女神大会
不是知道有多少人知道“懂球帝”这个 APP(网站),又有多少人关注过它的一个栏目“女神大会”,在这里,没有足球,只有女神哦。
女神评分,全部是由球迷来决定,是不是很赤鸡,下面就一起来看看球迷眼中女神排名吧。
开工
首先,我们可以通过抓取懂球帝 APP 的网络请求,拿到一个 API,
http://api.dongqiudi.com/search?keywords=type=all&page=
我们主要关注 ID 和 thumb,ID 后面用来拼接女神所在页面的 HTML 地址,thumb 就用来收藏。
def get_list(page): nvshen_id_list = [] nvshen_id_picture = [] for i in range(1, page): print("获取第" + str(i) + "页数据") url = 'http://api.dongqiudi.com/search?keywords=%E5%A5%B3%E7%A5%9E%E5%A4%A7%E4%BC%9A&type=all&page=' + str(i) html = requests.get(url=url).text news = json.loads(html)['news'] if len(news) == 0: print("没有更多啦") break nvshen_id = [k['id'] for k in news] nvshen_id_list = nvshen_id_list + nvshen_id nvshen_id_picture = nvshen_id_picture + [{k['id']: k['thumb']} for k in news] time.sleep(1) return nvshen_id_list, nvshen_id_picture
接下来,通过观察,我们能够得到,每个女神所在的页面地址都是这样的,
https://www.dongqiudi.com/archive/**.html
其中 ** 就是上面拿到的 ID 值,那么获取 HTML 页面的代码也就有了
def download_page(nvshen_id_list): for i in nvshen_id_list: print("正在下载ID为" + i + "的HTML网页") url = 'https://www.dongqiudi.com/archive/%s.html' % i download = DownloadPage() html = download.getHtml(url) download.saveHtml(i, html) time.sleep(2) class DownloadPage(object): def getHtml(self, url): html = requests.get(url=url).content return html def saveHtml(self, file_name, file_content): with open('html_page/' + file_name + '.html', 'wb') as f: f.write(file_content)
防止访问限制,每次请求都做了2秒的等待
没办法,继续斗争。重新分析,发现请求中有携带一个 cookie,哈哈,这个我们已经轻车熟路啦
对 requests 请求增加 cookie,同时再把 headers 里面增加个 User-Agent,再试
最后,就是解析下载到本地的 HTML 页面了,页面的规则就是,本期女神介绍页面,会公布上期女神的综合得分,而我们的主要任务就是获取各个女神的得分
def deal_loaclfile(nvshen_id_picture): files = os.listdir('html_page/') nvshen_list = [] special_page = [] for f in files: if f[-4:] == 'html' and not f.startswith('~'): htmlfile = open('html_page/' + f, 'r', encoding='utf-8').read() content = BeautifulSoup(htmlfile, 'html.parser') try: tmp_list = [] nvshen_name = content.find(text=re.compile("上一期女神")) if nvshen_name is None: continue nvshen_name_new = re.findall(r"女神(.+?),", nvshen_name) nvshen_count = re.findall(r"超过(.+?)人", nvshen_name) tmp_list.append(''.join(nvshen_name_new)) tmp_list.append(''.join(nvshen_count)) tmp_list.append(f[:-4]) tmp_score = content.find_all('span', attrs={'style': "color:#ff0000"}) tmp_score = list(filter(None, [k.string for k in tmp_score])) if '.' in tmp_score[0]: if len(tmp_score[0]) > 3: tmp_list.append(''.join(list(filter(str.isdigit, tmp_score[0].strip())))) nvshen_list = nvshen_list + get_picture(content, tmp_list, nvshen_id_picture) else: tmp_list.append(tmp_score[0]) nvshen_list = nvshen_list + get_picture(content, tmp_list, nvshen_id_picture) elif len(tmp_score) > 1: if '.' in tmp_score[1]: if len(tmp_score[1]) > 3: tmp_list.append(''.join(list(filter(str.isdigit, tmp_score[1].strip())))) nvshen_list = nvshen_list + get_picture(content, tmp_list, nvshen_id_picture) else: tmp_list.append(tmp_score[1]) nvshen_list = nvshen_list + get_picture(content, tmp_list, nvshen_id_picture) else: special_page.append(f) print("拿不到score的HTML:", f) else: special_page.append(f) print("拿不到score的HTML:", f) except: print("解析出错的HTML:", f) raise return nvshen_list, special_page def get_picture(c, t_list, n_id_p): print("进入get_picture函数:") nvshen_l = [] tmp_prev_id = c.find_all('a', attrs={"target": "_self"}) for j in tmp_prev_id: if '期' in j.string: href_list = j['href'].split('/') tmp_id = re.findall(r"\d+\.?\d*", href_list[-1]) if len(tmp_id) == 1: prev_nvshen_id = tmp_id[0] t_list.append(prev_nvshen_id) for n in n_id_p: for k, v in n.items(): if k == prev_nvshen_id: t_list.append(v) print("t_list", t_list) nvshen_l.append(t_list) print("get_picture函数结束") return nvshen_l
对于我们最后解析出来的数据,我们直接保存到 csv 文件中,如果数据量比较大的话,还可以考虑保存到 mongodb 中。
def save_to_file(nvshen_list, filename): with open(filename + '.csv', 'w', encoding='utf-8') as output: output.write('name,count,score,weight_score,page_id,picture\n') for row in nvshen_list: try: weight = int(''.join(list(filter(str.isdigit, row[1])))) / 1000 weight_2 = float(row[2]) + float('%.2f' % weight) weight_score = float('%.2f' % weight_2) rowcsv = '{},{},{},{},{},{}'.format(row[0], row[1], row[3], weight_score, row[4], row[5]) output.write(rowcsv) output.write('\n') except: raise
对于女神的得分,又根据打分的人数,做了个加权分数
def save_pic(url, nick_name): resp = requests.get(url) if not os.path.exists('picture'): os.mkdir('picture') if resp.status_code == 200: with open('picture' + f'/{nick_name}.jpg', 'wb') as f: f.write(resp.content)
直接从拿到的 thumb 地址中下载图片,并保存到本地。
做一些图
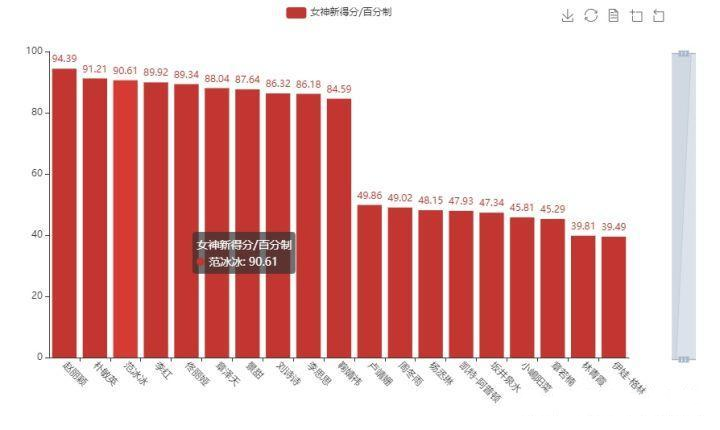
首先我们先做一个柱状图,看看排名前10和倒数前10的情况
可以看到,朱茵、石川恋和高圆圆位列三甲,而得分高达95+的女神也有7位之多。那么排名后10位的呢,自行看吧,有没有人感到有点扎心呢,哈哈哈。同时,也能够从打分的人数来看出,人气高的女神,普遍得分也不低哦。
不过,该排名目前只代表球迷心目中的榜单,不知道程序猿心中的榜单会是怎样的呢
百度有免费的人脸检测 API,只要输入图片,就能够得到对应的人脸得分,还是非常方便的,感兴趣的小伙伴可以去官网看看哦。
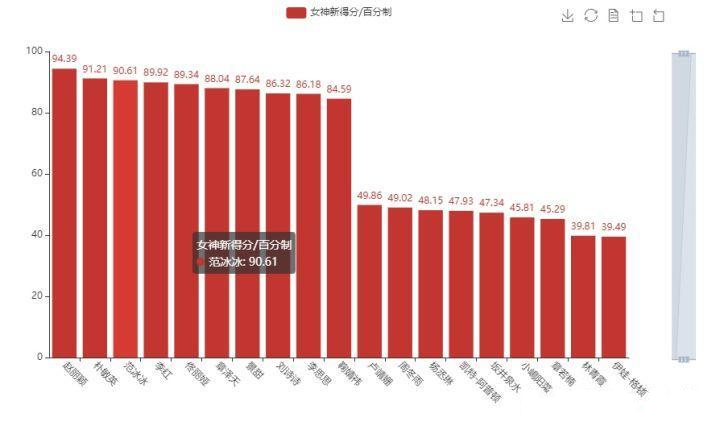
我这里直接给出了我通过百度 API 得出的女神新得分,一起来看看吧
哈哈哈哈,AI 的评分,对于图片的依赖太高,纯属娱乐。
- 是的,你没看错!Python可以实现自动化办公
是的,你没看错!Python可以实现自动化办公 公众号[伤心的辣条],如今越来越多的人加入到学习Python的队伍当中,尤其是对于很多职场人来说,不管你是程序员还是非程序员,Python已经为很多职场 ...
