elasticsearch的分布式基础概念(1)
Elasticsearch对复杂分布式机制的透明隐藏特性
Elasticsearch是一套分布式的系统,分布式是为了应对大数据量 隐藏了复杂的分布式机制
分片机制(随随便便就将一些document插入到es集群中去了,我们有没有care过数据怎么进行分片的,数据到哪个shard中去)
cluster discovery(集群发现机制,在做那个集群status从yellow转green的实验里,直接启动了第二个es进程,那个进程作为一个node自动就发现了集群,并且加入了进去,还接受了部分数据,replica shard)
shard负载均衡(举例,假设现在有3个节点,总共有25个shard要分配到3个节点上去,es会自动进行均匀分配,以保持每个节点的均衡的读写负载请求)
shard副本,请求路由,集群扩容,shard重分配
Elasticsearch的垂直扩容与水平扩容
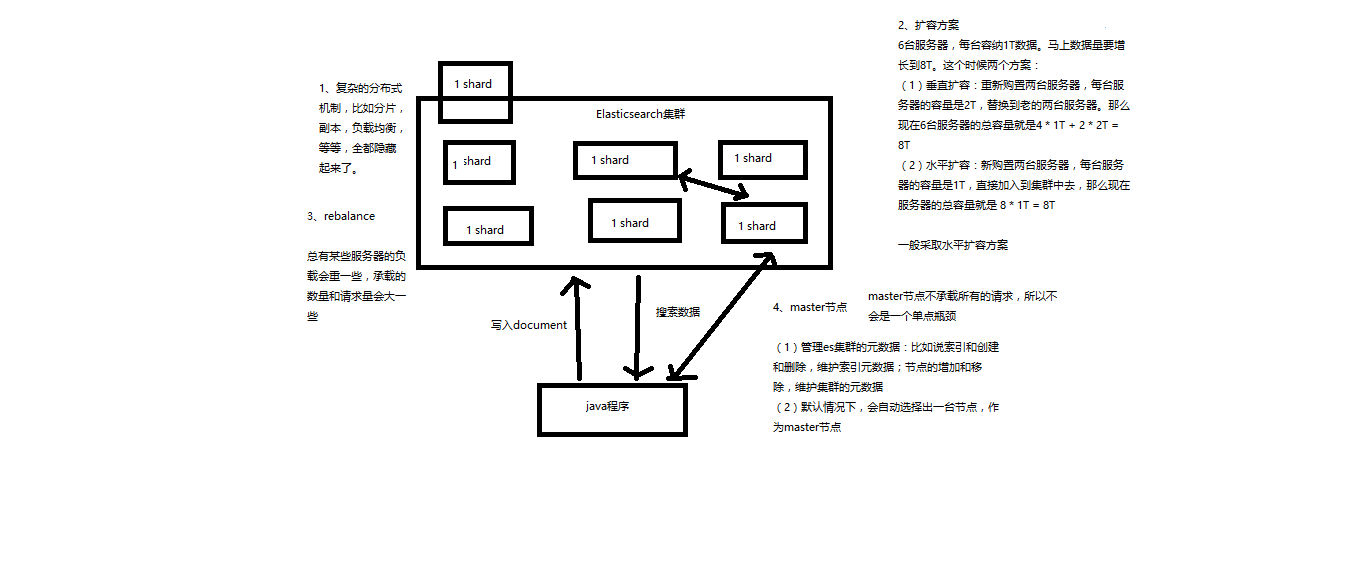

垂直扩容:采购更强大的服务器,成本非常高昂
水平扩容:业界经常采用的方案,采购越来越多的普通服务器,性能比较一般,但是很多普通服务器组织在一起,就能构成强大的计算和存储能力
扩容对应用程序的透明性
增减或减少节点时的数据rebalance
保持负载均衡
master节点
(1)创建或删除索引 (2)增加或删除节点
节点平等的分布式架构
(1)节点对等,每个节点都能接收所有的请求 (2)自动请求路由 (3)响应收集
shard&replica机制再次梳理
(1)index包含多个shard (2)每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力 (3)增减节点时,shard会自动在nodes中负载均衡 (4)primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard (5)replica shard是primary shard的副本,负责容错,以及承担读请求负载 (6)primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改 (7)primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard (8)primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
单node环境下创建index是什么样子的
(1)单node环境下,创建一个index,有3个primary shard,3个replica shard (2)集群status是yellow (3)这个时候,只会将3个primary shard分配到仅有的一个node上去,另外3个replica shard是无法分配的 (4)集群可以正常工作,但是一旦出现节点宕机,数据全部丢失,而且集群不可用,无法承接任何请求
PUT /test_index { "settings" : { "number_of_shards" : 3, "number_of_replicas" : 1 } }
2个node环境下replica shard的分配
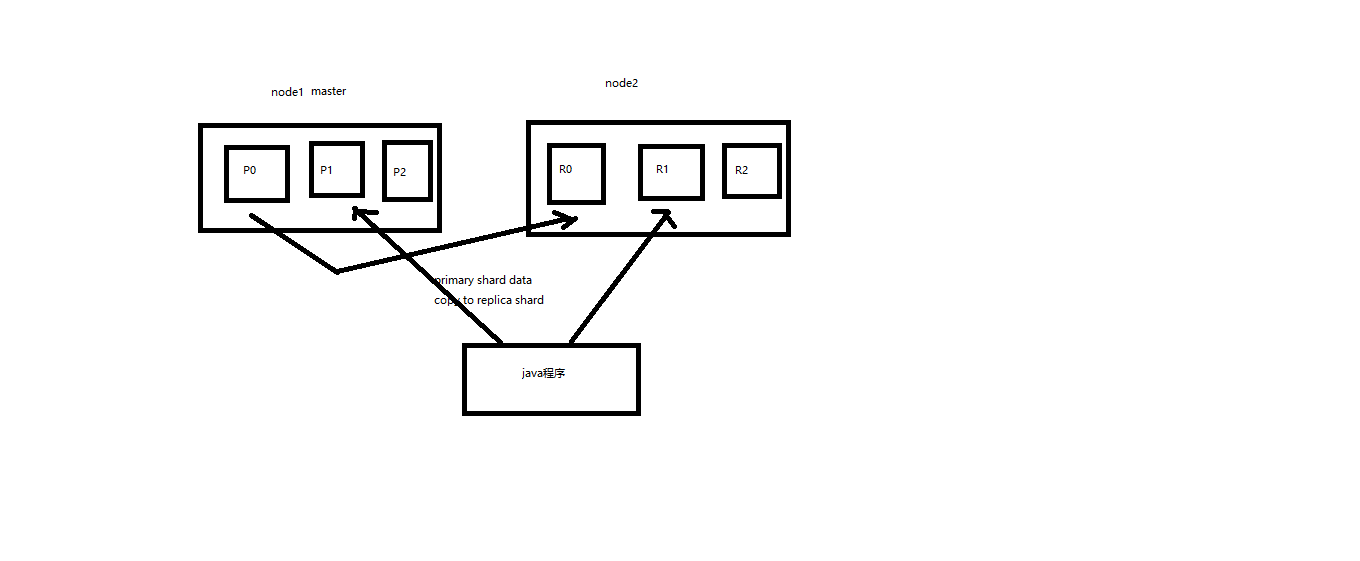

(1)replica shard分配:3个primary shard,3个replica shard,1 node (2)primary ---> replica同步 (3)读请求:primary/replica
横向扩容过程,如何超出扩容极限,以及如何提升容错性
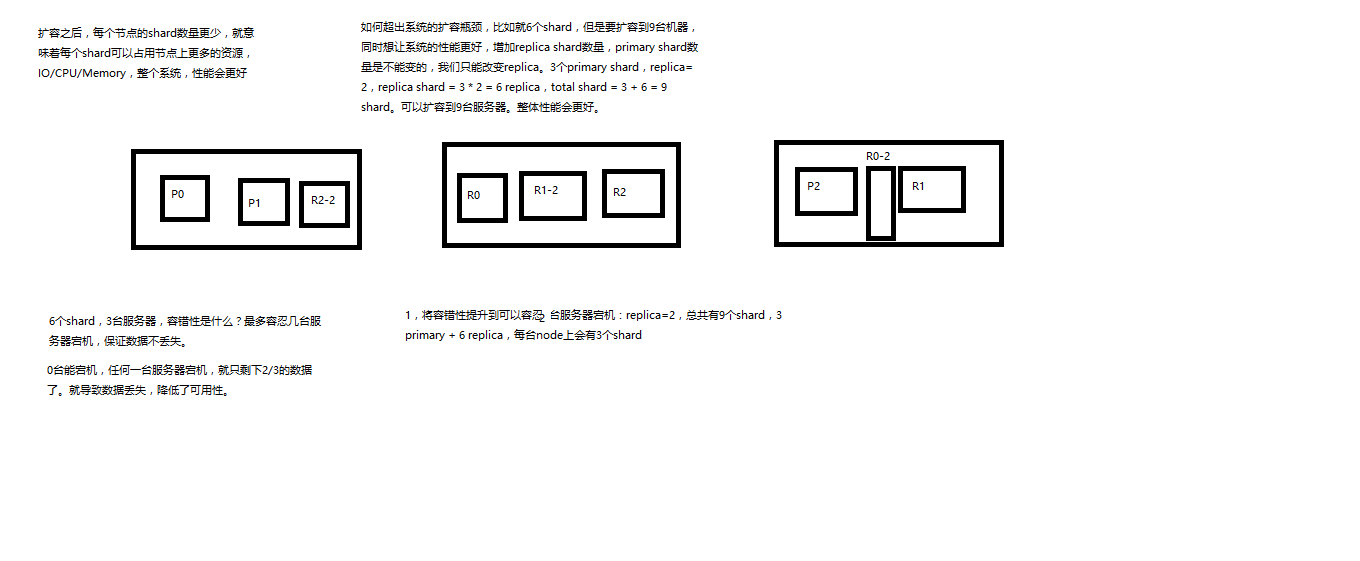
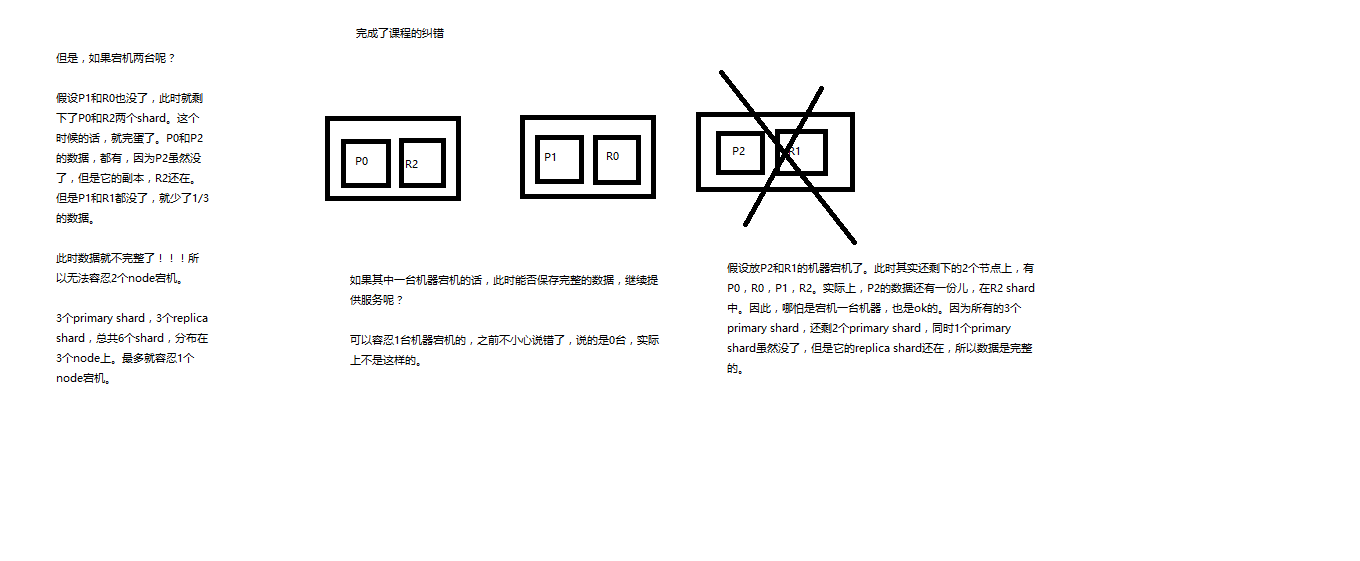


