1、Spark 2.1 源码编译支持CDH
一、准备工作
1、安装Java, 配置环境变量, 版本为JDK1.7或者以上
export JAVA_HOME=/usr/java/default
export JRE_HOME=/usr/java/default/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH2、安装Maven, 版本为3.3.9或者以上
export MAVEN_HOME=/usr/local/apache-maven-3.3.9
export PATH=$MAVEN_HOME/bin:$PATH二、编译Spark的源码包
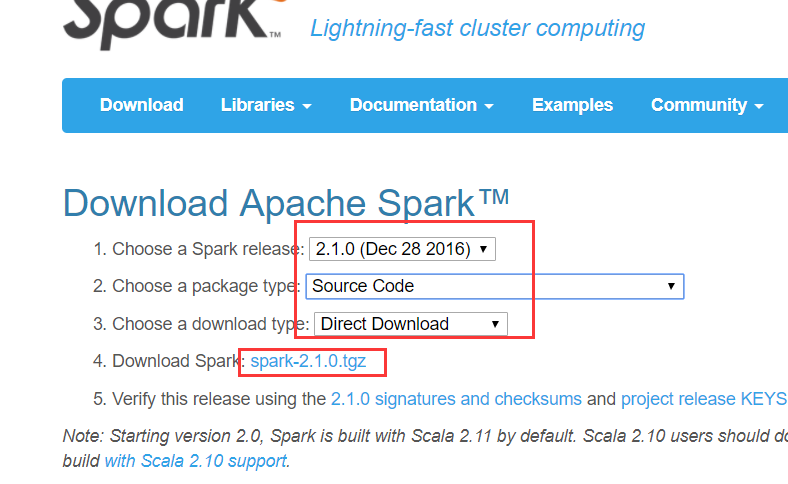
1、下载spark 2.1.0的源码包
2、增加cdh的repository
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>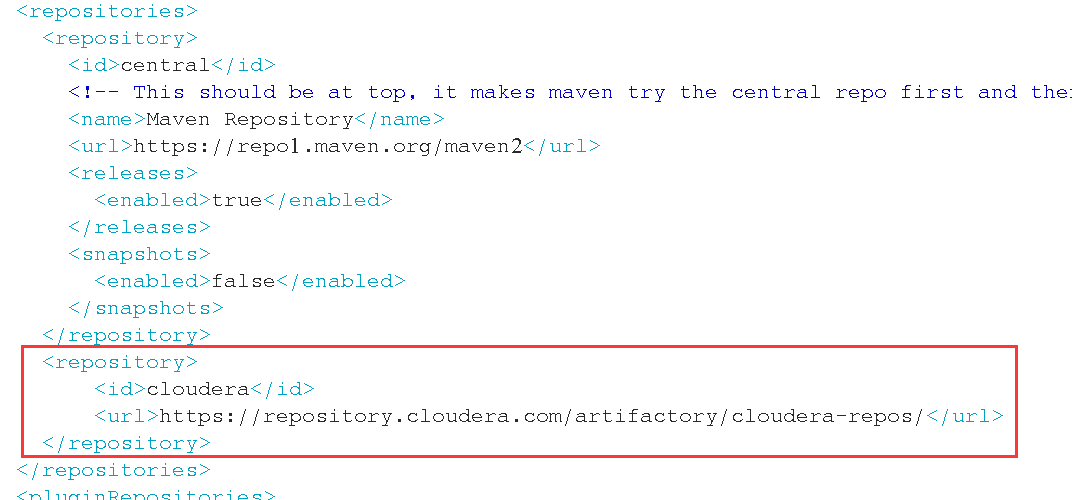
3、开始编译
