全卷积网络FCN详解
http://www.cnblogs.com/gujianhan/p/6030639.html
CNN能够对图片进行分类,可是怎么样才能识别图片中特定部分的物体? (图像语义分割)
FCN(Fully Convolutional Networks)对图像进行像素级的分类,从而解决了语义级别的图像分割(semantic segmentation)问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。最后逐个像素计算softmax分类的损失, 相当于每一个像素对应一个训练样本。
简单的来说,FCN与CNN的区域在把于CNN最后的全连接层换成卷积层,输出的是一张已经Label好的图片。
下图是Longjon用于语义分割所采用的全卷积网络(FCN)的结构示意图:

全连接层和卷积层之间唯一的不同就是卷积层中的神经元只与输入数据中的一个局部区域连接,并且在卷积列中的神经元共享参数。然而在两类层中,神经元都是计算点积,所以它们的函数形式是一样的。因此,将此两者相互转化是可能的:
对于任一个卷积层,都存在一个能实现和它一样的前向传播函数的全连接层。权重矩阵是一个巨大的矩阵,除了某些特定块,其余部分都是零。而在其中大部分块中,元素都是相等的。
相反,任何全连接层都可以被转化为卷积层。比如,一个 K=4096 的全连接层,输入数据体的尺寸是 7∗7∗512,这个全连接层可以被等效地看做一个 F=7,P=0,S=1,K=4096 的卷积层。换句话说,就是将滤波器的尺寸设置为和输入数据体的尺寸一致了。因为只有一个单独的深度列覆盖并滑过输入数据体,所以输出将变成 1∗1∗4096,这个结果就和使用初始的那个全连接层一样了。
全连接层转化为卷积层:在两种变换中,将全连接层转化为卷积层在实际运用中更加有用。假设一个卷积神经网络的输入是 224x224x3 的图像,一系列的卷积层和下采样层将图像数据变为尺寸为 7x7x512 的激活数据体。AlexNet使用了两个尺寸为4096的全连接层,最后一个有1000个神经元的全连接层用于计算分类评分。我们可以将这3个全连接层中的任意一个转化为卷积层:
- 针对第一个连接区域是[7x7x512]的全连接层,令其滤波器尺寸为F=7,这样输出数据体就为[1x1x4096]了。
