spring boot + druid + mybatis + atomikos 多数据源配置 并支持分布式事务
文章目录
一、综述
1.1 项目说明
本用例基于spring boot + druid + mybatis 配置多数据源,并采用 JTA 实现分布式事务。
源码仓库地址: https://github.com/heibaiying/spring-samples-for-all
1.2 项目结构
主要配置如下:

二、配置多数据源并支持分布式事务
2.1 导入基本依赖
除了mybatis 、durid 等依赖外,我们依靠切面来实现动态数据源的切换,所以还需要导入aop依赖。
最主要的是还要导入spring-boot-starter-jta-atomikos,Spring Boot通过Atomkos或Bitronix的内嵌事务管理器支持跨多个XA资源的分布式JTA事务,当发现JTA环境时,Spring Boot将使用Spring的JtaTransactionManager来管理事务。自动配置的JMS,DataSource和JPA beans将被升级以支持XA事务。
<!--mybatis starter-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.2</version>
</dependency>
<!--引入mysql驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>6.0.6</version>
</dependency>
<!--druid 依赖-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<!--aop starter-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<!--web starter -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--分布式事务依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jta-atomikos</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
2.2 在yml中配置多数据源信息
注意:Spring Boot 2.X 版本不再支持配置继承,多数据源的话每个数据源的所有配置都需要单独配置,否则配置不会生效。
这里我用的本地数据库mysql和mysql02,配置如下:
spring:
datasource:
druid:
db1:
url: jdbc:mysql://127.0.0.1:3306/mysql?characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
# 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时
initialSize: 5
# 最小连接池数量
minIdle: 5
# 最大连接池数量
maxActive: 10
# 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。
maxWait: 60000
# Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接。
timeBetweenEvictionRunsMillis: 60000
# 连接保持空闲而不被驱逐的最小时间
minEvictableIdleTimeMillis: 300000
# 用来检测连接是否有效的sql 因数据库方言而异, 例如 oracle 应该写成 SELECT 1 FROM DUAL
validationQuery: SELECT 1
# 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
testWhileIdle: true
# 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。
testOnBorrow: false
# 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。
testOnReturn: false
# 是否自动回收超时连接
removeAbandoned: true
# 超时时间(以秒数为单位)
remove-abandoned-timeout: 1800
db2:
url: jdbc:mysql://127.0.0.1:3306/mysql02?characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
# 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时
initialSize: 6
# 最小连接池数量
minIdle: 6
# 最大连接池数量
maxActive: 10
# 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。
maxWait: 60000
# Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接。
timeBetweenEvictionRunsMillis: 60000
# 连接保持空闲而不被驱逐的最小时间
minEvictableIdleTimeMillis: 300000
# 用来检测连接是否有效的sql 因数据库方言而异, 例如 oracle 应该写成 SELECT 1 FROM DUAL
validationQuery: SELECT 1
# 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
testWhileIdle: true
# 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。
testOnBorrow: false
# 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。
testOnReturn: false
# 是否自动回收超时连接
removeAbandoned: true
# 超时时间(以秒数为单位)
remove-abandoned-timeout: 1800
# WebStatFilter用于采集web-jdbc关联监控的数据。
web-stat-filter:
# 是否开启 WebStatFilter 默认是true
enabled: true
# 需要拦截的url
url-pattern: /*
# 排除静态资源的请求
exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*"
# Druid内置提供了一个StatViewServlet用于展示Druid的统计信息。
stat-view-servlet:
#是否启用StatViewServlet 默认值true
enabled: true
# 需要拦截的url
url-pattern: /druid/*
# 允许清空统计数据
reset-enable: true
login-username: druid
login-password: druid
2.3 进行多数据源的配置
1. 在启动类关闭springboot对数据源的自动化配置,由我们手动进行多数据源的配置
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})
public class DruidMybatisMultiApplication {
public static void main(String[] args) {
SpringApplication.run(DruidMybatisMultiApplication.class, args);
}
}
2. 创建多数据源配置类DataSourceFactory.java, 手动配置多数据源
- 这里我们创建druid数据源的时候,创建的是
DruidXADataSource,它继承自DruidDataSource并支持XA分布式事务; - 使用
AtomikosDataSourceBean包装我们创建的DruidXADataSource,使得数据源能够被 JTA 事务管理器管理; - 这里我们使用的sqlSessionTemplate是我们重写的
CustomSqlSessionTemplate,原生的sqlSessionTemplate是不能实现在一个事务中实现数据源切换的。(为了不占用篇幅,我会在后文再给出详细的原因分析)
/**
* @author : heibaiying
* @description : 多数据源配置
*/
@Configuration
@MapperScan(basePackages = DataSourceFactory.BASE_PACKAGES, sqlSessionTemplateRef = "sqlSessionTemplate")
public class DataSourceFactory {
static final String BASE_PACKAGES = "com.heibaiying.springboot.dao";
private static final String MAPPER_LOCATION = "classpath:mappers/*.xml";
/***
* 创建 DruidXADataSource 1 用@ConfigurationProperties自动配置属性
*/
@Bean
@ConfigurationProperties("spring.datasource.druid.db1")
public DataSource druidDataSourceOne() {
return new DruidXADataSource();
}
/***
* 创建 DruidXADataSource 2
*/
@Bean
@ConfigurationProperties("spring.datasource.druid.db2")
public DataSource druidDataSourceTwo() {
return new DruidXADataSource();
}
/**
* 创建支持XA事务的Atomikos数据源1
*/
@Bean
public DataSource dataSourceOne(DataSource druidDataSourceOne) {
AtomikosDataSourceBean sourceBean = new AtomikosDataSourceBean();
sourceBean.setXaDataSource((DruidXADataSource) druidDataSourceOne);
