Redis面试热点之底层实现篇(续)
0.题外话
接着昨天的【决战西二旗】|Redis面试热点之底层实现篇继续来了解一下ziplist压缩列表这个数据结构。
你可能会抱有疑问:我只是使用Redis的功能并且公司的运维同事都已经搭建好了平台,只需要在线申请一下配置和获取连接的地址就可以愉快地使用了,为啥还要这么深入的理解底层的数据结构呢?有啥用呢?
其实这个问题可以分几个方面去回答吧,笔者试着去解释一下原因:
- 好奇心 作为技术人员,没有好奇心会让我们错过很多精彩,难道你对如此强悍的NoSQL是如何跑起来的不感兴趣吗?好奇心让我们知道的更多,也让我们不知道的更多;
- 辩证的职业素养 无论是996还是快速迭代,让很多人陷入了网上找找、github找找、改改、跑起来万事大吉的循环,但是这种确实是温水煮青蛙,长此以往我们将渐渐失去判断力,再者国内的文章或者技术点说明基本上都是抄来抄去,没有好的鉴别能力往往就走很多弯路,在这个过程中职业素养就显得意义重大,算是比较核心的竞争力了;
- 善于思考的习惯 个人认为了解源码的一个好处是能对其中的原理有一定认识,不至于完全黑盒子一样使用,调包Boy或者API工程师往往在遇到一些问题是束手无策,因为不知道是什么原因造成的。更重要的一个好处在于对源码的学习本质上是相同问题的迁移,换句话说,我们有时候抱怨自己接触不到高难度的项目,无法快速提高自己的能力,但是个人觉得如果能力不够给你高难度项目只能让你失眠,因为当没有可借鉴可参考的过往项目时会让你束手无策,因为从0-1做一个好项目的能力不是一天养成的。深入研究开源工程的实现细节能让我们置身相同的境况来思考问题,假如自己被指定去完成该任务,那么要如何实现呢?
- 胸有成竹的能力 我们有个成语叫庖丁解牛,就是说我们掌握了事物的客观规律,就能运用自如。经验丰富的人在拿到一个任务之后,脑海里便可以浮现出这个任务需要被拆解成几部分,设计的重难点是什么,其中可能出现的坑是什么,需要使用哪些方法来解决特殊的问题,个人感觉阅读源码可以让你慢慢获得这种能力,试想你和大师面对一样的问题,你先深入思考如何去做,然后再仔细研究大师的方案,久而久之自己的功力也必然会提升,我觉得这也是研究开源工程源码最重要的原因。
说了这么多,无非是想表达,带着思考去学习,受益的必然是你自己,大的方针政策是正确的,剩下的就是一步步去执行了,源码工程千千万,那也不必着急,核心的思想并没有那么多,怕什么真理无穷,进一寸有一寸的欢喜!
Q6:Redis的ziplist是如何实现的?压缩列表的连锁更新的原因了解吗?
前面的文章介绍了zset和hash在数据量少且长度满足一定条件的基础上就会选择使用ziplist来进行存储。
当然后面antirez又推出了quicklist的结构,后续可以聊聊quicklist,不过快速链表也是基于压缩列表实现的,ziplist是一种使用特殊编码的内存连续型的数据结构,让我们来一起揭开ziplist的神秘面纱吧。
1.如何设计ziplist
先不看Redis的对ziplist的具体实现,我们先来想一下如果我们来设计这个数据结构需要做哪些方面的考虑呢?思考式地学习收获更大呦!