- 针对第二个全连接层,令其滤波器尺寸为F=1,这样输出数据体为[1x1x4096]。
- 对最后一个全连接层也做类似的,令其F=1,最终输出为[1x1x1000]
如下图所示,FCN将传统CNN中的全连接层转化成卷积层,对应CNN网络FCN把最后三层全连接层转换成为三层卷积层。在传统的CNN结构中,前5层是卷积层,第6层和第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,分别对应1000个不同类别的概率。FCN将这3层表示为卷积层,卷积核的大小 (通道数,宽,高) 分别为 (4096,1,1)、(4096,1,1)、(1000,1,1)。看上去数字上并没有什么差别,但是卷积跟全连接是不一样的概念和计算过程,使用的是之前CNN已经训练好的权值和偏置,但是不一样的在于权值和偏置是有自己的范围,属于自己的一个卷积核。因此FCN网络中所有的层都是卷积层,故称为全卷积网络。
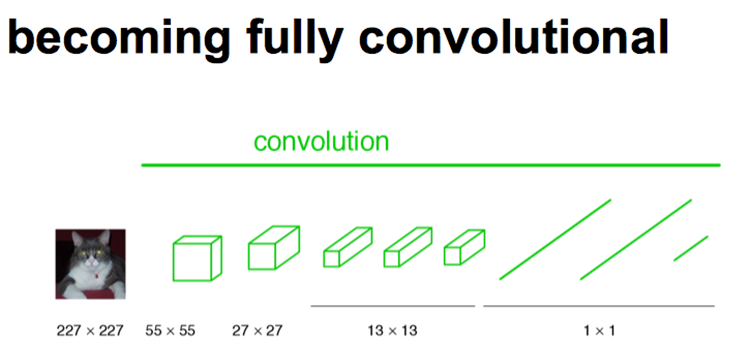
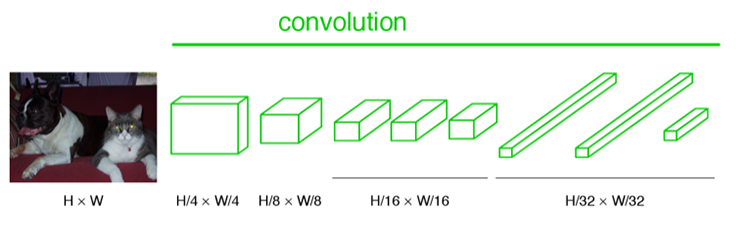
下图是一个全卷积层,与上图不一样的是图像对应的大小下标,CNN中输入的图像大小是同意固定resize成 227x227 大小的图像,第一层pooling后为55x55,第二层pooling后图像大小为27x27,第五层pooling后的图像大小为13*13。而FCN输入的图像是H*W大小,第一层pooling后变为原图大小的1/4,第二层变为原图大小的1/8,第五层变为原图大小的1/16,第八层变为原图大小的1/32(勘误:其实真正代码当中第一层是1/2,以此类推)。
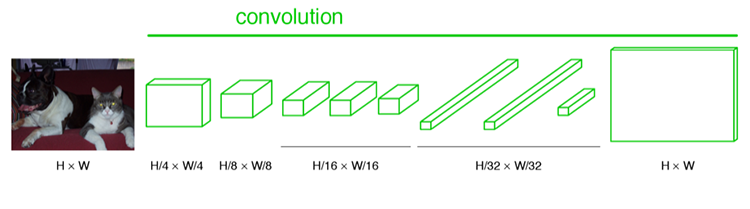
经过多次卷积和pooling以后,得到的图像越来越小,分辨率越来越低。其中图像到 H/32∗W/32 的时候图片是最小的一层时,所产生图叫做heatmap热图,热图就是我们最重要的高维特诊图,得到高维特征的heatmap之后就是最重要的一步也是最后的一步对原图像进行upsampling,把图像进行放大、放大、放大,到原图像的大小。
