【python测试开发栈】—理解python深拷贝与浅拷贝的区别
内存的浅拷贝和深拷贝是面试时经常被问到的问题,如果不能理解其本质原理,有可能会答非所问,给面试官留下不好的印象。另外,理解浅拷贝和深拷贝的原理,还可以帮助我们理解Python内存机制。这篇文章将会通过一些例子,来验证内存拷贝的过程,帮助大家理解内存拷贝的原理。
Python3中的数据类型
我们首先得知道Python3中的数据被分为可变类型和不可变类型
- 可变类型:Number(数字)、String(字符串)、Tuple(元祖)
- 不可变类型:List(列表)、Dictionary(字典)、Set(集合)
对于可变类型和不可变类型,它们在浅拷贝和深拷贝中的表现是不一样的,下面我们就通过具体的例子来引出对应的结论。
浅拷贝
我们先来贴一个例子,然后大家可以先思考下结果会是怎样的。
def shadow_copy_test():
"""
对浅copy进行验证
:return:
"""
# 不可变数据类型
param_a = 17
param_b = "paramB"
param_c = (18, "paramC")
copy_param_a = copy.copy(param_a)
copy_param_b = copy.copy(param_b)
copy_param_c = copy.copy(param_c)
print("验证不可变数据类型")
print(id(param_a))
print(id(copy_param_a))
print(id(param_b))
print(id(copy_param_b))
print(id(param_c))
print(id(copy_param_c))
print("======================")
# 可变数据类型
param_d = [[2, 3], 18, "paramD"]
param_e = {"key1": 18, "key2": "paramE", "key3": [1, 2]}
param_f = {18, "paramF"}
copy_param_d = copy.copy(param_d)
copy_param_e = copy.copy(param_e)
copy_param_f = copy.copy(param_f)
print("验证可变数据类型")
print(id(param_d))
print(id(copy_param_d))
print(id(param_e))
print(id(copy_param_e))
print(id(param_f))
print(id(copy_param_f))
# 运行结果
验证不可变数据类型
4455468864
4455468864
4457955120
4457955120
4457945040
4457945040
======================
验证可变数据类型
4458366368
4458367168
4457911312
4457911552
4457982144
4458284768
由此我们可以看出,对于不可变类型,浅拷贝并不会更改内存地址,而对于可变数据类型,会产生一个新的内存地址。接下来我们再来看看对于可变数据类型,去修改其中的元素会怎么样:
