Hadoop+Hbase+Zookeeper分布式存储构建
目录:
Hadoop+Hbase+zookeeper分布式存储构建
前言* Hadoop是Apache开源组织的一个分布式计算开源框架,在很多大型网站上都已经得到了应用,如亚马逊、Facebook和Yahoo等等。对于我来说,最近的一个使用点就是服务集成平台的日志分析。服务集成平台的日志量将会很大,而这也正好符合了分布式计算的适用场景(日志分析和索引建立就是两大应用场景)。
今天我们来实际搭建一下Hadoop 2.2.0版,实战环境为目前主流服务器操作系统CentOS 6.5系统。
一、实战环境
系统版本:CentOS 6.5 x86_64
JAVA版本:JDK-1.7.0_25
Hadoop版本:hadoop-2.2.0
192.168.172.59 namenode (充当namenode、secondary namenode和ResourceManager角色)
192.168.172.88 datanode1 (充当datanode、nodemanager角色)
192.168.172.89 datanode2 (充当datanode、nodemanager角色)
二、软件准备
1、Hadoop可以从Apache官方网站直接下载最新版本Hadoop2.2。官方目前是提供了linux32位系统可执行文件,所以如果需要在64位系统上部署则需要单独下载src 源码自行编译。(如果是真实线上环境,请下载64位hadoop版本,这样可以避免很多问题,这里我实验采用的是32位版本)
Hadoop下载地址
http://apache.claz.org/hadoop/common/hadoop-2.2.0/
Java 下载下载
http://www.oracle.com/technetwork/java/javase/downloads/index.html
2、我们这里采用三台CnetOS服务器来搭建Hadoop集群,分别的角色如上已经注明。
第一步:我们需要在三台服务器的/etc/hosts里面设置对应的主机名如下(真实环境可以使用内网DNS解析)
[root@node1 hadoop]# cat /etc/hosts
# Do not remove the following line, or various programs
# that require network functionality will fail.
127.0.0.1 localhost.localdomain localhost
192.168.172.59 node1
192.168.172.88 node2
192.168.172.89 node3
(注* 我们需要在namenode、datanode三台服务器上都配置hosts解析)
第二步:从namenode上无密码登陆各台datanode服务器,需要做如下配置:
在namenode 128上执行ssh-keygen,一路Enter回车即可。
然后把公钥/root/.ssh/id_rsa.pub拷贝到datanode服务器即可,拷贝方法如下:
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.172.88
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.172.89
三、Java安装配置
tar -xvzf jdk-7u25-linux-x64.tar.gz &&mkdir -p /usr/java/ ; mv /jdk1.7.0_25 /usr/java/ 即可。
安装完毕并配置java环境变量,在/etc/profile末尾添加如下代码:
export JAVA_HOME=/usr/java/jdk1.7.0_25/
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=$JAVE_HOME/lib/dt.jar:$JAVE_HOME/lib/tools.jar:./