- 考虑点1:连续内存的双面性
连续型内存减少了内存碎片,但是连续大内存又不容易满足。
这个非常好理解,你和好基友三人去做地铁,你们三个挨着坐肯定不浪费空间,但是地铁里很多人都是单独出行的,大家都不愿意紧挨着,就这样有2个的位置有1个的位置,可是3个连续的确实不好找呀,来张图:
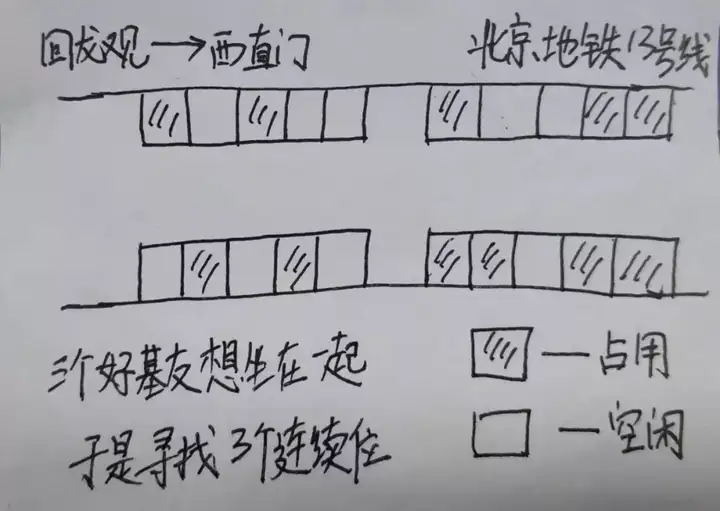
- 考虑点2: 压缩列表承载元素的多样性
待设计结构和数组不一样,数组是已经强制约定了类型,所以我们可以根据元素类型和个数来确定索引的偏移量,但是压缩列表对元素的类型没有约束,也就是说不知道是什么数据类型和长度,这个有点像TCP粘包拆包的做法了,需要我们指定结尾符或者指定单个存储的元素的长度,要不然数据都粘在一起了。 - 考虑点3:属性的常数级耗时获取
就是说我们解决了前面两点考虑,但是作为一个整体,压缩列表需要常数级消耗提供一些总体信息,比如总长度、已存储元素数量、尾节点位置(实现尾部的快速插入和删除)等,这样对于操作压缩列表意义很大。 - 考虑点4:数据结构对增删的支持
理论上我们设计的数据结构要很好地支持增删操作,当然凡事必有权衡,没有什么数据结构是完美的,我们边设计边调整吧。 - 考虑点5:如何节约内存
我们要节约内存就需要特殊情况特殊处理,所谓变长设计,也就是不像双向链表一样固定使用两个pre和next指针来实现,这样空间消耗更大,因此可能需要使用变长编码。
2.ziplist总体结构
大概想了这么多,我们来看看Redis是如何考虑的,笔者又画了一张总览简图:
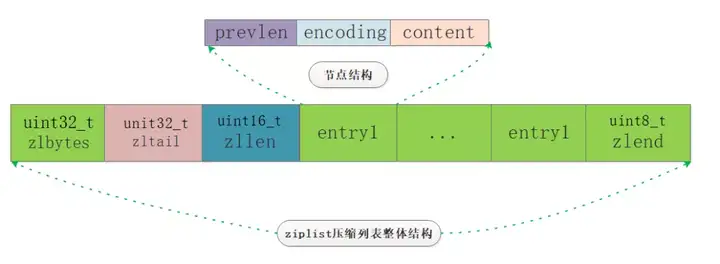
从图中我们基本上可以看到几个主要部分:zlbytes、zltail、zllen、zlentry、zlend。
来解释一下各个属性的含义,借鉴网上一张非常好的图,其中红线验证了我们的考虑点2、绿线验证了我们的考虑点3:

来看下ziplist.c中对ziplist的申请和扩容操作,加深对上面几个属性的理解:
/* Create a new empty ziplist. */
unsigned char *ziplistNew(void) {
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = ;
zl[bytes-] = ZIP_END;
return zl;
} /* Resize the ziplist. */
unsigned char *ziplistResize(unsigned char *zl, unsigned int len) {
zl = zrealloc(zl,len);
ZIPLIST_BYTES(zl) = intrev32ifbe(len);
zl[len-] = ZIP_END;
return zl;
}
3.zlentry的实现
- encoding编码和content存储
我们再来看看zlentry的实现,encoding的具体内容取决于content的类型和长度,其中当content是字符串时encoding的首字节的高2bit表示字符串类型,当content是整数时,encoding的首字节高2bit固定为11,从Redis源码的注释中可以看的比较清楚,笔者再做一层汉语版的注释^_^:
/*
###########字符串存储详解###############
#### encoding部分分为三种类型:1字节、2字节、5字节 ####
#### 最高2bit表示是哪种长度的字符串 分别是00 01 10 各自对应1字节 2字节 5字节 #### #### 当最高2bit=00时 表示encoding=1字节 剩余6bit 2^6=64 可表示范围0~63####
#### 当最高2bit=01时 表示encoding=2字节 剩余14bit 2^14=16384 可表示范围0~16383####
#### 当最高2bit=11时 表示encoding=5字节 比较特殊 用后4字节 剩余32bit 2^32=42亿多####
* |00pppppp| - 1 byte
* String value with length less than or equal to 63 bytes (6 bits).
* "pppppp" represents the unsigned 6 bit length.
* |01pppppp|qqqqqqqq| - 2 bytes
* String value with length less than or equal to 16383 bytes (14 bits).