print("验证列表中元素")
# 验证列表中第一个元素是否相等
print(id(param_d[1]))
print(id(copy_param_d[1]))
print(id(param_d[0]))
print(id(copy_param_d[0]))
print("======================")
# 更改列表中元素的值
print("验证修改可变数据类型元素的值")
param_d[0].append(4)
print(param_d)
print(copy_param_d)
param_d.append("abc")
print(param_d)
print(copy_param_d)
param_d[1] = 19
print(param_d)
print(copy_param_d)
# 运行结果
验证列表中元素
4534525792
4534525792
4537357968
4537357968
验证修改可变数据类型元素的值
[[2, 3, 4], 18, 'paramD']
[[2, 3, 4], 18, 'paramD']
[[2, 3, 4], 18, 'paramD', 'abc']
[[2, 3, 4], 18, 'paramD']
[[2, 3, 4], 19, 'paramD', 'abc']
[[2, 3, 4], 18, 'paramD']
我们从上面结果可以看出,对于可变数据结构,他们元素的内存地址没有变化(以List为例,相当于新生成一个List,然后将原来List中元素的值全部copy到新生成的List中),而修改其中的可变数据类型(比如:param_d[0]),copy对象也会同步修改(copy_param_d[0]);而修改不可变元素(比如:param_d[1]),并不会影响其copy对象(copy_param_d[1])。
综上我们可以得出如下结论(敲黑板,划重点):
- 对于不可变数据类型,浅拷贝只是复制了内存引用(指向内存的地址),并不会开辟新的内存空间(上例中param_a和copy_param_a、param_b和copy_param_b、param_c和copy_param_c内存地址一致)。
- 对于可变数据类型,浅拷贝会开辟新的内存空间(上例中param_d和copy_param_d内存地址不一致),但是它里面元素的内存地址还是一样的。
- 对于可变数据类型,改变原始对象中的可变数据类型的值,会同时影响拷贝对象的值(因为它们指向了对一个内存地址);改变原始对象中的不可变数据类型的值,不会影响拷贝对象的值。
为了方便大家理解,画了内存地址的简图:
首先是不可变数据类型,因为其值的内存地址是不可变的,所以在内存中只有这一份:
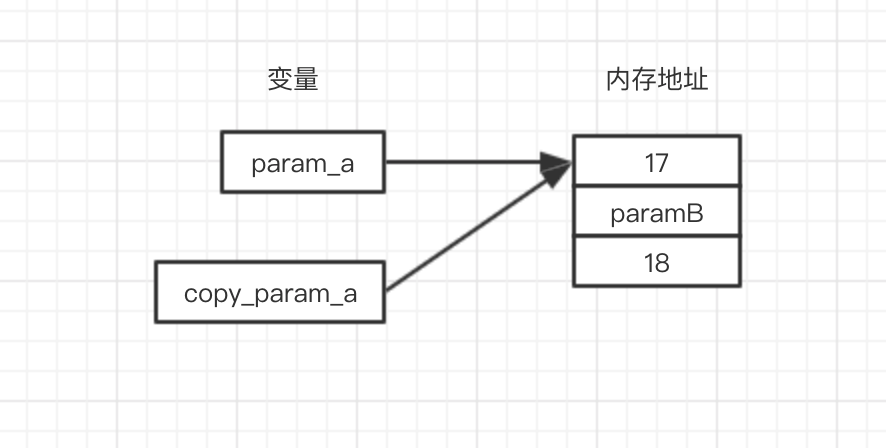
其次是可变数据类型:
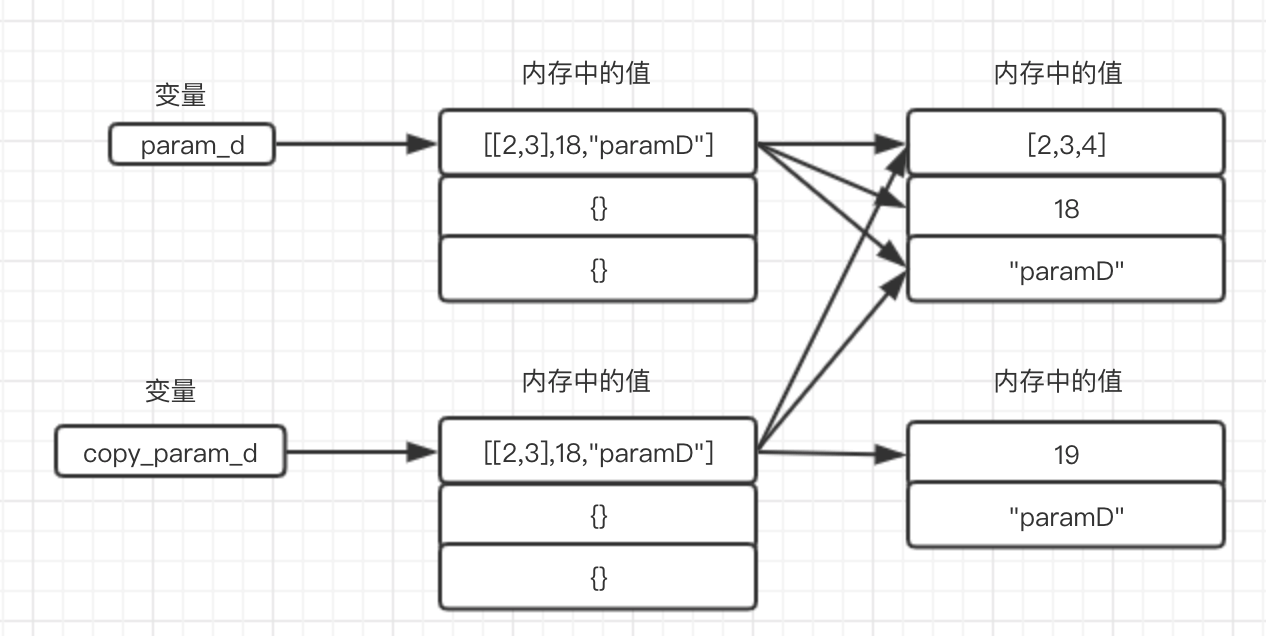
深拷贝
同样的,我们还是先来看例子(代码基本和上面的保持一致,只是修改了深拷贝方法deepcopy):
def deep_copy_test():
