flask 源码解析:上下文(一)
文章出处 https://www.cnblogs.com/jackchengcc/archive/2018/11/29/10025949.html
一:什么是上下文
每一段程序都有很多外部变量。只有像Add这种简单的函数才是没有外部变量的。一旦你的一段程序有了外部变量,这段程序就不完整,不能独立运行。你为了使他们运行,就要给所有的外部变量一个一个写一些值进去。这些值的集合就叫上下文。
在 flask 中,视图函数需要知道它执行情况的请求信息(请求的 url,参数,方法等)以及应用信息(应用中初始化的数据库等),才能够正确运行。最直观地做法是把这些信息封装成一个对象,作为参数传递给视图函数。但是这样的话,所有的视图函数都需要添加对应的参数,即使该函数内部并没有使用到它。flask 的做法是把这些信息作为类似全局变量的东西,视图函数需要的时候,可以使用 from flask import request 获取。但是这些对象和全局变量不同的是——它们必须是动态的,因为在多线程或者多协程的情况下,每个线程或者协程获取的都是自己独特的对象,不会互相干扰。
二:实现过程
在python多线程中,有threading.local,可以实现多个线程访问某个变量时,每个线程只能看到自己的数据(flask上下文中,每个线程也只能访问自己请求所封装的数据),其内部原理大致为:封装的对象有一个字典,字典中保存了每个线程id所对应的数据,读取到该对象时,它动态的查询当前线程id对应的数据。代码实现原理大致如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
import threadingfrom _thread import get_identfrom greenlet import getcurrent"""{ 1368:{}}"""import threadingtry: from greenlet import getcurrent as get_ident # 协程except ImportError: try: from thread import get_ident except ImportError: from _thread import get_ident # 线程<br>class Local(object): def __init__(self): self.storage = {}#存储数据 self.get_ident = get_ident#线程唯一标识 def set(self,k,v): ident = self.get_ident() origin = self.storage.get(ident) if not origin: origin = {k:v} else: origin[k] = v self.storage[ident] = origin def get(self,k): ident = self.get_ident() origin = self.storage.get(ident) if not origin: return None return origin.get(k,None)local_values = Local()def task(num): local_values.set('name',num) import time time.sleep(1) print(local_values.get('name'), threading.current_thread().name)for i in range(20): th = threading.Thread(target=task, args=(i,),name='线程%s' % i) th.start() |
flask 中有两种上下文:application context 和 request context。上下文有关的内容定义在 globals.py 文件,文件的内容也非常短:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
def _lookup_req_object(name): top = _request_ctx_stack.top if top is None: raise RuntimeError(_request_ctx_err_msg) return getattr(top, name)def _lookup_app_object(name): top = _app_ctx_stack.top if top is None: raise RuntimeError(_app_ctx_err_msg) return getattr(top, name)def _find_app(): top = _app_ctx_stack.top if top is None: raise RuntimeError(_app_ctx_err_msg) return top.app# context locals_request_ctx_stack = LocalStack()_app_ctx_stack = LocalStack()current_app = LocalProxy(_find_app)request = LocalProxy(partial(_lookup_req_object, 'request'))session = LocalProxy(partial(_lookup_req_object, 'session'))g = LocalProxy(partial(_lookup_app_object, 'g')) |
flask 提供两种上下文:application context 和 request context 。application context 又演化出来两个变量 current_app 和 g,而 request context 则演化出来 request 和 session。
这里的实现用到了两个东西:LocalStack 和 LocalProxy。它们两个的结果就是我们可以动态地获取两个上下文的内容,在并发程序中每个视图函数都会看到属于自己的上下文,而不会出现混乱。
LocalStack 和 LocalProxy 都是 werkzeug 提供的,定义在 local.py 文件中。在分析这两个类之前,我们先介绍这个文件另外一个基础的类 Local。Local 就是实现了类似 threading.local 的效果——多线程或者多协程情况下全局变量的隔离效果。下面是它的代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