* IMPORTANT: The 14 bit number is stored in big endian.
* |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes
* String value with length greater than or equal to 16384 bytes.
* Only the 4 bytes following the first byte represents the length
* up to 32^2-1. The 6 lower bits of the first byte are not used and
* are set to zero.
* IMPORTANT: The 32 bit number is stored in big endian. *########################字符串存储和整数存储的分界线####################*
*#### 高2bit固定为11 其后2bit 分别为00 01 10 11 表示存储的整数类型
* |11000000| - 3 bytes
* Integer encoded as int16_t (2 bytes).
* |11010000| - 5 bytes
* Integer encoded as int32_t (4 bytes).
* |11100000| - 9 bytes
* Integer encoded as int64_t (8 bytes).
* |11110000| - 4 bytes
* Integer encoded as 24 bit signed (3 bytes).
* |11111110| - 2 bytes
* Integer encoded as 8 bit signed (1 byte).
* |1111xxxx| - (with xxxx between 0000 and 1101) immediate 4 bit integer.
* Unsigned integer from 0 to 12. The encoded value is actually from
* 1 to 13 because 0000 and 1111 can not be used, so 1 should be
* subtracted from the encoded 4 bit value to obtain the right value.
* |11111111| - End of ziplist special entry.
*/
content保存节点内容,其内容可以是字节数组和各种类型的整数,它的类型和长度决定了encoding的编码,对照上面的注释来看两个例子吧:

保存字节数组:编码的最高两位00表示节点保存的是一个字节数组,编码的后六位001011记录了字节数组的长度11,content 属性保存着节点的值 "hello world"。

保存整数:编码为11000000表示节点保存的是一个int16_t类型的整数值,content属性保存着节点的值10086。
- prevlen属性
最后来说一下prevlen这个属性,该属性也比较关键,前面一直在说压缩列表是为了节约内存设计的,然而prevlen属性就恰好起到了这个作用,回想一下链表要想获取前面的节点需要使用指针实现,压缩列表由于元素的多样性也无法像数组一样来实现,所以使用prevlen属性记录前一个节点的大小来进行指向。
prevlen属性以字节为单位,记录了压缩列表中前一个节点的长度,其长度可以是 1 字节或者 5 字节:
- 如果前一节点的长度小于254字节,那么prevlen属性的长度为1字节, 前一节点的长度就保存在这一个字节里面。
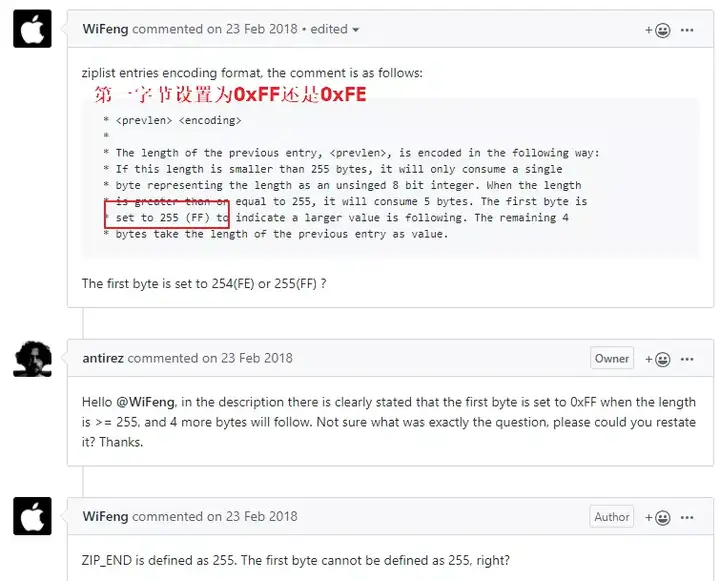
- 如果前一节点的长度大于等于254字节,那么prevlen属性的长度为5字节,第一字节会被设置为0xFE,之后的四个字节则用于保存前一节点的长度。
思考:注意一下这里的第一字节设置的是0xFE而不是0xFF,想下这是为什么呢?
没错!前面提到了zlend是个特殊值设置为0xFF表示压缩列表的结束,因此这里不可以设置为0xFF,关于这个问题在redis有个issue,有人提出来antirez的ziplist中的注释写的不对,最终antirez发现注释写错了,然后愉快地修改了,哈哈!