"""
对深拷贝进行验证
:return:
"""
"""
对浅copy进行验证
:return:
"""
# 不可变数据类型
param_a = 17
param_b = "paramB"
param_c = (18, "paramC")
copy_param_a = copy.deepcopy(param_a)
copy_param_b = copy.deepcopy(param_b)
copy_param_c = copy.deepcopy(param_c)
print("验证不可变数据类型")
print(id(param_a))
print(id(copy_param_a))
print(id(param_b))
print(id(copy_param_b))
print(id(param_c))
print(id(copy_param_c))
print("======================")
# 可变数据类型
param_d = [[2, 3], 18, "paramD"]
param_e = {"key1": 18, "key2": "paramE", "key3": [1, 2]}
param_f = {18, "paramF"}
copy_param_d = copy.deepcopy(param_d)
copy_param_e = copy.deepcopy(param_e)
copy_param_f = copy.deepcopy(param_f)
print("验证可变数据类型")
print(id(param_d))
print(id(copy_param_d))
print(id(param_e))
print(id(copy_param_e))
print(id(param_f))
print(id(copy_param_f))
print("======================")
print("验证列表中元素")
# 验证列表中第一个元素是否相等
print(id(param_d[1]))
print(id(copy_param_d[1]))
print(id(param_d[0]))
print(id(copy_param_d[0]))
print("======================")
# 更改列表中元素的值
print("验证修改可变数据类型元素的值")
param_d[0].append(4)
print(param_d)
print(copy_param_d)
param_d.append("abc")
print(param_d)
print(copy_param_d)
param_d[1] = 19
print(param_d)
print(copy_param_d)
# 打印结果如下:
验证不可变数据类型
4438175552
4438175552
4440636208
4440636208
4440885840
4440885840
======================
验证可变数据类型
4440987760
4441335360
4440593344
4440594224
4440966160
