HDFS 分布式文件系统
博客出处W3c:https://www.w3cschool.cn/hadoop/xvmi1hd6.html
简介
Hadoop Distributed File System,分布式文件系统
架构
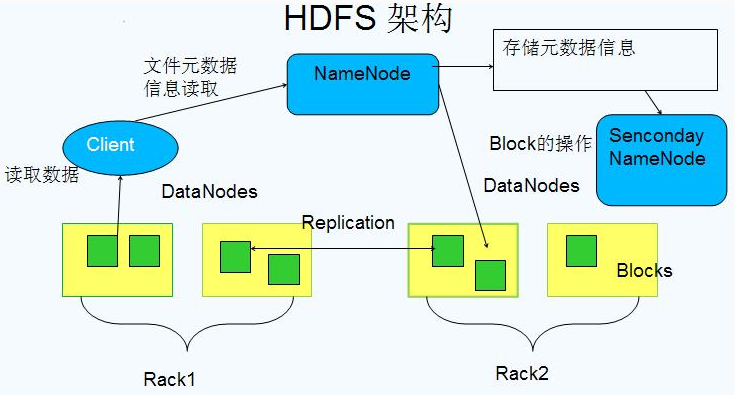
Block数据&##x5757;
基本存储单位,一般大小为64M(配置大的块主要是因为:1)减少搜寻时间,一般硬盘传输速率比寻道时间要快,大的块可以减少寻道时间;2)减少管理块的数据开销,每个块都需要在NameNode上有对应的记录;3)对数据块进行读写,减少建立网络的连接成本)
一个大文件会被拆分成一个个的块,然后存储于不同的机器。如果一个文件少于Block大小,那么实际占用的空间为其文件的大小
基本的读写S#x5355;位,类似于磁盘的页,每次都是读写一个块
- 每个块都会被复制到多台机器,默认复制3份
NameNode
存储文件的metadata,运行时所有数据都保存到内存,整个HDFS可存储的文件数受限于NameNode的内存大小
一个Block在NameNode中对应一条记录(一般一个block占用150字节),如果是大量的小文件,会消耗大量内存。同时map task的数量是由splits来决定的,所以用MapReduce处理大量的小文件时,就会产生过多的map task,线程管理开销将会增加作业时间。处理大量小文件的速度远远小于处理同等大小的大文件的速度。因此Hadoop建议存储大文件
数据会定时保存到本地磁盘,但不保存block的位置信息,而是由DataNode注册时上报和运行时维护(NameNode中与DataNode相关的信息并不保存到NameNode的文件系统中,而是NameNode每次重启后,动态重建)
- NameNode失效则整个HDFS都失效了,所以要保证NameNode的可用性
Secondary NameNode
- 定时与NameNode进行同步(定期合并文件系统镜像和编辑日&#x#x5FD7;,然后把合并后的传给NameNode,替换其镜像,并清空编辑日志,类似于CheckPoint机制),但NameNode失效后仍需要手工将其设置成主机
DataNode
保存具体的block数据
负责数据的读写操作和复制操作
DataNode启动时会向NameNode报告当前存储的数据块信息,后续也会定时报告修改信息
- DataNode之间会进行通信,复制数据块,保证数据的冗余性
HDFS 分布式文件系统的更多相关文章
- HDFS分布式文件系统资源管理器开发总结
HDFS,全称Hadoop分布式文件系统,作为Hadoop生态技术圈底层的关键技术之一,被设计成适合运行在通用硬件上的分布式文件系统.它和现有的分布式文件系统有很多共同点,但同时,它和其他的分布式 ...
- 通过Thrift访问HDFS分布式文件系统的性能瓶颈分析
通过Thrift访问HDFS分布式文件系统的性能瓶颈分析 引言 Hadoop提供的HDFS布式文件存储系统,提供了基于thrift的客户端访问支持,但是因为Thrift自身的访问特点,在高并发的访问情 ...
- Hadoop HDFS分布式文件系统 常用命令汇总
引言:我们维护hadoop系统的时候,必不可少需要对HDFS分布式文件系统做操作,例如拷贝一个文件/目录,查看HDFS文件系统目录下的内容,删除HDFS文件系统中的内容(文件/目录),还有HDFS管理 ...