// 必须为数据源指定唯一标识
sourceBean.setUniqueResourceName("db1");
return sourceBean;
}
/**
* 创建支持XA事务的Atomikos数据源2
*/
@Bean
public DataSource dataSourceTwo(DataSource druidDataSourceTwo) {
AtomikosDataSourceBean sourceBean = new AtomikosDataSourceBean();
sourceBean.setXaDataSource((DruidXADataSource) druidDataSourceTwo);
sourceBean.setUniqueResourceName("db2");
return sourceBean;
}
/**
* @param dataSourceOne 数据源1
* @return 数据源1的会话工厂
*/
@Bean
public SqlSessionFactory sqlSessionFactoryOne(DataSource dataSourceOne)
throws Exception {
return createSqlSessionFactory(dataSourceOne);
}
/**
* @param dataSourceTwo 数据源2
* @return 数据源2的会话工厂
*/
@Bean
public SqlSessionFactory sqlSessionFactoryTwo(DataSource dataSourceTwo)
throws Exception {
return createSqlSessionFactory(dataSourceTwo);
}
/***
* sqlSessionTemplate与Spring事务管理一起使用,以确保使用的实际SqlSession是与当前Spring事务关联的,
* 此外它还管理会话生命周期,包括根据Spring事务配置根据需要关闭,提交或回滚会话
* @param sqlSessionFactoryOne 数据源1
* @param sqlSessionFactoryTwo 数据源2
*/
@Bean
public CustomSqlSessionTemplate sqlSessionTemplate(SqlSessionFactory sqlSessionFactoryOne,
SqlSessionFactory sqlSessionFactoryTwo) {
Map<Object, SqlSessionFactory> sqlSessionFactoryMap = new HashMap<>();
sqlSessionFactoryMap.put(Data.DATASOURCE1, sqlSessionFactoryOne);
sqlSessionFactoryMap.put(Data.DATASOURCE2, sqlSessionFactoryTwo);
CustomSqlSessionTemplate customSqlSessionTemplate = new CustomSqlSessionTemplate(sqlSessionFactoryOne);
customSqlSessionTemplate.setTargetSqlSessionFactories(sqlSessionFactoryMap);
return customSqlSessionTemplate;
}
/***
* 自定义会话工厂
* @param dataSource 数据源
* @return :自定义的会话工厂
*/
private SqlSessionFactory createSqlSessionFactory(DataSource dataSource) throws Exception {
SqlSessionFactoryBean factoryBean = new SqlSessionFactoryBean();
factoryBean.setDataSource(dataSource);
factoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources(MAPPER_LOCATION));
// 其他可配置项(包括是否打印sql,是否开启驼峰命名等)
org.apache.ibatis.session.Configuration configuration = new org.apache.ibatis.session.Configuration();
configuration.setMapUnderscoreToCamelCase(true);
configuration.setLogImpl(StdOutImpl.class);
factoryBean.setConfiguration(configuration);
/* *
* 采用个如下方式配置属性的时候一定要保证已经进行数据源的配置(setDataSource)和数据源和MapperLocation配置(setMapperLocations)
* factoryBean.getObject().getConfiguration().setMapUnderscoreToCamelCase(true);
* factoryBean.getObject().getConfiguration().setLogImpl(StdOutImpl.class);
**/
return factoryBean.getObject();
}
}
3. 自定义sqlSessionTemplate的主要实现逻辑
这里主要覆盖重写了sqlSessionTemplate的getSqlSessionFactory,从ThreadLocal去获取实际使用的数据源(AOP切面将实际使用的数据源存入ThreadLocal)。
/***
* 获取当前使用数据源对应的会话工厂
*/
@Override
public SqlSessionFactory getSqlSessionFactory() {
String dataSourceKey = DataSourceContextHolder.getDataSourceKey();
log.info("当前会话工厂 : {}", dataSourceKey);
SqlSessionFactory targetSqlSessionFactory = targetSqlSessionFactories.get(dataSourceKey);
if (targetSqlSessionFactory != null) {
return targetSqlSessionFactory;
} else if (defaultTargetSqlSessionFactory != null) {
return defaultTargetSqlSessionFactory;
} else {
Assert.notNull(targetSqlSessionFactories, "Property 'targetSqlSessionFactories' or 'defaultTargetSqlSessionFactory' are required");
Assert.notNull(defaultTargetSqlSessionFactory, "Property 'defaultTargetSqlSessionFactory' or 'targetSqlSessionFactories' are required");
}
return this.sqlSessionFactory;
}
/**
* 这个方法的实现和父类的实现是基本一致的,唯一不同的就是在getSqlSession方法传参中获取会话工厂的方式
*/
private class SqlSessionInterceptor implements InvocationHandler {
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//在getSqlSession传参时候,用我们重写的getSqlSessionFactory获取当前数据源对应的会话工厂
final SqlSession sqlSession = getSqlSession(
CustomSqlSessionTemplate.this.getSqlSessionFactory(),
CustomSqlSessionTemplate.this.executorType,
CustomSqlSessionTemplate.this.exceptionTranslator);
try {
Object result = method.invoke(sqlSession, args);
if (!isSqlSessionTransactional(sqlSession, CustomSqlSessionTemplate.this.getSqlSessionFactory())) {
sqlSession.commit(true);
}
return result;
} catch (Throwable t) {
Throwable unwrapped = unwrapThrowable(t);
if (CustomSqlSessionTemplate.this.exceptionTranslator != null && unwrapped instanceof PersistenceException) {
Throwable translated = CustomSqlSessionTemplate.this.exceptionTranslator
.translateExceptionIfPossible((PersistenceException) unwrapped);
if (translated != null) {
unwrapped = translated;
}
}
throw unwrapped;
} finally {
closeSqlSession(sqlSession, CustomSqlSessionTemplate.this.getSqlSessionFactory());
}
}
}
4. 使用AOP动态切换数据源,将当前使用的数据源名称保存到线程隔离的ThreadLocal中
这里我们直接对dao层接口进行切面,如果第一个参数指明需要使用哪一个数据源,就使用对应的数据源,如果没有指定,就使用默认的数据源。
注:使用切面来切换数据源是一种实现思路,而具体如何定义切入点可以按照自己的实际情况来定,你可以使用第一个参数指明数据源,也可以自定义注解来指定数据源,这个按照自己的实际使用方便来实现即可。
@Aspect
@Component
public class DynamicDataSourceAspect {
@Pointcut(value = "execution(* com.heibaiying.springboot.dao.*.*(..))")
