Spark RDD :Spark API--图解Spark API
面试题引出:
简述Spark的宽窄依赖,以及Spark如何划分stage,每个stage又根据什么决定task个数?
Stage:根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage。
Task:Stage是一个TaskSet,将Stage根据分区数划分成一个个的Task。
请列举Spark的transformation算子(不少于8个),并简述功能
1)map(func):返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成.
2)mapPartitions(func):类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RD上运行时,func的函数类型必须是Iterator[T] => Iterator[U]。假设有N个元素,有M个分区,那么map的函数的将被调用N次,而mapPartitions被调用M次,一个函数一次处理所有分区。
3)reduceByKey(func,[numTask]):在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用定的reduce函数,将相同key的值聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置。
4)aggregateByKey (zeroValue:U,[partitioner: Partitioner]) (seqOp: (U, V) => U,combOp: (U, U) => U: 在kv对的RDD中,,按key将value进行分组合并,合并时,将每个value和初始值作为seq函数的参数,进行计算,返回的结果作为一个新的kv对,然后再将结果按照key进行合并,最后将每个分组的value传递给combine函数进行计算(先将前两个value进行计算,将返回结果和下一个value传给combine函数,以此类推),将key与计算结果作为一个新的kv对输出。
5)combineByKey(createCombiner: V=>C, mergeValue: (C, V) =>C, mergeCombiners: (C, C) =>C):
对相同K,把V合并成一个集合。
1.createCombiner: combineByKey() 会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的某个元素的键相同。如果这是一个新的元素,combineByKey()会使用一个叫作createCombiner()的函数来创建那个键对应的累加器的初始值