(1)primary&replica自动负载均衡,6个shard,3 primary,3 replica (2)每个node有更少的shard,IO/CPU/Memory资源给每个shard分配更多,每个shard性能更好 (3)扩容的极限,6个shard(3 primary,3 replica),最多扩容到6台机器,每个shard可以占用单台服务器的所有资源,性能最好 (4)超出扩容极限,动态修改replica数量,9个shard(3primary,6 replica),扩容到9台机器,比3台机器时,拥有3倍的读吞吐量 (5)3台机器下,9个shard(3 primary,6 replica),资源更少,但是容错性更好,最多容纳2台机器宕机,6个shard只能容纳0台机器宕机 (6)这里的这些知识点,综合起来看,一方面告诉你扩容的原理,怎么扩容,怎么提升系统整体吞吐量;另一方面要考虑到系统的容错性,怎么保证提高容错性,让尽可能多的服务器宕机,保证数据不丢失
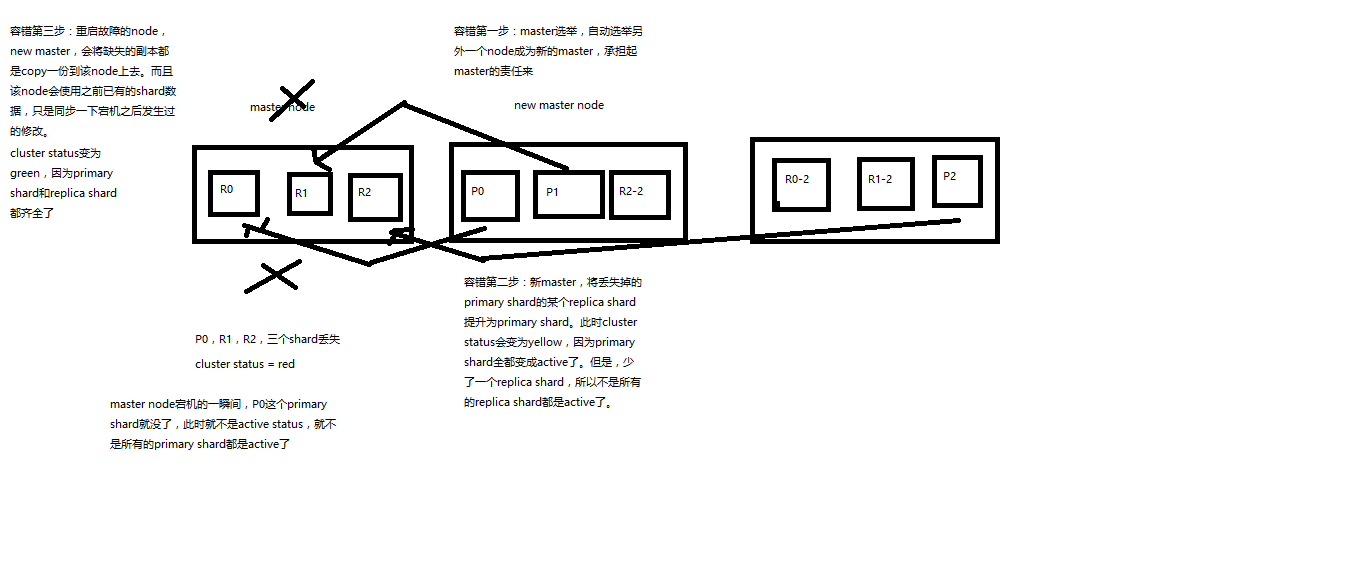
Elasticsearch容错机制:master选举,replica容错,数据恢复
(1)9 shard,3 node
(2)master node宕机,自动master选举,red
(3)replica容错:新master将replica提升为primary shard,yellow
(4)重启宕机node,master copy replica到该node,使用原有的shard并同步宕机后的修改,green

解析document的核心元数据以及图解剖析index创建反例
1、_index元数据
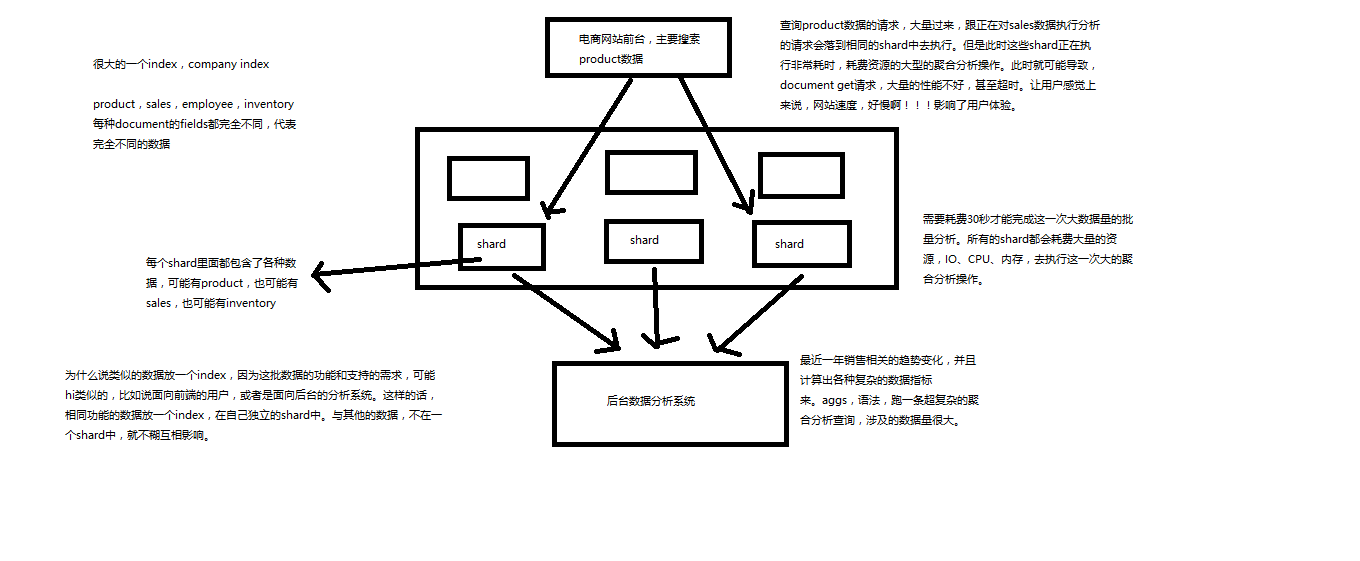