public void dataSourcePointCut() {
}
@Before(value = "dataSourcePointCut()")
public void beforeSwitchDS(JoinPoint point) {
Object[] args = point.getArgs();
if (args == null || args.length < 1 || !Data.DATASOURCE2.equals(args[0])) {
DataSourceContextHolder.setDataSourceKey(Data.DATASOURCE1);
} else {
DataSourceContextHolder.setDataSourceKey(Data.DATASOURCE2);
}
}
@After(value = "dataSourcePointCut()")
public void afterSwitchDS(JoinPoint point) {
DataSourceContextHolder.clearDataSourceKey();
}
}
DataSourceContextHolder 的实现:
public class DataSourceContextHolder {
private static final ThreadLocal<String> contextHolder = new ThreadLocal<>();
// 设置数据源名
public static void setDataSourceKey(String dbName) {
contextHolder.set(dbName);
}
// 获取数据源名
public static String getDataSourceKey() {
return (contextHolder.get());
}
// 清除数据源名
public static void clearDataSourceKey() {
contextHolder.remove();
}
}
5. JTA 事务管理器配置
/**
* @author : heibaiying
* @description : JTA事务配置
*/
@Configuration
@EnableTransactionManagement
public class XATransactionManagerConfig {
@Bean
public UserTransaction userTransaction() throws Throwable {
UserTransactionImp userTransactionImp = new UserTransactionImp();
userTransactionImp.setTransactionTimeout(10000);
return userTransactionImp;
}
@Bean(initMethod = "init", destroyMethod = "close")
public TransactionManager atomikosTransactionManager() {
UserTransactionManager userTransactionManager = new UserTransactionManager();
userTransactionManager.setForceShutdown(false);
return userTransactionManager;
}
@Bean
public PlatformTransactionManager transactionManager(UserTransaction userTransaction,
TransactionManager transactionManager) {
return new JtaTransactionManager(userTransaction, transactionManager);
}
}
三、整合结果测试
这里我一共给了三种情况的测试接口,如下:

3.1 测试数据库整合结果
这里我在mysql和mysql02的表中分别插入了一条数据:
mysql数据库:

mysql02 数据库:

前端查询结果:

3.2 测试单数据库事务
这里因为没有复杂的业务逻辑,我直接将@Transactional加载controller层,实际中最好加到service层