2.mergeValue: 如果这是一个在处理当前分区之前已经遇到的键,它会使用mergeValue()方法将该键的累加器对应的当前值与这个新的值进行合并
3.mergeCombiners: 由于每个分区都是独立处理的, 因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器, 就需要使用用户提供的 mergeCombiners() 方法将各个分区的结果进行合并。
…
根据自身情况选择比较熟悉的算子加以介绍。
4.10.8 请列举Spark的action算子(不少于6个),并简述功能
1)reduce:
2)collect:
3)first:
4)take:
5)aggregate:
6)countByKey:
7)foreach:
8)saveAsTextFile:
4.10.9 请列举会引起Shuffle过程的Spark算子,并简述功能。
reduceBykey:
groupByKey:
…ByKey:
初识spark,需要对其API有熟悉的了解才能方便开发上层应用。本文用图形的方式直观表达相关API的工作特点,并提供了解新的API接口使用的方法。例子代码全部使用python实现。
1. 数据源准备
准备输入文件:
$ cat /tmp/in
apple
bag bag
cat cat cat启动pyspark:
$ ./spark/bin/pyspark使用textFile创建RDD:
>>> txt = sc.textFile("file:///tmp/in", 2)查看RDD分区与数据:
>>> txt.glom().collect()
[[u'apple', u'bag bag'], [u'cat cat cat']]2. transformation
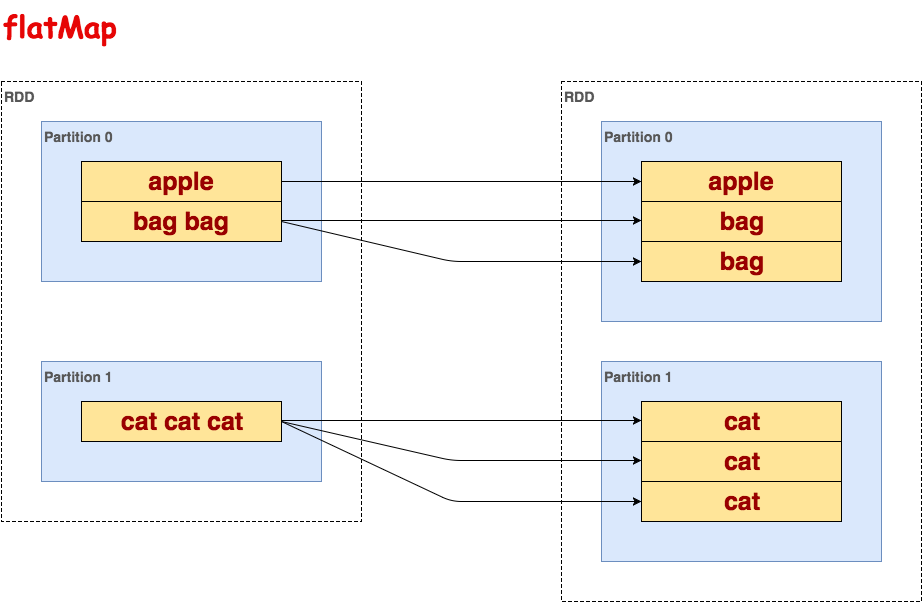
flatMap
处理RDD的每一行,一对多映射。
代码示例:
>>> txt.flatMap(lambda line: line.split()).collect()
[u'apple', u'bag', u'bag', u'cat', u'cat', u'cat']示意图:
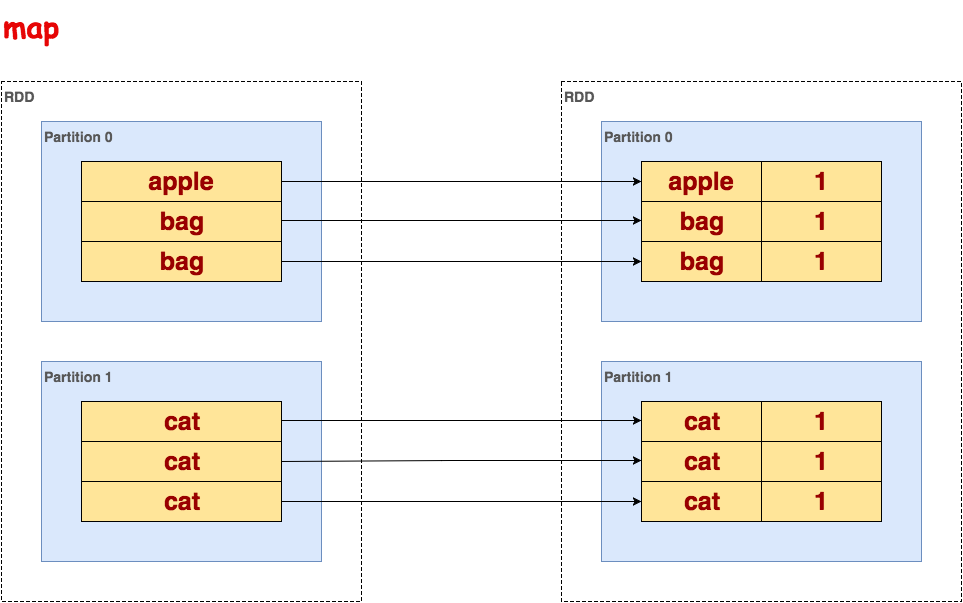
map
处理RDD的每一行,一对一映射。
代码示例:
>>> txt.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).collect()
[(u'apple', 1), (u'bag', 1), (u'bag', 1), (u'cat', 1), (u'cat', 1), (u'cat', 1)]示意图:
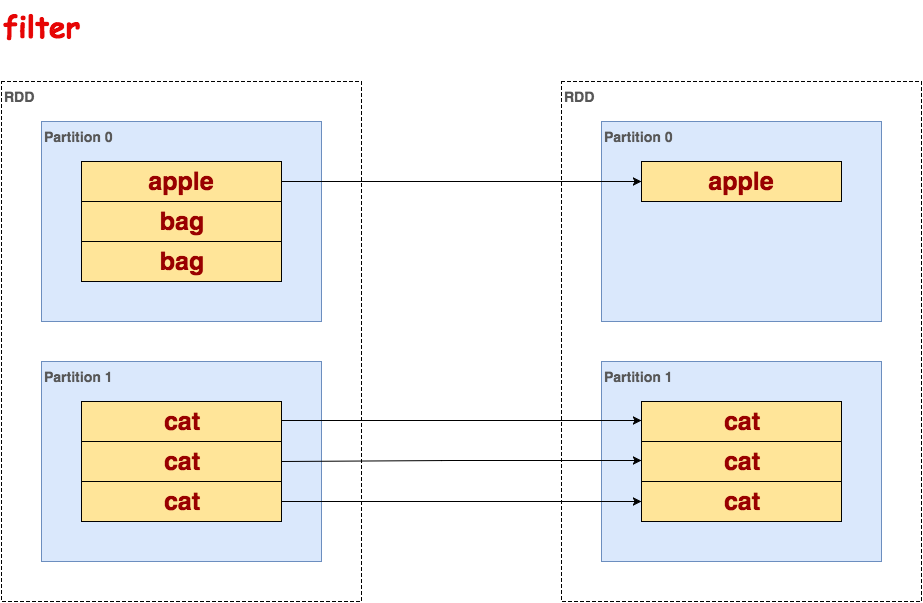
filter
处理RDD的每一行,过滤掉不满足条件的行。
代码示例:
>>> txt.flatMap(lambda line: line.split()).filter(lambda word: word !='bag').collect()
[u'apple', u'cat', u'cat', u'cat']
mapPartitions
逐个处理每一个partition,使用迭代器it访问每个partition的行。
代码示例:
>>> txt.flatMap(lambda line: line.split()).mapPartitions(lambda it: [len(list(it))]).collect()
[3, 3]示意图:

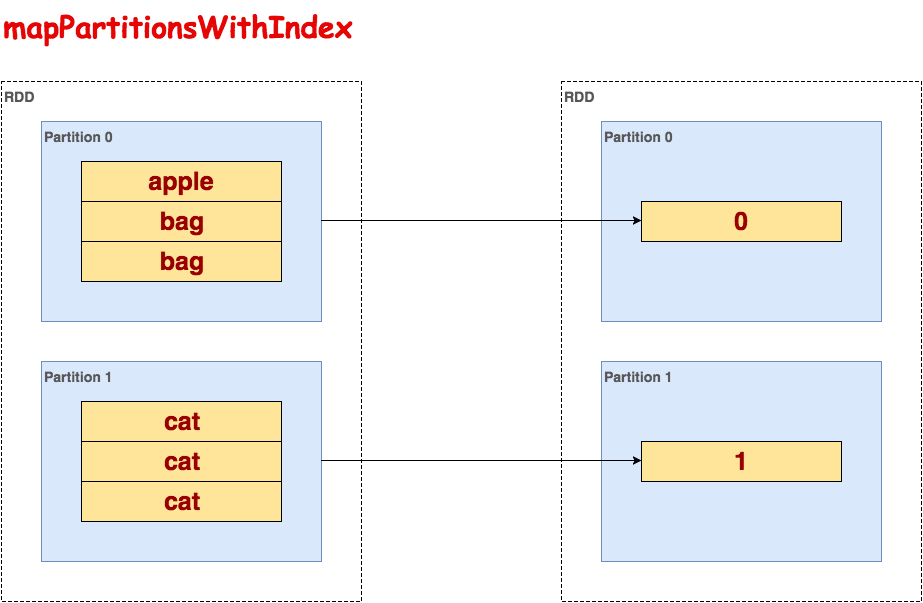
mapPartitionsWithIndex
逐个处理每一个partition,使用迭代器it访问每个partition的行,index保存partition的索引,等价于mapPartitionsWithSplit(过期函数)。
代码示例:
>>> txt.flatMap(lambda line: line.split()).mapPartitionsWithIndex(lambda index, it: [index]).collect()
[0, 1]示意图:
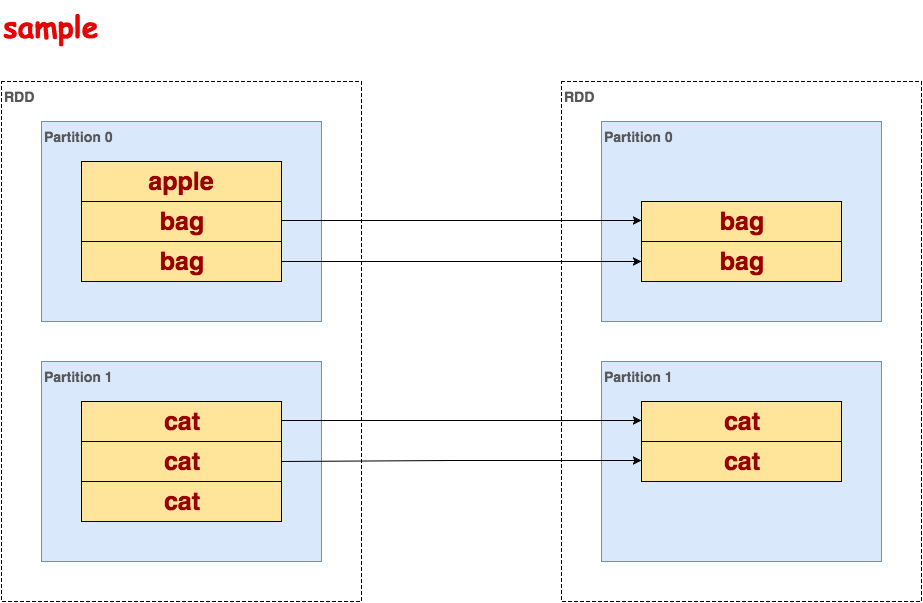
sample
根据采样因子指定的比例,对数据进行采样,可以选择是否用随机数进行替换,seed用于指定随机数生成器种子。第一个参数表示是否放回抽样,第二个参数表示抽样比例,第三个参数表示随机数seed。
代码示例:
>>> txt.flatMap(lambda line: line.split()).sample(False, 0.5, 5).collect()
[u'bag', u'bag', u'cat', u'cat']示意图:
union
合并RDD,不去重。
代码示例:
>>> txt.union(txt).collect()
[u'apple', u'bag bag', u'cat cat cat', u'apple', u'bag bag', u'cat cat cat']示意图:

distinct
对RDD去重。
代码示例:
>>> txt.flatMap(lambda line: line.split()).distinct().collect()
[u'bag', u'apple', u'cat']示意图:

groupByKey
在一个(K,V)对的数据集上调用,返回一个(K,Seq[V])对的数据集。
代码示例:
>>> txt.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).groupByKey().collect()
