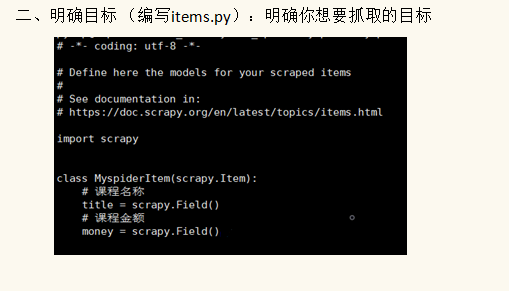
scrapy框架介绍及安装
什么是scrapy框架?

scrapy框架的安装
1.windowes下的安装
Python 2 / 3
升级pip版本:
pip install --upgrade pip
通过pip 安装 Scrapy 框架
pip install scrapy
2.Ubuntu下的安装
Ubuntu 需要9.10或以上版本安装方式
Python 2 / 3
安装非Python的依赖
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
通过pip 安装 Scrapy 框架
sudo pip install scrapy
具体Scrapy安装流程参考:http://doc.scrapy.org/en/latest/intro/install.html#intro-install-platform-notes 里面有各个平台的安装方法
3.scrapy的运行流程

Scrapy构架解析:Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
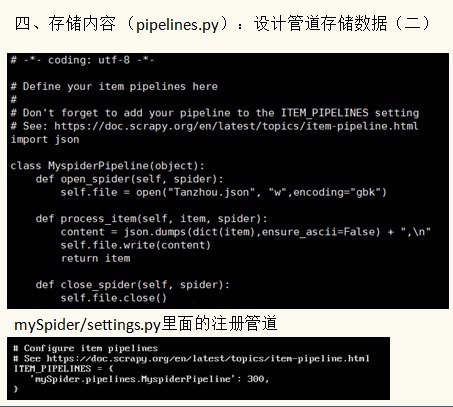
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
4.部分问题解答



scrapy框架介绍及安装的更多相关文章
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- Scrapy框架——介绍、安装、命令行创建,启动、项目目录结构介绍、Spiders文件夹详解(包括去重规则)、Selectors解析页面、Items、pipelines(自定义pipeline)、下载中间件(Downloader Middleware)、爬虫中间件、信号
一 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Scrapy的用途十分广泛,可 ...
- hue框架介绍和安装部署
大家好,我是来自内蒙古的小哥,我现在在北京学习大数据,我想把学到的东西分享给大家,想和大家一起学习 hue框架介绍和安装部署 hue全称:HUE=Hadoop User Experience 他是cl ...
- 爬虫之Scrapy框架介绍
Scrapy介绍 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内 ...
- scrapy框架介绍
一,介绍 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性 ...
- python爬虫之scrapy框架介绍
一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等) ...
- 爬虫相关-scrapy框架介绍
性能相关-进程.线程.协程 在编写爬虫时,性能的消耗主要在IO请求中,当单进程单线程模式下请求URL时必然会引起等待,从而使得请求整体变慢. 串行执行 import requests def fetc ...
- Scrapy框架学习(一)Scrapy框架介绍
Scrapy框架的架构图如上. Scrapy中的数据流由引擎控制,数据流的过程如下: 1.Engine打开一个网站,找到处理该网站的Spider,并向该Spider请求第一个要爬取得URL. 2.En ...
- Scrapy 框架介绍
Scrapy 框架 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试. ...
随机推荐
- DOS打印目录树到文件
tree /f >>tree.txt 卷 数据 的文件夹 PATH 列表 卷序列号为 -FBAE E:. └─mysite │ manage.py │ └─mysite settings. ...
- C/c.pp:贪心,二分答案
说是贪心有点牵强. 其次,答案满足单调性,如果在k次操作能完成那么在k+1次操作内也能完成. 因为大不了你就把多的一次对方操作再进行一次就好了. 怎么操作呢? 我们从头扫这个序列,遇到每一个不匹配位置 ...
- 单(single):换根dp,表达式分析,高斯消元
虽说这题看大家都改得好快啊,但是为什么我感觉这题挺难.(我好菜啊) 所以不管怎么说那群切掉这题的大佬是不会看这篇博客的所以我要开始自嗨了. 这题,明显是树dp啊.只不过出题人想看你发疯,询问二合一了而 ...
- 伪紫题p5194 天平(dfs剪枝)
这题作为一个紫题实在是过分了吧...绿的了不起了.—————————————————————————— 看题第一眼,01背包无误.2min打好一交全屏紫色(所以这就是这题是紫色的原因233?) re原 ...
- 考试T3麻将
这题就是一个简单的暴力,但考试的时候不知道脑子在想什么,什么都没打出来,也许是我想的太多了... 这道题对于不会打麻将的人来说还是有点难理解规则的,我没说过我会打麻将,这里是题目链接. 20分思路,利 ...
- unittest加载测试用例名称必须以test开头,是否可以定制化
前几天,在一个群里,一个人问了,这样一个问题.说他面试遇到一个面试官,问他,为啥unittest的测试用例要用test 开头,能不能定制化.他不知道为啥. 看到这个题目,我回答当然可以了,可以用l ...
- HTTPS加密流程理解
HTTPS加密流程 由于HTTP的内容在网络上实际是明文传输,并且也没有身份验证之类的安全措施,所以容易遭到挟持与攻击 HTTPS是通过SSL(安全套接层)和TLS(安全传输协议)的组合使用,加密TC ...
- 201871010114-李岩松《面向对象程序设计(java)》第二周学习总结
项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 https://www.cnblogs.com/nwnu-daizh/p ...
- PHP---无限极分类数组处理
$array = array( 0=>array('id'=>1,'uid'=>0,'menuname'=>'菜单1','url'=>0,'addtime'=> ...
- PHP Swoole长连接常见问题
连接失效问题例子其中,Redis常见的报错就是: 配置项:timeout报错信息:Error while reading line from the serverRedis可以配置如果客户端经过多少秒 ...