(1)代表一个document存放在哪个index中 (2)类似的数据放在一个索引,非类似的数据放不同索引:product index(包含了所有的商品),sales index(包含了所有的商品销售数据),inventory index(包含了所有库存相关的数据)。如果你把比如product,sales,human resource(employee),全都放在一个大的index里面,比如说company index,不合适的。 (3)index中包含了很多类似的document:类似是什么意思,其实指的就是说,这些document的fields很大一部分是相同的,你说你放了3个document,每个document的fields都完全不一样,这就不是类似了,就不太适合放到一个index里面去了。 (4)索引名称必须是小写的,不能用下划线开头,不能包含逗号:product,website,blog
2、_type元数据
(1)代表document属于index中的哪个类别(type) (2)一个索引通常会划分为多个type,逻辑上对index中有些许不同的几类数据进行分类:因为一批相同的数据,可能有很多相同的fields,但是还是可能会有一些轻微的不同,可能会有少数fields是不一样的,举个例子,就比如说,商品,可能划分为电子商品,生鲜商品,日化商品,等等。 (3)type名称可以是大写或者小写,但是同时不能用下划线开头,不能包含逗号
3、_id元数据
(1)代表document的唯一标识,与index和type一起,可以唯一标识和定位一个document (2)我们可以手动指定document的id(put /index/type/id),也可以不指定,由es自动为我们创建一个id

document id的手动指定与自动生成两种方式解析
1、手动指定document id
(1)根据应用情况来说,是否满足手动指定document id的前提:
一般来说,是从某些其他的系统中,导入一些数据到es时,会采取这种方式,就是使用系统中已有数据的唯一标识,作为es中document的id。举个例子,比如说,我们现在在开发一个电商网站,做搜索功能,或者是OA系统,做员工检索功能。这个时候,数据首先会在网站系统或者IT系统内部的数据库中,会先有一份,此时就肯定会有一个数据库的primary key(自增长,UUID,或者是业务编号)。如果将数据导入到es中,此时就比较适合采用数据在数据库中已有的primary key。
如果说,我们是在做一个系统,这个系统主要的数据存储就是es一种,也就是说,数据产生出来以后,可能就没有id,直接就放es一个存储,那么这个时候,可能就不太适合说手动指定document id的形式了,因为你也不知道id应该是什么,此时可以采取下面要讲解的让es自动生成id的方式。
(2)put /index/type/id
PUT /test_index/test_type/2 { "test_content": "my test" }
2、自动生成document id
(1)post /index/type
POST /test_index/test_type { "test_content": "my test" }
{ "index": "test_index", "type": "test_type", "id": "AVp4RN0bhjxldOOnBxaE", "version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "created": true }
(2)自动生成的id,长度为20个字符,URL安全,base64编码,GUID,分布式系统并行生成时不可能会发生冲突
_source元数据
我们在创建一个document的时候,使用的那个放在request body中的json串,默认情况下,在get的时候,会原封不动的给我们返回回来。
