微服务-springboot-读写分离(多数据源切换)
为什么需要读写分离
当项目越来越大和并发越来大的情况下,单个数据库服务器的压力肯定也是越来越大,最终演变成数据库成为性能的瓶颈,而且当数据越来越多时,查询也更加耗费时间,当然数据库数据过大时,可以采用数据库分库分表,同时数据库压力过大时,也可以采用Redis等缓存技术来降低压力,但是任何一种技术都不是万金油,很多时候都是通过多种技术搭配使用,而本文主要就是介绍通过读写分离来加快数据库读取速度
实现方式
读写分离实现的方式有多种,但是多种都需要配置数据库的主从复制
方式一
数据库中间件实现,如Mycat等数据库中间件,对于项目本身来说,只有一个数据源,就是链接到Mycat,再由mycat根据规则去选择从哪个库获取数据
方式二
代码中配置多数据源,通过代码控制使用哪个数据源,本文也是主要介绍这种方式
优点
1.降低数据库读取压力,尤其是有些需要大量计算的实时报表类应用
2.增强数据安全性,读写分离有个好处就是数据近乎实时备份,一旦某台服务器硬盘发生了损坏,从库的数据可以无限接近主库
3.可以实现高可用,当然只是配置了读写分离并不能实现搞可用,最多就是在Master(主库)宕机了还能进行查询操作,具体高可用还需要其他操作
缺点
1.增大成本,一台数据库服务器和多台数据库的成本肯定是不一样的
2.增大代码复杂度,不过这点还比较轻微吧,但是也的确会一定程度上加重
3.增大写入成本,虽然降低了读取成本,但是写入成本却是一点也没有降低,毕竟还有从库一直在向主库请求数据
实践:
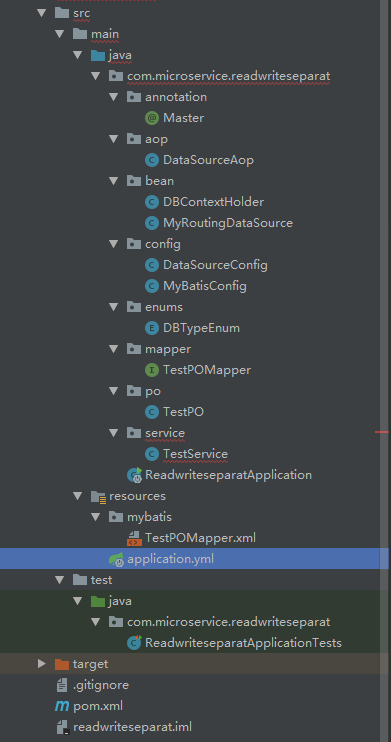
项目结构:
application.yml
spring:
datasource:
master: # 写账户
jdbc-url: jdbc:mysql://localhost:3306/otadb?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false
username: root
password: 123456
slave1: # 只读账户
jdbc-url: jdbc:mysql://localhost:3306/otadb1?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false
username: root
password: 123456
slave2: # 只读账户
jdbc-url: jdbc:mysql://localhost:3306/otadb2?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false
username: root
password: 123456
多数据源配置
import com.microservice.readwriteseparat.bean.MyRoutingDataSource;
import com.microservice.readwriteseparat.enums.DBTypeEnum;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.jdbc.DataSourceBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration; import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map; @Configuration
public class DataSourceConfig { /**
* 写库
* @return
*/
@Bean
@ConfigurationProperties("spring.datasource.master")
public DataSource masterDataSource() {
return DataSourceBuilder.create().build();
} /**
* 读库
* @return
*/
@Bean
@ConfigurationProperties("spring.datasource.slave1")
public DataSource slave1DataSource() {
return DataSourceBuilder.create().build();
} /**
* 读库
* @return
*/
@Bean
@ConfigurationProperties("spring.datasource.slave2")
public DataSource slave2DataSource() {
return DataSourceBuilder.create().build();
} @Bean
public DataSource myRoutingDataSource(@Qualifier("masterDataSource") DataSource masterDataSource,
@Qualifier("slave1DataSource") DataSource slave1DataSource,
@Qualifier("slave2DataSource") DataSource slave2DataSource) {
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DBTypeEnum.MASTER, masterDataSource);
targetDataSources.put(DBTypeEnum.SLAVE1, slave1DataSource);
targetDataSources.put(DBTypeEnum.SLAVE2, slave2DataSource);
MyRoutingDataSource myRoutingDataSource = new MyRoutingDataSource();
myRoutingDataSource.setDefaultTargetDataSource(masterDataSource);
myRoutingDataSource.setTargetDataSources(targetDataSources);
return myRoutingDataSource;
} }
这里,我们配置了4个数据源,1个master,2两个slave,1个路由数据源。前3个数据源都是为了生成第4个数据源,而且后续我们只用这最后一个路由数据源myRoutingDataSource。
MyBatis配置
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.transaction.PlatformTransactionManager;
import org.springframework.transaction.annotation.EnableTransactionManagement; import javax.annotation.Resource;
