利用HtmlAgilityPack插件写的一个抓取指定网页的图片 第一次写 很乱 随便看看就行
public partial class Form1 : Form
{
/// <summary>
/// 存放图片地址
/// </summary>
List<string> ImgList = new List<string>();
/// <summary>
/// 当前下载文件
/// </summary>
int _loadFile = 0;
//图片标题
string title = "";
/// <summary>
/// 文件总数
/// </summary>
int _totalFile = 0;
string[] exts = {
".bmp", ".dib", ".jpg", ".jpeg",
".jpe", ".jfif", ".png", ".gif",
".tif", ".tiff" };
public Form1()
{
InitializeComponent();
Control.CheckForIllegalCrossThreadCalls = false;
}
private void Form1_Load(object sender, EventArgs e)
{
this.comboBoxEdit1.Properties.Items.Add("UTF-8");
this.comboBoxEdit1.Properties.Items.Add("GB2312");
}
/// <summary>
/// 获取当前页面图片数量
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void button1_Click(object sender, EventArgs e)
{
getImgs();
}
/// <summary>
/// 下载图片
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void button2_Click(object sender, EventArgs e)
{
try
{
this.textBox1.Clear();
if (ImgList.Count <= 0) return;
//重置加载文件数
_loadFile = 0;
int index = 1;
Task.Factory.StartNew(() =>
{
foreach (var item in ImgList)
{
WebClient webClient = new WebClient();
webClient.DownloadProgressChanged += new DownloadProgressChangedEventHandler(webClient_DownloadProgressChanged);
webClient.DownloadFileCompleted += new AsyncCompletedEventHandler(webClient_DownloadFileCompleted);
webClient.Proxy = null;
Uri uri = new Uri(item);
if (!Directory.Exists(System.Environment.CurrentDirectory + "\\Img"))
{
Directory.CreateDirectory(System.Environment.CurrentDirectory + "\\Img");
}
var imghouzhui = item.Substring(item.LastIndexOf(".")).Substring(0, 4);
string fileName = title == "" ? Guid.NewGuid().ToString() : title + "_" + index + imghouzhui;
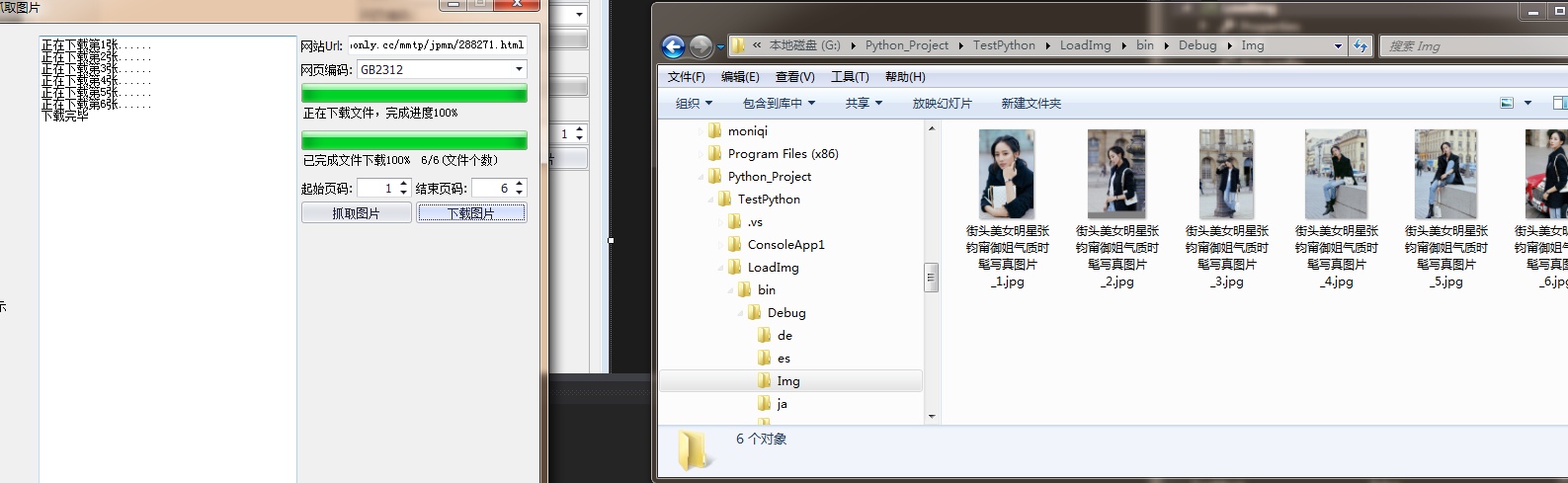
webClient.DownloadFileAsync(uri, System.Environment.CurrentDirectory + "\\Img\\" + fileName);
index++;
}
});
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
}
/// <summary>
/// 下载文件进度条
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void webClient_DownloadProgressChanged(object sender, DownloadProgressChangedEventArgs e)
{
this.Invoke(new MethodInvoker(delegate
{
this.progressBar2.Value = e.ProgressPercentage;
this.label2.Text = string.Format("正在下载文件,完成进度{0}% {1}/{2}(字节)"
