ConcurrentLinkedQueue 源码解读
一、介绍
ConcurrentLinkedQueue 是一个基于链接节点的无界线程安全队列,非阻塞,它采用先进先出的规则对节点进行排序,当我们添加一个元素的时候,它会添加到队列的尾部;当我们获取一个元素时,它会返回队列头部的元素。
ConcurrentLinkedQueue 采用非阻塞的方式实现线程安全队列,它采用了"wait-free"算法(即CAS算法)来实现。
ConcurrentLinkedQueue 由 head 节点和 tail 节点组成,每个节点(Node)由节点元素(item)和指向下一个节点(next)的引用组成,节点与节点之间就是通过这个 next 关联起来,从而组成一张链表结构的队列。默认情况下head节点存储的元素为 null,tail 节点等于 head 节点。
二、源码解读
现在我们有了 head 和 tail 节点,如果按照我们平常的思维,head 节点即头节点,tail 节点即尾节点。那么入队列的时候,将 tail 的 next 节点设置为 newNode,将 newNode 设置为 tail;出队列的时候,将 head 节点元素返回,head 的 next 节点设置为 head。实现代码如下:
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
Node<E> n = new Node<E>(e);
for (; ; ) {
Node<E> t = tail;
if (t.casNext(null, n) && casTail(t, n)) {
return true;
}
}
}
不要怀疑你的思维,这样的做法完全是可行的。
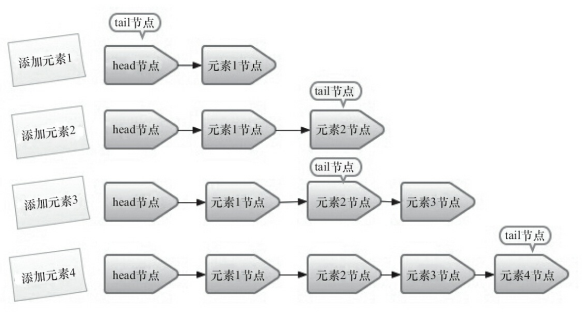
这样的做法 tail 节点永远作为队列的尾节点,head 节点永远为队列的头节点。实现代码量非常少,而且逻辑清晰和易懂。但是,这么做有个缺点,每次都需要使用循环 CAS 更新 tail 节点。所以 doug lea 为了减少 CAS 更新 tail 节点的次数,提高入队的效率,使用增加循环来控制 tail 节点的更新频率,并不是每次节点入队后都将 tail 节点更新成尾节点,而是当 tail 节点和尾节点不一致时(也就是循环两次)才更新 tail 节点。如下图:
想要读懂 ConcurrentLinkedQueue 的源码,最好先搞懂以下特质:
- 队列中任意时刻只有最后一个元素的 next 为 null
- head 和 tail 不会是 null(哨兵节点的设计)
- head 未必是队列中第一个元素(head指向的可能是一个已经被移除的元素)
- tail 未必是队列中最后一个元素(tail.next 可以不为 null)
- 一旦某个元素的 item 变为 null,就意味着它不再是队列中的有效元素了,并且会将已删除节点的 next 指针指向自身。
- 入队列
public boolean offer(E e) {
// 1.
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
// 2.
if (q == null) {
// 3.
if (p.casNext(null, newNode)) {
// 4.
if (p != t)
casTail(t, newNode);
return true;
}
}
// 5.
else if (p == q)
p = (t != (t = tail)) ? t : head;
else
// 6.
p = (p != t && t != (t = tail)) ? t : q;
}
}
- 队列中的元素不允许为 null,否则抛出一个 NullPointerException
- q == null 说明 p 是队列中最后一个元素
- CAS 设置 newNode 入队
- t 是当前线程读到的 tail 快照,p 是上面 CAS 队列中最后一个元素。当 p != t 时说明需要更新 tail 节点。如果 CAS 失败则说明 tail 已经被其它线程更新过了,这没关系。
- 什么情况下 p == q 呢?只有当 p 元素已经不在队列中了,即 p == p.next。这时候怎么办呢?重新读取一次 tail 到快照 t。如果 t 发生变化,则从新的 tail 节点继续下去(注意这里的设值和 for 循环中的初始值一样,表明重新开始,继续尝试)。如果 t 没有发生变化,说明 tail 元素也已经在队列外了(因为队列是先进先出),这种情况下我们需要从 head 继续遍历下去。
- 如果 p 与 t 相等,说明 p 不是尾节点,则让 p 继续向后移动一个节点; 如果 p 和 t 不相等,则说明已经经历至少两轮循环(仍然没有入队), 则重新读取一次 tail 到 t,p = t(和上面 for 的初始值一样),表示重新开始尝试入队。
- 出队列
public E poll() {
restartFromHead:
for (;;) {
// 1.