import javax.sql.DataSource; @EnableTransactionManagement
@Configuration
public class MyBatisConfig {
@Resource(name = "myRoutingDataSource")
private DataSource myRoutingDataSource; /**
* 扫描mybatis下的xml文件
* @return
* @throws Exception
*/
@Bean
public SqlSessionFactory sqlSessionFactory() throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(myRoutingDataSource);
sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mybatis/*.xml"));
return sqlSessionFactoryBean.getObject();
} @Bean
public PlatformTransactionManager platformTransactionManager() {
return new DataSourceTransactionManager(myRoutingDataSource);//由于Spring容器中现在有4个数据源,所以我们需要为事务管理器和MyBatis手动指定一个明确的数据源。
}
}
定义一个枚举来代表这三个数据源
public enum DBTypeEnum {
MASTER,SLAVE1,SLAVE2
}
通过ThreadLocal将数据源设置到每个线程上下文中
import com.microservice.readwriteseparat.enums.DBTypeEnum;
import java.util.concurrent.atomic.AtomicInteger;
public class DBContextHolder {
private static final ThreadLocal<DBTypeEnum> contextHolder = new ThreadLocal<>();
private static final AtomicInteger counter = new AtomicInteger(-1);
public static void set(DBTypeEnum dbType) {
contextHolder.set(dbType);
}
public static DBTypeEnum get() {
return contextHolder.get();
}
public static void master() {
set(DBTypeEnum.MASTER);
System.out.println("切换到master");
}
public static void slave() {
// 轮询
int index = counter.getAndIncrement() % 2;
if (counter.get() > 9999) {
counter.set(-1);
}
if (index == 0) {
set(DBTypeEnum.SLAVE1);
System.out.println("切换到slave1");
}else {
set(DBTypeEnum.SLAVE2);
System.out.println("切换到slave2");
}
}
}
获取路由key
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
import org.springframework.lang.Nullable; public class MyRoutingDataSource extends AbstractRoutingDataSource {
@Nullable
@Override
protected Object determineCurrentLookupKey() {
return DBContextHolder.get();
}
}
默认情况下,所有的查询都走从库,插入/修改/删除走主库。我们通过方法名来区分操作类型(CRUD)
import com.microservice.readwriteseparat.bean.DBContextHolder;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.stereotype.Component; @Aspect
@Component
public class DataSourceAop {
/**
* 只读:
* 不是Master注解的对象或方法 && select开头的方法 || get开头的方法
*/
@Pointcut("!@annotation(com.microservice.readwriteseparat.annotation.Master) " +
"&& (execution(* com.microservice.readwriteseparat.service..*.select*(..)) " +
"|| execution(* com.microservice.readwriteseparat.service..*.get*(..)))")
public void readPointcut() { } /**
* 写:
* Master注解的对象或方法 || insert开头的方法 || add开头的方法 || update开头的方法
* || edlt开头的方法 || delete开头的方法 || remove开头的方法
*/
@Pointcut("@annotation(com.microservice.readwriteseparat.annotation.Master) " +
"|| execution(* com.microservice.readwriteseparat.service..*.insert*(..)) " +
"|| execution(* com.microservice.readwriteseparat.service..*.add*(..)) " +
"|| execution(* com.microservice.readwriteseparat.service..*.update*(..)) " +
"|| execution(* com.microservice.readwriteseparat.service..*.edit*(..)) " +
"|| execution(* com.microservice.readwriteseparat.service..*.delete*(..)) " +
"|| execution(* com.microservice.readwriteseparat..*.remove*(..))")
