python爬虫--图片懒加载
图片懒加载
是一种反爬机制,图片懒加载是一种网页优化技术。图片作为一种网络资源,在被请求时也与普通静态资源一样,将占用网络资源,而一次性将整个页面的所有图片加载完,将大大增加页面的首屏加载时间。为了解决这种问题,通过前后端配合,使图片仅在浏览器当前视窗内出现时才加载该图片,达到减少首屏图片请求数的技术就被称为“图片懒加载”。
如何实现图片懒加载技术
在网页源码中,在img标签中首先会使用一个“伪属性”(通常使用src2,original…)去存放真正的图片链接而并非是直接存放在src属性中。当图片出现到页面的可视化区域中,会动态将伪属性替换成src属性,完成图片的加载。
案例
爬取站长之家的图片素材
import scrapy
import requests
headers={
'USER_AGENT':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
class ImgzzSpider(scrapy.Spider):
name = 'imgzz'
start_urls = ['http://sc.chinaz.com/tupian/']
def parse(self, response):
src = response.xpath('//*[@id="container"]/div/div[1]/a/img/@src').extract()
print(src) # 打印结果为空,这里的图片属性就应用的图片懒加载技术,其实图片的真正的src不是图片真正的属性
for url in src:
name = url.split('/')[-1]
img = requests.get(url=url,headers=headers).content
with open(name,'wb') as f:
f.write(img)
分析:
正常访问时:
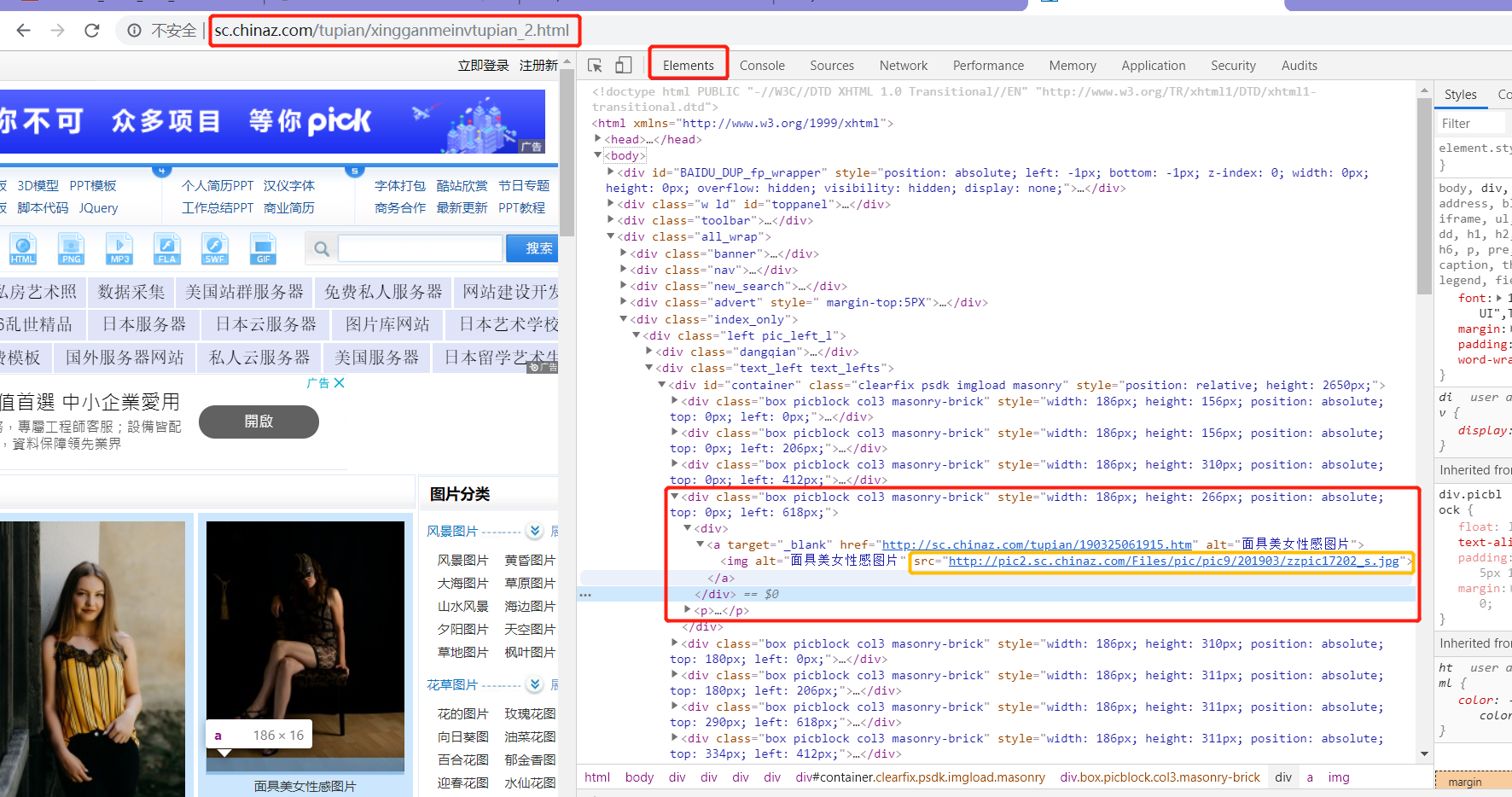
这样直接写xpath表达式定位标签的话获取的值为空
当图片出现到页面的可视化区域中,会动态将伪属性替换成src属性,完成图片的加载。通过js来完成对图片属性的替换
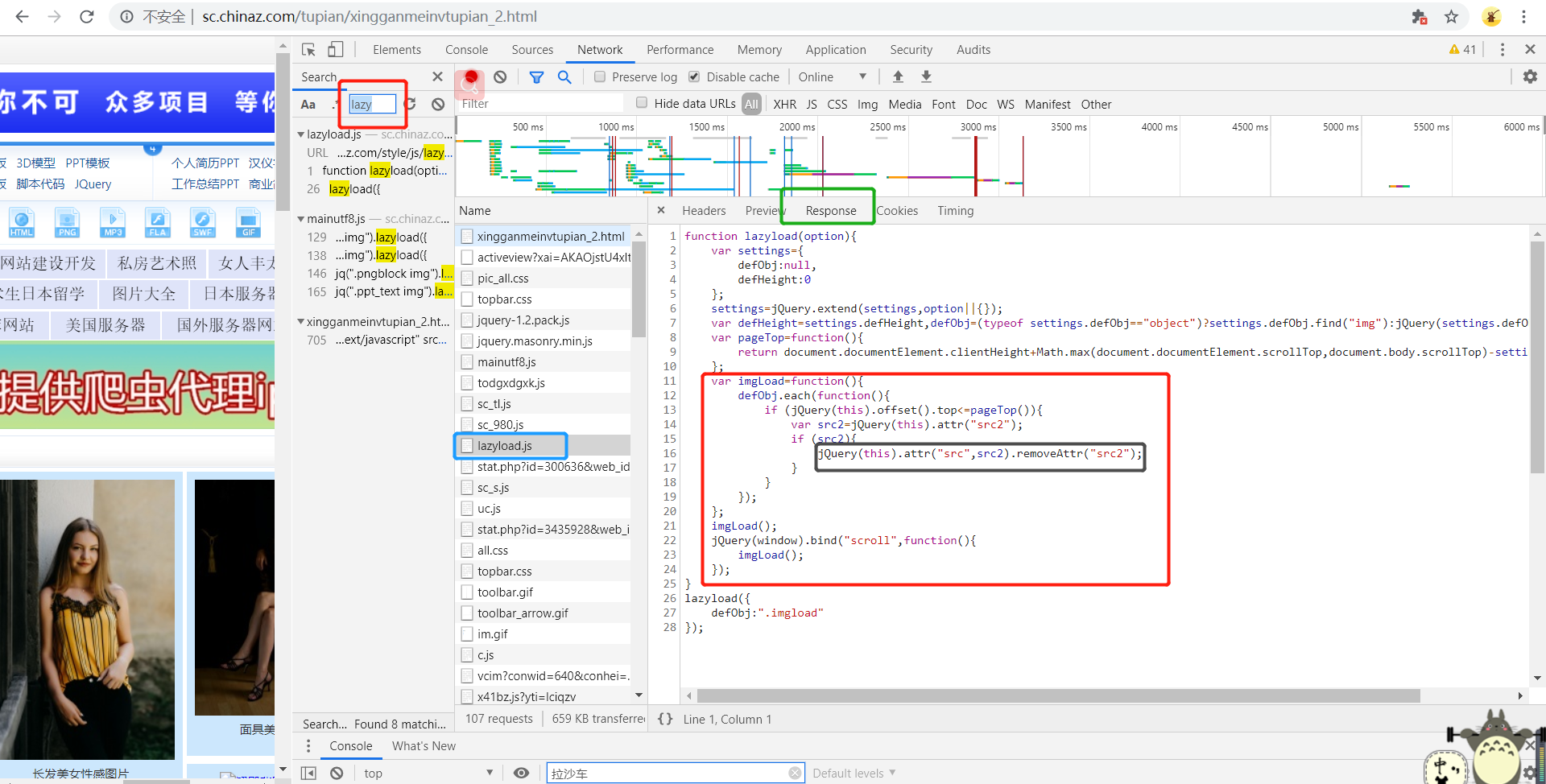
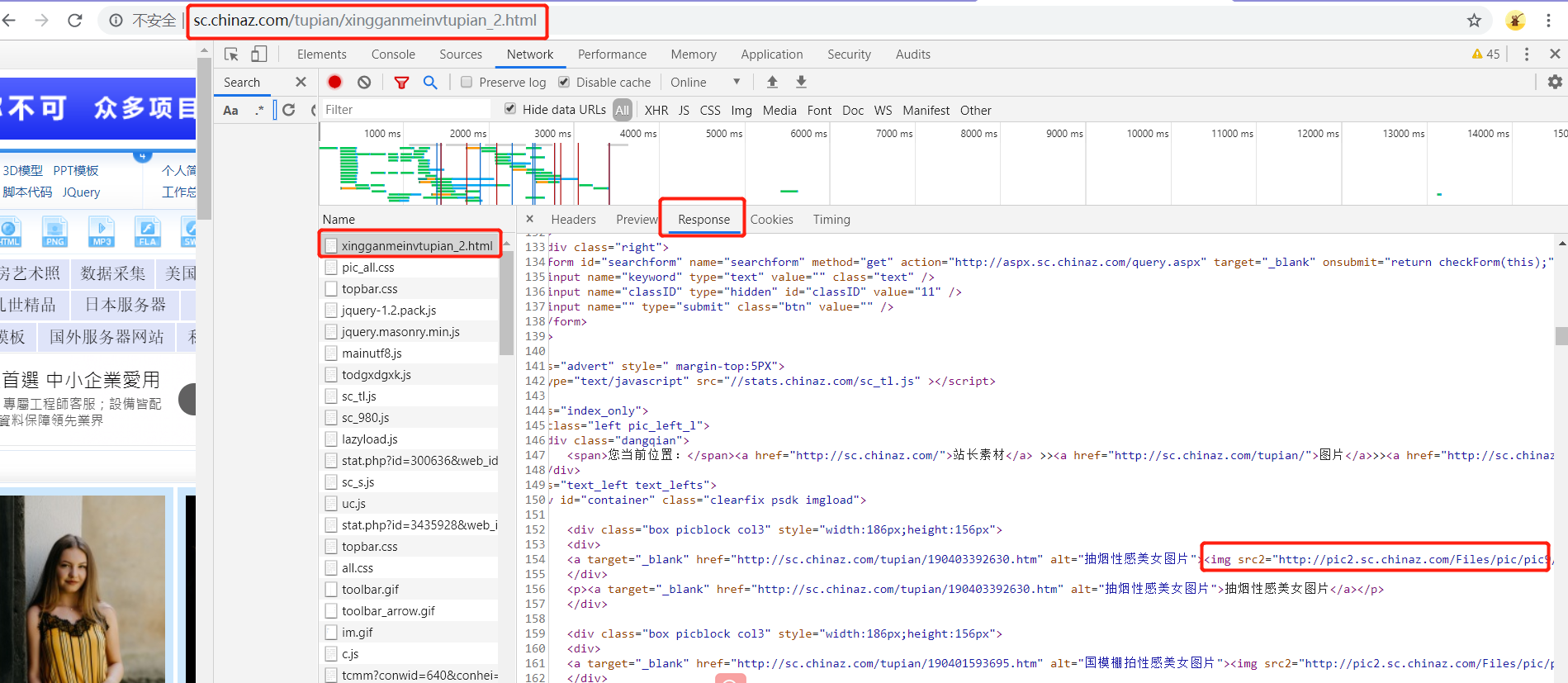
import scrapy
import requests
headers={
'USER_AGENT':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
class ImgzzSpider(scrapy.Spider):
name = 'imgzz'
start_urls = ['http://sc.chinaz.com/tupian/']
def parse(self, response):
src = response.xpath('//*[@id="container"]/div/div[1]/a/img/@src2').extract() #改为图片的真正属性
print(src)
for url in src:
name = url.split('/')[-1]
img = requests.get(url=url,headers=headers).content
with open(name,'wb') as f:
f.write(img)
python爬虫--图片懒加载的更多相关文章
- 08.Python网络爬虫之图片懒加载技术、selenium和PhantomJS
引入 今日概要 图片懒加载 selenium phantomJs 谷歌无头浏览器 知识点回顾 验证码处理流程 今日详情 动态数据加载处理 一.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素材ht ...