保存退出即可,然后执行source /etc/profile 生效。在命令行执行java -version 如下代表JAVA安装成功。
[root@node1 ~]# java -version
java version "1.7.0_25"
Java(TM) SE Runtime Environment (build 1.7.0_25-b15)
Java HotSpot(TM) 64-Bit Server VM (build 23.25-b01, mixed mode)
(注* 我们需要在namenode、datanode三台服务器上都安装Java JDK版本)
- Hadoop版本安装
官方下载的hadoop2.2.0版本,不用编译直接解压安装就可以使用了,如下:
第一步解压:
tar -xzvf hadoop-2.2.0.tar.gz &&mv hadoop-2.2.0 /data/hadoop/
(注* 先在namenode服务器上都安装hadoop版本即可,datanode先不用安装,待会修改完配置后统一安装datanode)
第二步配置变量:
在/etc/profile末尾继续添加如下代码,并执行source /etc/profile生效。
export HADOOP_HOME=/data/hadoop/
export PATH=$PATH:$HADOOP_HOME/bin/
export JAVA_LIBRARY_PATH=/data/hadoop/lib/native/
(注* 我们需要在namenode、datanode三台服务器上都配置Hadoop相关变量)
五、配置Hadoop
在namenode上配置,我们需要修改如下几个地方:
1、修改vi /data/hadoop/etc/hadoop/core-site.xml 内容为如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-${user.name}</value>
<description>A base for other temporary directories.</description>
</property>
</configuration>
2、修改vi /data/hadoop/etc/hadoop/mapred-site.xml内容为如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>node1:9001</value>
</property>
</configuration>
3、修改vi /data/hadoop/etc/hadoop/hdfs-site.xml内容为如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/data/hadoop/data_name1,/data/hadoop/data_name2</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/data/hadoop/data_1,/data/hadoop/data_2</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
4、在/data/hadoop/etc/hadoop/hadoop-env.sh文件末尾追加JAV_HOME变量:
echo "export JAVA_HOME=/usr/java/jdk1.7.0_25/" >> /data/hadoop/etc/hadoop/hadoop-env.sh
5、修改 vi /data/hadoop/etc/hadoop/masters文件内容为如下:
node1
6、修改vi /data/hadoop/etc/hadoop/slaves文件内容为如下:
node2
node3
如上配置完毕,以上的配置具体含义在这里就不做过多的解释了,搭建的时候不明白,可以查看一下相关的官方文档。
