数据结构-哈夫曼树(python实现)
好,前面我们介绍了一般二叉树、完全二叉树、满二叉树,这篇文章呢,我们要介绍的是哈夫曼树。
哈夫曼树也叫最优二叉树,与哈夫曼树相关的概念还有哈夫曼编码,这两者其实是相同的。哈夫曼编码是哈夫曼在1952年提出的。现在哈夫曼编码多应用在文本压缩方面。接下来,我们就来介绍哈夫曼树到底是个什么东西?哈夫曼编码又是什么,以及它如何应用于文本压缩。
哈夫曼树(Huffman Tree)
给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
首先,我们有这样一些数据:
sourceData = [('a', 8), ('b', 5), ('c', 3), ('d', 3), ('e', 8), ('f', 6), ('g', 2), ('h', 5), ('i', 9), ('j', 5), ('k', 7), ('l', 5), ('m', 10), ('n', 9)]
每一个数据项是一个元组,元组的第一项是数据内容,第二项是该数据的权重。也就是说,用于构建哈夫曼树的数据是带权重的。假设这些数据里面的字母a-n的权重是根据这些字母在y一个文本出出现的概率计算得出的,字母出现的概率越高,则该字母的权重越大。例如字母 a 的权重为 8 .
好,拿到数据我们就可以来构建哈夫曼树了。
- 首先,找出所有元素中权重最小的两个元素,即g(2)和c(3),
- 以g和c为子节点构建二叉树,则构建的二叉树的父节点的权重为 2+3 = 5.
- 从除g和c以外剩下的元素和新构建的权重为5的节点中选出权重最小的两个节点,
