【集合框架】JDK1.8源码分析之LinkedList(七)
一、前言
在分析了ArrayList了之后,紧接着必须要分析它的同胞兄弟:LinkedList,LinkedList与ArrayList在底层的实现上有所不同,其实,只要我们有数据结构的基础,在分析源码的时候就会很简单,下面进入正题,LinkedList源码分析。
二、LinkedList数据结构
还是老规矩,先抓住LinkedList的核心部分:数据结构,其数据结构如下

说明:如上图所示,LinkedList底层使用的双向链表结构,有一个头结点和一个尾结点,双向链表意味着我们可以从头开始正向遍历,或者是从尾开始逆向遍历,并且可以针对头部和尾部进行相应的操作。
三、LinkedList源码分析
3.1 类的继承关系
- public class LinkedList<E>
- extends AbstractSequentialList<E>
- implements List<E>, Deque<E>, Cloneable, java.io.Serializable
说明:LinkedList的类继承结构很有意思,我们着重要看是Deque接口,Deque接口表示是一个双端队列,那么也意味着LinkedList是双端队列的一种实现,所以,基于双端队列的操作在LinkedList中全部有效。
3.2 类的内部类
- private static class Node<E> {
- E item; // 数据域
- Node<E> next; // 后继
- Node<E> prev; // 前驱
- // 构造函数,赋值前驱后继
- Node(Node<E> prev, E element, Node<E> next) {
- this.item = element;
- this.next = next;
- this.prev = prev;
- }
- }
说明:内部类Node就是实际的结点,用于存放实际元素的地方。
3.3 类的属性
- public class LinkedList<E>
- extends AbstractSequentialList<E>
- implements List<E>, Deque<E>, Cloneable, java.io.Serializable
- {
- // 实际元素个数
- transient int size = 0;
- // 头结点
- transient Node<E> first;
- // 尾结点
- transient Node<E> last;
- }
说明:LinkedList的属性非常简单,一个头结点、一个尾结点、一个表示链表中实际元素个数的变量。注意,头结点、尾结点都有transient关键字修饰,这也意味着在序列化时该域是不会序列化的。
3.4 类的构造函数
1. LinkedList()型构造函数
- public LinkedList() {
- }
2. LinkedList(Collection<? extends E>)型构造函数
- public LinkedList(Collection<? extends E> c) {
- // 调用无参构造函数
- this();
- // 添加集合中所有的元素
- addAll(c);
- }
说明:会调用无参构造函数,并且会把集合中所有的元素添加到LinkedList中。
3.5 核心函数分析
1. add函数
- public boolean add(E e) {
- // 添加到末尾
- linkLast(e);
- return true;
- }
说明:add函数用于向LinkedList中添加一个元素,并且添加到链表尾部。具体添加到尾部的逻辑是由linkLast函数完成的。
- void linkLast(E e) {
- // 保存尾结点,l为final类型,不可更改
- final Node<E> l = last;
- // 新生成结点的前驱为l,后继为null
- final Node<E> newNode = new Node<>(l, e, null);
- // 重新赋值尾结点
- last = newNode;
- if (l == null) // 尾结点为空
- first = newNode; // 赋值头结点
- else // 尾结点不为空
- l.next = newNode; // 尾结点的后继为新生成的结点