# since each thread has its own greenlet we can just use those as identifiers# for the context. If greenlets are not available we fall back to the# current thread ident depending on where it is.try: from greenlet import getcurrent as get_identexcept ImportError: try: from thread import get_ident except ImportError: from _thread import get_identclass Local(object): __slots__ = ('__storage__', '__ident_func__') def __init__(self): # 数据保存在 __storage__ 中,后续访问都是对该属性的操作 object.__setattr__(self, '__storage__', {}) object.__setattr__(self, '__ident_func__', get_ident) def __call__(self, proxy): """Create a proxy for a name.""" return LocalProxy(self, proxy) # 清空当前线程/协程保存的所有数据 def __release_local__(self): self.__storage__.pop(self.__ident_func__(), None) # 下面三个方法实现了属性的访问、设置和删除。 # 注意到,内部都调用 `self.__ident_func__` 获取当前线程或者协程的 id,然后再访问对应的内部字典。 # 如果访问或者删除的属性不存在,会抛出 AttributeError。 # 这样,外部用户看到的就是它在访问实例的属性,完全不知道字典或者多线程/协程切换的实现 def __getattr__(self, name): try: return self.__storage__[self.__ident_func__()][name] except KeyError: raise AttributeError(name) def __setattr__(self, name, value): ident = self.__ident_func__() storage = self.__storage__ try: storage[ident][name] = value except KeyError: storage[ident] = {name: value} def __delattr__(self, name): try: del self.__storage__[self.__ident_func__()][name] except KeyError: raise AttributeError(name) |
可以看到,Local 对象内部的数据都是保存在 __storage__ 属性的,这个属性变量是个嵌套的字典:map[ident]map[key]value。最外面字典 key 是线程或者协程的 identity,value 是另外一个字典,这个内部字典就是用户自定义的 key-value 键值对。用户访问实例的属性,就变成了访问内部的字典,外面字典的 key 是自动关联的。__ident_func 是 协程的 get_current 或者线程的 get_ident,从而获取当前代码所在线程或者协程的 id。
除了这些基本操作之外,Local 还实现了 __release_local__ ,用来清空(析构)当前线程或者协程的数据(状态)。__call__ 操作来创建一个 LocalProxy 对象,LocalProxy 会在下面讲到。
理解了 Local,我们继续回来看另外两个类。
LocalStack 是基于 Local 实现的栈结构。如果说 Local 提供了多线程或者多协程隔离的属性访问,那么 LocalStack 就提供了隔离的栈访问。下面是它的实现代码,可以看到它提供了 push、pop 和 top 方法。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
# __release_local__ 可以用来清空当前线程或者协程的栈数据<br># __call__ 方法返回当前线程或者协程栈顶元素的代理对象。<br>class LocalStack(object): """This class works similar to a :class:`Local` but keeps a stack of objects instead. """ def __init__(self): self._local = Local() def __release_local__(self): self._local.__release_local__() def __call__(self): def _lookup(): rv = self.top if rv is None: raise RuntimeError('object unbound') return rv return LocalProxy(_lookup) # push、pop 和 top 三个方法实现了栈的操作, # 可以看到栈的数据是保存在 self._local.stack 属性中的 def push(self, obj): """Pushes a new item to the stack""" rv = getattr(self._local, 'stack', None) if rv is None: self._local.stack = rv = [] rv.append(obj) return rv def pop(self): """Removes the topmost item from the stack, will return the old value or `None` if the stack was already empty. """ stack = getattr(self._local, 'stack', None) if stack is None: return None elif len(stack) == 1: release_local(self._local) return stack[-1] else: return stack.pop() @property def top(self): """The topmost item on the stack. If the stack is empty, `None` is returned. """ try: return self._local.stack[-1] except (AttributeError, IndexError): return None |
我们在之前看到了 request context 的定义,它就是一个 LocalStack 的实例:
|
1
|
_request_ctx_stack = LocalStack() |
它会当前线程或者协程的请求都保存在栈里,等使用的时候再从里面读取。至于为什么要用到栈结构,而不是直接使用 Local,我们会在后面揭晓答案,你可以先思考一下。
LocalProxy 是一个 Local 对象的代理,负责把所有对自己的操作转发给内部的 Local 对象。LocalProxy 的构造函数介绍一个 callable 的参数,这个 callable 调用之后需要返回一个 Local 实例,后续所有的属性操作都会转发给 callable 返回的对象。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
|
