数据采集框架Gobblin简介
问题导读:
Gobblin的架构设计是怎样的?
Gobblin拥有哪些组建,如何实现可扩展?
Gobblin采集执行流程的过程?
前面我们介绍Gobblin是用来整合各种数据源的通用型ETL框架,在某种意义上,各种数据都可以在这里“一站式”的解决ETL整个过程,专为大数据采集而生,易于操作和监控,提供流式抽取支持。
号称整合各种数据源“一站式”解决ETL整个过程的架构到底是怎样的呢?没图说个X。
Gobblin架构图
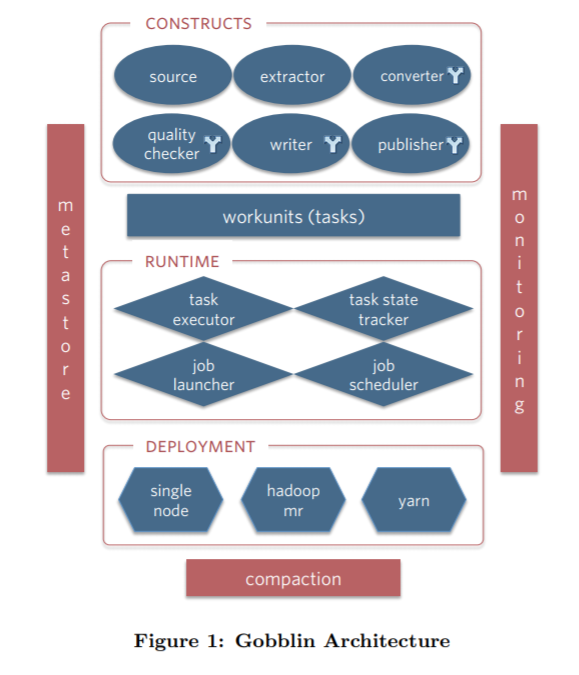
从Gobblin的架构图来看,Gobblin的功能真的是非常的全。底层支持三种部署方式,分别是standalone,mapreduce,mapreduce on yarn。可以方便快捷的与Hadoop进行集成,上层有运行时任务调度和状态管理层,可以与Oozie,Azkaban进行整合,同时也支持使用Quartz来调度(standalone模式默认使用Quartz进行调度)。对于失败的任务还拥有多种级别的重试机制,可以充分满足我们的需求。再上层呢就是由6大组件组成的执行单元了。这6大组件的设计也正是Gobblin高度可扩展的原因。
Gobblin组件
Gobblin提供了6个不同的组件接口,因此易于扩展并进行定制化开发。分别是:
- source
- extractor
- convertor
- quality checker
- writer
- publisher
Source主要负责将源数据整合到一系列workunits中,并指出对应的extractor是什么。这有点类似于Hadoop的InputFormat。
Extractor则通过workunit指定数据源的信息,例如kafka,指出topic中每个partition的起始offset,用于本次抽取使用。Gobblin使用了watermark的概念,记录每次抽取的数据的起始位置信息。
Converter顾名思义是转换器的意思,即对抽取的数据进行一些过滤、转换操作,例如将byte arrays 或者JSON格式的数据转换为需要输出的格式。转换操作也可以将一条数据映射成0条或多条数据(类似于flatmap操作)。
Quality Checker即质量检测器,有2中类型的checker:record-level和task-level的策略。通过手动策略或可选的策略,将被check的数据输出到外部文件或者给出warning。
Writer就是把导出的数据写出,但是这里并不是直接写出到output file,而是写到一个缓冲路径( staging directory)中。当所有的数据被写完后,才写到输出路径以便被publisher发布。Sink的路径可以包括HDFS或者kafka或者S3中,而格式可以是Avro,Parquet,或者CSV格式。同时Writer也可是根据时间戳,将输出的文件输出到按照“小时”或者“天”命名的目录中。
Publisher就是根据writer写出的路径,将数据输出到最终的路径。同时其提供2种提交机制:完全提交和部分提交;如果是完全提交,则需要等到task成功后才pub,如果是部分提交模式,则当task失败时,有部分在staging directory的数据已经被pub到输出路径了。
Gobblin执行流程
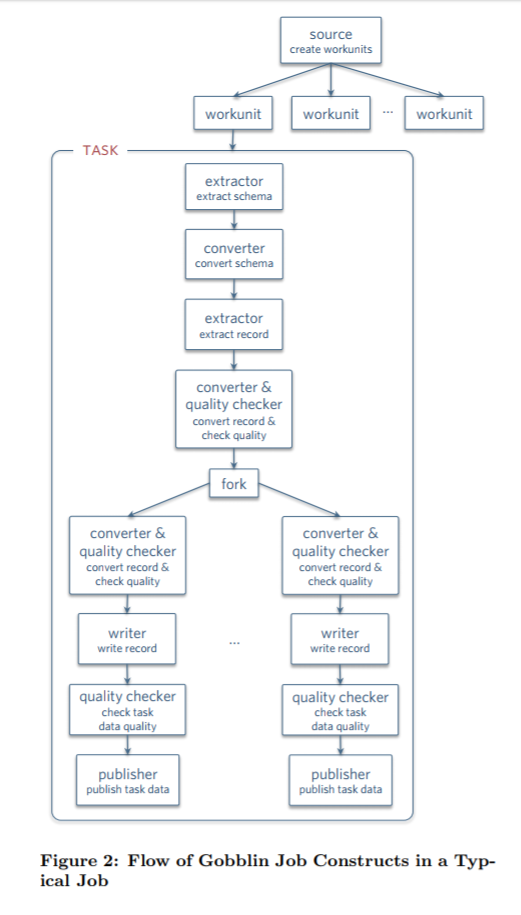
Job被创建后,Runtime就根据Job的部署方式进行执行。Runtime负责job/task的定时执行,状态管理,错误处理以及失败重试,监控和报告等工作。Gobblin存在分支的概念,从数据源获取的数据由不同的分支进行处理。每个分支都可以有自己的Converter,Quality Checker,Writer和Publisher。因此各个分支可以按不同的结构发布到不同的目标地址。单个分支任务失败不会影响其他分支。 同时每一次Job的执行都会将结果持久化到文件( SequenceFiles)中,以便下一次执行时可以读到上次执行的位置信息(例如offset),本次执行可以从上次offset开始执行本次Job。状态的存储会被定期清理,以免出现存储无限增长的情况。
Kafka to HDFS 示例
