Redis高级应用解析:缓存穿透、击穿、雪崩
1 背景
像我们去面试一些大公司的时候,就会遇到一些关于缓存的问题。可能很多同学都是接触过,多多少少了解一些,但是如果没有好好记录这些内容,不熟练精通的话,在真正面试的时候,就很难答出来了。
在我们的平常的项目中多多少少都会使用到缓存,因为一些数据我们没有必要每次查询的时候都去查询到数据库。
特别是高 QPS 的系统,每次都去查询数据库,对于你的数据库来说将是灾难。
今天我们不牵涉多级缓存的知识,就把系统使用到的缓存方案,不管是一级还是多级的都统称为缓存,主要是为了讲述使用缓存的时候可能会遇到的一些问题以及一些解决办法。
我们使用缓存时,我们的业务系统大概的调用流程如下图:
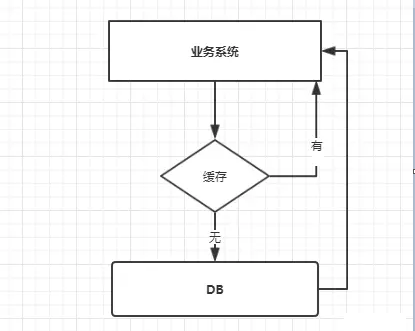
当我们查询一条数据时,先去查询缓存,如果缓存有就直接返回,如果没有就去查询数据库,然后返回。这种情况下就可能会出现一些现象。
2 缓存穿透
2.1 什么是缓存穿透
正常情况下,我们去查询数据都是存在。
那么请求去查询一条压根儿数据库中根本就不存在的数据,也就是缓存和数据库都查询不到这条数据,但是请求每次都会打到数据库上面去。
这种查询不存在数据的现象我们称为缓存穿透。
2.2 穿透带来的问题
试想一下,如果有黑客会对你的系统进行攻击,拿一个不存在的id 去查询数据,会产生大量的请求到数据库去查询。可能会导致你的数据库由于压力过大而宕掉。
2.3 解决办法
2.3.1 缓存空值
之所以会发生穿透,就是因为缓存中没有存储这些空数据的key。从而导致每次查询都到数据库去了。
那么我们就可以为这些key对应的值设置为null 丢到缓存里面去。后面再出现查询这个key 的请求的时候,直接返回null 。
这样,就不用在到数据库中去走一圈了,但是别忘了设置过期时间。
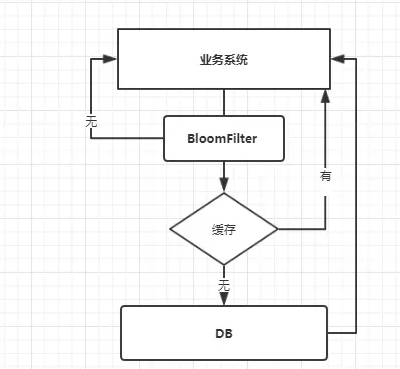
2.3.2 BloomFilter
BloomFilter 类似于一个hbase set 用来判断某个元素(key)是否存在于某个集合中。
这种方式在大数据场景应用比较多,比如 Hbase 中使用它去判断数据是否在磁盘上。还有在爬虫场景判断url 是否已经被爬取过。
这种方案可以加在第一种方案中,在缓存之前在加一层 BloomFilter ,在查询的时候先去 BloomFilter 去查询 key 是否存在,如果不存在就直接返回,存在再走查缓存 -> 查 DB。
流程图如下:
2.4 如何选择
针对于一些恶意攻击,攻击带过来的大量key 是不存在的,那么我们采用第一种方案就会缓存大量不存在key的数据。
此时我们采用第一种方案就不合适了,我们完全可以先对使用第二种方案进行过滤掉这些key。
针对这种key异常多、请求重复率比较低的数据,我们就没有必要进行缓存,使用第二种方案直接过滤掉。
而对于空数据的key有限的,重复率比较高的,我们则可以采用第一种方式进行缓存。
3 缓存击穿
3.1 什么是击穿
缓存击穿是我们可能遇到的第二个使用缓存方案可能遇到的问题。