定制返回结果
指定_source中,返回哪些field
GET /test_index/test_type/1?_source=test_field1,test_field2
{ "index": "test_index", "type": "test_type", "id": "1", "version": 2, "found": true, "_source": { "test_field2": "test field2" } }
document相关操作
1、document的全量替换
(1)语法与创建文档是一样的,如果document id不存在,那么就是创建;如果document id已经存在,那么就是全量替换操作,替换document的json串内容 (2)document是不可变的,如果要修改document的内容,第一种方式就是全量替换,直接对document重新建立索引,替换里面所有的内容 (3)es会将老的document标记为deleted,然后新增我们给定的一个document,当我们创建越来越多的document的时候,es会在适当的时机在后台自动删除标记为deleted的document
2、document的强制创建
(1)创建文档与全量替换的语法是一样的,有时我们只是想新建文档,不想替换文档,如果强制进行创建呢? (2)PUT /index/type/id?op_type=create,PUT /index/type/id/_create
3、document的删除
(1)DELETE /index/type/id (2)不会理解物理删除,只会将其标记为deleted,当数据越来越多的时候,在后台自动删除
深度图解剖析Elasticsearch并发冲突问题
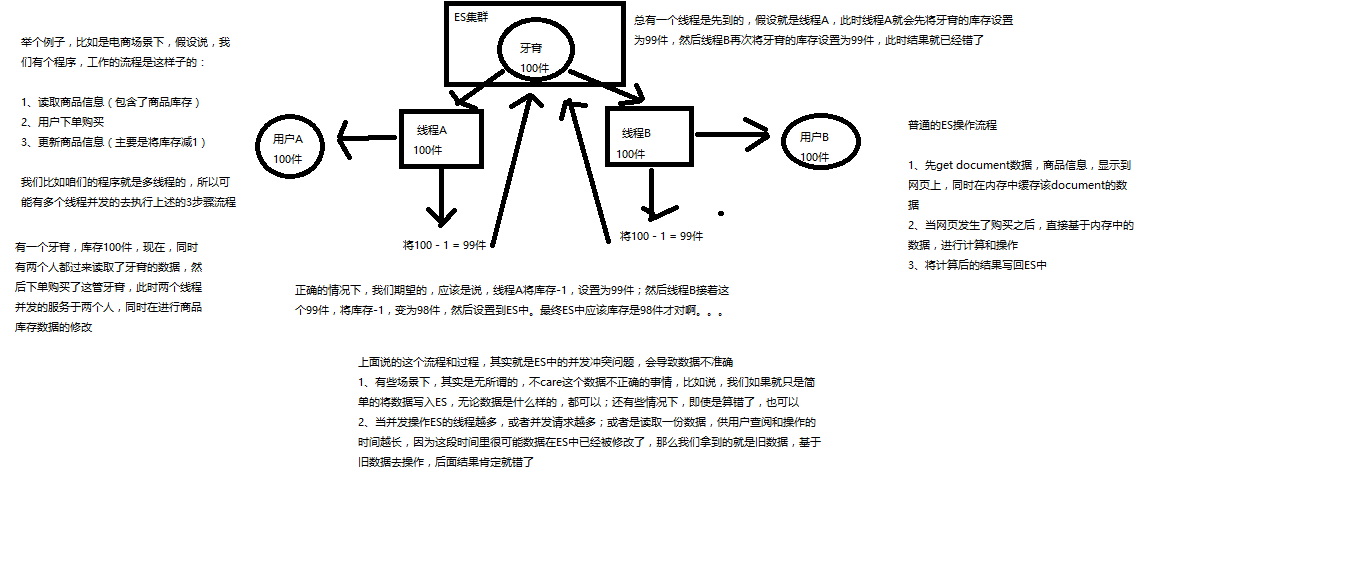

图解乐悲观锁