- steam夏日促销悄然开始,用Python爬取排行榜上的游戏打折信息
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 不知不觉,一年一度如火如荼的steam夏日促销悄然开始了.每年通过大大小小 ...
- python爬爬爬之单网页html页面爬取
python爬爬爬之单网页html页面爬取 作者:vpoet mail:vpoet_sir@163.com 注:随意copy 不用告诉我 #coding:utf-8 import urllib2 Re ...
- python爬取免费优质IP归属地查询接口
python爬取免费优质IP归属地查询接口 具体不表,我今天要做的工作就是: 需要将数据库中大量ip查询出起归属地 刚开始感觉好简单啊,毕竟只需要从百度找个免费接口然后来个python脚本跑一晚上就o ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- Python爬取620首虾米歌曲,揭秘五月天为什么狂吸粉?!
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: CDA数据分析师 PS:如有需要Python学习资料的小伙伴可以加点 ...
- 用Python爬E站本
用Python爬E站本 一.前言 参考并改进自 OverJerry 大佬的 教你怎么用Python爬取E站的本子_OverJerry. 本文为技术学习记录,不提供访问无存在网站的任何方法,也不包含不和 ...
- Python爬取视频指南
摘自:https://www.jianshu.com/p/9ca86becd86d 前言 前两天尔羽说让我爬一下菜鸟窝的教程视频,这次就跟大家来说说Python爬取视频的经验 正文 https://w ...
- Python 爬取陈都灵百度图片
Python 爬取陈都灵百度图片 标签(空格分隔): 随笔 今天意外发现了自己以前写的一篇爬虫脚本,爬取的是我的女神陈都灵,尝试运行了一下发现居然还能用.故把脚本贴出来分享一下. import req ...
随机推荐
- 母版页 treeview控件 SiteMapPath控件 treeview数据库绑定模式
母版页就是网站中一样的部分母版页的后缀名是.Master可以把母版页当成一个页面 想让哪里是别的内容就可以 通过如下: <asp:ContentPlaceHolder ID="C ...
- (转)深入解析TensorFlow中滑动平均模型与代码实现
本文链接:https://blog.csdn.net/m0_38106113/article/details/81542863 指数加权平均算法的原理 TensorFlow中的滑动平均模型使用的是滑动 ...
- 在python操作数据库中游标的使用方法
cursor就是一个Cursor对象,这个cursor是一个实现了迭代器(def__iter__())和生成器(yield)的MySQLdb对象,这个时候cursor中还没有数据,只有等到fetcho ...
- 松软科技web课堂:SQLServer之NOW() 函数
NOW() 函数 NOW 函数返回当前的日期和时间. 提示:如果您在使用 Sql Server 数据库,请使用 getdate() 函数来获得当前的日期时间. SQL NOW() 语法 SELECT ...
- Locust压测结果准确性验证
最近闲着没事做,就重新研究了一下基于python语言的Locust性能测试框架 发现在压测的过程中,虽然设置了100并发,但是通过实际监控,完全看不到100并发压测的效果 通过代码AOP日志监控接口的 ...
- python数据库模块
安装数据库 [mariadb] name = MariaDB baseurl = http://yum.mariadb.org/10.3/centos7-amd64 gpgkey=https://yu ...
- Saltstack_使用指南18_API
1. 主机规划 salt 版本 [root@salt100 ~]# salt --version salt (Oxygen) [root@salt100 ~]# salt-minion --versi ...
- python-初始网络编程
一.服务端和客户端 BS架构 (腾讯通软件:server+client) CS架构 (web网站) C/S架构与socket的关系: 我们学习socket就是为了完成C/S架构的开发 二.OSI七层 ...
- Linux-3.14.12内存管理笔记【伙伴管理算法(3)】
前面分析了伙伴管理算法的初始化,在切入分析代码实现之前,例行先分析一下其实现原理. 伙伴管理算法(也称之为Buddy算法),该算法将所有空闲的页面分组划分为MAX_ORDER个页面块链表进行管理,其中 ...
- 洛谷 P5638 光骓者的荣耀
洛谷 P5638 [CSGRound2]光骓者的荣耀 洛谷传送门 题目背景 小 K 又在做白日梦了.他进入到他的幻想中,发现他打下了一片江山. 题目描述 小 K 打下的江山一共有nn个城市,城市ii和 ...