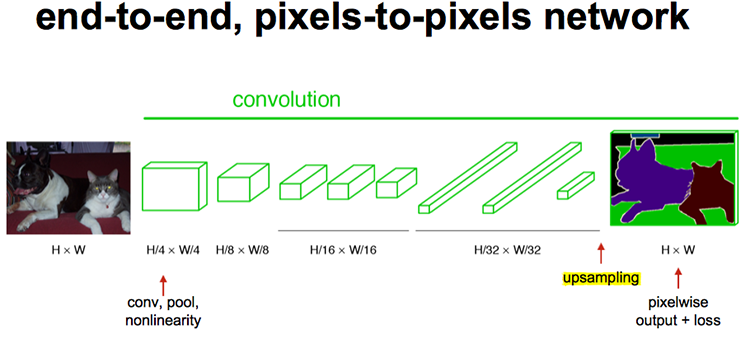
最后的输出是1000张heatmap经过upsampling变为原图大小的图片,为了对每个像素进行分类预测label成最后已经进行语义分割的图像,这里有一个小trick,就是最后通过逐个像素地求其在1000张图像该像素位置的最大数值描述(概率)作为该像素的分类。因此产生了一张已经分类好的图片,如下图右侧有狗狗和猫猫的图。
医疗图像分割框架
基于CNN的框架
对图像的每一个像素点进行分类,在每一个像素点上取一个patch,当做一幅图像,输入神经网络进行训练,参考论文:http://papers.nips.cc/paper/4741-deep-neural-networks-segment-neuronal-membranes-in-electron-microscopy-images
这种网络显然有两个缺点:
1. 冗余太大,由于每个像素点都需要取一个patch,那么相邻的两个像素点的patch相似度是非常高的,这就导致了非常多的冗余,导致网络训练很慢。
2. 感受野和定位精度不可兼得,当感受野选取比较大的时候,后面对应的pooling层的降维倍数就会增大,这样就会导致定位精度降低,但是如果感受野比较小,那么分类精度就会降低。
基于FCN框架
医学图像处理领域,有一个应用很广泛的网络结构—-U-net ,网络结构如下:
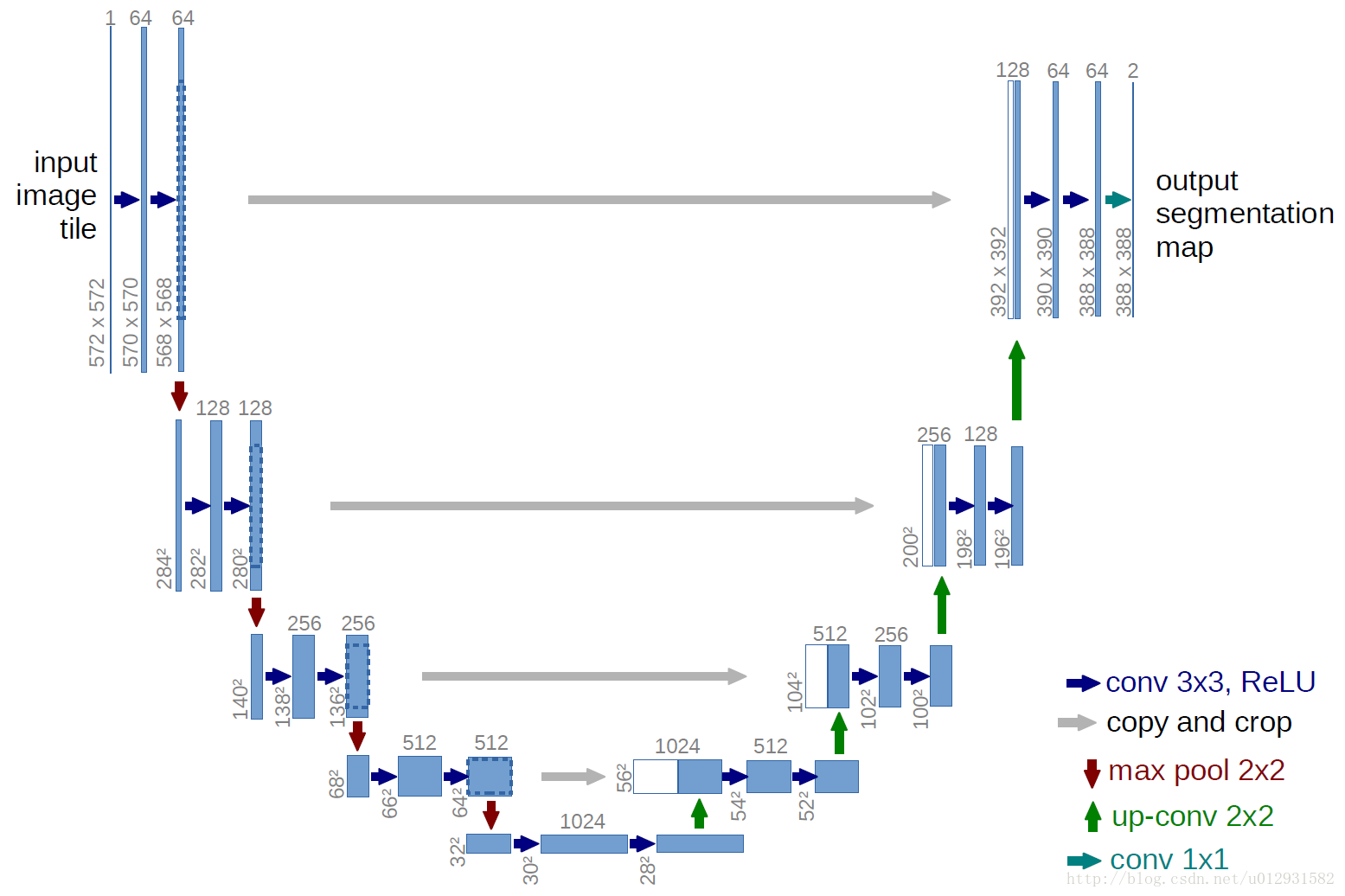
可以看出来,就是一个全卷积神经网络,输入和输出都是图像,没有全连接层。较浅的高分辨率层用来解决像素定位的问题,较深的层用来解决像素分类的问题。
全卷积网络FCN详解的更多相关文章
- 语义分割--全卷积网络FCN详解
语义分割--全卷积网络FCN详解 1.FCN概述 CNN做图像分类甚至做目标检测的效果已经被证明并广泛应用,图像语义分割本质上也可以认为是稠密的目标识别(需要预测每个像素点的类别). 传统的基于C ...
- 全卷积网络 FCN 详解
背景 CNN能够对图片进行分类,可是怎么样才能识别图片中特定部分的物体,在2015年之前还是一个世界难题.神经网络大神Jonathan Long发表了<Fully Convolutional N ...