再思考一个问题,为什么prevlen的长度要么是1字节要么是5字节呢?为啥没有2字节、3字节、4字节这些中间态的长度呢?要解答这个问题就引出了今天的一个关键问题:连锁更新问题。
4.连锁更新问题
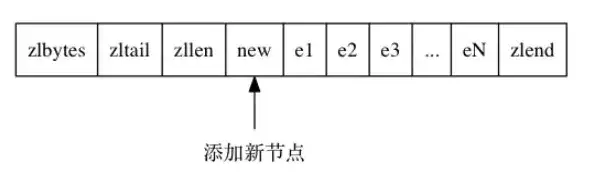
试想这样一种增加节点的场景:
如果在压缩列表的头部增加一个新节点,并且长度大于254字节,所以其后面节点的prevlen必须是5字节,然而在增加新节点之前其prevlen是1字节,必须进行扩展,极端情况下如果一直都需要扩展那么将产生连锁反应:
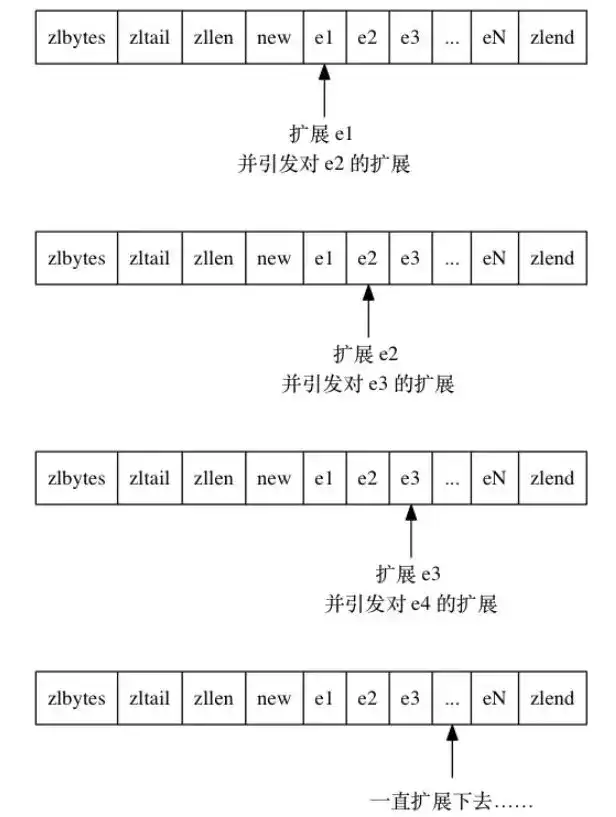
试想另外一种删除节点的场景:
如果需要删除的节点时小节点,该节点前面的节点是大节点,这样当把小节点删除时,其后面的节点就要保持其前面大节点的长度,面临着扩展的问题:
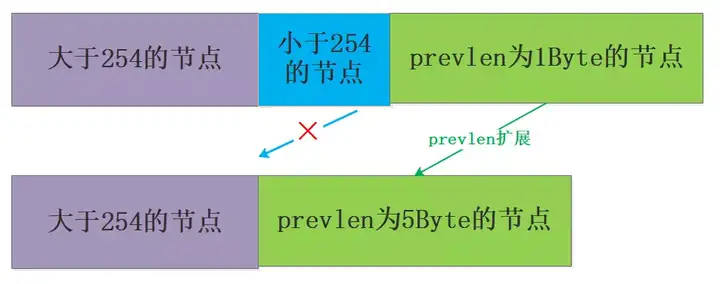
理解了连锁更新问题,再来看看为什么要么1字节要么5字节的问题吧,如果是2-4字节那么可能产生连锁反应的概率就更大了,相反直接给到最大5字节会大大降低连锁更新的概率,所以笔者也认为这种内存的小小浪费也是值得的。
5.辩证看待ziplist
从ziplist的设计来看,压缩列表并不擅长修改操作,这样会导致内存拷贝问题,并且当压缩列表存储的数据量超过某个阈值之后查找指定元素带来的遍历损耗也会增加。
6.巨人的肩膀
http://zhangtielei.com/posts/blog-redis-ziplist.html
https://github.com/antirez/redis/blob/unstable/src/ziplist.c
Redis面试热点之底层实现篇(续)的更多相关文章
- Redis面试热点之底层实现篇
通过本文你将了解到以下内容: Redis的作者.发展演进和江湖地位 Redis面试问题的概况 Redis底层实现相关的问题包括:常用数据类型底层实现.SDS的原理和优势.字典的实现原理.跳表和有序集合 ...
- 浅谈Redis面试热点之工程架构篇[1]
前言 前面用两篇文章大致介绍了Redis热点面试中的底层实现相关的问题,感兴趣的可以回顾一下:[决战西二旗]|Redis面试热点之底层实现篇[决战西二旗]|Redis面试热点之底层实现篇(续) 接下来 ...