- // 大小加1
- size++;
- // 结构性修改加1
- modCount++;
- }
说明:对于添加一个元素至链表中会调用add方法 -> linkLast方法。
对于添加元素的情况我们使用如下示例进行说明
示例一代码如下(只展示了核心代码)
- List<Integer> lists = new LinkedList<Integer>();
- lists.add(5);
- lists.add(6);
说明:首先调用无参构造函数,之后添加元素5,之后再添加元素6。具体的示意图如下:
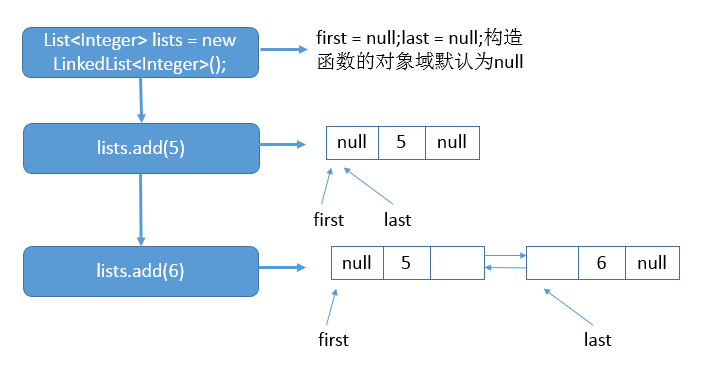
说明:上图的表明了在执行每一条语句后,链表对应的状态。
2. addAll函数
addAll有两个重载函数,addAll(Collection<? extends E>)型和addAll(int, Collection<? extends E>)型,我们平时习惯调用的addAll(Collection<? extends E>)型会转化为addAll(int, Collection<? extends E>)型,所以我们着重分析此函数即可。
- // 添加一个集合
- public boolean addAll(int index, Collection<? extends E> c) {
- // 检查插入的的位置是否合法
- checkPositionIndex(index);
- // 将集合转化为数组
- Object[] a = c.toArray();
- // 保存集合大小
- int numNew = a.length;
- if (numNew == 0) // 集合为空,直接返回
- return false;
- Node<E> pred, succ; // 前驱,后继
- if (index == size) { // 如果插入位置为链表末尾,则后继为null,前驱为尾结点
- succ = null;
- pred = last;
- } else { // 插入位置为其他某个位置
- succ = node(index); // 寻找到该结点
- pred = succ.prev; // 保存该结点的前驱
- }
- for (Object o : a) { // 遍历数组
- @SuppressWarnings("unchecked") E e = (E) o; // 向下转型
- // 生成新结点
- Node<E> newNode = new Node<>(pred, e, null);
- if (pred == null) // 表示在第一个元素之前插入(索引为0的结点)
- first = newNode;
- else
- pred.next = newNode;
- pred = newNode;
- }
- if (succ == null) { // 表示在最后一个元素之后插入
- last = pred;
- } else {
- pred.next = succ;
- succ.prev = pred;
- }
- // 修改实际元素个数
- size += numNew;
- // 结构性修改加1
- modCount++;
- return true;
- }
说明:参数中的index表示在索引下标为index的结点(实际上是第index + 1个结点)的前面插入。在addAll函数中,addAll函数中还会调用到node函数,get函数也会调用到node函数,此函数是根据索引下标找到该结点并返回,具体代码如下
- Node<E> node(int index) {
- // 判断插入的位置在链表前半段或者是后半段
- if (index < (size >> 1)) { // 插入位置在前半段
- Node<E> x = first;
- for (int i = 0; i < index; i++) // 从头结点开始正向遍历
- x = x.next;
- return x; // 返回该结点
- } else { // 插入位置在后半段
- Node<E> x = last;
- for (int i = size - 1; i > index; i--) // 从尾结点开始反向遍历
- x = x.prev;
- return x; // 返回该结点