class LocalProxy(object): """Acts as a proxy for a werkzeug local. Forwards all operations to a proxied object. The only operations not supported for forwarding are right handed operands and any kind of assignment. Example usage:: from werkzeug.local import Local l = Local() # these are proxies request = l('request') user = l('user') from werkzeug.local import LocalStack _response_local = LocalStack() # this is a proxy response = _response_local() Whenever something is bound to l.user / l.request the proxy objects will forward all operations. If no object is bound a :exc:`RuntimeError` will be raised. To create proxies to :class:`Local` or :class:`LocalStack` objects, call the object as shown above. If you want to have a proxy to an object looked up by a function, you can (as of Werkzeug 0.6.1) pass a function to the :class:`LocalProxy` constructor:: session = LocalProxy(lambda: get_current_request().session) .. versionchanged:: 0.6.1 The class can be instantiated with a callable as well now. """ __slots__ = ('__local', '__dict__', '__name__', '__wrapped__') def __init__(self, local, name=None): object.__setattr__(self, '_LocalProxy__local', local) object.__setattr__(self, '__name__', name) if callable(local) and not hasattr(local, '__release_local__'): # "local" is a callable that is not an instance of Local or # LocalManager: mark it as a wrapped function. object.__setattr__(self, '__wrapped__', local) def _get_current_object(self): """Return the current object. This is useful if you want the real object behind the proxy at a time for performance reasons or because you want to pass the object into a different context. """ if not hasattr(self.__local, '__release_local__'): return self.__local() try: return getattr(self.__local, self.__name__) except AttributeError: raise RuntimeError('no object bound to %s' % self.__name__) @property def __dict__(self): try: return self._get_current_object().__dict__ except RuntimeError: raise AttributeError('__dict__') def __repr__(self): try: obj = self._get_current_object() except RuntimeError: return '<%s unbound>' % self.__class__.__name__ return repr(obj) def __bool__(self): try: return bool(self._get_current_object()) except RuntimeError: return False def __unicode__(self): try: return unicode(self._get_current_object()) # noqa except RuntimeError: return repr(self) def __dir__(self): try: return dir(self._get_current_object()) except RuntimeError: return [] def __getattr__(self, name): if name == '__members__': return dir(self._get_current_object()) return getattr(self._get_current_object(), name) def __setitem__(self, key, value): self._get_current_object()[key] = value def __delitem__(self, key): del self._get_current_object()[key] if PY2: __getslice__ = lambda x, i, j: x._get_current_object()[i:j] def __setslice__(self, i, j, seq): self._get_current_object()[i:j] = seq def __delslice__(self, i, j): del self._get_current_object()[i:j] __setattr__ = lambda x, n, v: setattr(x._get_current_object(), n, v) __delattr__ = lambda x, n: delattr(x._get_current_object(), n) __str__ = lambda x: str(x._get_current_object()) __lt__ = lambda x, o: x._get_current_object() < o __le__ = lambda x, o: x._get_current_object() <= o __eq__ = lambda x, o: x._get_current_object() == o __ne__ = lambda x, o: x._get_current_object() != o __gt__ = lambda x, o: x._get_current_object() > o __ge__ = lambda x, o: x._get_current_object() >= o __cmp__ = lambda x, o: cmp(x._get_current_object(), o) # noqa __hash__ = lambda x: hash(x._get_current_object()) __call__ = lambda x, *a, **kw: x._get_current_object()(*a, **kw) __len__ = lambda x: len(x._get_current_object()) __getitem__ = lambda x, i: x._get_current_object()[i] __iter__ = lambda x: iter(x._get_current_object()) __contains__ = lambda x, i: i in x._get_current_object() __add__ = lambda x, o: x._get_current_object() + o __sub__ = lambda x, o: x._get_current_object() - o __mul__ = lambda x, o: x._get_current_object() * o __floordiv__ = lambda x, o: x._get_current_object() // o __mod__ = lambda x, o: x._get_current_object() % o __divmod__ = lambda x, o: x._get_current_object().__divmod__(o) __pow__ = lambda x, o: x._get_current_object() ** o __lshift__ = lambda x, o: x._get_current_object() << o __rshift__ = lambda x, o: x._get_current_object() >> o __and__ = lambda x, o: x._get_current_object() & o __xor__ = lambda x, o: x._get_current_object() ^ o __or__ = lambda x, o: x._get_current_object() | o __div__ = lambda x, o: x._get_current_object().__div__(o) __truediv__ = lambda x, o: x._get_current_object().__truediv__(o) __neg__ = lambda x: -(x._get_current_object()) __pos__ = lambda x: +(x._get_current_object()) __abs__ = lambda x: abs(x._get_current_object()) __invert__ = lambda x: ~(x._get_current_object()) __complex__ = lambda x: complex(x._get_current_object()) __int__ = lambda x: int(x._get_current_object()) __long__ = lambda x: long(x._get_current_object()) # noqa __float__ = lambda x: float(x._get_current_object()) __oct__ = lambda x: oct(x._get_current_object()) __hex__ = lambda x: hex(x._get_current_object()) __index__ = lambda x: x._get_current_object().__index__() __coerce__ = lambda x, o: x._get_current_object().__coerce__(x, o) __enter__ = lambda x: x._get_current_object().__enter__() __exit__ = lambda x, *a, **kw: x._get_current_object().__exit__(*a, **kw) __radd__ = lambda x, o: o + x._get_current_object() __rsub__ = lambda x, o: o - x._get_current_object() __rmul__ = lambda x, o: o * x._get_current_object() __rdiv__ = lambda x, o: o / x._get_current_object() if PY2: __rtruediv__ = lambda x, o: x._get_current_object().__rtruediv__(o) else: __rtruediv__ = __rdiv__ __rfloordiv__ = lambda x, o: o // x._get_current_object() __rmod__ = lambda x, o: o % x._get_current_object() __rdivmod__ = lambda x, o: x._get_current_object().__rdivmod__(o) __copy__ = lambda x: copy.copy(x._get_current_object()) __deepcopy__ = lambda x, memo: copy.deepcopy(x._get_current_object(), memo) |
这里实现的关键是把通过参数传递进来的 Local 实例保存在 __local 属性中,并定义了 _get_current_object() 方法获取当前线程或者协程对应的对象。
NOTE:前面双下划线的属性,会保存到 _ClassName__variable 中。所以这里通过 “_LocalProxy__local” 设置的值,后面可以通过 self.__local 来获取。关于这个知识点,可以查看 stackoverflow 的这个问题。
然后 LocalProxy 重写了所有的魔术方法(名字前后有两个下划线的方法),具体操作都是转发给代理对象的。这里只给出了几个魔术方法,感兴趣的可以查看源码中所有的魔术方法。
继续回到 request context 的实现:
|
1
2
3
|
_request_ctx_stack = LocalStack()request = LocalProxy(partial(_lookup_req_object, 'request'))session = LocalProxy(partial(_lookup_req_object, 'session')) |
再次看这段代码希望能看明白,_request_ctx_stack 是多线程或者协程隔离的栈结构,request每次都会调用 _lookup_req_object 栈头部的数据来获取保存在里面的 requst context。
那么请求上下文信息是什么被放在 stack 中呢?还记得之前介绍的 wsgi_app() 方法有下面两行代码吗?