public void writePointcut() { } @Before("readPointcut()")
public void read() {
DBContextHolder.slave();
} @Before("writePointcut()")
public void write() {
DBContextHolder.master();
}
}
有一般情况就有特殊情况,特殊情况是某些情况下我们需要强制读主库,针对这种情况,我们定义一个主键,用该注解标注的就读主库
public @interface Master {
}
mapper:
import com.microservice.readwriteseparat.po.TestPO;
import org.apache.ibatis.annotations.Mapper; @Mapper
public interface TestPOMapper {
int deleteByPrimaryKey(Long id); int insert(TestPO record); int insertSelective(TestPO record); TestPO selectByPrimaryKey(Long id); int updateByPrimaryKeySelective(TestPO record); int updateByPrimaryKey(TestPO record);
}
po:
public class TestPO {
private Long id;
private String name;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name == null ? null : name.trim();
}
}
service:
import com.microservice.readwriteseparat.annotation.Master;
import com.microservice.readwriteseparat.mapper.TestPOMapper;
import com.microservice.readwriteseparat.po.TestPO;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service; @Service
public class TestService{ @Autowired
private TestPOMapper testPOMapper; public int insert(TestPO aaa) {
return testPOMapper.insert(aaa);
} @Master
public int save(TestPO aaa) {
return testPOMapper.insert(aaa);
} public TestPO selectByPrimaryKey(Long id) {
return testPOMapper.selectByPrimaryKey(id);
} @Master
public TestPO getById(Long id) {
// 有些读操作必须读主数据库
// 比如,获取微信access_token,因为高峰时期主从同步可能延迟
// 这种情况下就必须强制从主数据读
return testPOMapper.selectByPrimaryKey(id);
}
}
测试:
import com.microservice.readwriteseparat.po.TestPO;
import com.microservice.readwriteseparat.service.TestService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner; @RunWith(SpringRunner.class)
@SpringBootTest
public class ReadwriteseparatApplicationTests {
private static final Logger logger = LoggerFactory.getLogger(ReadwriteseparatApplicationTests.class); @Autowired
private TestService aaaService; /**
* 写库进行写入
*/
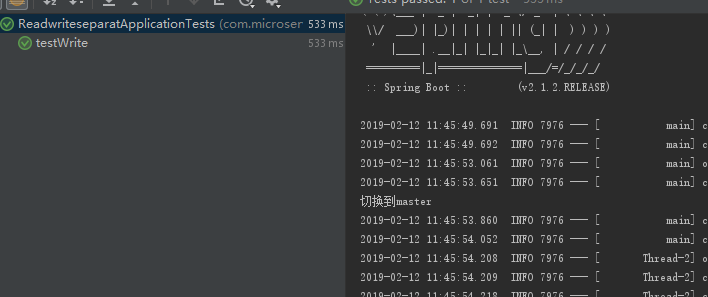
@Test
public void testWrite() {
TestPO aaa = new TestPO();
aaaService.insert(aaa);
} /**
* 读库(otadb1和otadb2随机)进行读取
*/
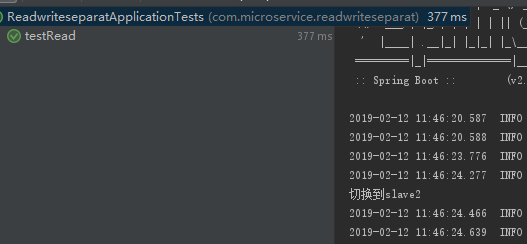
@Test
public void testRead() {
TestPO aaa = aaaService.selectByPrimaryKey(1l);
logger.info("aaa="+aaa.toString());
} /**
* 写库进行写入
*/
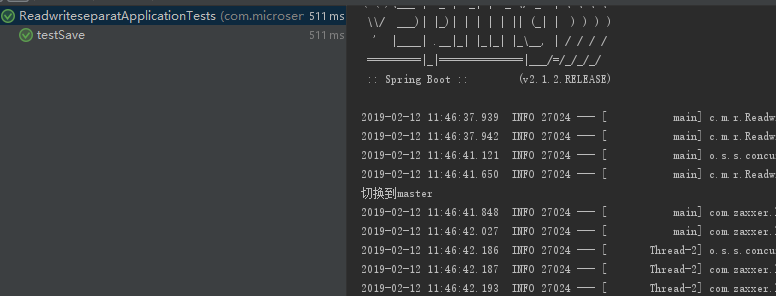
@Test
public void testSave() {
TestPO aaa = new TestPO();
aaaService.save(aaa);
} /**
* 写库进行读取
*/
@Test
public void testReadFromMaster() {
aaaService.getById(10001l);
} }
查看控制台:
源码地址:https://github.com/qjm201000/micro_service_readwriteseparat.git
参考资料:https://www.cnblogs.com/cjsblog/p/9712457.html
微服务-springboot-读写分离(多数据源切换)的更多相关文章
- Mycat读写分离、主从切换、分库分表的操作记录
系统开发中,数据库是非常重要的一个点.除了程序的本身的优化,如:SQL语句优化.代码优化,数据库的处理本身优化也是非常重要的.主从.热备.分表分库等都是系统发展迟早会遇到的技术问题问题.Mycat是一 ...