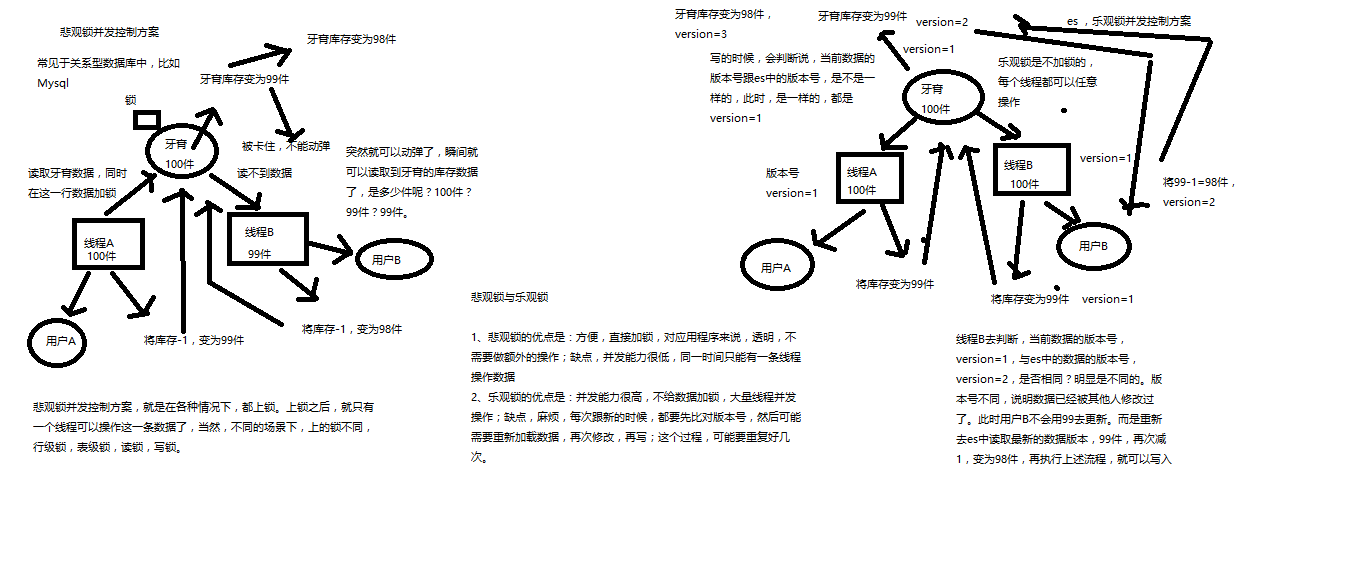

Elasticsearch内部如何基于_version进行乐观锁并发控制
(1)_version元数据
PUT /test_index/test_type/6 { "test_field": "test test" }
{ "index": "test_index", "type": "test_type", "id": "6", "version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "created": true }
第一次创建一个document的时候,它的version内部版本号就是1;以后,每次对这个document执行修改或者删除操作,都会对这个version版本号自动加1;哪怕是删除,也会对这条数据的版本号加1
{ "found": true, "index": "test_index", "type": "test_type", "id": "6", "version": 4, "result": "deleted", "_shards": { "total": 2, "successful": 1, "failed": 0 } }
我们会发现,在删除一个document之后,可以从一个侧面证明,它不是立即物理删除掉的,因为它的一些版本号等信息还是保留着的。先删除一条document,再重新创建这条document,其实会在delete version基础之上,再把version号加1

elasticsearch的分布式基础概念(1)的更多相关文章
- Elasticsearch教程之基础概念
基础概念 Elasticsearch有几个核心概念.从一开始理解这些概念会对整个学习过程有莫大的帮助. 1.接近实时(NRT) Elasticsearch是一个接近实时的搜索平台.这意味 ...