- Python网络爬虫之图片懒加载技术、selenium和PhantomJS
引入 图片懒加载 selenium phantomJs 谷歌无头浏览器 知识点回顾 验证码处理流程 动态数据加载处理 一.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素材http://sc.ch ...
- python爬虫之图片懒加载、selenium和phantomJS
一.什么是图片懒加载 在网页中,常常需要用到图片,而图片需要消耗较大的流量.正常情况下,浏览器会解析整个HTML代码,然后从上到下依次加载<img src="xxx"> ...
- Python爬虫之图片懒加载技术、selenium和PhantomJS
一.引入 2.概要 图片懒加载 selenium phantomJs 谷歌无头浏览器 3.回顾 验证码处理流程 一.今日详情 动态数据加载处理 1.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素 ...
- 爬虫(七)图片懒加载技术、selenium和PhantomJS
动态数据加载处理 一.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素材http://sc.chinaz.com/中的图片数据 #!/usr/bin/env python # -*- coding ...
- 爬虫之 图片懒加载, selenium , phantomJs, 谷歌无头浏览器
一.图片懒加载 懒加载 : JS 代码 是页面自然滚动 window.scrollTo(0,document.body.scrollHeight) (重点) bro.execute_ ...
- 爬虫之图片懒加载技术、selenium和PhantomJS
爬虫之图片懒加载技术.selenium和PhantomJS 图片懒加载 selenium phantomJs 谷歌无头浏览器 一.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素材http:/ ...
- 爬虫之图片懒加载技术、selenium工具与PhantomJS无头浏览器
图片懒加载技术 selenium爬虫简单使用 2.1 selenium简介 2.2 selenium安装 2.3 selenium简单使用 2.3.1 selenium使用案例 2.3.2 selen ...
- 爬虫之图片懒加载技术及js加密
图片懒加载 图片懒加载概念: 图片懒加载是一种网页优化技术.图片作为一种网络资源,在被请求时也与普通静态资源一样,将占用网络资源,而一次性将整个页面的所有图片加载完,将大大增加页面的首屏加载时间.为了 ...
随机推荐
- 【Vue | ElementUI】Vue离开当前页面时弹出确认框实现
Vue离开当前页面时弹出确认框实现 1. 实现目的 在某种业务场景下,用户不允许跳转到其他页面.于是,需要在用户误操作或者是点击浏览器跳转时提示用户. 2. 实现原理 使用路由守卫beforeRout ...
- Centos7下oracle12c的安装与配置(详细)
一.硬件配置 CentOS7@VMware® Workstation 15 Pro,分配资源:CPU:2颗,内存:4GB,硬盘空间:30GB 二.软件准备 linux.x64_11gR2_datab ...
- Laravel 菜鸟的晋级之路
第一阶段:简单的增删改查 这是最开始接触Laravel的一个阶段.如果有PHP经验,那么应该能很快找到MVC的路径,然后驾轻就熟的开始写起来.虽然还显得有些笨拙,不过很快就能做出一些内容了.如果没有P ...
- PHP中Session ID的实现原理分析
ession 的工作机制: 为每个访问者创建一个唯一的 id (UID),并基于这个 UID 来存储变量.UID 存储在 cookie 中,亦或通过 URL 进行传导. PHPSESSIONID的生产 ...
- 20191010-4 alpha week 1/2 Scrum立会报告+燃尽图 02
此作业要求参见https://edu.cnblogs.com/campus/nenu/2019fall/homework/8747 一.小组情况 组长:迟俊文 组员:宋晓丽 梁梦瑶 韩昊 刘信鹏 队名 ...
- 学会这8个优秀 Python 库用于业余项目,将大大减少程序员耗费的精力
在数据库中即时保存数据:Dataset 当我们想要在不知道最终数据库表长什么样的情况下,快速收集数据并保存到数据库中的时候,Dataset 库将是我们的最佳选择.Dataset 库有一个简单但功能强大 ...
- Glibc编译报错:*** LD_LIBRARY_PATH shouldn't contain the current directory when*** building glibc. Please change the environment variable
执行glibc编译出错如下图 [root@localhost tmpdir]# ../configure --prefix=/usr/loacl/glibc2.9 --disable-profile ...
- Kafka原理详解
Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量 ...
- HTML 表格 各标签使用的标准顺序(心得)
<table> <caption>标题</caption> <colground> <col> <col& ...
- 监控io性能、free、ps命令、查看网络状态、Linux下抓包 使用介绍
第7周第2次课(5月8日) 课程内容: 10.6 监控io性能 10.7 free命令10.8 ps命令10.9 查看网络状态10.10 linux下抓包扩展tcp三次握手四次挥手 http://ww ...