4440967840
======================
======================
验证列表中元素
4438175584
4438175584
4440628192
4441336000
验证修改可变数据类型元素的值
[[2, 3, 4], 18, 'paramD']
[[2, 3], 18, 'paramD']
[[2, 3, 4], 18, 'paramD', 'abc']
[[2, 3], 18, 'paramD']
[[2, 3, 4], 19, 'paramD', 'abc']
[[2, 3], 18, 'paramD']
我们可以和浅拷贝的运行结果做个对比,其中有差别的地方是:浅拷贝时列表中元素的内存地址没变,而深拷贝时列表中元素的内存地址发生了变化(主要针对可变数据类型,比如:param_d[0]和copy_param_d[0])。另外,对于可变数据类型,修改原始数据中的值,并不会影响拷贝数据。
综上,我们得出如下结论(敲黑板,划重点):
- 深拷贝是在浅拷贝的基础上,又对可变数据类型的元素进行了递归拷贝,因此拷贝完成时,对于可变数据类型的元素,其内存地址全部都不一致。
- 深拷贝修改原始对象和拷贝对象的值,相互之间不影响。
为了大家理解,同样画了一幅内存简图(主要是针对可变数据类型),可以对比下和浅拷贝时内存简图的区别:
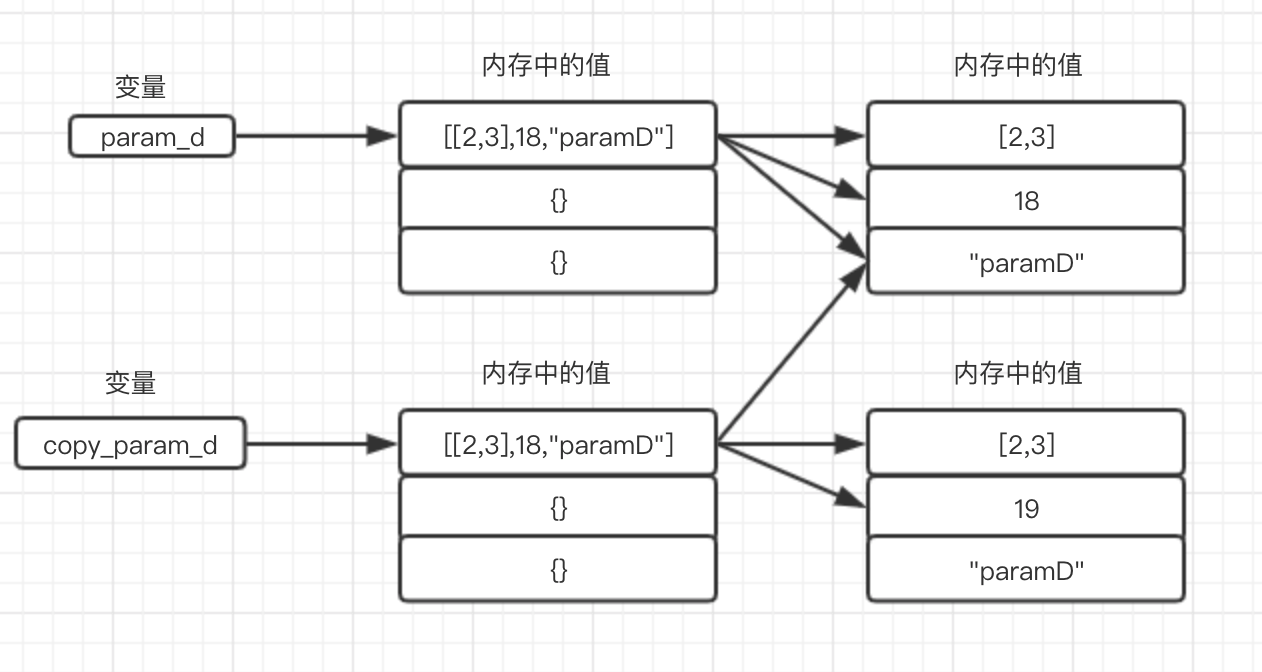
总结
本文主要介绍了在Python3中内存的深拷贝和浅拷贝机制,大家可以动手写一下文中贴的Python代码,这样更能加深你的理解。总结来说,对于Python的不可变数据类型,深拷贝和浅拷贝的差别不大;主要区别是Python中的可变数据类型,深拷贝会对列表中的子元素进行递归拷贝处理,而浅拷贝则不会。

【python测试开发栈】—理解python深拷贝与浅拷贝的区别的更多相关文章
- 【python测试开发栈】python基础语法大盘点
周边很多同学在用python,但是偶尔会发现有人对python的基础语法还不是特别了解,所以帮大家梳理了python的基础语法(文中的介绍以python3为例).如果你已然是python大牛,可以跳过 ...
- 【python测试开发栈】python内存管理机制(一)—引用计数
什么是内存 在开始进入正题之前,我们先来回忆下,计算机基础原理的知识,为什么需要内存.我们都知道计算机的CPU相当于人类的大脑,其运算速度非常的快,而我们平时写的数据,比如:文档.代码等都是存储在磁盘 ...
- 【python测试开发栈】—python内存管理机制(二)—垃圾回收
在上一篇文章中(python 内存管理机制-引用计数)中,我们介绍了python内存管理机制中的引用计数,python正是通过它来有效的管理内存.今天来介绍python的垃圾回收,其主要策略是引用计数 ...
- 【python测试开发栈】带你彻底搞明白python3编码原理
在之前的文章中,我们介绍过编码格式的发展史:[文章传送门-todo].今天我们通过几个例子,来彻底搞清楚python3中的编码格式原理,这样你之后写python脚本时碰到编码问题,才能有章可循. 我们 ...