- }
- }
说明:在根据索引查找结点时,会有一个小优化,结点在前半段则从头开始遍历,在后半段则从尾开始遍历,这样就保证了只需要遍历最多一半结点就可以找到指定索引的结点。
下面通过示例来更深入了解调用addAll函数后的链表状态。
- List<Integer> lists = new LinkedList<Integer>();
- lists.add(5);
- lists.addAll(0, Arrays.asList(2, 3, 4, 5));
上述代码内部的链表结构如下:
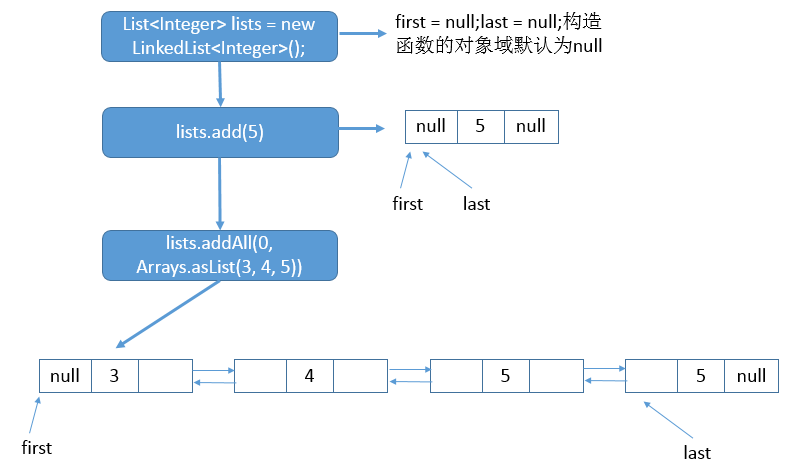
3. unlink函数
在调用remove移除结点时,会调用到unlink函数,unlink函数具体如下:
- E unlink(Node<E> x) {
- // 保存结点的元素
- final E element = x.item;
- // 保存x的后继
- final Node<E> next = x.next;
- // 保存x的前驱
- final Node<E> prev = x.prev;
- if (prev == null) { // 前驱为空,表示删除的结点为头结点
- first = next; // 重新赋值头结点
- } else { // 删除的结点不为头结点
- prev.next = next; // 赋值前驱结点的后继
- x.prev = null; // 结点的前驱为空,切断结点的前驱指针
- }
- if (next == null) { // 后继为空,表示删除的结点为尾结点
- last = prev; // 重新赋值尾结点
- } else { // 删除的结点不为尾结点
- next.prev = prev; // 赋值后继结点的前驱
- x.next = null; // 结点的后继为空,切断结点的后继指针
- }
- x.item = null; // 结点元素赋值为空
- // 减少元素实际个数
- size--;
- // 结构性修改加1
- modCount++;
- // 返回结点的旧元素
- return element;
- }
说明:将指定的结点从链表中断开,不再累赘。
四、针对LinkedList的思考
1. 对addAll函数的思考
在addAll函数中,传入一个集合参数和插入位置,然后将集合转化为数组,然后再遍历数组,挨个添加数组的元素,但是问题来了,为什么要先转化为数组再进行遍历,而不是直接遍历集合呢?从效果上两者是完全等价的,都可以达到遍历的效果。关于为什么要转化为数组的问题,我的思考如下:1. 如果直接遍历集合的话,那么在遍历过程中需要插入元素,在堆上分配内存空间,修改指针域,这个过程中就会一直占用着这个集合,考虑正确同步的话,其他线程只能一直等待。2. 如果转化为数组,只需要遍历集合,而遍历集合过程中不需要额外的操作,所以占用的时间相对是较短的,这样就利于其他线程尽快的使用这个集合。说白了,就是有利于提高多线程访问该集合的效率,尽可能短时间的阻塞。
五、总结
分析完了LinkedList源码,其实很简单,值得注意的是LinkedList可以作为双端队列使用,这也是队列结构在Java中一种实现,当需要使用队列结构时,可以考虑LinkedList。谢谢各位园友观看~
【集合框架】JDK1.8源码分析之LinkedList(七)的更多相关文章
- 【集合框架】JDK1.8源码分析之HashMap(一) 转载
[集合框架]JDK1.8源码分析之HashMap(一) 一.前言 在分析jdk1.8后的HashMap源码时,发现网上好多分析都是基于之前的jdk,而Java8的HashMap对之前做了较大的优化 ...
- 【集合框架】JDK1.8源码分析之ArrayList详解(一)
[集合框架]JDK1.8源码分析之ArrayList详解(一) 一. 从ArrayList字表面推测 ArrayList类的命名是由Array和List单词组合而成,Array的中文意思是数组,Lis ...
- 【集合框架】JDK1.8源码分析之Collections && Arrays(十)
一.前言 整个集合框架的常用类我们已经分析完成了,但是还有两个工具类我们还没有进行分析.可以说,这两个工具类对于我们操作集合时相当有用,下面进行分析. 二.Collections源码分析 2.1 类的 ...