- Hadoop基础-HDFS分布式文件系统的存储
Hadoop基础-HDFS分布式文件系统的存储 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS数据块 1>.磁盘中的数据块 每个磁盘都有默认的数据块大小,这个磁盘 ...
- 认识HDFS分布式文件系统
1.设计基础目标 (1) 错误是常态,需要使用数据冗余 (2)流式数据访问.数据批量读而不是随机速写,不支持OLTP,hadoop擅长数据分析而不是事物处理. (3)文件采用一次性写多次读的模型, ...
- 1、HDFS分布式文件系统
1.HDFS分布式文件系统 分布式存储 分布式计算 2.hadoop hadoop含有四个模块,分别是 common. hdfs和yarn. common 公共模块. HDFS hadoop dist ...
- 我理解中的Hadoop HDFS分布式文件系统
一,什么是分布式文件系统,分布式文件系统能干什么 在学习一个文件系统时,首先我先想到的是,学习它能为我们提供什么样的服务,它的价值在哪里,为什么要去学它.以这样的方式去理解它之后在日后的深入学习中才能 ...
- 大数据基础总结---HDFS分布式文件系统
HDFS分布式文件系统 文件系统的基本概述 文件系统定义:文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易. 文件名:在文件系统中,文件名是用于定位存储位置. 元数据(Metad ...
- hdfs(分布式文件系统)优缺点
hdfs(分布式文件系统) 优点 支持超大文件 支持超大文件.超大文件在这里指的是几百M,几百GB,甚至几TB大小的文件.一般来说hadoop的文件系统会存储TB级别或者PB级别的数据.所以在企业的应 ...
- 【史上最全】Hadoop 核心 - HDFS 分布式文件系统详解(上万字建议收藏)
1. HDFS概述 Hadoop 分布式系统框架中,首要的基础功能就是文件系统,在 Hadoop 中使用 FileSystem 这个抽象类来表示我们的文件系统,这个抽象类下面有很多子实现类,究竟使用哪 ...
随机推荐
- layUI学习第一日:myeclipse中使用layUI
第一步:下载layUI,网址:https://www.layui.com/ 第二步:查看layUI解压后的内容,和官网解释各个文件夹的内容 第三部:在myeclipse中新建一个web project ...
- 史上最全的LaTeX特殊符号语法
史上最全的LaTeX特殊符号语法 运算符 语法 效果 语法 效果 语法 效果 + \(+\) - \(-\) \triangleleft \(\triangleleft\) \pm \(\pm\) \ ...
- 使用Python对ElasticSearch获取数据及操作
#!/usr/bin/env python# -*- coding: utf-8 -*-""" @Time : 2018/7/4 @Author : LiuXueWen ...
- Spring Security OAuth2学习
什么是 oAuth oAuth 协议为用户资源的授权提供了一个安全的.开放而又简易的标准.与以往的授权方式不同之处是 oAuth 的授权不会使第三方触及到用户的帐号信息(如用户名与密码),即第三方无需 ...
- 当usbnet打印 kevent * may have been dropped(转)
http://patchwork.ozlabs.org/patch/815639/ Every once in a while when my system is under a bit of str ...
- mysql增加索引、删除索引、查看索引
添加索引 有四种方式来添加数据表的索引: 1.添加一个主键,这意味着索引值必须是唯一的,且不能为NULL ALTER TABLE tbl_name ADD PRIMARY KEY (column_li ...
- 查看xml源码的方法
查看xml源码的方法 要通过查看源码才能看到xml源码 因为 print_r输出的时候 默认页面打开是html编码的...... 所以解析不了xml
- Python保存json文件并格式化
使用json.dump()的时候设置一下indent参数的值就好了.比如json.dump(json_dict, f, indent=4), ensure_ascii=False,写入中文
- Win10+Anaconda+tensorflow-cpu安装教程
基础概念 Python2.x or Python3.x 自从20世纪90年代初Python语言诞生至今,一直在迭代更新,根据出现的时期,可以分为Python2.x和Python3.x两个大版本.其中P ...
- F#周报2019年第22期
新闻 2019年实用F#挑战结果 FSharp.Formatting正在确定维护者 实用F#挑战的赢家们 使用F#在分布式系统中进行故障检测与共识 F#里的Cloudflare Worker Juni ...