在平常高并发的系统中,大量的请求同时查询一个 key 时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去。这种现象我们称为缓存击穿。
3.2 会带来什么问题
会造成某一时刻数据库请求量过大,压力剧增。
3.3 如何解决
上面的现象是多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。
其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
4、缓存雪崩
4.1 什么是缓存雪崩
缓存雪崩的情况是说,当某一时刻发生大规模的缓存失效的情况,比如你的缓存服务宕机了,会有大量的请求进来直接打到DB上面。结果就是DB 称不住,挂掉。
4.2 解决办法
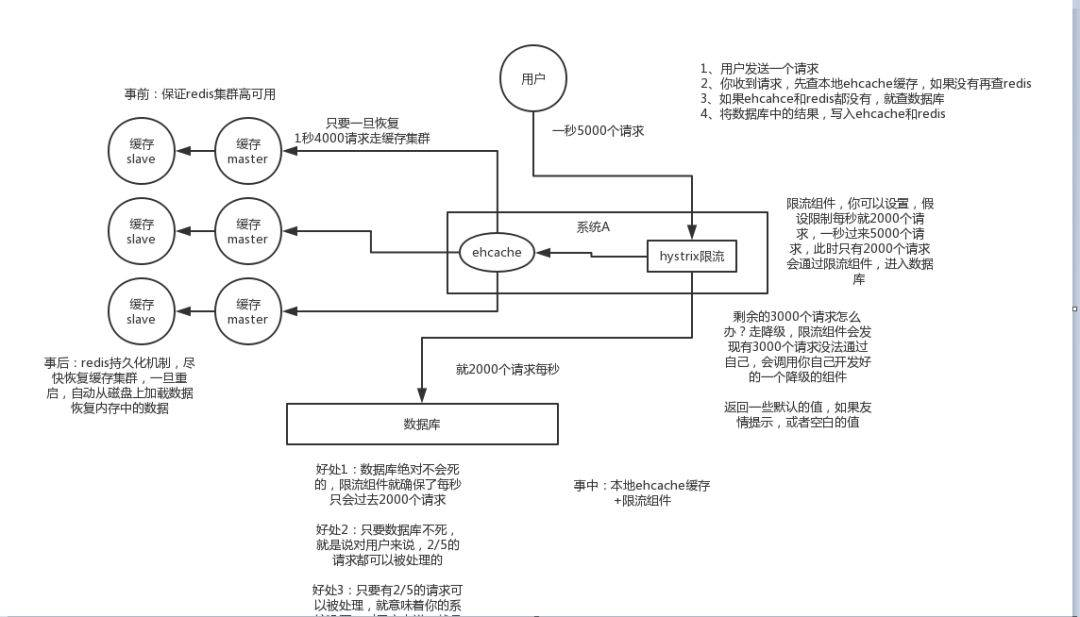
4.2.1 事前:
- 使用集群缓存,保证缓存服务的高可用
这种方案就是在发生雪崩前对缓存集群实现高可用,如果是使用 Redis,可以使用 主从+哨兵 ,Redis Cluster 来避免 Redis 全盘崩溃的情况。
4.2.2 事中:
- ehcache本地缓存 + Hystrix限流&降级,避免MySQL被打死
使用 ehcache 本地缓存的目的也是考虑在 Redis Cluster 完全不可用的时候,ehcache 本地缓存还能够支撑一阵。
使用 Hystrix进行限流 & 降级 ,比如一秒来了5000个请求,我们可以设置假设只能有一秒 2000个请求能通过这个组件,那么其他剩余的 3000 请求就会走限流逻辑。
然后去调用我们自己开发的降级组件(降级),比如设置的一些默认值呀之类的。以此来保护最后的 MySQL 不会被大量的请求给打死。
4.2.3 事后:
- 开启Redis持久化机制,尽快恢复缓存集群
一旦重启,就能从磁盘上自动加载数据恢复内存中的数据。
防止雪崩方案如下图所示:
5 解决热点数据集中失效问题
我们在设置缓存的时候,一般会给缓存设置一个失效时间,过了这个时间,缓存就失效了。
对于一些热点的数据来说,当缓存失效以后会存在大量的请求过来,然后打到数据库去,从而可能导致数据库崩溃的情况。
5.1 解决办法
5.1.1 设置不同的失效时间
为了避免这些热点的数据集中失效,那么我们在设置缓存过期时间的时候,我们让他们失效的时间错开。
比如在一个基础的时间上加上或者减去一个范围内的随机值。
5.1.2 互斥锁
结合上面的击穿的情况,在第一个请求去查询数据库的时候对他加一个互斥锁,其余的查询请求都会被阻塞住,直到锁被释放,从而保护数据库。
但是也是由于它会阻塞其他的线程,此时系统吞吐量会下降。需要结合实际的业务去考虑是否要这么做。
Redis高级应用解析:缓存穿透、击穿、雪崩的更多相关文章
- Redis中几个简单的概念:缓存穿透/击穿/雪崩,别再被吓唬了
Redis中几个“看似”高大上的概念,经常有人提到,某些好事者喜欢死扣概念,实战没多少,嘴巴里冒出来的全是高大上的名词,个人一向鄙视概念党,呵呵! 其实这几个概念:缓存穿透/缓存击穿/缓存雪崩,有一个 ...