/**
* @author : heibaiying
* @description : 测试单数据库事务
*/
@RestController
public class TransactionController {
@Autowired
private ProgrammerMapper programmerDao;
@RequestMapping("db1/change")
@Transactional
public void changeDb1() {
Programmer programmer = new Programmer(1, "db1", 99, 6662.32f, new Date());
programmerDao.modify(Data.DATASOURCE1, programmer);
}
@RequestMapping("ts/db1/change")
@Transactional
public void changeTsDb1() {
Programmer programmer = new Programmer(1, "db1", 88, 6662.32f, new Date());
programmerDao.modify(Data.DATASOURCE1, programmer);
// 抛出异常 查看回滚
int j = 1 / 0;
}
}
3.3 测试分布式事务
/**
* @author : heibaiying
* @description : 测试分布式事务
*/
@RestController
public class XATransactionController {
@Autowired
private ProgrammerMapper programmerDao;
@RequestMapping("/db/change")
@Transactional
public void changeDb() {
Programmer programmer01 = new Programmer(1, "db1", 100, 6662.32f, new Date());
Programmer programmer02 = new Programmer(1, "db2", 100, 6662.32f, new Date());
programmerDao.modify(Data.DATASOURCE1, programmer01);
programmerDao.modify(Data.DATASOURCE2, programmer02);
}
@RequestMapping("ts/db/change")
@Transactional
public void changeTsDb() {
Programmer programmer01 = new Programmer(1, "db1", 99, 6662.32f, new Date());
Programmer programmer02 = new Programmer(1, "db2", 99, 6662.32f, new Date());
programmerDao.modify(Data.DATASOURCE1, programmer01);
programmerDao.modify(Data.DATASOURCE2, programmer02);
int i = 1 / 0;
}
}
3.4 测试druid数据源是否整合成功
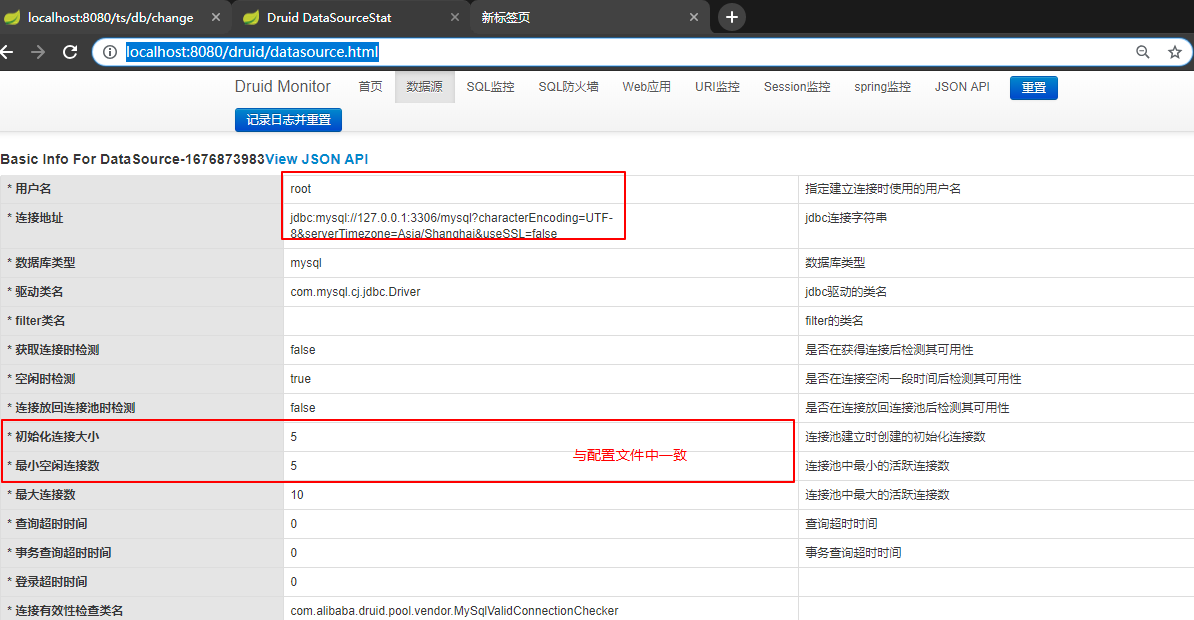
访问 http://localhost:8080/druid/index.html ,可以在数据源监控页面看到两个数据源已配置成功,同时配置都与我们在yml配置文件中的一致。
数据源1:
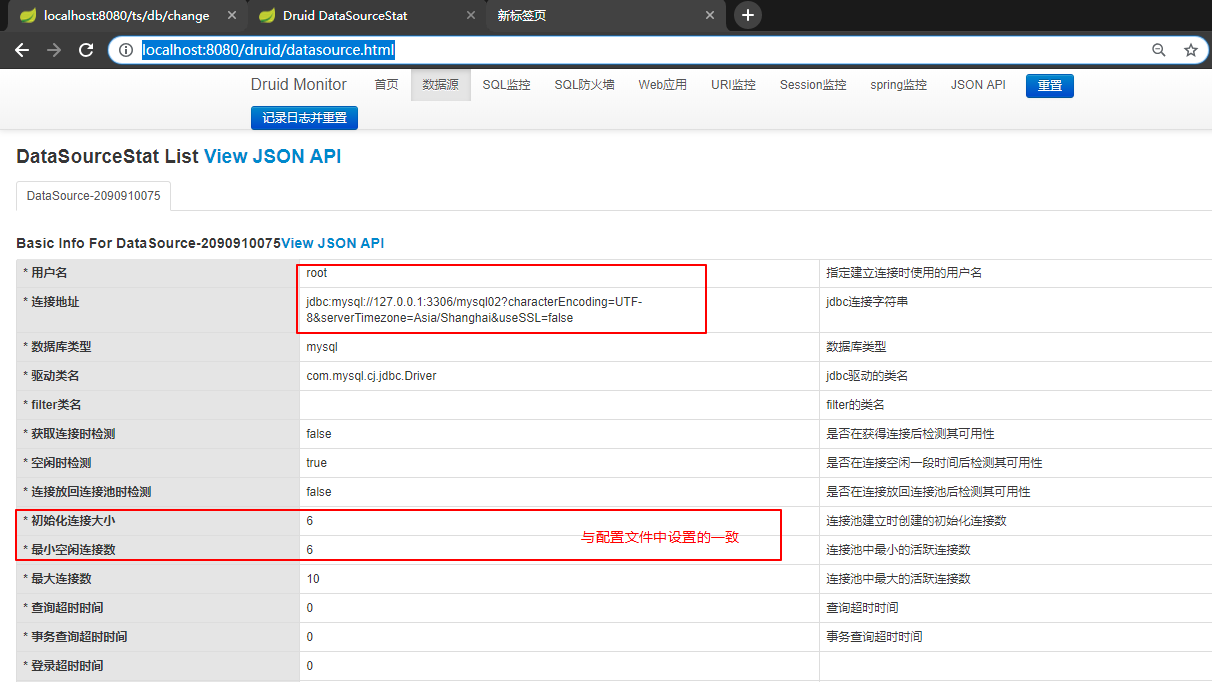
数据源2:
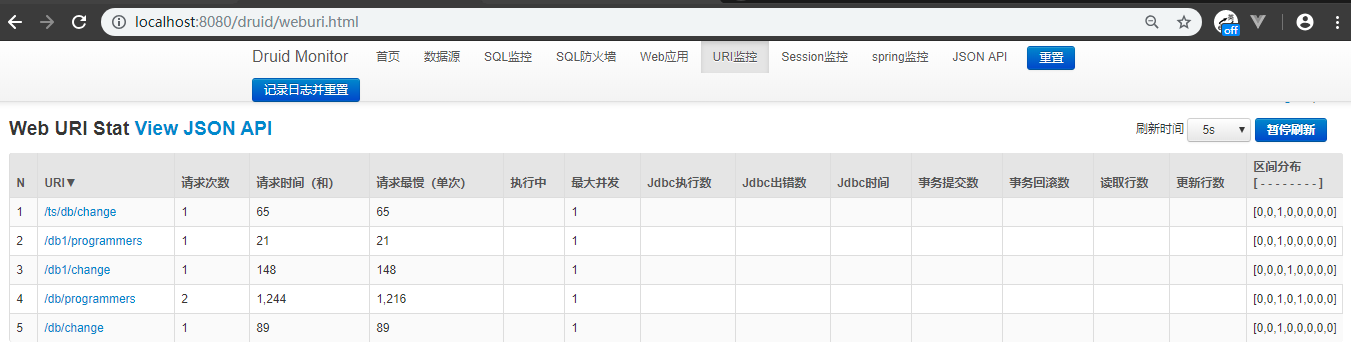
url 监控情况:
四、JTA与两阶段提交
解释一下本用例中涉及到的相关概念。
4.1 XA 与 JTA
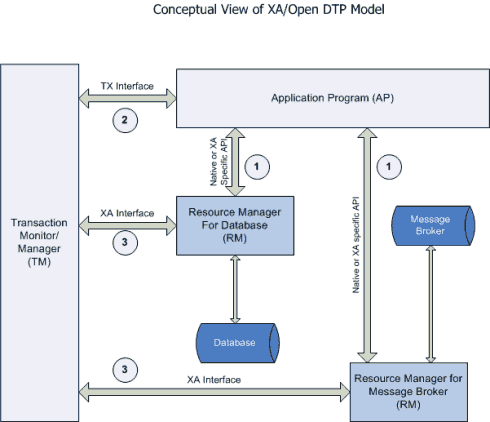