如上namenode就基本搭建完毕,接下来我们需要部署datanode,部署datanode相对简单,执行如下操作即可。
for i in `seq 88 89 ` ; do scp -r /data/hadoop/ root@192.168.172.$i:/data/ ; done
自此整个集群基本搭建完毕,接下来就是启动hadoop集群了。
六、启动hadoop并测试
在启动hadoop之前,我们需要做一步非常关键的步骤,需要在namenode上执行如下命令初始化name目录和数据目录。
cd /data/hadoop/ ; ./bin/hadoop namenode -format
那如何算初始化成功呢,如下截图成功创建name目录即正常:

然后启动hadoop所有服务,如下命令:
[root@node1 hadoop]# ./sbin/start-all.sh

我们还可以查看相应的端口是否启动:netstat -ntpl
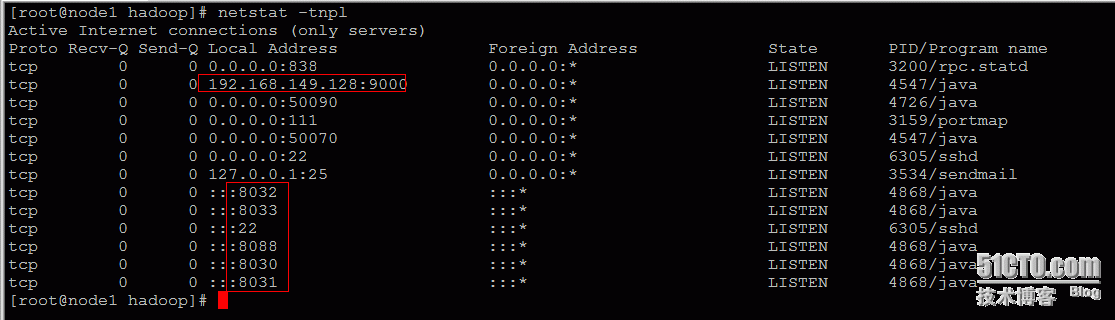
访问如下地址:http://192.168.172.59:50070/
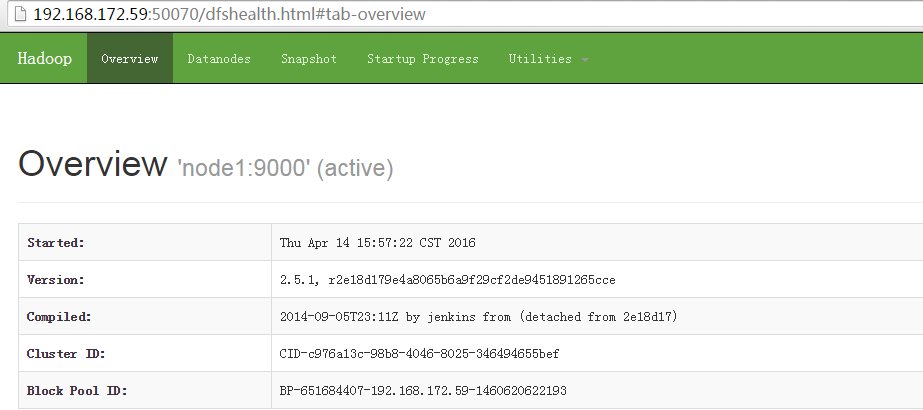
访问地址:http://192.168.172.59:8088/
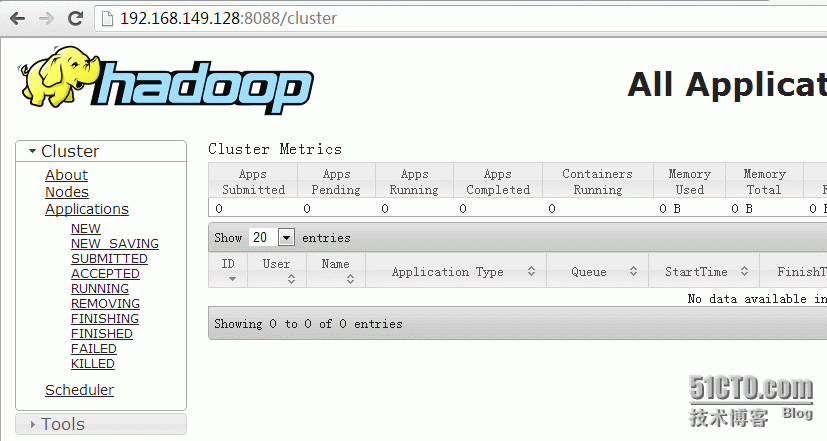
搭建完成后,我们简单的实际操作一下,如下图:

自此hadoop基本搭建完毕,
部署zookeeper:
在node1上配置:
下载zookeeper3.4.6版本:
wget http://apache.fayea.com/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz
tar -xzf zookeeper-3.4.6.tar.gz -C /export/servers/
#vim /export/servers/ zookeeper-3.4.6/conf/zoo.cfg写入如下内容:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
dataDir=/export/zookeeper
# the port at which the clients will connect
clientPort=2181
initLimit=5
syncLimit=2
dataLogDir=/export/zookeeper/logs
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
注意:zk里面的node节点名称要一一对应哦,然后创建zk数据目录和日志路径:
mkdir -p /export/zookeeper/logs
echo 1 >/export/zookeeper/myid
如上在node1上配置好zk后,把zk整个程序同步到另外两台node2、node3。
执行如下脚本:
for i in `seq 88 89` ; do rsync -aP --delete /export/servers/zookeeper-3.4.6/ root@192.168.172.$i:/export/servers/zookeeper-3.4.6/ ;rsync -av /export/zookeeper/ root@192.168.172.$i:/export/; done
然后分别修改node2、node3的myid为2和3,命令如下:
在node2上执行:
echo 2 >/export/zookeeper/myid
在node3上执行:
echo 3 >/export/zookeeper/myid
执行完后,分别启动三台服务器的zk服务:
cd /export/servers/zookeeper-3.4.6/ ;./bin/zkServer.sh start

如上配置,zookeeper配置完毕,
配置hbase:
在node1上配置:
下载软件:hbase-0.96.2-hadoop2.tar.gz,然后执行如下命令:
tar xf hbase-0.96.2-hadoop2.tar.gz ;mv hbase-0.96.2-hadoop2 /export/hbase
然后进入hbase配置文件目录,如下图:
cd /export/hbase/conf/
Vim hbase-site.xml内容如下:
<configuration>
<property>
<name>hbase.tmp.dir</name>
<value>/export/hbase/tmp</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>3600000</value>
</property>
<property>
<name>hbase.zookeeper.property.tickTime</name>
<value>180000</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://node1:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node1,node2,node3</value>
</property>
<!--禁止magor compaction-->
<property>
<name>hbase.hregion.majorcompaction</name>
<value>0</value>
</property>
<!--禁止split-->
<property>
<name>hbase.hregion.max.filesize</name>
<value>536870912000</value>
</property>
<!---->
<property>
<name>hbase.hstore.blockingStoreFiles</name>
<value>2100000000</value>
</property>
<property>
<name>hbase.regionserver.handler.count</name>
<value>100</value>
</property>
</configuration>
vim hbase-env.sh内容如下:
export JAVA_HOME=/export/servers/jdk1.6.0_25/
export HBASE_OPTS="-XX:+UseConcMarkSweepGC"
export HBASE_MANAGES_ZK=false
export HADOOP_HOME=/export/hadoop/
vim regionservers内容如下:
node2
node3
然后将node1 habse配置同步至node2、node3:
for i in `seq 88 89` ; do rsync -av /export/hbase/ root@192.168.172.$i:/export/ ; done
最好在node1启动整个集群hbase即可:
cd /export/hbase/;sh bin/start-hbase.sh
查看node1 JAVA进程信息如下:
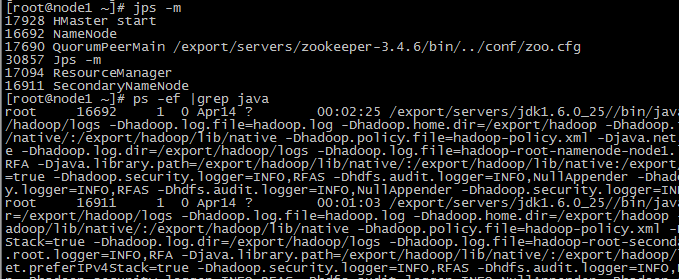
最好查看hbase日志如下:

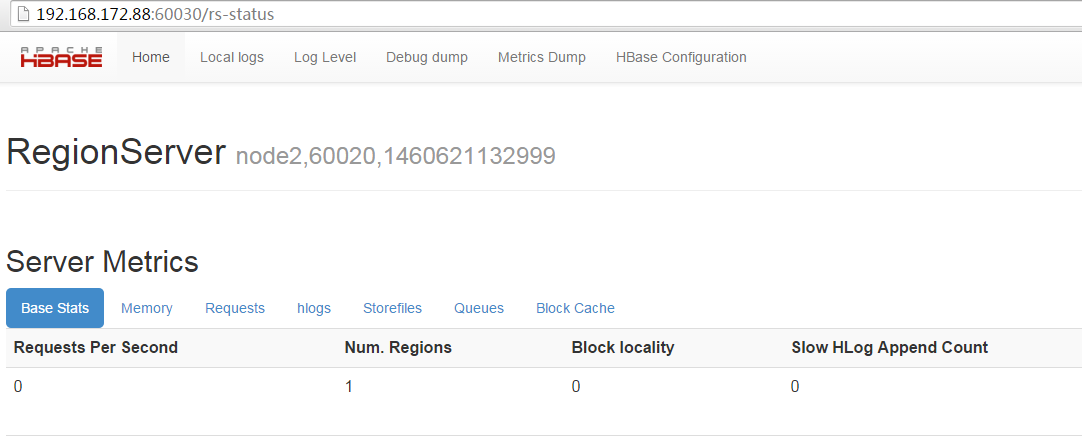
通过web查看hbase截图如下:

NODE2状态:
---------------------------------------------------------------------------
Hadoop+Hbase+Zookeeper分布式存储构建的更多相关文章
- [推荐]Hadoop+HBase+Zookeeper集群的配置
[推荐]Hadoop+HBase+Zookeeper集群的配置 Hadoop+HBase+Zookeeper集群的配置 http://wenku.baidu.com/view/991258e881c ...