- 进行第 2 步操作。
以此类推,直至最后合成一个二叉树就是哈夫曼树。
我们用图例来表示一下:
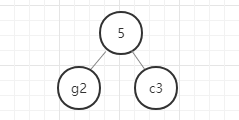
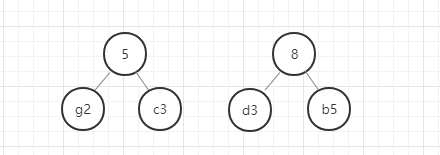
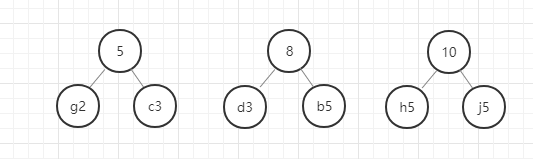
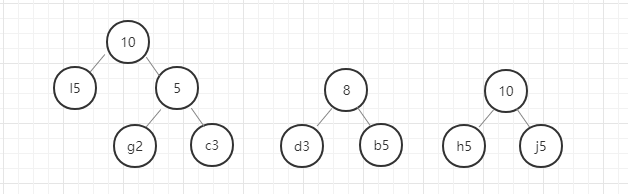
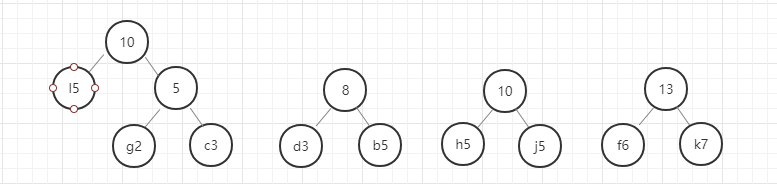
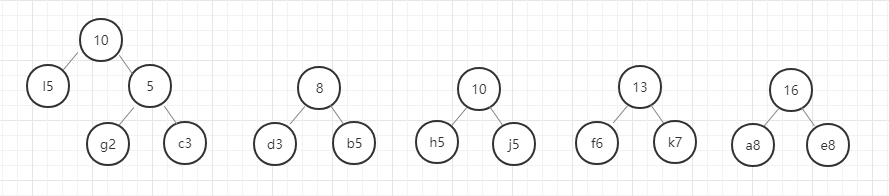
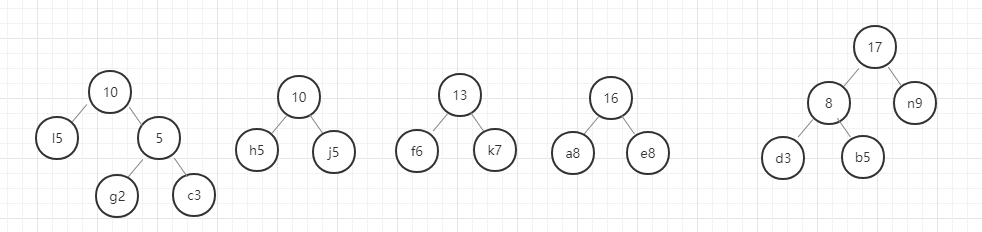
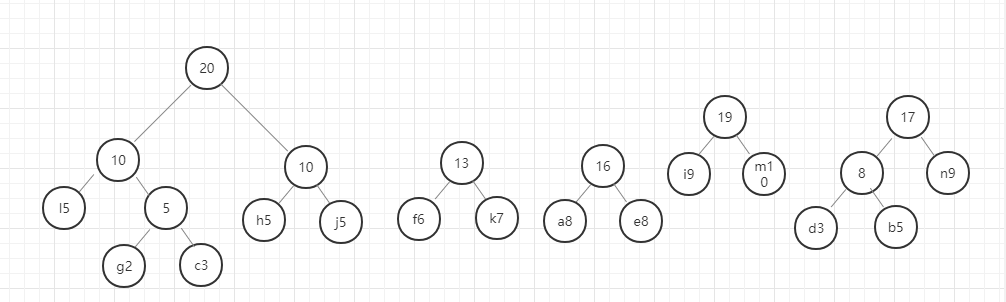
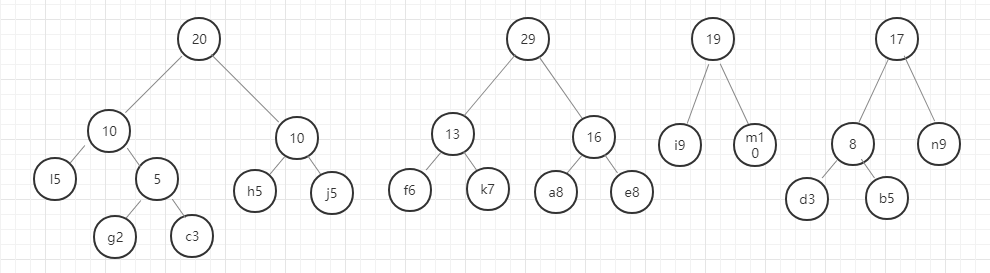
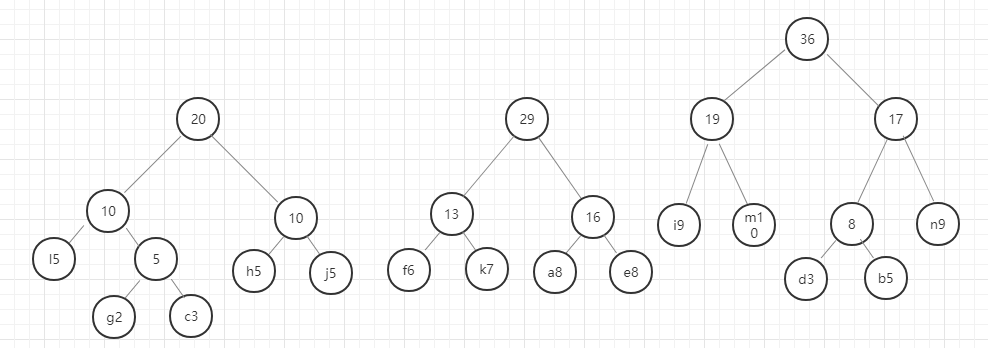
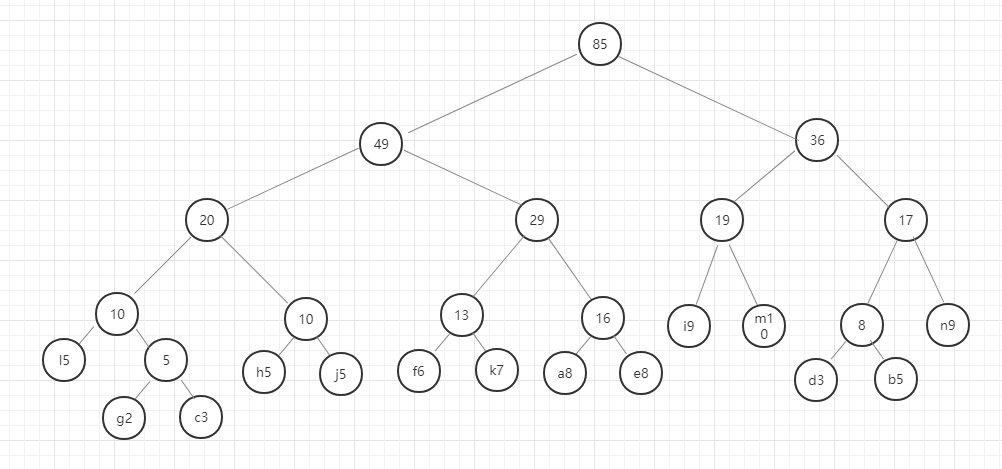
好,这里我们的哈夫曼树就构建好了,节点中字母后面的数字表示该字母的权重,就是前面给定的数据。在这里我要强调的是,同样的数据创建的哈夫曼树并不是唯一的,所以只要按照规则一步一步没有出错,你的哈夫曼树就是正确的。
我们现在将访问左节点定义为0,访问右节点定义为1.则我们现在访问字母a,则它的编码为0110,访问字母n的编码为111,这个编码就是哈夫曼编码。
通过比对不同字母的哈夫曼编码,你发现了什么?