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
// 2.
if (item != null && p.casItem(item, null)) {
// 3.
if (p != h)
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
// 4.
else if ((q = p.next) == null) {
updateHead(h, p);
return null;
}
// 5.
else if (p == q)
continue restartFromHead;
// 6.
else
p = q;
}
}
}
- h 作为 head 的快照节点,p 初始设置为 head,q = null。
- CAS 成功将 item 设置为 null,表明已经移除了元素(注意这个时候该元素还没有真正移出队列,p = p.next 的动作在 updateHead 中完成)。这里的 item != null 判断也是为了尽可能避免无意义的CAS。
- 当 p 不等于 h,说明 head 节点存在滞后性,需要更新 head 节点。如果 p.next 节点不等于 null,则把 head 设置为 p.next;如果 p.next == null,表明 p 已经是最后一个节点了,没办法,也只能将 head 放在 p 节点上了。updateHead 还会做一个动作 — p = p.next,把滞后的 p 节点正式移出队列。
- 同第3点解释类似,如果 p.next == null,表明已经是最后一个节点了,则只能更新 head 为 p 节点,返回 null。
- 什么情况下会出现 p == q 呢?即 p == p.next 。出现这种情况,表明其他线程提前完成, p 元素已经被移出队列。这时候再继续循环意义不大,所以干脆重新开始,重新读一次 head 到快照 h,再尝试移除元素。
- p 向后移一位(这时 q = p.next),继续尝试移除元素。
三、API 使用
| 返回值 | 方法 | 说明 |
|---|---|---|
| boolean | add(E e) / offer(E e) | 在该队列的尾部插入指定的元素 |
| boolean | addAll(Collection<? extends E> c) | 按照集合迭代器返回的顺序追加到队列的末尾 |
| boolean | contains(Object o) | 队列中是否包含指定元素 |
| boolean | isEmpty() | 如果队列中部包含元素,则返回 true |
| Iterator | iterator() | 返回此队列中元素的迭代器,从头元素开始迭代 |
| E | peek() | 检索但不删除队列的头部,如果此队列为空,则返回 null |
| E | poll() | 检索并删除队列的头部,如果此队列为空,则返回 null |
| boolean | remove(Object o) | 从该队列中删除指定元素的单个实例(如果存在) |
| int | size() | 返回队列中元素的个数 |
| T[] | toArray(T[] a) | 队列转成指定类型的数组 |
ConcurrentLinkedQueue 源码解读的更多相关文章
- ConcurrentLinkedQueue源码解读
1.简介 ConcurrentLinkedQueue是JUC中的基于链表的无锁队列实现.本文将解读其源码实现. 2. 论文 ConcurrentLinkedQueue的实现是以Maged M. Mic ...
- JDK容器类List,Set,Queue源码解读
List,Set,Queue都是继承Collection接口的单列集合接口.List常用的实现主要有ArrayList,LinkedList,List中的数据是有序可重复的.Set常用的实现主要是Ha ...
- SDWebImage源码解读之SDWebImageDownloaderOperation
第七篇 前言 本篇文章主要讲解下载操作的相关知识,SDWebImageDownloaderOperation的主要任务是把一张图片从服务器下载到内存中.下载数据并不难,如何对下载这一系列的任务进行设计 ...
- SDWebImage源码解读 之 NSData+ImageContentType
第一篇 前言 从今天开始,我将开启一段源码解读的旅途了.在这里先暂时不透露具体解读的源码到底是哪些?因为也可能随着解读的进行会更改计划.但能够肯定的是,这一系列之中肯定会有Swift版本的代码. 说说 ...
- SDWebImage源码解读 之 UIImage+GIF
第二篇 前言 本篇是和GIF相关的一个UIImage的分类.主要提供了三个方法: + (UIImage *)sd_animatedGIFNamed:(NSString *)name ----- 根据名 ...