XA是由X/Open组织提出的分布式事务的规范。XA规范主要定义了(全局)事务管理器(Transaction Manager)和(局部)资源管理器(Resource Manager)之间的接口。XA接口是双向的系统接口,在事务管理器(Transaction Manager)以及一个或多个资源管理器(Resource Manager)之间形成通信桥梁。XA之所以需要引入事务管理器是因为,在分布式系统中,从理论上讲,两台机器理论上无 法达到一致的状态,需要引入一个单点进行协调。
事务管理器控制着全局事务,管理事务生命周期,并协调资源。资源管理器负责控制和管理实际资源(如数据库或 JMS队列)。
下图说明了事务管理器、资源管理器,与应用程序之间的关系。
而 JTA 就是 XA 规范在java语言上的实现。JTA 采用两阶段提交实现分布式事务。
4.2 两阶段提交
分布式事务必须满足传统事务的特性,即原子性,一致性,分离性和持久性。但是分布式事务处理过程中,某些节点(Server)可能发生故障,或 者由于网络发生故障而无法访问到某些节点。为了防止分布式系统部分失败时产生数据的不一致性。在分布式事务的控制中采用了两阶段提交协议(Two- Phase Commit Protocol)。即事务的提交分为两个阶段:
- 预提交阶段(Pre-Commit Phase)
- 决策后阶段(Post-Decision Phase)
两阶段提交用来协调参与一个更新中的多个服务器的活动,以防止分布式系统部分失败时产生数据的不一致性。例如,如果一个更新操作要求位于三个不同结点上的记录被改变,且其中只要有一个结点失败,另外两个结点必须检测到这个失败并取消它们所做的改变。为了支持两阶段提交,一个分布式更新事务中涉及到的服务器必须能够相互通信。一般来说一个服务器会被指定为"控制"或"提交"服务器并监控来自其它服务器的信息。
在分布式更新期间,各服务器首先标志它们已经完成(但未提交)指定给它们的分布式事务的那一部分,并准备提交(以使它们的更新部分成为永久性的)。这是 两阶段提交的第一阶段。如果有一结点不能响应,那么控制服务器要指示其它结点撤消分布式事务的各个部分的影响。如果所有结点都回答准备好提交,控制服务器 则指示它们提交并等待它们的响应。等待确认信息阶段是第二阶段。在接收到可以提交指示后,每个服务器提交分布式事务中属于自己的那一部分,并给控制服务器 发回提交完成信息。
在一个分布式事务中,必须有一个场地的Server作为协调者(coordinator),它能向 其它场地的Server发出请求,并对它们的回答作出响应,由它来控制一个分布式事务的提交或撤消。该分布式事务中涉及到的其它场地的Server称为参与者(Participant)。
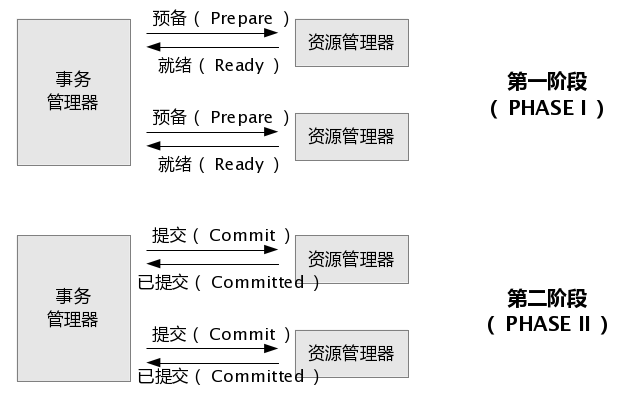
事务两阶段提交的过程如下:
第一阶段:
两阶段提交在应用程序向协调者发出一个提交命令时被启动。这时提交进入第一阶段,即预提交阶段。在这一阶段中:
(1) 协调者准备局部(即在本地)提交并在日志中写入"预提交"日志项,并包含有该事务的所有参与者的名字。
(2) 协调者询问参与者能否提交该事务。一个参与者可能由于多种原因不能提交。例如,该Server提供的约束条(Constraints)的延迟检查不符合 限制条件时,不能提交;参与者本身的Server进程或硬件发生故障,不能提交;或者协调者访问不到某参与者(网络故障),这时协调者都认为是收到了一个 否定的回答。
(3) 如果参与者能够提交,则在其本身的日志中写入"准备提交"日志项,该日志项立即写入硬盘,然后给协调者发回,已准备好提交"的回答。
(4) 协调者等待所有参与者的回答,如果有参与者发回否定的回答,则协调者撤消该事务并给所有参与者发出一个"撤消该事务"的消息,结束该分布式事务,撤消该事务的所有影响。
第二阶段:
如果所有的参与者都送回"已准备好提交"的消息,则该事务的提交进入第二阶段,即决策后提交阶段。在这一阶段中:
(1) 协调者在日志中写入"提交"日志项,并立即写入硬盘。
(2) 协调者向参与者发出"提交该事务"的命令。各参与者接到该命令后,在各自的日志中写入"提交"日志项,并立即写入硬盘。然后送回"已提交"的消息,释放该事务占用的资源。
(3) 当所有的参与者都送回"已提交"的消息后,协调者在日志中写入"事务提交完成"日志项,释放协调者占用的资源 。这样,完成了该分布式事务的提交。
本小结的表述引用自博客浅谈分布式事务
五、常见整合异常
5.1 事务下多数据源无法切换
这里是主要是对上文提到为什么不重写sqlSessionTemplate会导致在事务下数据源切换失败的补充,我们先看看sqlSessionTemplate源码中关于该类的定义:
sqlSessionTemplate与Spring事务管理一起使用,以确保使用的实际SqlSession是与当前Spring事务关联的,此外它还管理会话生命周期,包括根据Spring事务配置根据需要关闭,提交或回滚会话
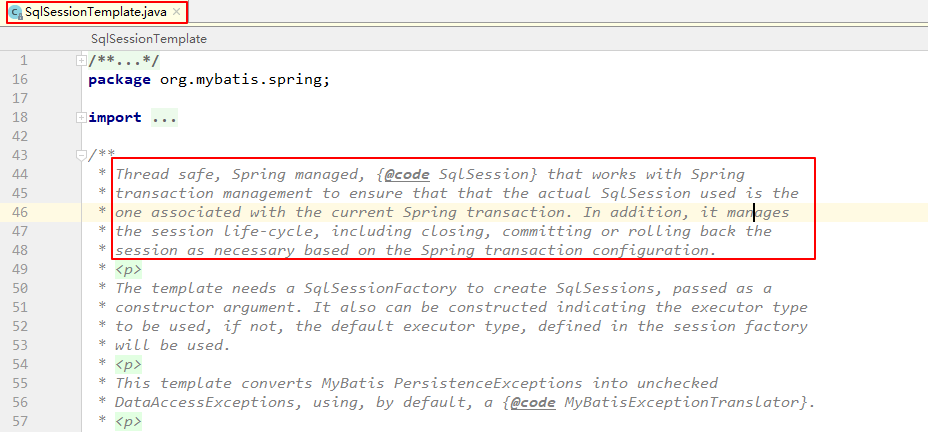
这里最主要的是说明sqlSession是与当前是spring 事务是关联的。
1. sqlSession与事务关联导致问题
对于mybatis 来说,是默认开启一级缓存的,一级缓存是session级别的,对于同一个session如果是相同的查询语句并且查询参数都相同,第二次的查询就直接从一级缓存中获取。
这也就是说,对于如下的情况,由于sqlSession是与事务绑定的,如果使用原生sqlSessionTemplate,则第一次查询和第二次查询都是用的同一个sqlSession,那么第二个查询数据库2的查询语句根本不会执行,会直接从一级缓存中获取查询结果。两次查询得到都是第一次查询的结果。
@GetMapping("ts/db/programmers")
@Transactional
public List<Programmer> getAllProgrammers() {
List<Programmer> programmers = programmerDao.selectAll(Data.DATASOURCE1);
programmers.addAll(programmerDao.selectAll(Data.DATASOURCE2));
return programmers;
}
2. 连接的复用导致无法切换数据源
先说一下为什么会出现连接的复用:
我们可以在spring的源码中看到spring在通过DataSourceUtils类中去获取新的连接doGetConnection的时候,会通过TransactionSynchronizationManager.getResource(dataSource)方法去判断当前数据源是否有可用的连接,如果有就直接返回,如果没有就通过fetchConnection方法去获取。
public static Connection doGetConnection(DataSource dataSource) throws SQLException {
Assert.notNull(dataSource, "No DataSource specified");
// 判断是否有可用的连接
ConnectionHolder conHolder = (ConnectionHolder) TransactionSynchronizationManager.getResource(dataSource);
if (conHolder != null && (conHolder.hasConnection() || conHolder.isSynchronizedWithTransaction())) {
conHolder.requested();
if (!conHolder.hasConnection()) {
logger.debug("Fetching resumed JDBC Connection from DataSource");
conHolder.setConnection(fetchConnection(dataSource));
}
//如果有可用的连接就直接方法
return conHolder.getConnection();
}
// Else we either got no holder or an empty thread-bound holder here.
logger.debug("Fetching JDBC Connection from DataSource");
// 如果没有可用的连接就直接返回
Connection con = fetchConnection(dataSource);
if (TransactionSynchronizationManager.isSynchronizationActive()) {
try {
// Use same Connection for further JDBC actions within the transaction.
// Thread-bound object will get removed by synchronization at transaction completion.