./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.7.0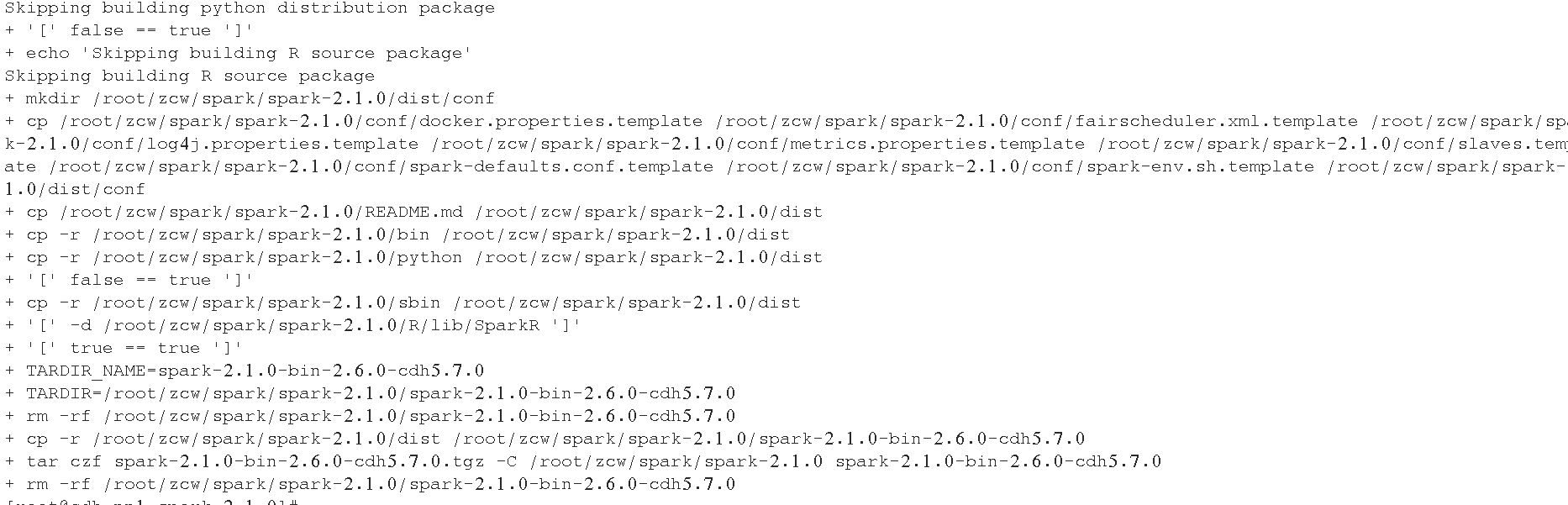
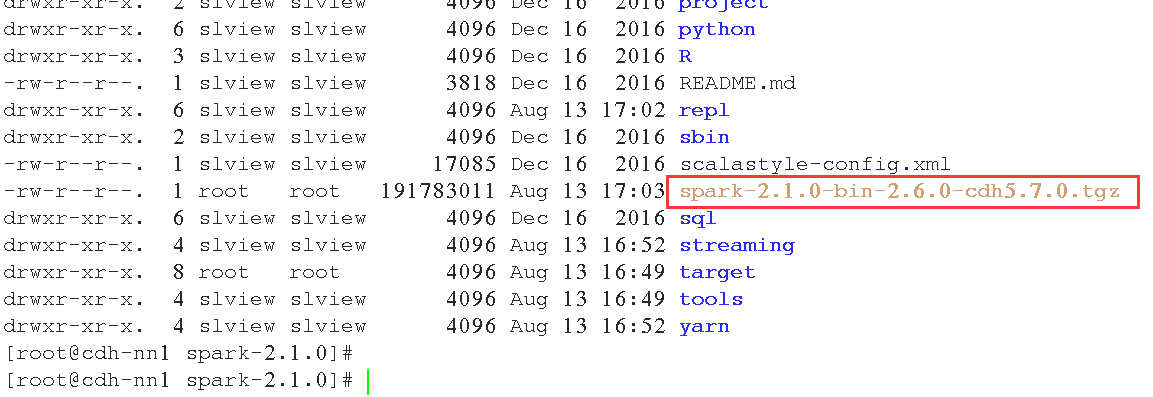
三、测试
1、提交到yarn上面

# export HADOOP_CONF_DIR=/etc/hadoop/conf
val file=spark.sparkContext.textFile("/tmp/appveyor.yml")
val wc = file.flatMap(line => line.split(",")).map(word=>(word,1)).reduceByKey(_ + _)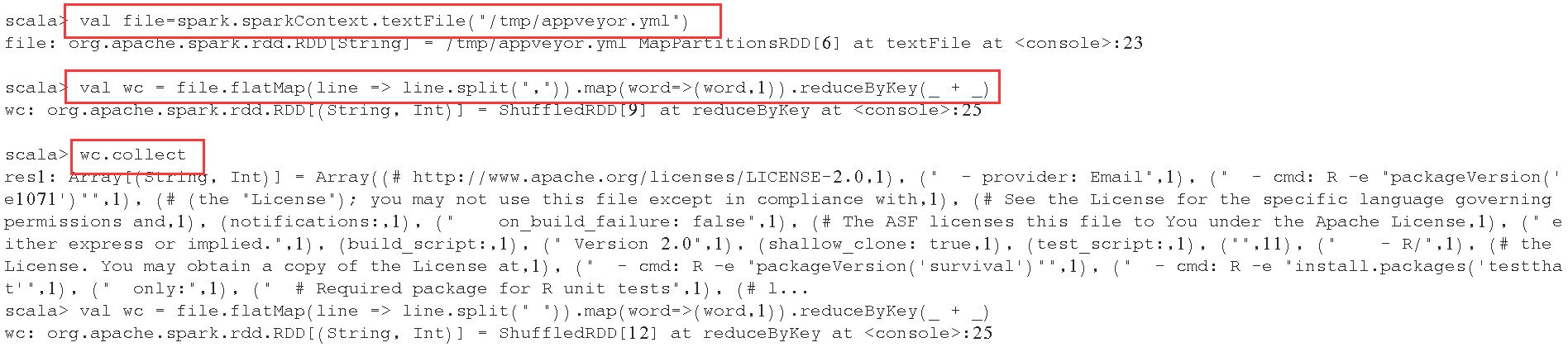
2、访问hive的表

1、Spark 2.1 源码编译支持CDH的更多相关文章
- dhcp源码编译支持4G上网卡
1. tar xvzf dhcp-4.2.5-P1.tar.gz 2. ./configure --host=arm-linux ac_cv_file__dev_random=yes 3. vi bi ...