- NoSQL & Redis 介绍、缓存穿透 & 击穿 & 雪崩
1. NoSql 简介 2. Redis 简介 2.1 Redis 的起源 2.2 缓存过期 & 缓存淘汰 3. 缓存异常 1)缓存穿透 2)缓存击穿 3)缓存雪崩 4)总结 1. NoSQL ...
- 《Redis - 穿透/击穿/雪崩/集中失效》
一:什么是缓存穿透? - 定义 - 正常情况下,我们在理想的条件下去查询缓存数据都是存在的. - 那么请求去查询一条数据库中不存在的数据,也就是缓存和数据库都查询不到这条数据. - 所以请求每次都会打 ...
- Redis缓存穿透和雪崩
缓存穿透 用户想要查询一个数据 在redis缓存数据库中没有获取到 就会向后端的数据库中查询. 当用户很多 都去访问后端数据库的话,这就会给数据库带来很大的压力. 常见场景:秒杀活动 等 解决方法: ...
- Redis 穿透 & 击穿 & 雪崩
原文:https://www.cnblogs.com/binghe001/p/13661381.html 缓存穿透 如果在请求数据时,在缓存层和数据库层都没有找到符合条件的数据,也就是说,在缓存层和数 ...
- 缓存穿透、雪崩、热点与Redis
(拼多多问:Redis雪崩解决办法) 导读:互联网系统中不可避免要大量用到缓存,在缓存的使用过程中,架构师需要注意哪些问题?本文以 Redis 为例,详细探讨了最关键的 3 个问题. 一.缓存穿透预防 ...
- Redis系列(八)--缓存穿透、雪崩、更新策略
1.缓存更新策略 1.LRU/LFU/FIFO算法剔除:例如maxmemory-policy 2.超时剔除,过期时间expire,对于一些用户可以容忍延时更新的数据,例如文章简介内容改了几个字 3.主 ...
- Redis-缓存穿透/击穿/雪崩
1. 简介 如图所示,一个正常的请求 客户端请求张铁牛的博客. 服务首先会请求redis,查看请求的内容是否存在. redis将请求结果返回给服务,如果返回的结果有数据则执行7:如果没有数据则会继续往 ...
- redis整理:常用命令,雪崩击穿穿透原因及方案,分布式锁实现思路,分布式锁redission(更新中)
redis个人整理笔记 reids常见数据结构 基本类型 String: 普通key-value Hash: 类似hashMap List: 双向链表 Set: 不可重复 SortedSet: 不可重 ...
随机推荐
- guava multimap介绍
引用一篇别人的博客,理解理解 http://vipcowrie.iteye.com/blog/1517338
- 9.1练习题5 差k素数对 题解
题目出处:洛谷 P1348 ,题面略有改编. 题目描述 给你两个数 n 和 k ,请求出所有小于等于 n 的相差为 k 的素数对. 输入格式 两个正整数n,k.1<=k<=n<=10 ...
- html的表格边框为什么会这么粗?
因为默认情况下,cellspacing = 2px. 当表格的 border 不为 0 的时候,单元格(cell)的 border 为 1. 只有当表格的 border 设置为 0 的时候,单元格的 ...
- 二、springBoot 整合 mybatis 项目实战
前言 上一篇文章开始了我们的springboot序篇,我们配置了mysql数据库,但是我们sql语句直接写在controller中并且使用的是jdbcTemplate.项目中肯定不会这样使用,上篇文章 ...
- 上手Dubbo之 环境搭建
和传统ssm整合--写XML配置文件 搭建服务的提供者和服务的消费者,实现服务消费者跨应用远程调用服务提供者 公共模块抽取 公共模块的抽取 服务的消费者远程调用服务的提供者, 最起码他自己要得到在服务 ...
- 02 (OC)* ViewController 的声明周期
一. UIViewController 的 生命周期 代码 示例 #pragma mark --- life circle // 非storyBoard(xib或非xib)都走这个方法 - (inst ...
- Java String 对象,你真的了解了吗?
String 对象的实现 String对象是 Java 中使用最频繁的对象之一,所以 Java 公司也在不断的对String对象的实现进行优化,以便提升String对象的性能,看下面这张图,一起了解一 ...
- 网站开发过程中的URL写法
在开发网页和服务器时发现,在很多地方需要写超链接 那么可以将超链接的使用者分为服务器和浏览器,以区分不同的写法 地址可能使用的情况: 1.跳转 2.转发 3.服务器资源地址 4.浏览器超链接 impo ...
- Python日志产生器
Python日志产生器 写在前面 有的时候,可能就是我们做实时数据收集的时候,会有一个头疼的问题就是,你会发现,你可能一下子,没有日志的数据源.所以,我们可以简单使用python脚本来实现产生实时的数 ...
- Maven项目运行报错提示找不到加载主类
遇到这个问题花了几小时时间看网上的各种解决方法.试了几种都没用,最后用了这种本办法. 亲测第三条 https://blog.csdn.net/yuliantao/article/details/766 ...