- 【python测试开发栈】帮你总结python random模块高频使用方法
随机数据在平时写python脚本时会经常被用到,比如随机生成0和1来控制逻辑.或者从列表中随机选择一个元素(其实抽奖程序也类似,就是从公司所有人中随机选择中奖用户)等等.这篇文章,就帮大家整理在pyt ...
- 【python测试开发栈】—帮你总结Python os模块高频使用的方法
Python中的os模块是主要和系统操作相关的模块,在平时的工作中会经常用到,花时间整理了os模块的高频使用方法,同时整理出使用时需要注意的点.归纳来讲,os模块的方法可以分为:目录操作.文件操作.路 ...
- 《Python测试开发技术栈—巴哥职场进化记》—前言
写在前面 今年从4月份开始写一本讲Python测试开发技术栈的书,主要有两个目的,第一是将自己掌握的一些内容分享给大家,第二是希望自己能系统的梳理和学习Python相关的技术栈.当时我本来打算以故事体 ...
- 《Python测试开发技术栈—巴哥职场进化记》—初来乍到,请多关照
上文<巴哥职场进化记-Python测试开发技术栈>开篇讲到巴哥毕业初到深圳,见到了来自五湖四海的室友.一番畅聊之后,抱着对未来职场生活的期待,大家都进入了梦乡.今天我们来看看巴哥第一天上班 ...
- 《Python测试开发技术栈—巴哥职场进化记》—软件测试工程师“兵器库”
上文<Python测试开发技术栈-巴哥职场进化记>-初来乍到,请多关照 我们介绍了巴哥入职后见到了自己的导师华哥,第一次参加团队站会,认识了团队中的开发小哥哥和产品小姐姐以及吃到了公司的加 ...
随机推荐
- spark-宽依赖和窄依赖
一.窄依赖(Narrow Dependency,) 即一个RDD,对它的父RDD,只有简单的一对一的依赖关系.也就是说, RDD的每个partition ,仅仅依赖于父RDD中的一个partition ...
- Centos内核参数优化
关于内核参数优化 net.ipv4.tcp_max_tw_buckets = 6000 net.ipv4.ip_local_port_range = 1024 65000 net.ipv4.tcp_ ...
- element表格点击行即选中该行复选框
关键代码如下 <el-table ref="multipleTable" :data="tableData" highlight-current-row ...
- js数组和集合互转
js数组和集合互转可用于去重: 数组转集合 var arr = [55, 44, 65]; var set = new Set(arr); console.log(set.size === arr ...
- Alibaba Nacos 学习(一):Nacos介绍与安装
Alibaba Nacos 学习(一):Nacos介绍与安装 Alibaba Nacos 学习(二):Spring Cloud Nacos Config Alibaba Nacos 学习(三):Spr ...
- 【Stream—6】BufferedStream相关知识分享
一.简单介绍以下BufferedStream 在前几章的讲述中,我们已经能够掌握流的基本特性和特点,一般进行对流的处理时,系统肩负着IO所带来的开销,调用十分频繁,这时候就应该想个办法减少这种开销,而 ...
- k8s 随记
1.kubelet参数解析:https://blog.csdn.net/qq_34857250/article/details/84995381 2.如何在github中查找k8s代码关键字? 现在我 ...
- PostGIS 查询点在线上
1.缓冲区法:查询数据库fm表里,与坐标(12989691.512 4798962.444)相距0.0001米的数据(3857坐标系) ),),),),geom) ; --如果坐标系统一,不用tran ...
- pyhton3 之 time模块实例小结
一.实例1:实现秒表: import time print('按下回车开始计时,按下 Ctrl + C 停止计时.') while True: try: input() # 如果是 python 2. ...
- ehcache同步原理
最近研究ehcache同步时发现一个问题: 现有A.B两个服务器,由A服务器向B服务器同步信息,采用RMI方式手动方式进行同步 配置信息如下: <?xml version="1.0&q ...