, e.ProgressPercentage
, e.BytesReceived
, e.TotalBytesToReceive);
}));
}
/// <summary>
/// 抓取https://www.mntup.com/网站写真
/// </summary>
public void getImgs()
{
this.textBox1.Clear();
this.progressBar1.Value = 0;
this.progressBar2.Value = 0;
this.label2.Text = "单个文件进度:";
this.label1.Text = "总进度:";
ImgList.Clear();
HtmlWeb htmlWeb = new HtmlWeb();
if (textBox2.Text.Trim().Length <= 0 || comboBoxEdit1.SelectedText == "")
{
return;
}
try
{
htmlWeb.OverrideEncoding = Encoding.GetEncoding(comboBoxEdit1.SelectedText.ToString());
int pageMinIndex = Convert.ToInt32(pageMin.Value);
int pageMaxIndex = Convert.ToInt32(pageMax.Value);
this.textBox1.AppendText("抓取到的图片地址");
for (int i = pageMinIndex; i <= pageMaxIndex; i++)
{
string url = this.textBox2.Text.Trim().ToString();
if (i >= 2)
{
url = url.Substring(0, url.LastIndexOf(".")).ToString() + "_" + i + ".html";
}
HtmlAgilityPack.HtmlDocument htmlDocument = htmlWeb.Load(url);
//if (htmlDocument.DocumentNode.InnerText.Contains("未找到")) return;
////*[@id="big-pic"]
HtmlNodeCollection nodes = null;
if (url.Contains("https://www.mntup.com"))
{
title = htmlDocument.DocumentNode.SelectSingleNode("//div[@class='title']").InnerText;
nodes = htmlDocument.DocumentNode.SelectNodes("//img");
}
else if (url.StartsWith("http://www.mmonly.cc", StringComparison.OrdinalIgnoreCase))
{
title = htmlDocument.DocumentNode.SelectSingleNode("//h1").InnerText.Substring(0, htmlDocument.DocumentNode.SelectSingleNode("//h1").InnerText.Length - 5);
nodes = htmlDocument.DocumentNode.SelectNodes("//div[@id='big-pic']//img");
}
else
{
title = htmlDocument.DocumentNode.SelectSingleNode("//div[@class='title']")?.InnerText;
nodes = htmlDocument.DocumentNode.SelectNodes("//img");
}
bool flag2 = nodes == null || nodes.Count <= 0;
if (flag2)
{
MessageBox.Show($@"当前页{i}未找到图片,或没有第{i}页");
ImgList.Clear();
textBox1.Clear();
return;
}
int index = this.textBox2.Text.Trim().IndexOf(".com");
string urls = this.textBox2.Text.Trim().ToString().Substring(0, 21);
foreach (HtmlNode item in nodes)
{
//https://www.mntup.com/YouMi/zhangyumeng_38bebee5.html
string houzui = item.Attributes["src"]?.Value;
if (string.IsNullOrEmpty(houzui)) continue;
houzui = houzui.Substring(houzui.LastIndexOf("."), 4);
if (houzui != ".jpg")