- mycat读写分离与主从切换【转】
什么是mycat,以及mycat的优点和特性本文不做赘述,本文继续本着实战的态度,来分享一些个人对mycat的基础功能实践.本文mycat的读写分离和主从切换的环境为mysql主从环境. 如何安装my ...
- Mycat读写分离、主从切换学习(转)
http://blog.csdn.net/zhanglei_16/article/details/50707487 Mycat读写分离.主从切换学习问题一:分表.分库的优缺点,以及分表无法成为主流分表 ...
- SpringBoot与动态多数据源切换
本文简单的介绍一下基于SpringBoot框架动态多数据源切换的实现,采用主从配置的方式,配置master.slave两个数据库. 一.配置主从数据库 spring: datasource: ty ...
- springcloud vue.js 微服务分布式 前后分离 集成代码生成器 shiro权限 activiti工作流
1.代码生成器: [正反双向](单表.主表.明细表.树形表,快速开发利器)freemaker模版技术 ,0个代码不用写,生成完整的一个模块,带页面.建表sql脚本.处理类.service等完整模块2. ...
- Spring AOP /代理模式/事务管理/读写分离/多数据源管理
参考文章: http://www.cnblogs.com/MOBIN/p/5597215.html http://www.cnblogs.com/fenglie/articles/4097759.ht ...
- redis的主从复制,读写分离,主从切换
当数据量变得庞大的时候,读写分离还是很有必要的.同时避免一个redis服务宕机,导致应用宕机的情况,我们启用sentinel(哨兵)服务,实现主从切换的功能. redis提供了一个master,多个s ...
- Redis哨兵模式(sentinel)学习总结及部署记录(主从复制、读写分离、主从切换)
Redis的集群方案大致有三种:1)redis cluster集群方案:2)master/slave主从方案:3)哨兵模式来进行主从替换以及故障恢复. 一.sentinel哨兵模式介绍Sentinel ...
- mycat 1.6.6.1安装以及配置docker 安装mysql 5.7.24 双主多从读写分离主主切换
mycat和mysql的高可用参考如下两个图 简介:应用程序仅需要连接HAproxy或者mycat,后端服务器的读写分离由mycat进行控制,后端服务器数据的同步由MySQL主从同步进行控制. 服务器 ...
随机推荐
- WPF Path实现虚线流动效果
原文:WPF Path实现虚线流动效果 最近闲来无事,每天上上网,看看博客生活也过得惬意,这下老总看不过去了,给我一个任务,叫我用WPF实现虚线流动效果,我想想,不就是虚线流动嘛,这简单于是就答应下来 ...
- Painting and Drawing[MSDN/Windows GDI]
https://msdn.microsoft.com/en-us/library/dd162759(v=vs.85).aspx Painting and Drawing This overview d ...
- ArcGIS Runtime SDK for WPF 初始化
安装包 管理nuget包 Esri.ArcGISRuntime.WPF 也许还需要 Esri.ArcGISRuntime.Hydrography Esri.ArcGISRuntime.LocalSer ...
- SQL基础 关键字
SQL语言类型 数据定义:create/alter/drop table/trigger/index/function/存储过程/约束/…数据操纵:select/update/insert/delet ...
- 使注解@ContextConfiguration同时支持locations和classes
@Configuration @ImportResource("classpath:META-INF/dataContext.xml") class TestConfig { } ...
- php将秒转换为 分:秒 函数
php将秒转换为 分:秒 函数 /** * 将秒转换为 分:秒 * s int 秒数 */ function s_to_hs($s=0){ //计算分钟 //算法:将秒数除以60,然后下舍入,既得到分 ...
- ELINK离线编程器版本说明
ELINK离线编程器版本详情,ELinkPROG版本与固件版本须匹配使用! 编程器支持芯片详细列表参见 https://www.cnblogs.com/raswin/p/9303300.html
- 一款好用的视频转换gif的小软件——抠抠视频秀
在平常生活中,我们拍下来精彩的视频想要转换为gif动画,或是想要录制网页上的视频.电脑上的鼠标操作等等,大家可以使用以下这款很好用的视频转换gif的小软件——抠抠视频秀,这个软件操作简单 ...
- 《芒果TV》UWP版利用Windows10通用平台特性,率先支持Xbox One平台
在Windows开发者中心开放提交Xbox平台应用之后,<芒果TV>UWP版迅速更新v3.1.2版,通过升级兼容目标,利用Windows10通用平台特性,率先覆盖Xbox平台用户. 芒果T ...
- API HOOK介绍 【转】
什么是“跨进程 API Hook”? 众所周知Windows应用程序的各种系统功能是通过调用API函数来实现.API Hook就是给系统的API附加上一段小程序,它能监视甚至控制应用程序对API函数的 ...