- SDWebImage源码解读 之 SDWebImageCompat
第三篇 前言 本篇主要解读SDWebImage的配置文件.正如compat的定义,该配置文件主要是兼容Apple的其他设备.也许我们真实的开发平台只有一个,但考虑各个平台的兼容性,对于框架有着很重要的 ...
- SDWebImage源码解读_之SDWebImageDecoder
第四篇 前言 首先,我们要弄明白一个问题? 为什么要对UIImage进行解码呢?难道不能直接使用吗? 其实不解码也是可以使用的,假如说我们通过imageNamed:来加载image,系统默认会在主线程 ...
- SDWebImage源码解读之SDWebImageCache(上)
第五篇 前言 本篇主要讲解图片缓存类的知识,虽然只涉及了图片方面的缓存的设计,但思想同样适用于别的方面的设计.在架构上来说,缓存算是存储设计的一部分.我们把各种不同的存储内容按照功能进行切割后,图片缓 ...
- SDWebImage源码解读之SDWebImageCache(下)
第六篇 前言 我们在SDWebImageCache(上)中了解了这个缓存类大概的功能是什么?那么接下来就要看看这些功能是如何实现的? 再次强调,不管是图片的缓存还是其他各种不同形式的缓存,在原理上都极 ...
随机推荐
- C#中unit
整理的百度百科的一些关于UNIT的资料 中文名UINT 外文名typedef unsigned short UIN 性 质 32位无符号整数 应 用 是unsigned int派生出来的 ...
- Python基础之格式化输出、运算符、数字与布尔值互换以及while...else
python是一天学一点,就这样零零碎碎…… 格式化输出 %是占位符,%s是字符串格式,%d整数格式,%f是浮点数格式 name = input('输入姓名') age = input('输入年龄') ...
- HTML --- <a href=”#”>与 <a href=”javascript:void(0)” 的区别
<a href=”#”>中的“#”其实是锚点的意思,默认为#top,所以当页面比较长的时候,使用这种方式会让页面刷新到页首(页面的最上部) javascript:void(0)其实是一个死 ...
- nginx文件名逻辑漏洞_CVE-2013-4547漏洞复现
nginx文件名逻辑漏洞_CVE-2013-4547漏洞复现 一.漏洞描述 这个漏洞其实和代码执行没有太大的关系,主要原因是错误地解析了请求的URL,错误地获取到用户请求的文件名,导致出现权限绕过.代 ...
- HTTP,TCP,IP详解
互联网协议包含了上百种协议标准,但是最重要的两个协议是TCP和IP协议,所以,大家把互联网的协议简称TCP/IP协议. 通信的时候,双方必须知道对方的标识,好比发邮件必须知道对方的邮件地址.互联网上每 ...
- CentOS 配置阿里云 NTP 服务
NTP 是网络时间协议(Network Time Protocol),NTP 服务能保证服务器的本地时间与标准时间同步. ▶ 配置时区信息 1.删除系统里的当地时间链接 sudo rm /etc/lo ...
- java的jar打包工具的使用
java的jar打包工具的使用 java的jar是一个打包工具,用于将我们编译后的class文件打包起来,这里面主要是举一个例子用来说明这个工具的使用. 在C盘下的temp文件夹下面: ...
- 使用Arthas 获取Spring ApplicationContext还原问题现场
## 背景 最近来了个实习僧小弟,安排他实现对目标网站 连通性检测的小功能,简单讲就是将下边的shell 脚本换成Java 代码来实现 ``` 1#!/bin/bash 2URL="http ...
- Cannot attach the file “MvcMovie.mdf” as database “aspnet-MvcMovie”
今天在微软开发人员官网上学习asp.net mvc5入门的时候,遇到一个棘手的问题,我是按照教程一步一步操作的,但期间遇到一个自己觉得莫名其妙的问题,教程中也没有提到这个, 在添加新字段这一章节,跟着 ...
- 在vue-cli 3中, 给stylus、sass样式传入共享的全局变量
在开发中有时,我们定义了大量的基础样式变量,例如: 大量的vue单文件组件会用到这些变量,每个组件都引人一次又太麻烦.全局引入是个不错的方法,于是,在main.js 中引入variable.styl文 ...