[(u'bag', <pyspark.resultiterable.ResultIterable object at 0x128a150>), (u'apple', <pyspark.resultiterable.ResultIterable object at 0x128a550>), (u'cat', <pyspark.resultiterable.ResultIterable object at 0x13234d0>)]
>>> txt.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).groupByKey().collect()[0][1].data
[1, 1]示意图:

reduceByKey
在一个(K,V)对的数据集上调用时,返回一个(K,V)对的数据集,使用指定的reduce函数,将相同key的值聚合到一起。
代码示例:
>>> txt.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b).collect()
[(u'bag', 2), (u'apple', 1), (u'cat', 3)]示意图:

aggregateByKey
自定义聚合函数,类似groupByKey。在一个(K,V)对的数据集上调用,不过可以返回一个(K,Seq[U])对的数据集。
代码示例(实现groupByKey的功能):
>>> txt.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).aggregateByKey([], lambda seq, elem: seq + [elem], lambda a, b: a + b).collect()
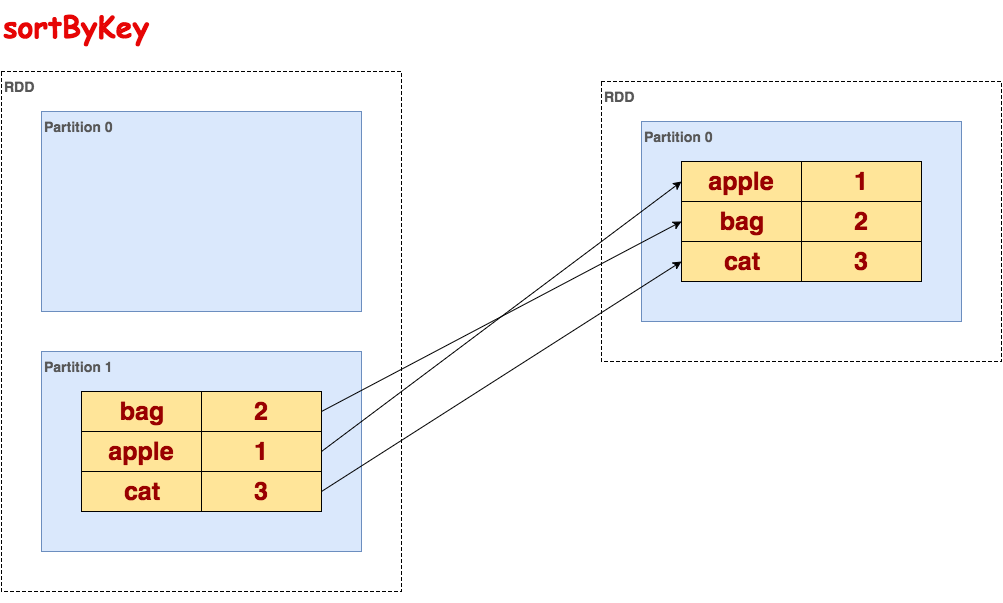
[(u'bag', [1, 1]), (u'apple', [1]), (u'cat', [1, 1, 1])]sortByKey
在一个(K,V)对的数据集上调用,K必须实现Ordered接口,返回一个按照Key进行排序的(K,V)对数据集。升序或降序由ascending布尔参数决定。
代码示例:
>>> txt.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b).sortByKey().collect()
[(u'apple', 1), (u'bag', 2), (u'cat', 3)]示意图:
join
在类型为(K,V)和(K,W)类型的数据集上调用时,返回一个相同key对应的所有元素对在一起的(K, (V, W))数据集。
代码示例:
>>> sorted_txt = txt.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b).sortByKey()