ConnectionHolder holderToUse = conHolder;
if (holderToUse == null) {
holderToUse = new ConnectionHolder(con);
}
else {
holderToUse.setConnection(con);
}
holderToUse.requested();
TransactionSynchronizationManager.registerSynchronization(
new ConnectionSynchronization(holderToUse, dataSource));
holderToUse.setSynchronizedWithTransaction(true);
if (holderToUse != conHolder) {
TransactionSynchronizationManager.bindResource(dataSource, holderToUse);
}
}
catch (RuntimeException ex) {
// Unexpected exception from external delegation call -> close Connection and rethrow.
releaseConnection(con, dataSource);
throw ex;
}
}
return con;
}
这里主要的问题是TransactionSynchronizationManager.getResource(dataSource)中dataSource参数是在哪里进行注入的,这里可以沿着调用堆栈往上寻找,可以看到是在这个参数是SpringManagedTransaction类中获取连接的时候传入的。
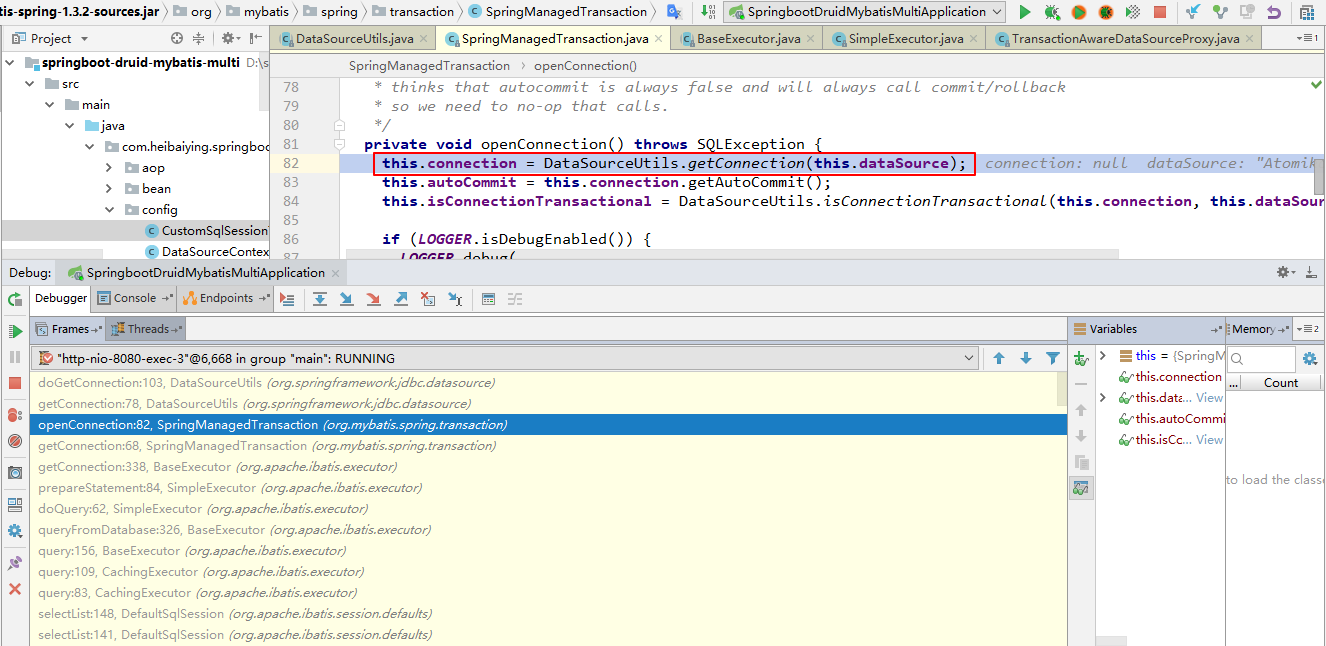
而SpringManagedTransaction这类中的dataSource是如何得到赋值的,这里可以进入这个类中查看,只有在创建这个类的时候通过构造器为dataSource赋值,那么是哪个方法创建了SpringManagedTransaction?
在构造器上打一个断点,沿着调用的堆栈往上寻找可以看到是DefaultSqlSessionFactory在创建SpringManagedTransaction中传入的,这个数据源就是创建sqlSession的sqlSessionFactory中数据源。
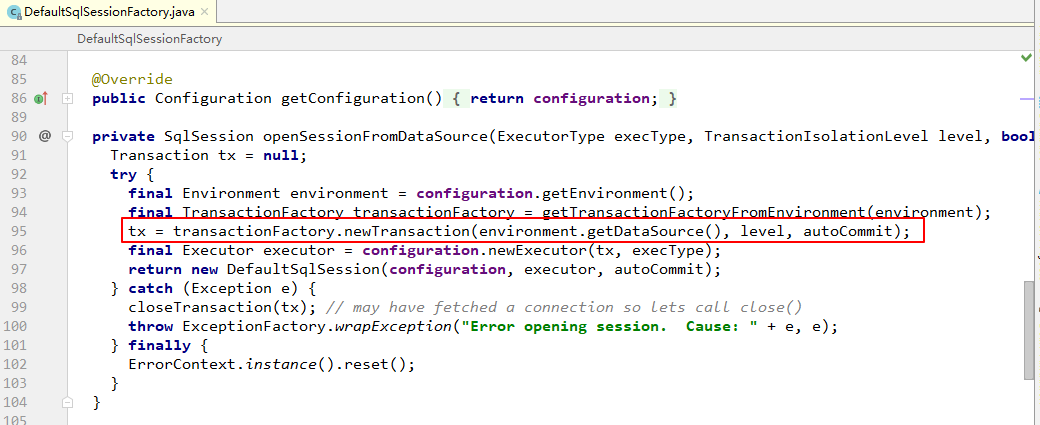
这里说明连接的复用是与我们创建sqlSession时候传入的sqlSessionFactory是否是同一个有关。

所以我们才重写了sqlSessionTemplate中的getSqlSession方法,获取sqlSession时候传入正在使用的数据源对应的sqlSessionFactory,这样即便在同一个的事务中,由于传入的sqlSessionFactory中不同,就不会出现连接复用。

关于mybati-spring 的更多事务处理机制,推荐阅读博客mybatis-spring事务处理机制分析
5.2 出现org.apache.ibatis.binding.BindingExceptionInvalid bound statement (not found)异常
出现这个异常的的原因是在创建SqlSessionFactory的时候,在setMapperLocations配置好之前调用了factoryBean.getObject()方法
//一个错误的示范
private SqlSessionFactory createSqlSessionFactory(DataSource dataSource) throws Exception {
SqlSessionFactoryBean factoryBean = new SqlSessionFactoryBean();
factoryBean.setDataSource(dataSource);
// factoryBean.getObject()
factoryBean.getObject().getConfiguration().setMapUnderscoreToCamelCase(true);
factoryBean.getObject().getConfiguration().setLogImpl(StdOutImpl.class);
factoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources(MAPPER_LOCATION));
return factoryBean.getObject();
}
上面这段代码没有任何编译问题,导致这个错误不容易发现,但是在调用sql时候就会出现异常。原因是factoryBean.getObject()方法被调用时就已经创建了SqlSessionFactory,并且SqlSessionFactory只会被创建一次。此时还没有指定sql 文件的位置,导致mybatis无法将接口与xml中的sql语句进行绑定,所以出现BindingExceptionInvalid 绑定异常。
@Override
public SqlSessionFactory getObject() throws Exception {
if (this.sqlSessionFactory == null) {
afterPropertiesSet();
}
return this.sqlSessionFactory;
}
正常绑定的情况下,我们是可以在sqlSessionFactory中查看到绑定好的查询接口:

参考资料
spring boot + druid + mybatis + atomikos 多数据源配置 并支持分布式事务的更多相关文章
- Spring Boot 2.x Redis多数据源配置(jedis,lettuce)
Spring Boot 2.x Redis多数据源配置(jedis,lettuce) 96 不敢预言的预言家 0.1 2018.11.13 14:22* 字数 65 阅读 727评论 0喜欢 2 多数 ...