- Redis面试热点工程架构篇之数据同步
温馨提示 更佳阅读体验:[决战西二旗]|Redis面试热点之工程架构篇[2] 前言 前面用了3篇文章介绍了一些底层实现和工程架构相关的问题,鉴于Redis的热点问题还是比较多的,因此今天继续来看工程架 ...
- Redis面试大全
1. 什么是Redis Redis是由意大利人Salvatore Sanfilippo(网名:antirez)开发的一款内存高速缓存数据库.Redis全称为:Remote Dictionary Ser ...
- Redisson实现Redis分布式锁的底层原理
一.写在前面 现在面试,一般都会聊聊分布式系统这块的东西.通常面试官都会从服务框架(Spring Cloud.Dubbo)聊起,一路聊到分布式事务.分布式锁.ZooKeeper等知识.所以咱们这篇文章 ...
- Redis面试专题
Redis面试专题 1. 什么是redis? Redis 是一个基于内存的高性能key-value数据库. (有空再补充,有理解错误或不足欢迎指正) 2. Reids的特点 Redis本质上是一个Ke ...
- Java 面试知识点解析(六)——数据库篇
前言: 在遨游了一番 Java Web 的世界之后,发现了自己的一些缺失,所以就着一篇深度好文:知名互联网公司校招 Java 开发岗面试知识点解析 ,来好好的对 Java 知识点进行复习和学习一番,大 ...
- 转 Redis 总结精讲 看一篇成高手系统-4
转 Redis 总结精讲 看一篇成高手系统-4 2018年05月31日 09:00:05 hjm4702192 阅读数:125633 本文围绕以下几点进行阐述 1.为什么使用redis 2.使用r ...
- redis面试问题(二)
1.redis和其他缓存相比有哪些优点呢 见上一篇 2. 你刚刚提到了持久化,能重点介绍一下么 见上一篇 3.Redis中对于IO的控制做过什么优化? pipeline? 4 有没有尝试进行多机red ...
随机推荐
- 8*8LED点阵
基础认识 1.5英寸LED点阵管数码管8*8红色16pin 有如下两种型号: 共阳1588BS 共阴1588AS 共阴1588AS 共阳1588BS 编程导向 共阴和共阳其编程思路基本类似,只是对应I ...
- 『题解』Codeforces9D How many trees?
更好的阅读体验 Portal Portal1: Codeforces Portal2: Luogu Description In one very old text file there was wr ...
- mysql找出重复数据的方法
mysql找出重复数据的方法<pre>select openid,count(openid) from info group by openid,jichushezhi_id HAVING ...
- 来了!GitHub for mobile 发布!iOS beta 版已来,Android 版即将发布
北京时间 2019 年 11 月 14 日,在 GitHub Universe 2019大会上,GitHub 正式发布了 GitHub for mobile,支持 iOS 与 Android 两大移动 ...
- C语言:大数取余
大数取余数(数组) 今天做学校的oj时遇到一题,问题可见一下截图: 查遍各大论坛,都没有遇到合适的方法,普通方法不可用,要采用数组的形式. 被除数超过long long类型,不能采用常规思路,否则会出 ...
- 数据结构之队列and栈总结分析
一.前言: 数据结构中队列和栈也是常见的两个数据结构,队列和栈在实际使用场景上也是相辅相成的,下面简单总结一下,如有不对之处,多多指点交流,谢谢. 二.队列简介 队列顾名思义就是排队的意思,根据我们的 ...
- Mybatis动态语句部分收集
where: <select id="findActiveBlogLike" resultType="Blog"> SELECT * FROM BL ...
- thinkphp分页样式css代码
<style type="text/css"> .Pagination a:hover,.current{background-color: #f54281;borde ...
- ThinkPHP 6.0 管道模式与中间件的实现分析
设计模式六大原则 开放封闭原则:一个软件实体如类.模块和函数应该对扩展开放,对修改关闭. 里氏替换原则:所有引用基类的地方必须能透明地使用其子类的对象. 依赖倒置原则:高层模块不应该依赖低层模块,二者 ...
- 给大家整理了几个开源免费的 Spring Boot + Vue 学习资料
最近抽空在整理前面的文章案例啥的,顺便把手上的几个 Spring Boot + Vue 的学习资料推荐给各位小伙伴.这些案例有知识点的讲解,也有项目实战,正在做这一块的小伙伴们可以收藏下. 案例学习 ...