽象类和具体类. Java集合框架支持2种容器:(1) 集合(Collection),存储元素集合 (2)图(Map),存储键值对.
- Java集合框架实现自定义排序
Java集合框架针对不同的数据结构提供了多种排序的方法,虽然很多时候我们可以自己实现排序,比如数组等,但是灵活的使用JDK提供的排序方法,可以提高开发效率,而且通常JDK的实现要比自己造的轮子性能更优 ...
- (转)Java集合框架:HashMap
来源:朱小厮 链接:http://blog.csdn.net/u013256816/article/details/50912762 Java集合框架概述 Java集合框架无论是在工作.学习.面试中都 ...
- Java集合框架
集合框架体系如图所示 Java 集合框架提供了一套性能优良,使用方便的接口和类,java集合框架位于java.util包中, 所以当使用集合框架的时候需要进行导包. Map接口的常用方法 Map接口提 ...
- Java集合框架(常用类) JCF
Java集合框架(常用类) JCF 为了实现某一目的或功能而预先设计好一系列封装好的具有继承关系或实现关系类的接口: 集合的由来: 特点:元素类型可以不同,集合长度可变,空间不固定: 管理集合类和接口 ...
随机推荐
- Mongodb3.6 Replica Set 配置
单机下执行: /usr/local/mongodb/bin/mongod --dbpath /usr/local/mongodb/r1 --port --replSet myset /usr/loca ...
- python3 queue队列
一.queue队列 1.python3中的队列模块是queue,不是Queue 2.一般涉及到同步,多线程之类用到队列模块 3.定义了 queue.Queue 类,以及继承它的 queue.LifoQ ...
- 《The One!团队》:BETA Scrum metting3
项目 内容 作业所属课程 所属课程 作业要求 作业要求 团队名称 < The One !> 作业学习目标 (1)掌握软件黑盒测试技术:(2)学会编制软件项目总结PPT.项目验收报告:(3) ...
- keras模块学习之-目标函数(objectives)笔记
本笔记由博客园-圆柱模板 博主整理笔记发布,转载需注明,谢谢合作! 目标函数又称损失函数(loss),目的是计算神经网络的输出与样本标记的差的一种方法,如: model = Sequential() ...
- sql查询排序
ORDER BY _column1, _column2; /* _column1升序,_column2升序 */ ORDER BY _column1, _column2 DESC; /* ...
- 关于redis的持久化策略
Redis的持久化 Redis虽然是基于内存的存储系统,但是它本身是支持内存数据的持久化的,而且提供两种主要的持久化策略:RDB快照和AOF日志. Redis的RDB快照 Redis支持将当前数据的快 ...
- TortoiseGit-下载安装汉语语言包(汉化-方法)
TortoiseGit是一款版本控制软件,和git bash是差不多的, 但是TortoiseGit是图形界面,git bash却是命令界面,但是, 我更新了TortoiseGit后,记得明明选择了汉 ...
- bind、apply、call的理解
一直感觉代码中有call和apply就很高大上(看不懂),但是都草草略过,今天非要弄明白!以前总是死记硬背:call.apply.bind 都是用来修改函数中的this,传参时,call是一个个传参, ...
- js 全选反选
<th><input type="checkbox" id="checkall" name="checkall" oncl ...
- 3-html块-语义化的标签
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...