{
continue;
};
string imgurl = "";
if (!item.Attributes["src"].Value.StartsWith("http") &&
!item.Attributes["src"].Value.StartsWith("https"))
{
imgurl = urls + item.Attributes["src"].Value;
}
else
{
imgurl = item.Attributes["src"].Value;
}
this.textBox1.AppendText(imgurl + "\r\n");
this.ImgList.Add(imgurl);
}
}
//ImgList = ImgList.Distinct().ToList();
this._totalFile = ImgList.Count;
this.textBox1.AppendText("总共获取图片" + ImgList.Count);
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
return;
}
}
/// <summary>
/// 文件下载时事件
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void webClient_DownloadFileCompleted(object sender, AsyncCompletedEventArgs e)
{
//https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111111&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E8%90%9D%E8%8E%89&oq=%E8%90%9D%E8%8E%89&rsp=-1
_loadFile++;
int percent = (int)(100.0 * _loadFile / _totalFile);
this.Invoke(new MethodInvoker(delegate
{
this.progressBar1.Value = percent;
this.label1.Text = string.Format("已完成文件下载{0}% {1}/{2}(文件个数)"
, percent
, _loadFile
, _totalFile);
}));
this.textBox1.Invoke(new Action(() =>
{
textBox1.AppendText($"正在下载第{_loadFile}张......\r\n");
}));
if (sender is WebClient)
{
((WebClient)sender).CancelAsync();
((WebClient)sender).Dispose();
}
if (percent == 100)
{
this.textBox1.Invoke(new Action(() =>
{
this.textBox1.AppendText("下载完毕");
}));
}
}
}
利用HtmlAgilityPack插件写的一个抓取指定网页的图片 第一次写 很乱 随便看看就行的更多相关文章
- 利用python脚本(re)抓取美空mm图片
很久没有写博客了,这段时间一直在搞风控的东西,过段时间我把风控的内容整理整理发出来大家一起研究研究. 这两天抽空写了两个python爬虫脚本,一个使用re,一个使用xpath. 直接上代码——基于re ...
- 利用HtmlAgilityPack库进行HTML数据抓取
主要介绍基于XPATH的文本分析方式的实现,代码如下: using System; using System.Collections.Generic; using System.Linq; using ...
- 利用python脚本(xpath)抓取数据
有人会问re和xpath是什么关系?如果你了解js与jquery,那么这个就很好理解了. 上一篇:利用python脚本(re)抓取美空mm图片 # -*- coding:utf-8 -*- from ...
- 微信朋友圈转疯了(golang写小爬虫抓取朋友圈文章)
很多人在朋友圈里转发一些文章,标题都是什么转疯啦之类,虽然大多都也是广告啦,我觉得还蛮无聊的,但是的确是有一些文章是非常值得收藏的,比如老婆经常就会收藏一些养生和美容的文章在微信里看. 今天就突发奇想 ...
- 利用wget 抓取 网站网页 包括css背景图片
利用wget 抓取 网站网页 包括css背景图片 wget是一款非常优秀的http/ftp下载工具,它功能强大,而且几乎所有的unix系统上都有.不过用它来dump比较现代的网站会有一个问题:不支持c ...
- 30分钟编写一个抓取 Unsplash 图片的 Python爬虫
我一直想用 Python and Selenium 创建一个网页爬虫,但从来没有实现它. 几天前, 我决定尝试一下,这听起来可能是挺复杂的, 然而编写代码从 Unsplash 抓取一些美丽的图片 ...