>>> sorted_txt.join(sorted_txt).collect()
[(u'bag', (2, 2)), (u'apple', (1, 1)), (u'cat', (3, 3))]示意图:

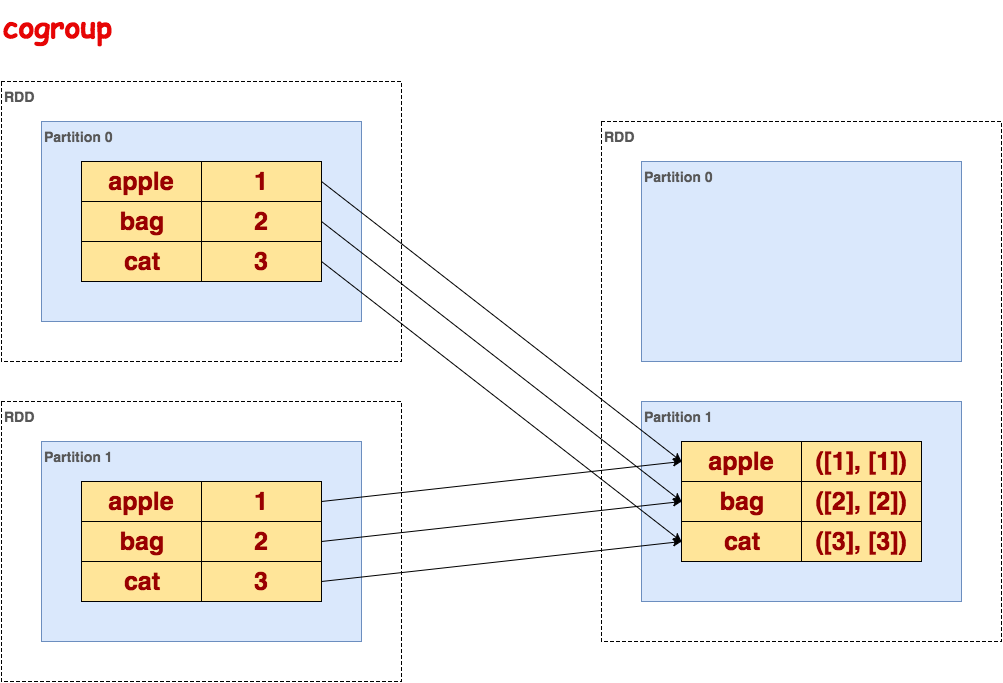
cogroup
在类型为(K,V)和(K,W)的数据集上调用,返回一个 (K, (Seq[V], Seq[W]))元组的数据集。这个操作也可以称之为groupwith。
代码示例:
>>> sorted_txt = txt.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b).sortByKey()
>>> sorted_txt.cogroup(sorted_txt).collect()
[(u'bag', (<pyspark.resultiterable.ResultIterable object at 0x1323790>, <pyspark.resultiterable.ResultIterable object at 0x1323310>)), (u'apple', (<pyspark.resultiterable.ResultIterable object at 0x1323990>, <pyspark.resultiterable.ResultIterable object at 0x1323ad0>)), (u'cat', (<pyspark.resultiterable.ResultIterable object at 0x1323110>, <pyspark.resultiterable.ResultIterable object at 0x13230d0>))]
>>> sorted_txt.cogroup(sorted_txt).collect()[0][1][0].data
[2]示意图:
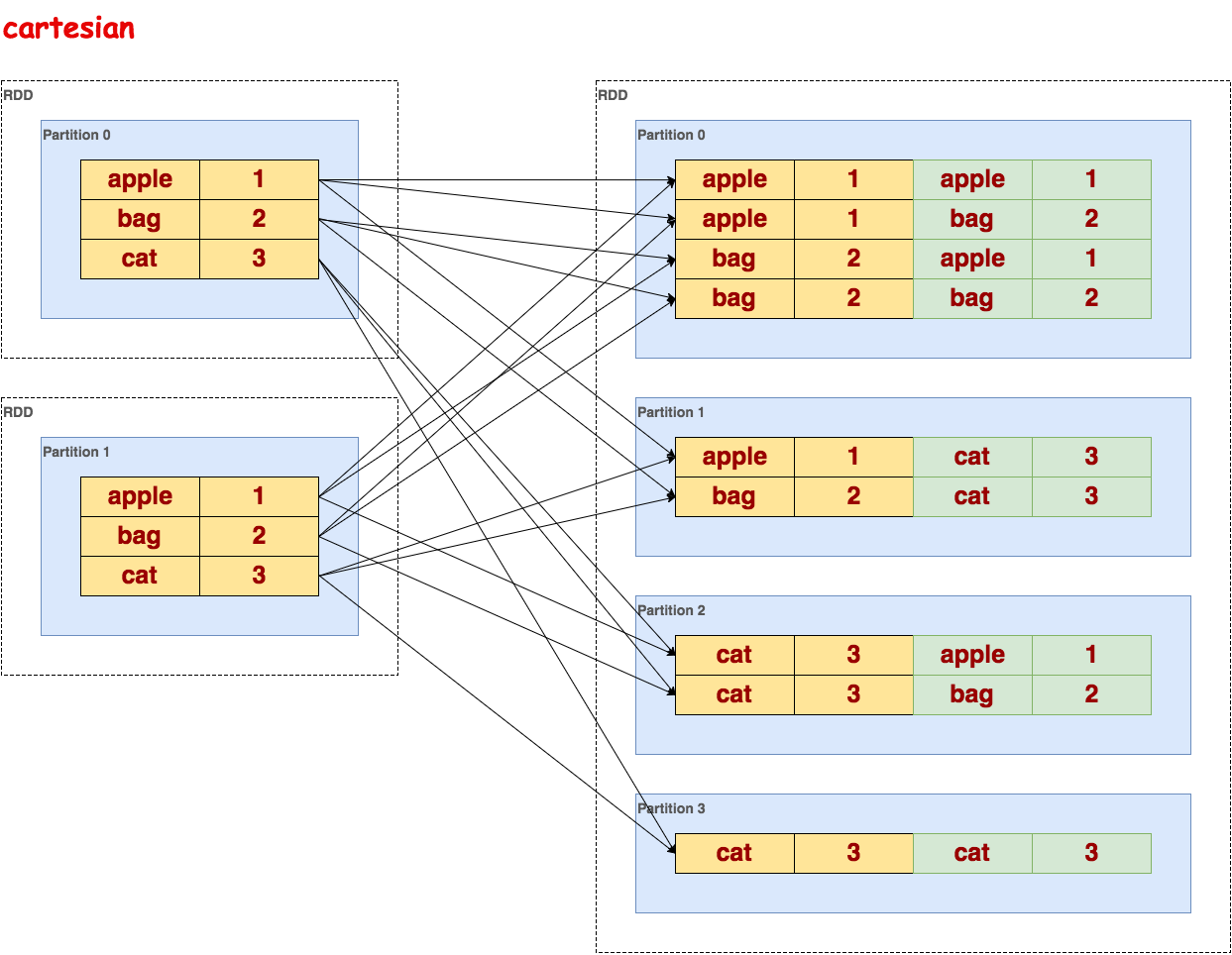
cartesian
笛卡尔积,在类型为 T 和 U 类型的数据集上调用时,返回一个 (T, U)对数据集(两两的元素对)。
代码示例:
>>> sorted_txt = txt.flatMap(lambda line: line.split()).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b).sortByKey()
>>> sorted_txt.cogroup(sorted_txt).collect()