权重越大的字母对应的哈夫曼编码越短,权重越小的字母对应的哈夫曼编码则越长。也就是说文本中出现概率大的字母编码短,出现概率小的字母编码长。通过这种编码方式来表示文本中的字母,那所得整个文本的编码长度也会缩短。
这就是哈夫曼树也就是哈夫曼编码在文本压缩中的应用。
下面我们用代码来实现:
定义一个二叉树类:
class BinaryTree:
def __init__(self, data, weight):
self.data = data
self.weight = weight
self.left = None
self.right = None
获取节点列表中权重最小的两个节点:
# 定义获取列表中权重最大的两个节点的方法:
def min2(li):
result = [BinaryTree(None, float('inf')), BinaryTree(None, float('inf'))]
li2 = []
for i in range(len(li)):
if li[i].weight < result[0].weight:
if result[1].weight != float('inf'):
li2.append(result[1])
result[0], result[1] = li[i], result[0]
elif li[i].weight < result[1].weight:
if result[1].weight != float('inf'):
li2.append(result[1])
result[1] = li[i]
else:
li2.append(li[i])
return result, li2
定义生成哈夫曼树的方法:
def makeHuffman(source):
m2, data = min2(source)
print(m2[0].data, m2[1].data)
left = m2[0]
right = m2[1]
sumLR = left.weight + right.weight
father = BinaryTree(None, sumLR)
father.left = left
father.right = right
if data == []:
return father
data.append(father)
return makeHuffman(data)
定义广度优先遍历方法:
# 递归方式实现广度优先遍历
def breadthFirst(gen, index=0, nextGen=[], result=[]):
if type(gen) == BinaryTree:
gen = [gen]
result.append((gen[index].data, gen[index].weight))
if gen[index].left != None:
nextGen.append(gen[index].left)
if gen[index].right != None:
nextGen.append(gen[index].right)
if index == len(gen)-1:
if nextGen == []:
return
else:
gen = nextGen
nextGen = []
index = 0
else:
index += 1
breadthFirst(gen, index, nextGen,result)
return result
输入数据:
# 某篇文章中部分字母根据出现的概率规定权重
sourceData = [('a', 8), ('b', 5), ('c', 3), ('d', 3), ('e', 8), ('f', 6), ('g', 2), ('h', 5), ('i', 9), ('j', 5), ('k', 7), ('l', 5), ('m', 10), ('n', 9)]
sourceData = [BinaryTree(x[0], x[1]) for x in sourceData]
创建哈夫曼树并进行广度优先遍历:
huffman = makeHuffman(sourceData)
print(breadthFirst(huffman))
OK ,我们的哈夫曼树就介绍到这里了,你还有什么不懂的问题记得留言给我哦。
数据结构-哈夫曼树(python实现)的更多相关文章
- C#数据结构-赫夫曼树
什么是赫夫曼树? 赫夫曼树(Huffman Tree)是指给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小.哈夫曼树(也称为最优二叉树)是带权路径长度最短的树,权值较大的结点 ...
- Java数据结构和算法(四)赫夫曼树
Java数据结构和算法(四)赫夫曼树 数据结构与算法目录(https://www.cnblogs.com/binarylei/p/10115867.html) 赫夫曼树又称为最优二叉树,赫夫曼树的一个 ...