- fiddler4如何只抓取指定浏览器的包
在实际工作中,常常会抓取浏览器的数据,其加载的数据较多,不好区分,不知道其是哪个是需要抓取的数据,所以就需抓取指定浏览器的数据,这样就能很清晰知道数据的来源. 步骤一: 打开fiddler4,再打开浏 ...
- python网络爬虫抓取动态网页并将数据存入数据库MySQL
简述以下的代码是使用python实现的网络爬虫,抓取动态网页 http://hb.qq.com/baoliao/ .此网页中的最新.精华下面的内容是由JavaScript动态生成的.审查网页元素与网页 ...
- 下载远程(第三方服务器)文件、图片,保存到本地(服务器)的方法、保存抓取远程文件、图片 将图片的二进制字节字符串在HTML页面以图片形式输出 asp.net 文件 操作方法
下载远程(第三方服务器)文件.图片,保存到本地(服务器)的方法.保存抓取远程文件.图片 将一台服务器的文件.图片,保存(下载)到另外一台服务器进行保存的方法: 1 #region 图片下载 2 3 ...
随机推荐
- C#读取文件夹特定文件的方法
public image[] getImages() { FolderBrowserDialog fbd = new FolderBrowserDialog(); if (fbd.ShowDialog ...
- ASP .NET Response类型
.ContentType .htm,.html Response.ContentType = "text/HTML"; .txt Response.ContentType= &qu ...
- 【python】python调用adb
本期分享下python如何调用adb: 1.导入os模块 import os 2.python中调用adb命令语法 print("显示机型信息:") os.system('adb ...
- UBUNTU 16.04 + CUDA8.0 + CUDNN6.0 + OPENCV3.2 + MKL +CAFFE + tensorflow
首先说一下自己机子的配置 CPU:Intel(R) Core(TM) i5-5600 CUP @3.20GHz *4 GPU : GTX 1060 OS : 64bit Ubuntu16.04LTS ...
- C++虚函数表解析(图文并茂,非常清楚)( 任何妄图使用父类指针想调用子类中的未覆盖父类的成员函数的行为都会被编译器视为非法)good
C++中的虚函数的作用主要是实现了多态的机制.关于多态,简而言之就是用父类型别的指针指向其子类的实例,然后通过父类的指针调用实际子类的成员函数.这种技术可以让父类的指针有“多种形态”,这是一种泛型技术 ...
- qt 维护x86和arm两套编译环境
1.中间库: 中间库都放在middlewares目录,include头文件相同,所以不需要特殊处理,只要特殊处理lib安装目录, 示例pro文件如下: TEMPLATE = lib TARGET = ...
- Qt+QZXing编写识别二维码的程序
本人最近在用Qt编写程序,需要用编写二维码识别功能.在网上搜寻一番,找到了QZXing.配置过程中确实出了一大把汗,这里我写这篇文章记录配置方法,替后人省一把汗吧!我的开发环境:MSVC2010 + ...
- 浅谈网络爬虫爬js动态加载网页(一)
由于别的项目组在做舆情的预言项目,我手头正好没有什么项目,突然心血来潮想研究一下爬虫.分析的简单原型.网上查查这方面的资料还真是多,眼睛都看花了.搜了搜对于我这种新手来说,想做一个简单的爬虫程序,所以 ...
- Bitmap的读写和几个小儿科的滤镜效果~
闲来玩玩图像处理,拿破仑说过:“不想自己实现滤镜的美工不是好程序员~~#@!*^...#&!@......” 因为在学校做过很多美工的工作,而且从小就喜欢画画所以对图像相关的东西都还比较感兴 ...
- kafka设计原理(转)
一.kafka简介 1.1 背景历史 当今社会各种应用系统,诸如商业.社交.搜索.浏览等信息工厂一样不断被生产出各种信息,在大数据时代,我们面临如下几个挑战: 如何收集这些巨大的信息 如何分析它 如何 ...