- ELK & ElasticSearch 5.1 基础概念及配置文件详解【转】
转自:https://blog.csdn.net/zxf_668899/article/details/54582849 配置文件 基本概念 接近实时NRT 集群cluster 索引index 文档d ...
- 读《深入理解Elasticsearch》点滴-基础概念
Lucene的概念 document:以json的形式体现,搜索和搜索的主要载体 field:document的一个部分 term(词项):代表文本中的一个词 token(词条):term在field ...
- [Re:从零开始的分布式] 0.x——分布式基础概念
分布式的特点 1. 分布式 2. 对等性 3. 并发性 4. 缺乏全局时钟 5. 故障总是会发生 分布式环境的问题 1. 网络不可靠 2. 网络分区 3. 节点故障 CAP理论 一致性 可用性 分区容 ...
- day1 分布式基础概念
1. 分布式:一个业务分拆多个子业务,部署在不同的服务器上集群:同一个业务,部署在多个服务器上节点:集群中的一个服务器 2.远程调用 分布式系统中调用其它主机 springcloud用http+jso ...
- 搜索引擎 ElasticSearch 之 步步为营2 【基础概念】
在正式学习 ElasticSearch 之前,首先看一下 ElasticSearch 中的基本概念. 这些概念将在以后的章节中出现多次,所以花15分钟理解一下是非常值得的. 英文好的同学,请直接移步官 ...
- Elasticsearch一些常用操作和一些基础概念
1.查看集群健康状态 [root@ELK-chaofeng01 ~]#curl -XGET http://172.16.0.51:9200/_cat/health?v epoch timestamp ...
- 分布式强化学习基础概念(Distributional RL )
分布式强化学习基础概念(Distributional RL) from: https://mtomassoli.github.io/2017/12/08/distributional_rl/ 1. Q ...
- 第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念 elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点 ...
随机推荐
- NDK Cmake
CMake与NDK搭配使用时,可以配置的部分变量: 1. `ANDROID_PLATFORM`:指定Android的目标版本,对应`$NDK/platforms/`目录下的版本.通常情况下是`defa ...
- JSP指令、标签以及中文乱码
JSP指令.标签以及中文乱码 一.JSP指令简介 JSP指令(directive)是为JSP引擎而设计的,它们并不直接产生任何可见输出,而只是告诉引擎如何处理JSP页面中的其余部分. JSP指令的基本 ...
- [Python] 常见的排序与搜索算法
说明: 本文主要使用python实现常见的排序与搜索算法:冒泡排序.选择排序.插入排序.希尔排序.快速排序.归并排序以及二分查找等. 对算法的基本思想作简要说明,只要理解了基本的思想,与实现语言无关. ...
- Python--编码与字符串
为什么字符串要编码呢? 因为计算机只能处理数字,最底层的CPU只能识别0和1.所以字符串就需要编码成对应的数字. 在计算机中,最开始只有ASCII,我们开始接触计算机编程时就学了ASCII码.最早只有 ...
- matplotlib 库的使用
1.问题描述: 在学习kaggle经典学习项目Titanic,进行数据可视化处理时,对于每个特征进行相关性分析(也就是绘制pearson correlation heatmap )热力相关性矩阵时, ...
- Badboy - 从excel中读取数据
参考: http://leafwf.blog.51cto.com/872759/1119161 http://www.51testing.com/html/00/130600-1367743.html ...
- [python] - profilers性能分析器
1. 性能分析器: profile, hotshot, cProfile 2. 作用: 测试函数的执行时间 每次脚本执行的总时间
- 洛谷 P2051 [AHOI2009]中国象棋 状态压缩思想DP
P2051 [AHOI2009]中国象棋 题意: 给定一个n*m的空棋盘,问合法放置任意多个炮有多少种情况.合法放置的意思是棋子炮不会相互打到. 思路: 这道题我们可以发现因为炮是隔一个棋子可以打出去 ...
- 线段树模板 hdu 1166 敌兵布阵
敌兵布阵 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submis ...
- 如何将idea工程打包成jar文件
如何将idea工程打包成jar文件 近日在工作中遇到了一个问题,需要把本地的java文件打成jar包,传到云服务器上运行.于是学习了一下如何在intellij idea中将java工程打成jar包. ...