|
1
2
|
ctx = self.request_context(environ)ctx.push() |
每次在调用 app.__call__ 的时候,都会把对应的请求信息压栈,最后执行完请求的处理之后把它出栈。
我们来看看request_context, 这个 方法只有一行代码:
|
1
2
|
def request_context(self, environ): return RequestContext(self, environ) |
它调用了 RequestContext,并把 self 和请求信息的字典 environ 当做参数传递进去。追踪到 RequestContext 定义的地方,它出现在 ctx.py 文件中,代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
|
class RequestContext(object): """The request context contains all request relevant information. It is created at the beginning of the request and pushed to the `_request_ctx_stack` and removed at the end of it. It will create the URL adapter and request object for the WSGI environment provided. """ def __init__(self, app, environ, request=None): self.app = app if request is None: request = app.request_class(environ) self.request = request self.url_adapter = app.create_url_adapter(self.request) self.match_request() def match_request(self): """Can be overridden by a subclass to hook into the matching of the request. """ try: url_rule, self.request.view_args = \ self.url_adapter.match(return_rule=True) self.request.url_rule = url_rule except HTTPException as e: self.request.routing_exception = e def push(self): """Binds the request context to the current context.""" # Before we push the request context we have to ensure that there # is an application context. app_ctx = _app_ctx_stack.top if app_ctx is None or app_ctx.app != self.app: app_ctx = self.app.app_context() app_ctx.push() self._implicit_app_ctx_stack.append(app_ctx) else: self._implicit_app_ctx_stack.append(None) _request_ctx_stack.push(self) self.session = self.app.open_session(self.request) if self.session is None: self.session = self.app.make_null_session() def pop(self, exc=_sentinel): """Pops the request context and unbinds it by doing that. This will also trigger the execution of functions registered by the :meth:`~flask.Flask.teardown_request` decorator. """ app_ctx = self._implicit_app_ctx_stack.pop() try: clear_request = False if not self._implicit_app_ctx_stack: self.app.do_teardown_request(exc) request_close = getattr(self.request, 'close', None) if request_close is not None: request_close() clear_request = True finally: rv = _request_ctx_stack.pop() # get rid of circular dependencies at the end of the request # so that we don't require the GC to be active. if clear_request: rv.request.environ['werkzeug.request'] = None # Get rid of the app as well if necessary. if app_ctx is not None: app_ctx.pop(exc) def auto_pop(self, exc): if self.request.environ.get('flask._preserve_context') or \ (exc is not None and self.app.preserve_context_on_exception): self.preserved = True self._preserved_exc = exc else: self.pop(exc) def __enter__(self): self.push() return self def __exit__(self, exc_type, exc_value, tb): self.auto_pop(exc_value) |
每个 request context 都保存了当前请求的信息,比如 request 对象和 app 对象。在初始化的最后,还调用了 match_request 实现了路由的匹配逻辑。
push 操作就是把该请求的 ApplicationContext(如果 _app_ctx_stack 栈顶不是当前请求所在 app ,需要创建新的 app context) 和 RequestContext 有关的信息保存到对应的栈上,压栈后还会保存 session 的信息; pop 则相反,把 request context 和 application context 出栈,做一些清理性的工作。
到这里,上下文的实现就比较清晰了:每次有请求过来的时候,flask 会先创建当前线程或者进程需要处理的两个重要上下文对象,把它们保存到隔离的栈里面,这样视图函数进行处理的时候就能直接从栈上获取这些信息。
NOTE:因为 app 实例只有一个,因此多个 request 共享了 application context。
到这里,关于 context 的实现和功能已经讲解得差不多了。还有两个疑惑没有解答。
- 为什么要把 request context 和 application context 分开?每个请求不是都同时拥有这两个上下文信息吗?
- 为什么 request context 和 application context 都有实现成栈的结构?每个请求难道会出现多个 request context 或者 application context 吗?