[(u'bag', (<pyspark.resultiterable.ResultIterable object at 0x1323790>, <pyspark.resultiterable.ResultIterable object at 0x1323310>)), (u'apple', (<pyspark.resultiterable.ResultIterable object at 0x1323990>, <pyspark.resultiterable.ResultIterable object at 0x1323ad0>)), (u'cat', (<pyspark.resultiterable.ResultIterable object at 0x1323110>, <pyspark.resultiterable.ResultIterable object at 0x13230d0>))]
>>> sorted_txt.cogroup(sorted_txt).collect()[0][1][0].data
[2]示意图:
pipe
处理RDD的每一行作为shell命令输入,shell命令结果为输出。
代码示例:
>>> txt.pipe("awk '{print $1}'").collect()
[u'apple', u'bag', u'cat']示意图:

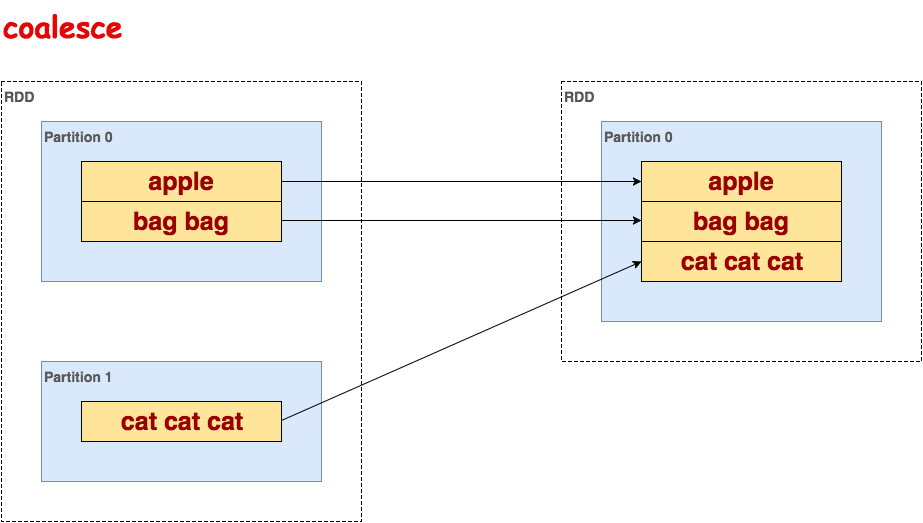
coalesce
减少RDD分区数。
代码示例:
>>> txt.coalesce(1).collect()
[u'apple', u'bag bag', u'cat cat cat']示意图:
repartition
对RDD重新分区,类似于coalesce。
代码示例:
>>> txt.repartition(1).collect()
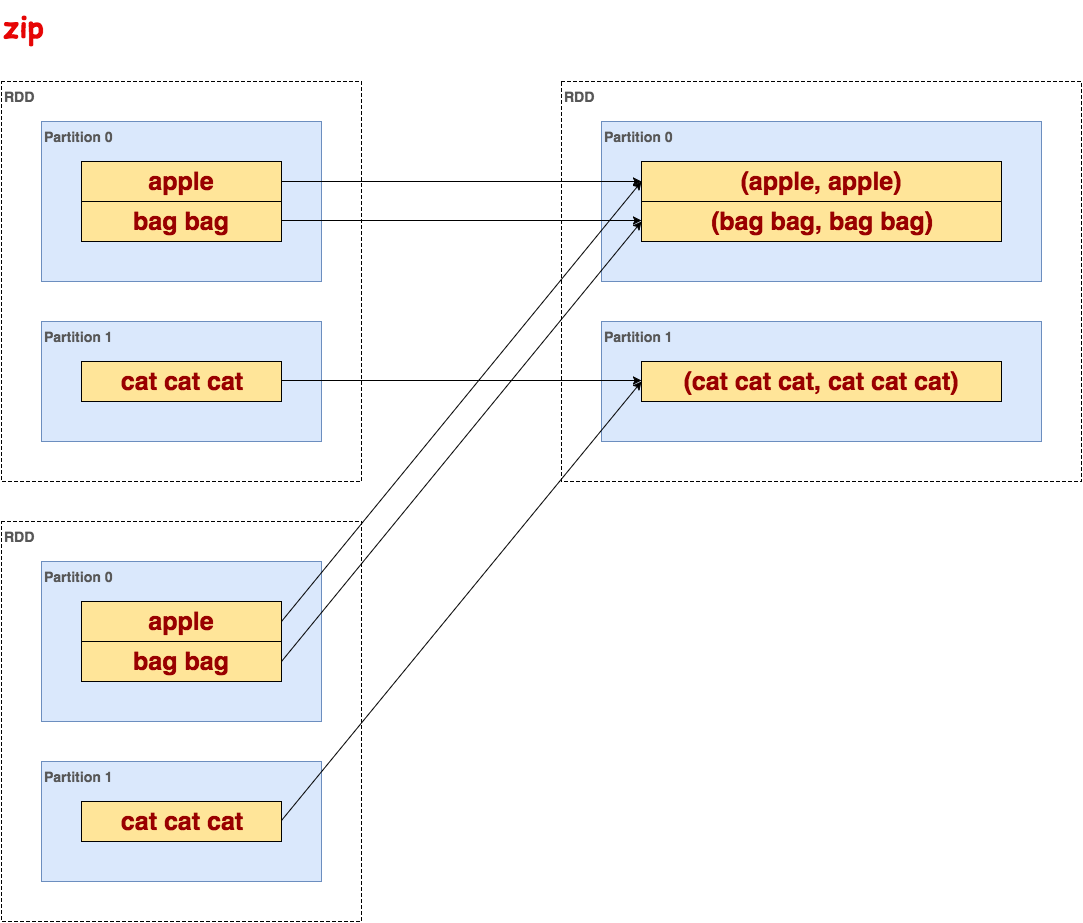
[u'apple', u'bag bag', u'cat cat cat']zip
合并两个RDD序列为元组,要求序列长度相等。
代码示例:
>>> txt.zip(txt).collect()
[(u'apple', u'apple'), (u'bag bag', u'bag bag'), (u'cat cat cat', u'cat cat cat')]示意图:
3. action
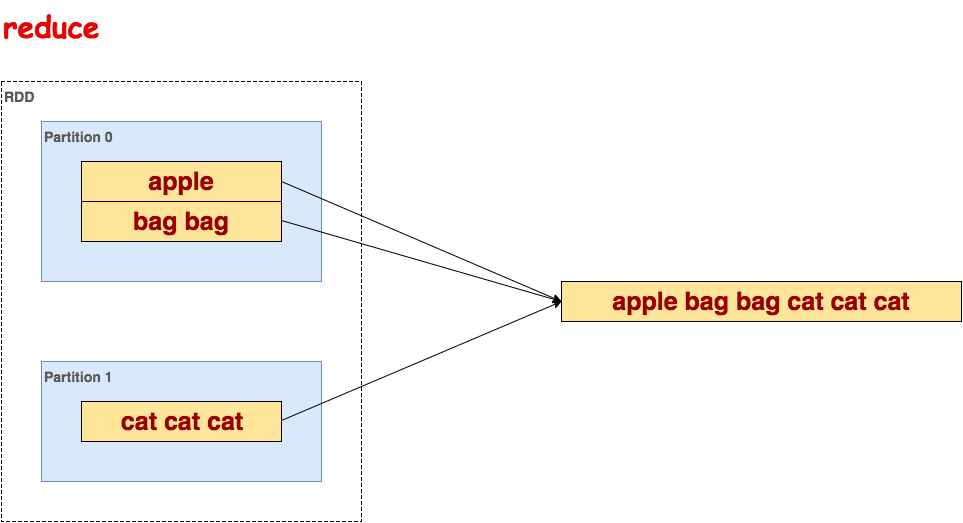
reduce
聚集数据集中的所有元素。
代码示例:
>>> txt.reduce(lambda a, b: a + " " + b)
u'apple bag bag cat cat cat'示意图:
collect
以数组的形式,返回数据集的所有元素。
代码示例:
>>> txt.collect()
[u'apple', u'bag bag', u'cat cat cat']count
返回数据集的元素的个数。
代码示例:
>>> txt.count()
3first
返回数据集第一个元素。
代码示例:
>>> txt.first()