- 数据结构图文解析之:哈夫曼树与哈夫曼编码详解及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- 【数据结构】赫夫曼树的实现和模拟压缩(C++)
赫夫曼(Huffman)树,由发明它的人物命名,又称最优树,是一类带权路径最短的二叉树,主要用于数据压缩传输. 赫夫曼树的构造过程相对比较简单,要理解赫夫曼数,要先了解赫夫曼编码. 对一组出现频率不同 ...
- Android版数据结构与算法(七):赫夫曼树
版权声明:本文出自汪磊的博客,未经作者允许禁止转载. 近期忙着新版本的开发,此外正在回顾C语言,大部分时间没放在数据结构与算法的整理上,所以更新有点慢了,不过既然写了就肯定尽力将这部分完全整理好分享出 ...
- 6-9-哈夫曼树(HuffmanTree)-树和二叉树-第6章-《数据结构》课本源码-严蔚敏吴伟民版
课本源码部分 第6章 树和二叉树 - 哈夫曼树(HuffmanTree) ——<数据结构>-严蔚敏.吴伟民版 源码使用说明 链接☛☛☛ <数据结构-C语言版> ...
- 20172332 2017-2018-2 《程序设计与数据结构》Java哈夫曼编码实验--哈夫曼树的建立,编码与解码
20172332 2017-2018-2 <程序设计与数据结构>Java哈夫曼编码实验--哈夫曼树的建立,编码与解码 哈夫曼树 1.路径和路径长度 在一棵树中,从一个结点往下可以达到的孩子 ...
- hdu 2527:Safe Or Unsafe(数据结构,哈夫曼树,求WPL)
Safe Or Unsafe Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)To ...
- 数据结构之C语言实现哈夫曼树
1.基本概念 a.路径和路径长度 若在一棵树中存在着一个结点序列 k1,k2,……,kj, 使得 ki是ki+1 的双亲(1<=i<j),则称此结点序列是从 k1 到 kj 的路径. 从 ...
随机推荐
- UWP开发-自适应布局
了解css的人知道,对于不同的屏幕尺寸,css使用一种名为媒体查询的东东来适用不同的屏幕尺寸,以提升用户体验.当用户使用PC等大屏幕的设备时,网页将呈现一种布局形式:而当用户使用手机等小屏幕设备时,布 ...
- 腾讯移动Web整体解决方案Spirit
Spirit(勇气号),美国航天局NASA派往Mars(火星)的第一艘探测器.移动Web开发是一块新的领域,甚至有很多坑,这一点与人类从未踏上的Mars(火星)相似.为了避免开发者重复遇到相同的问题, ...
- QT5 屏幕旋转90度
主要思路是将所有项目界面加载到QGraphicsScene,再进行旋转操作.直接上代码#include <QApplication>#include <QGraphicsView&g ...
- 剖析Qt的事件机制原理(源代码级别)
在用Qt写Gui程序的时候,在main函数里面最后依据都是app.exec();很多书上对这句的解释是,使Qt程序进入消息循环.下面我们就到exec()函数内部,来看一下他的实现原理.Let's go ...
- Codility--- Distinct
Task description Write a function class Solution { public int solution(int[] A); } that, given a zer ...
- python中的基本数据类型之 int bool str
一.基本数据类型 1. int ==> 整数.主要用来进行数学运算. 2.str ==> 字符串.可以保存少量的数据,并进行相应的操作. 3.bool => 布尔值.判断 ...
- Spark学习之路(十三)—— Spark Streaming 与流处理
一.流处理 1.1 静态数据处理 在流处理之前,数据通常存储在数据库,文件系统或其他形式的存储系统中.应用程序根据需要查询数据或计算数据.这就是传统的静态数据处理架构.Hadoop采用HDFS进行数据 ...
- PATB 1019. 数字黑洞 (20)
一个神奇的数字. 时间限制 100 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 CHEN, Yue 给定任一个各位数字不完全相同的4位正整数,如果我 ...
- Linux不重启识别新添加的磁盘
现网的一台EXSI 下的虚拟机一般在进行配置变更后都会通过重启来识别新增的配置,不过业务侧某台主机因为业务需要无法重启,想通过不重启直接识别护容上去的新磁盘.经测试,发现如下方可以解决. 1.通过ex ...
- c语言:链表
1.链表概述: 链表是一种数据结构,它采用动态分配存储单元方式.它能够有效地节省存储空间(同数组比较). 由于链表中的节点是一个结构体类型,并且结点中有一个成员用于指向下一个结点.所以定义作为结点的格 ...