- 【集合框架】JDK1.8源码分析HashSet && LinkedHashSet(八)
一.前言 分析完了List的两个主要类之后,我们来分析Set接口下的类,HashSet和LinkedHashSet,其实,在分析完HashMap与LinkedHashMap之后,再来分析HashSet ...
- 集合之TreeSet(含JDK1.8源码分析)
一.前言 前面分析了Set接口下的hashSet和linkedHashSet,下面接着来看treeSet,treeSet的底层实现是基于treeMap的. 四个关注点在treeSet上的答案 二.tr ...
- 集合之LinkedHashSet(含JDK1.8源码分析)
一.前言 上篇已经分析了Set接口下HashSet,我们发现其操作都是基于hashMap的,接下来看LinkedHashSet,其底层实现都是基于linkedHashMap的. 二.linkedHas ...
- 集合之HashSet(含JDK1.8源码分析)
一.前言 我们已经分析了List接口下的ArrayList和LinkedList,以及Map接口下的HashMap.LinkedHashMap.TreeMap,接下来看的是Set接口下HashSet和 ...
- 【JUC】JDK1.8源码分析之ArrayBlockingQueue(三)
一.前言 在完成Map下的并发集合后,现在来分析ArrayBlockingQueue,ArrayBlockingQueue可以用作一个阻塞型队列,支持多任务并发操作,有了之前看源码的积累,再看Arra ...
- Java集合系列[4]----LinkedHashMap源码分析
这篇文章我们开始分析LinkedHashMap的源码,LinkedHashMap继承了HashMap,也就是说LinkedHashMap是在HashMap的基础上扩展而来的,因此在看LinkedHas ...
随机推荐
- C++指针类型识别正确姿势
指针是C和C++中编程最复杂也是最有技巧的部分,但对于新手来说,指针无疑是最致命的,让很多人望而退步.不过很多事情都是从陌生开始,然后渐渐熟悉起来的,就像交朋友一样,得花点时间去培养感情才行.不过指针 ...
- 关于mysql ERROR 1045 (28000)错误的解决办法
错误情景: 使用Navicat打开mysql的时候弹出错误框 错误代码: ERROR 1045 (28000): Access denied for user 'ODBC'@'localhost' ( ...
- JDBC的连接和操作
package Test; import java.sql.*; public class Test21 { public static void main(String[] args) { Conn ...
- 动态sql
目录 1.给动态语句传值(USING 子句) 2.从动态语句检索值(INTO子句) 3.动态调用存过 4.将返回值传递到PL/SQL记录类型;同样也可用%rowtype变量 5.传递并检索值.INTO ...
- Expert 诊断优化系列------------------你的CPU高么?
现在很多用户被数据库的慢的问题所困扰,又苦于花钱请一个专业的DBA成本太高.软件维护人员对数据库的了解又不是那么深入,所以导致问题迟迟不能解决,或只能暂时解决不能得到根治.开发人员解决数据问题基本又是 ...
- Python学习笔记
1. 进行浮点数运算时,整数要写成浮点数形式,否则Python默认按照整数进行运算了,譬如3/5应该写成3.0/5.0: 2. Python没有switch: 3. Python中没有重载,但是可以通 ...
- 我所理解的RESTful Web API [Web标准篇]
REST不是一个标准,而是一种软件应用架构风格.基于SOAP的Web服务采用RPC架构,如果说RPC是一种面向操作的架构风格,而REST则是一种面向资源的架构风格.REST是目前业界更为推崇的构建新一 ...
- PHPCMS后台密码忘记解决办法
什么是PHPCMS? PHPCMS是一款网站管理软件.该软件采用模块化开发,支持多种分类方式,使用它可方便实现个性化网站的设计.开发与维护.它支持众多的程序组合,可轻松实现网站平台迁移,并可广泛满足各 ...
- php单条件查询,关键字查询
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- 2013 duilib入门简明教程 -- XML配置界面(6)
前面那些教程都是为了让小伙伴们从win32.MFC过渡到duilib,让大家觉得duilib不是那么陌生,如果大家现在还对duilib非常陌生的话,那就说明前面的教程做得不好,请大家在下面留言 ...