u'apple'take
返回数据集前n个元素。
代码示例:
>>> txt.take(2)
[u'apple', u'bag bag']takeSample
采样返回数据集前n个元素。第一个参数表示是否放回抽样,第二个参数表示抽样个数,第三个参数表示随机数seed。
代码示例:
>>> txt.takeSample(False, 2, 1)
[u'cat cat cat', u'bag bag']takeOrdered
排序返回前n个元素。
代码示例:
>>> txt.takeOrdered(2)
[u'apple', u'bag bag']saveAsTextFile
将数据集的元素,以textfile的形式,保存到本地文件系统,HDFS或者任何其它hadoop支持的文件系统。
代码示例:
>>> txt.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b).saveAsTextFile("file:///tmp/out")查看输出文件:
$cat /tmp/out/part-00001
(u'bag', 2)
(u'apple', 1)
(u'cat', 3)saveAsSequenceFile
将数据集的元素,以Hadoop sequencefile的格式,保存到指定的目录下,本地系统,HDFS或者任何其它hadoop支持的文件系统。这个只限于由key-value对组成,并实现了Hadoop的Writable接口,或者隐式的可以转换为Writable的RDD。
countByKey
对(K,V)类型的RDD有效,返回一个(K,Int)对的Map,表示每一个key对应的元素个数。
代码示例:
>>> txt.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).countByKey()
defaultdict(<type 'int'>, {u'bag': 2, u'apple': 1, u'cat': 3})foreach
在数据集的每一个元素上,运行函数func进行更新。这通常用于边缘效果,例如更新一个累加器,或者和外部存储系统进行交互。
代码示例:
>>> def func(line): print line
>>> txt.foreach(lambda line: func(line))
apple
bag bag
cat cat catSpark RDD :Spark API--图解Spark API的更多相关文章
- Spark RDD概念学习系列之Spark Hash Shuffle内幕彻底解密(二十)
本博文的主要内容: 1.Hash Shuffle彻底解密 2.Shuffle Pluggable解密 3.Sorted Shuffle解密 4.Shuffle性能优化 一:到底什么是Shuffle? ...