- Spring Boot 集成Mybatis实现多数据源
静态的方式 我们以两套配置方式为例,在项目中有两套配置文件,两套mapper,两套SqlSessionFactory,各自处理各自的业务,这个两套mapper都可以进行增删改查的操作,在这两个主MYS ...
- Spring Boot 2.4 对多环境配置的支持更改
在目前最新的Spring Boot 2.4版本中,对配置的加载机制做了较大的调整.相关的问题最近也被问的比较多,所以今天就花点时间,给大家讲讲Spring Boot 2.4的多环境配置较之前版本有哪些 ...
- spring boot 中 Mybatis plus 多数据源的配置方法
最近在学习spring boot,发现在jar包依赖方面做很少的工作量就可以了,对于数据库操作,我用的比较多的是mybatis plus,在中央仓库已经有mybatis-plus的插件了,对于单数据源 ...
- spring boot druid mybatis多数据源
一.关闭数据源自动配置(很关键) @SpringBootApplication(exclude = { DataSourceAutoConfiguration.class }) 如果不关闭会报异常:o ...
- Spring Boot 集成 Mybatis 实现双数据源
这里用到了Spring Boot + Mybatis + DynamicDataSource配置动态双数据源,可以动态切换数据源实现数据库的读写分离. 添加依赖 加入Mybatis启动器,这里添加了D ...
- Spring Boot数据访问之多数据源配置及数据源动态切换
如果一个数据库数据量过大,考虑到分库分表和读写分离需要动态的切换到相应的数据库进行相关操作,这样就会有多个数据源.对于一个数据源的配置在Spring Boot数据访问之数据源自动配置 - 池塘里洗澡的 ...
- Spring Boot 整合mybatis 使用多数据源
本人想要实现一个项目里面多个数据库源连接,所以就尝试写一个demo,不多说,先贴结构,再贴代码,可以根据以下的顺序,直接copy解决问题. 首先,dao和resource下的mappers可以用myb ...
- spring boot 添加mybatis,以及相关配置
首先在pom.xml文件里加入 <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifa ...
随机推荐
- 理解 UWP 视图的概念,让 UWP 应用显示多个窗口(多视图)
原文 理解 UWP 视图的概念,让 UWP 应用显示多个窗口(多视图) UWP 应用多是一个窗口完成所有业务的,事实上我也推荐使用这种单一窗口的方式.不过,总有一些特别的情况下我们需要用到不止一个窗口 ...
- 简明Python3教程 首页
A Byte of Python 'A Byte of Python' is a free book on programming using the Python language. It serv ...
- WPF3D图片轮播效果
原文:WPF3D图片轮播效果 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/m0_37591671/article/details/68059169 ...
- Android Intent传递对象摘要
效果: watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvaG9uZ3NoZW5ncGVuZw==/font/5a6L5L2T/fontsize/400/fil ...
- ASP.NET Core SameSite 设置引起 Cookie 在 QQ 浏览器中不起作用
最近在发布了基于 ASP.NET Core 实现的新版登录页面之后,陆陆续续地接到用户反馈登录时 Antiforgery Token 总是验证失败. 日志中记录的对应错误是 Antiforgery t ...
- JS window下面的对象
) •Js脚本一执行就会访问服务器.超链接诶还需要点击. getElementById(), (非常常用),根据元素的Id获得对象,网页中id不能重复.也可以直接通过元素的id来引用元素,但是有有效范 ...
- Java Policy
# What The policy for a Java™ programming language application environment (specifying which permiss ...
- C# Winform制作虚拟键盘,支持中文
原文:C# Winform制作虚拟键盘,支持中文 最近在做一个虚拟键盘功能,代替鼠标键盘操作,效果如下: 实现思路: 1 构建中文-拼音 数据库, ...
- java.text.MessageFormat 专题
java.text.MessageFormat类MessageFormat提供一种语言无关的方式来组装消息,它允许你在运行时刻用指定的参数来替换掉消息字符串中的一部分.你可以为MessageForma ...
- Expression Blend学习四控件
原文:Expression Blend学习四控件 Expression Blend制作自定义按钮 1.从Blend工具箱中添加一个Button,按住shift,将尺寸调整为125*125; 2.右键点 ...