- Spark环境搭建(六)-----------sprk源码编译
想要搭建自己的Hadoop和spark集群,尤其是在生产环境中,下载官网提供的安装包远远不够的,必须要自己源码编译spark才行. 环境准备: 1,Maven环境搭建,版本Apache Maven 3 ...
- 基于cdh5.10.x hadoop版本的apache源码编译安装spark
参考文档:http://spark.apache.org/docs/1.6.0/building-spark.html spark安装需要选择源码编译方式进行安装部署,cdh5.10.0提供默认的二进 ...
- Spark记录-源码编译spark2.2.0(结合Hive on Spark/Hive on MR2/Spark on Yarn)
#spark2.2.0源码编译 #组件:mvn-3.3.9 jdk-1.8 #wget http://mirror.bit.edu.cn/apache/spark/spark-2.2.0/spark- ...
- Spark 2.1.1 源码编译
Spark 2.1.1 源码编译 标签(空格分隔): Spark Spark 源码编译 环境准备与起因 由于线上Spark On Yarn Spark Streaming程序在消费kafka 写入HD ...
- Apache Spark源码走读之9 -- Spark源码编译
欢迎转载,转载请注明出处,徽沪一郎. 概要 本来源码编译没有什么可说的,对于java项目来说,只要会点maven或ant的简单命令,依葫芦画瓢,一下子就ok了.但到了Spark上面,事情似乎不这么简单 ...
- Spark源码编译
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3822995.html spark源码编译步骤如下: cd /home/hdpusr/workspace ...
- spark源码编译记录
spark在项目中已经用了一段时间了,趁现在空闲,下个源码编译在IDEA里面阅读下,特此记录过程. 前提已经安装maven和git 1.上官网下载源码的包: 2.然后解压到一个文件夹 3.编译,编译的 ...
- centos7.6环境zabbix3.2源码编译安装版升级到zabbix4.0长期支持版
zabbix3.2源码编译安装版升级到zabbix4.0长期支持版 项目需求: .2版本不再支持,想升级成4.0的长期支持版 环境介绍: zabbix服务端是编译安装的,数据库和web在一台机器上 整 ...
随机推荐
- bs4-BeautifulSoup
1.BeautifulSoup下载 pip install BeautifulSoup4 或者 pip install bs4 pip install lxml #解析器 2.BeautifulSou ...
- 小白系统篇-windows 系统安装
现阶段装系统的方法基本有几种1.硬盘安装2.光驱安装3.PE(u盘即可)安装 现在比较主流方便的用pe安装,所以我们这边就说一下PE安装系统的方法 首先我们了解下系统镜像,也就是你装系统所需得到文件( ...
- js 设计模式——状态模式
状态模式 允许一个对象在其内部状态改变时改变它的行为,对象看起来似乎修改了它的类. 简单的解释一下: 第一部分的意思是将状态封装成独立的类,并将请求委托给当前的状态对象,当对象的内部状态改变时,会带来 ...
- app发布当天,用户无法登录
原因:当用户登录时候有商城用户的触发器存在,它会让商城用户也更新成登录状态. 由于用户量大,导致数据库锁死. 最后解决案:删掉触发器,在app的接口登录程序里,追加商城用户更新成登录的操作. 他案1: ...
- JSON格式提取相同属性的某个值
[ {UID:"222",value:"111"}, {UID:"222",value:"103"}, {UID:&qu ...
- d3.js V5版本在vue里使用 自定义节点图片
var width = this.$refs.topInfo.offsetWidth; var height = this.$refs.topInfo.offsetHeight; var img_w ...
- .NET CORE 怎么样从控制台中读取输入流
.NET CORE 怎么样从控制台中读取输入流 从Console.ReadList/Read 的源码中,可学习到.NET CORE 是怎么样来读取输入流. 也可以学习到是如何使用P/Invoke来调用 ...
- ZOJ3435
题意略. 思路: 将每一个点的坐标 (x,y,z) 与 (1,1,1) 相减,得到向量 (x - 1,y - 1,z - 1) 我们实际上就是要求出 这样互质的三元组有多少对就行了. 我们把这个长方体 ...
- CSS文件引入link和@import 区别
1.(本质区别)link 属于 HTML 标签,而 @import 完全是 css 提供的一种导入 css 文件的规则. 2.文件加载时机有差别: 当一个页面被加载的时候,link 引用的 css 会 ...
- 小白专场-多项式乘法与加法运算-c语言实现
目录 一.题意理解 二.求解思路 三.多项式的表示 3.1 数组 3.2 链表 四.程序框架搭建 五.如何读入多项式 六.如何将两个多项式相加 七.如何将两个多项式相乘 八.如何将多项式输出 一.题意 ...