- 全卷积神经网络FCN详解(附带Tensorflow详解代码实现)
一.导论 在图像语义分割领域,困扰了计算机科学家很多年的一个问题则是我们如何才能将我们感兴趣的对象和不感兴趣的对象分别分割开来呢?比如我们有一只小猫的图片,怎样才能够通过计算机自己对图像进行识别达到将 ...
- 全卷积网络FCN
全卷积网络FCN fcn是深度学习用于图像分割的鼻祖.后续的很多网络结构都是在此基础上演进而来. 图像分割即像素级别的分类. 语义分割的基本框架: 前端fcn(以及在此基础上的segnet,decon ...
- 全卷积网络(FCN)与图像分割
最近在做物体检测,也用到了全卷积网络,来此学习一波. 这篇文章写了很好,有利于入门,在此记录一下: http://blog.csdn.net/taigw/article/details/5140144 ...
- 全卷积网络(FCN)实战:使用FCN实现语义分割
摘要:FCN对图像进行像素级的分类,从而解决了语义级别的图像分割问题. 本文分享自华为云社区<全卷积网络(FCN)实战:使用FCN实现语义分割>,作者: AI浩. FCN对图像进行像素级的 ...
- FCN详解
转载自:https://www.cnblogs.com/gujianhan/p/6030639.html 论文地址:https://arxiv.org/pdf/1411.4038v1.pdf 背景 C ...
- 全卷积网络Fully Convolutional Networks (FCN)实战
全卷积网络Fully Convolutional Networks (FCN)实战 使用图像中的每个像素进行类别预测的语义分割.全卷积网络(FCN)使用卷积神经网络将图像像素转换为像素类别.与之前介绍 ...
- 深度学习之卷积神经网络(CNN)详解与代码实现(一)
卷积神经网络(CNN)详解与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10430073.html 目 ...
随机推荐
- (转)iOS 属性字符串
富文本的基本数据类型是NSAttributedString.**属性化字符串**(attributed string)是把属性设置到某些字符上的字符串.属性可以是任何键值对,但是为了实现富文本,则通常 ...
- 数据结构之--图(Graphics)
1.1:图的定义和术语 图是一种比线性表和树更为复杂的数据结构.在线性表中,数据元素之间仅有线性关系,每个元素仅有一个直接前驱和一个直接后继:在树形结构中,数据元素之间有着明显的层次关系,并且每一 ...
- H.264分层结构与码流结构
H.264分层结构 H.264编码器输出的Bit流中,每个Bit都隶属于某个句法元素.句法元素被组织成有层次的结构,分别描述各个层次的信息. 在H.264 中,句法元素共被组织成 序列.图像.片.宏 ...
- Java基础知识:集合框架
*本文是最近学习到的知识的记录以及分享,算不上原创. *参考文献见链接. 目录 集合框架 Collection接口 Map接口 集合的工具类 这篇文章只大致回顾一下Java的总体框架. 集合框架 ht ...
- java 获取音频文件时长
需要导入jar包:jave 1.0.2 jar 如果是maven项目,在pom.xml文件中添加: <dependency> <groupId>it.sauronsoftwar ...
- css字体文本格式 鼠标样式
缩进 text-indent 属性规定文本块中首行文本的缩进.(允许使用负值.如果使用负值,那么首行会被缩进到左边.) length 定义固定的缩进.默认值:0.% 定义基于父元素宽度的百分比的缩进. ...
- 00049_super关键字
1.子父类中构造方法的调用 (1)在创建子类对象时,父类的构造方法会先执行,因为子类中所有构造方法的第一行有默认的隐式super();语句: (2)格式 调用本类中的构造方法 this(实参列表); ...
- OSPF 提升 三 type of Areas
ospf ccnp 三 上图中 rip域中的不连续的100条路由 在a1中导致LSDB太大 在保证网段的可达性的前提下 尽可能减少区域内路由器的lsdb 可以将a1设置 ...
- Convolution Fundamental II
Practical Advice Using Open-Source Implementation We have learned a lot of NNs and ConvNets architec ...
- 【SVN】http和https的区别
导读:输入网址的时候,经常输入http://什么什么的,但http是什么,一直都不知道.然后,这回在SVN的学习中,又出现了http和https,而且还有说https的8443端口相对优越,我就在想, ...