- Spark RDD概念学习系列之Spark的算子的分类(十一)
Spark的算子的分类 从大方向来说,Spark 算子大致可以分为以下两类: 1)Transformation 变换/转换算子:这种变换并不触发提交作业,完成作业中间过程处理. Transformat ...
- Spark RDD概念学习系列之Spark的数据存储(十二)
Spark数据存储的核心是弹性分布式数据集(RDD). RDD可以被抽象地理解为一个大的数组(Array),但是这个数组是分布在集群上的. 逻辑上RDD的每个分区叫一个Partition. 在Spar ...
- Spark RDD概念学习系列之Spark的算子的作用(十四)
Spark的算子的作用 首先,关于spark算子的分类,详细见 http://www.cnblogs.com/zlslch/p/5723857.html 1.Transformation 变换/转换算 ...
- Apache Spark : RDD
Resilient Distributed Datasets Resilient Distributed Datasets (RDD) is a fundamental data structure ...
- Spark RDD API详解(一) Map和Reduce
RDD是什么? RDD是Spark中的抽象数据结构类型,任何数据在Spark中都被表示为RDD.从编程的角度来看,RDD可以简单看成是一个数组.和普通数组的区别是,RDD中的数据是分区存储的,这样不同 ...
- Spark RDD API具体解释(一) Map和Reduce
本文由cmd markdown编辑.原始链接:https://www.zybuluo.com/jewes/note/35032 RDD是什么? RDD是Spark中的抽象数据结构类型,不论什么数据在S ...
- spark 中的RDD编程 -以下基于Java api
1.RDD介绍: RDD,弹性分布式数据集,即分布式的元素集合.在spark中,对所有数据的操作不外乎是创建RDD.转化已有的RDD以及调用RDD操作进行求值.在这一切的背后,Spark会自动 ...
- Spark RDD API扩展开发
原文链接: Spark RDD API扩展开发(1) Spark RDD API扩展开发(2):自定义RDD 我们都知道,Apache Spark内置了很多操作数据的API.但是很多时候,当我们在现实 ...
- Spark RDD API详解之:Map和Reduce
RDD是什么? RDD是Spark中的抽象数据结构类型,任何数据在Spark中都被表示为RDD.从编程的角度来看, RDD可以简单看成是一个数组.和普通数组的区别是,RDD中的数据是分区存储的,这样不 ...
随机推荐
- Centos修改swap分区大小
1. 查看当前分区情况 free -m 2. 增加swap大小 dd if=/dev/zero of=/var/swap bs=1024 count=12288000 #增加12G空间 3. 设置交换 ...
- 使用 Jest 和 Supertest 进行接口端点测试
如何创建测试是一件困难的事.网络上有许多关于测试的文章,却从来不告诉你他们是如何开始创建测试的. 所以,今天我将分享我在实际工作中是如何从头开始创建测试的.希望能够对你提供一些灵感. 目录: 使用 E ...
- SAINT学习笔记
SAINT的介绍 SAINT(Significance Analysis of INTeractome)是一种概率方法,用于在亲和纯化-质谱(AP-MS)实验中对阴性对照的诱饵-猎物相互作用进行打分, ...
- spring扩展点之五:ApplicationContextInitializer实现与使用
ApplicationContextInitializer是Spring框架原有的东西,这个类的主要作用就是在ConfigurableApplicationContext类型(或者子类型)的Appli ...
- BFS --- 模板题
Catch That Cow Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 36079 Accepted: 11123 ...
- Linux文件目录指令
1.pwd指令 pwd 显示当前所在的目录 2.ls指令 ls [选项] [目录或文件] 查看文件信息 ls -a 查看所有文件和目录,包括隐藏的 ls -l 以列表的方式显示 3.cd指令 cd 路 ...
- HDU校赛 | 2019 Multi-University Training Contest 6
2019 Multi-University Training Contest 6 http://acm.hdu.edu.cn/contests/contest_show.php?cid=853 100 ...
- JWT与RBAC权限模型
JWT JWT是什么? Json web token (JWT)是为了网络应用环境间传递声明而执行的一种基于JSON的开发标准(RFC7519),该token被设计为紧凑且安全的,特别适用于分布式站点 ...
- 创建一个dotnetcore的SPA模板项目
MPA和SPA 对比 dotnet new --install Microsoft.AspNetCore.SpaTemplates::* 我这边用的是vue dotnet new vue dotnet ...
- 动软软件 生成 实体类模板(EnterpriseFrameWork框架)
1.废话不多说,直接上效果图 . 2 .动软模板代码 <#@ template language="c#" HostSpecific="True" #&g ...