第一个答案是“灵活度”,第二个答案是“多 application”。虽然在实际运行中,每个请求对应一个 request context 和一个 application context,但是在测试或者 python shell 中运行的时候,用户可以单独创建 request context 或者 application context,这种灵活度方便用户的不同的使用场景;而且栈可以让 redirect 更容易实现,一个处理函数可以从栈中获取重定向路径的多个请求信息。application 设计成栈也是类似,测试的时候可以添加多个上下文,另外一个原因是 flask 可以多个 application 同时运行:
|
1
2
3
4
5
6
7
|
from werkzeug.wsgi import DispatcherMiddlewarefrom frontend_app import application as frontendfrom backend_app import application as backendapplication = DispatcherMiddleware(frontend, { '/backend': backend}) |
这个例子就是使用 werkzeug 的 DispatcherMiddleware 实现多个 app 的分发,这种情况下 _app_ctx_stack 栈里会出现两个 application context。
Update: 为什么要用 LocalProxy
为什么要使用 LocalProxy?不使用 LocalProxy 直接访问 LocalStack 的对象会有什么问题吗?
首先明确一点,Local 和 LocalStack 实现了不同线程/协程之间的数据隔离。在为什么用 LocalStack 而不是直接使用 Local 的时候,我们说过这是因为 flask 希望在测试或者开发的时候,允许多 app 、多 request 的情况。而 LocalProxy 也是因为这个才引入进来的!
我们拿 current_app = LocalProxy(_find_app) 来举例子。每次使用 current_app 的时候,他都会调用 _find_app 函数,然后对得到的变量进行操作。
如果直接使用 current_app = _find_app() 有什么区别呢?区别就在于,我们导入进来之后,current_app 就不会再变化了。如果有多 app 的情况,就会出现错误,比如:
|
1
2
3
4
5
6
7
8
9
10
|