- Hadoop,HBase,Zookeeper源码编译并导入eclipse
基本理念:尽可能的参考官方英文文档 Hadoop: http://wiki.apache.org/hadoop/FrontPage HBase: http://hbase.apache.org/b ...
- CentOS7搭建 Hadoop + HBase + Zookeeper集群
摘要: 本文主要介绍搭建Hadoop.HBase.Zookeeper集群环境的搭建 一.基础环境准备 1.下载安装包(均使用当前最新的稳定版本,截止至2017年05月24日) 1)jdk-8u131 ...
- Hadoop+HBase+ZooKeeper分布式集群环境搭建
一.环境说明 集群环境至少需要3个节点(也就是3台服务器设备):1个Master,2个Slave,节点之间局域网连接,可以相互ping通,下面举例说明,配置节点IP分配如下: Hostname IP ...
- prometheus 监控 hadoop + Hbase + zookeeper
1. run JMX exporter as a java agent with all the four daemons. For this I have added EXTRA_JAVA_OPTS ...
- hbase报错Could not initialize class org.apache.hadoop.hbase.protobuf.ProtobufUtil
Caused by: java.lang.RuntimeException: java.io.IOException: java.lang.reflect.InvocationTargetExcept ...
- org.apache.hadoop.hbase.master.HMasterCommandLine: Master exiting java.lang.RuntimeException: HMaster Aborted
前一篇的问题解决了,是 hbase 下面lib 包的jar问题,之前写MR的时候加错了包,替换掉了原来的包后出现另一问题:@ubuntu:/home/hadoop/hbase-0.94.6-cdh4. ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- HADOOP+SPARK+ZOOKEEPER+HBASE+HIVE集群搭建(转)
原文地址:https://www.cnblogs.com/hanzhi/articles/8794984.html 目录 引言 目录 一环境选择 1集群机器安装图 2配置说明 3下载地址 二集群的相关 ...
随机推荐
- Alpha冲刺(9/10)——2019.5.2
所属课程 软件工程1916|W(福州大学) 作业要求 Alpha冲刺(9/10)--2019.5.2 团队名称 待就业六人组 1.团队信息 团队名称:待就业六人组 团队描述:同舟共济扬帆起,乘风破浪万 ...
- webview-h5页面刷新
问题:webview 缓存了index.html页面:浏览器缓存了子页面.解决方案:网页链接后添加时间戳. 第一:避免webView缓存]在service.vue中,给url后边添加时间戳 第二:避免 ...
- May Cook-Off 2019 解题报告
太气了.Atcoder unrated了. 这一场时间太不友好了.昨天下午一时兴起就去补了一发.题很好,学到好多东西. Chain Reaction 题意:给一个矩阵,这个矩阵是稳定的当且仅当每一个元 ...
- Goexit
package main import ( "fmt" "runtime" ) func test() { defer fmt.Println("cc ...
- WinDbg常用命令系列---显示加载的模块列表lm
lm (List Loaded Modules) lm命令显示指定的加载模块.输出包括模块的状态和路径. lmOptions [a Address] [m Pattern | M Pattern] 参 ...
- 关于dword ptr 指令
dword 双字 就是四个字节ptr pointer缩写 即指针[]里的数据是一个地址值,这个地址指向一个双字型数据比如mov eax, dword ptr [12345678] 把内存地址12345 ...
- vigil rpm 包制作
vigil 可以方便的进行服务的监控,以下尝试制作一个rpm 包,方便使用 安装依赖 ruby yum -y install ruby rubygems ruby-devel 修改gem 源 可选, ...
- (15)Go错误处理
1.erro(一般错误) package main import ( "errors" "fmt" ) func div(a, b int) (res int) ...
- Spark-Streaming kafka count 案例
Streaming 统计来自 kafka 的数据,这里涉及到的比较,kafka 的数据是使用从 flume 获取到的,这里相当于一个小的案例. 1. 启动 kafka Spark-Streaming ...
- go 牛顿法开平方
func main() { fmt.Println(sqrt(3)) } func sqrt(x float64)float64{ z := x for i := 0; i < 10 ; i++ ...