from flask import current_appapp = create_app()admin_app = create_admin_app()def do_something(): with app.app_context(): work_on(current_app) with admin_app.app_context(): work_on(current_app) |
这里我们出现了嵌套的 app,每个 with 上下文都需要操作其对应的 app,如果不适用 LocalProxy 是做不到的。
对于 request 也是类似!但是这种情况真的很少发生,有必要费这么大的功夫增加这么多复杂度吗?
其实还有一个更大的问题,这个例子也可以看出来。比如我们知道 current_app 是动态的,因为它背后对应的栈会 push 和 pop 元素进去。那刚开始的时候,栈一定是空的,只有在 with app.app_context() 这句的时候,才把栈数据 push 进去。而如果不采用 LocalProxy 进行转发,那么在最上面导入 from flask import current_app 的时候,current_app 就是空的,因为这个时候还没有把数据 push 进去,后面调用的时候根本无法使用。
所以为什么需要 LocalProxy 呢?简单总结一句话:因为上下文保存的数据是保存在栈里的,并且会动态发生变化。如果不是动态地去访问,会造成数据访问异常。
Flask上下文流程
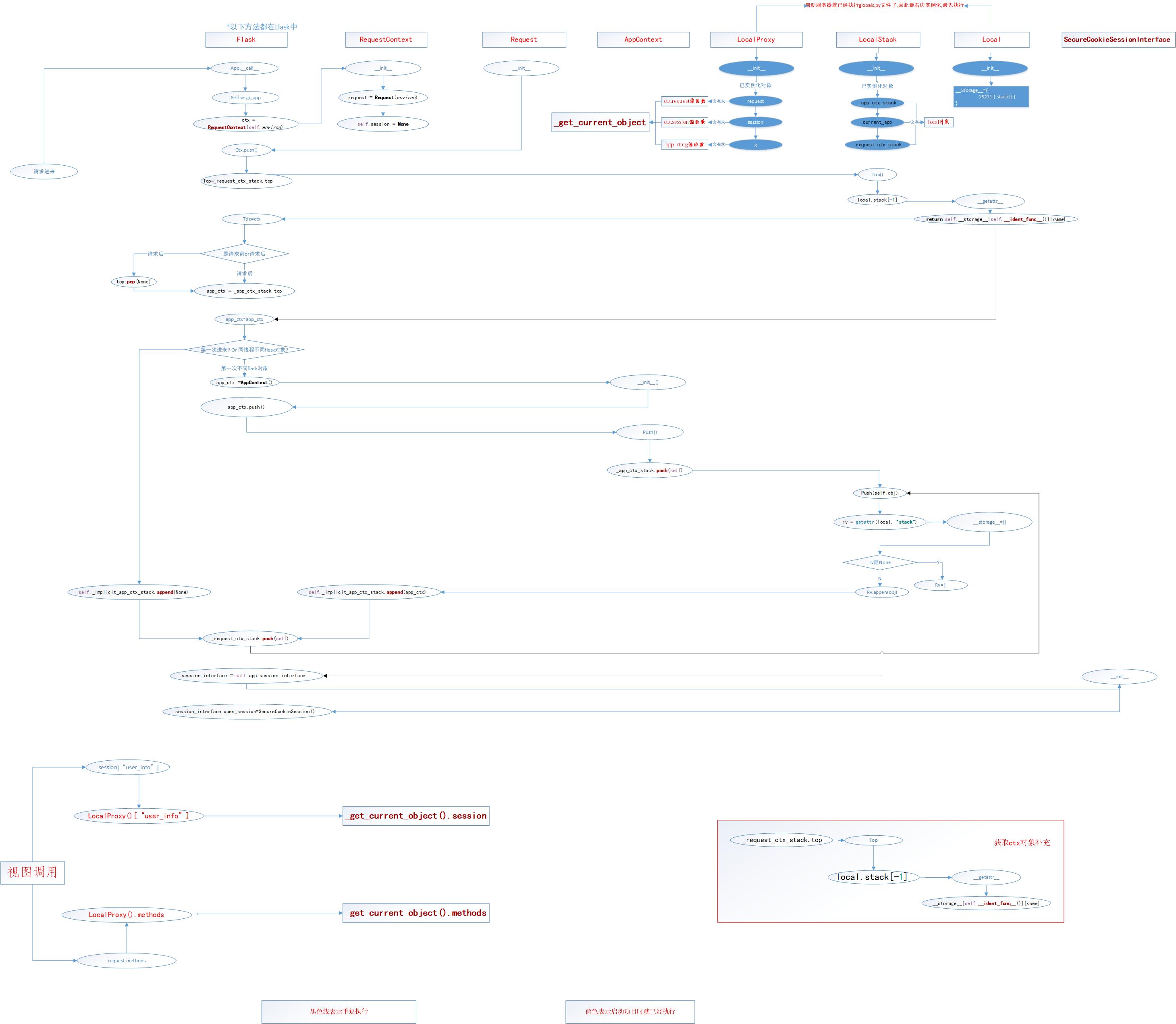
flask 源码解析:上下文(一)的更多相关文章
- flask源码解析之上下文为什么用栈
楔子 我在之前的文章<flask源码解析之上下文>中对flask上下文流程进行了详细的说明,但是在学习的过程中我一直在思考flask上下文中为什么要使用栈完成对请求上下文和应用上下文的入栈 ...
- flask源码解析之上下文
引入 对于flask而言,其请求过程与django有着截然不同的流程.在django中是将请求一步步封装最终传入视图函数的参数中,但是在flask中,视图函数中并没有请求参数,而是将请求通过上下文机制 ...
- Flask源码解析:Flask上下文
一.上下文(Context) 什么是上下文: 每一段程序都有很多外部变量.只有像Add这种简单的函数才是没有外部变量的.一旦你的一段程序有了外部变量,这段程序就不完整,不能独立运行.你为了使他们运行, ...
- Flask源码解析:Flask应用执行流程及原理
WSGI WSGI:全称是Web Server Gateway Interface,WSGI不是服务器,python模块,框架,API或者任何软件,只是一种规范,描述服务器端如何与web应用程序通信的 ...
- flask源码解析之session
内容回顾 cookie与session的区别: 1. session 是保存在服务端的键值对 2. cookie 只能保存4096个字节的数据,但是session不受限制 3. cookie保存在浏览 ...
- flask源码解析之DispatcherMiddleware
DispatcherMiddleware作用 实现多app的应用,完成路由分发的功能 如何使用 from werkzeug.wsgi import DispatcherMiddleware from ...
- 用尽洪荒之力学习Flask源码
WSGIapp.run()werkzeug@app.route('/')ContextLocalLocalStackLocalProxyContext CreateStack pushStack po ...
- Flask之 请求,应用 上下文源码解析
什么是上下文? 每一段程序都有很多外部变量.只有像Add这种简单的函数才是没有外部变量的.一旦你的一段程序有了外部变量,这段程序就不完整,不能独立运行.你为了使他们运行,就要给所有的外部变量一个一个写 ...
- flask 源码专题(二):请求上下文与全文上下文
源码解析 0. 请求入口 if __name__ == '__main__': app.run() def run(self, host=None, port=None, debug=None, lo ...
随机推荐
- 虚IP解决AlWaysON读库服务器过保替换
公司核心交易数据库,使用SQL 2012 AlWaysON的1主4从,有2台(8.14,8.15)从库服务器,已经使用3年多,过保替换,新买的2台服务器已经安装好,一开始方案如下: 服务器(8.14) ...
- Day004_Linux基础_基础命令之tar打包解包
基础命令之 打包,和解包. tar zcvf 打包的参数 tar zcvf /tmp/etc.tar.gz /etc 将/etc/下的文件压缩成一个压缩包 z 通过gzip工具进行压缩 c 表示 ...
- Redis的那些最常见面试问题(转)
Redis的那些最常见面试问题 1.什么是redis? Redis 是一个基于内存的高性能key-value数据库. 2.Reids的特点 Redis本质上是一个Key-Value类型 ...
- 史上最全面的SignalR系列教程-目录汇总
1.引言 最遗憾的不是把理想丢在路上,而是理想从未上路. 每一个将想法变成现实的人,都值得称赞和学习. 致正在奔跑的您! 2.SignalR介绍 SignalR实现服务器与客户端的实时通信 ,她是一个 ...
- php文件加密解密
利用base64加解密 base64_encode是加密,而base64_decode是解密 语法:string base64_encode(string data); 语法:string bas ...
- 可见性有序性,Happens-before来搞定
写在前面 上一篇文章并发 Bug 之源有三,请睁大眼睛看清它们 谈到了可见性/原子性/有序性三个问题,这些问题通常违背我们的直觉和思考模式,也就导致了很多并发 Bug 为了解决 CPU,内存,IO 的 ...
- 【学习笔记】第三章 python3核心技术与实践--Jupyter Notebook
可能你已经知道,Python 在 14 年后的“崛起”,得益于机器学习和数学统计应用的兴起.那为什么 Python 如此适合数学统计和机器学习呢?作为“老司机”的我可以肯定地告诉你,Jupyter N ...
- Qt线程实现分析-moveToThread vs 继承
最近抽空研究了下QThread,使用起来方式多种多样,但是在使用的同时,我们也应该去了解Qt的线程它到底是怎么玩儿的. Qt的帮助文档里讲述了2种QThread的使用方式,一种是moveToThrea ...
- 【Jenkins持续集成(二)】Windows上安装Jenkins教程
一.前言 Jenkins是一款开源 CI&CD 软件,用于自动化各种任务,包括构建.测试和部署软件. Jenkins 支持各种运行方式,可通过系统包.Docker 或者通过一个独立的 Java ...
- Apache Hadoop集群安装(NameNode HA + YARN HA + SPARK + 机架感知)
1.主机规划 序号 主机名 IP地址 角色 1 nn-1 192.168.9.21 NameNode.mr-jobhistory.zookeeper.JournalNode 2 nn-2 192.16 ...