Gobblin的官方论文上给了一个Kafka数据抽取到HDFS的示例,通过Job运行在Yarn上,Gobblin可以达到运行一个long-running,流处理的模式。分为如下几步:
Source:每个partition中起始offset都通过Source生成到workunit中;同时,从state中获取上一次抽取结尾的offset信息,以便判断本次Job执行的起始offset。
Extractor:Extractor会逐个抽取partition的数据,抽取完成一个后,会将末尾offset信息存到状态存储中。
Converter:LinkedIn内部的Kafka集群主要存储Avro格式的数据,并对此进行一些过滤和转换。
Quality Checker:LinkedIn中数据都会包含一个时间戳,以便决定放到哪个“小时”目录和“天”目录。对于没有时间戳的数据,则会根据record-level的策略将这些数据写到外部文件中。
Writer and Publisher:内部使用基于时间的writer和基于时间的publisher去写并pub数据。
问:新增数据采集如何处理呢???
选(kai)择(fa)对应的六大组件,配置采集配置文件即可。so easy~~(下篇详解)
欢迎关注我:叁金大数据(不稳定持续更新~~~)

数据采集框架Gobblin简介的更多相关文章
- Hadoop的数据采集框架
问题导读: Hadoop数据采集框架都有哪些? Hadoop数据采集框架异同及适用场景? Hadoop提供了一个高度容错的分布式存储系统,帮助我们实现集中式的数据分析和数据共享.在日常应用中我们比如要 ...
- DWZ富客户端框架+DWZ简介及其使用+DWZ讨论组
DWZ富客户端框架+DWZ简介及其使用+DWZ讨论组 地址: DWZ富客户端框架:http://jui.org/#_blank DWZ简介及其使用:http://blog.sina.com.cn/s/ ...
- 从零开始写一个武侠冒险游戏-0-开发框架Codea简介
从零开始写一个武侠冒险游戏-0-开发框架Codea简介 作者:FreeBlues 修订记录 2016.06.21 初稿完成. 2016.08.03 增加对 XCode 项目文件的说明. 概述 本游戏全 ...
- Twitter的RPC框架Finagle简介
Twitter的RPC框架Finagle简介 http://www.infoq.com/cn/news/2014/05/twitter-finagle-intro
- android hook 框架 libinject2 简介、编译、运行
Android so注入-libinject2 简介.编译.运行 Android so注入-libinject2 如何实现so注入 Android so注入-Libinject 如何实现so注入 A ...
- 自制简单的.Net ORM框架 (一) 简介
在自己研究ORM之前,也使用过几个成熟的ORM方案,例如:EntityFramework,PetaPoco,Dapper 等,用是很好用,但是对自己来说总是不那么方便,EF比较笨重,Dapper要自定 ...
- 河北省重大技术需求征集系统原型(MVC框架业务流程简介)
这段时间了解了一些MVC框架. 一.MVC简介 MVC 是一种使用 MVC(Model View Controller 模型-视图-控制器)设计创建 Web 应用程序的模式.它的模式是JSP + se ...
- Xposed 框架 hook 简介 原理 案例 MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- 国内优秀MVC开源框架jfinal简介
JFinal简介 JFinal 项目开发始于2011年初,作者詹波(James Zhan)曾任搜格信息技术有限公司Java架构师,北京信息管理科学研究所CTO,现任微格网际(北京)科技有限公司联合创始 ...
随机推荐
- Jsp标签字典开发_基于Spring+Hibernate
目录 1. Jsp标签字典开发_基于Spring+Hibernate 1.1. 简述 1.2. 定义DictItem实体 1.3. 定义字典的@interface 1.4. 定义字典缓存类 1.5. ...
- 彻底来理解下hashmap吧
1.什么叫hashmap? 答:首先是一种map集合,其次呢,它是一种利用hash表来存储的数据结构.所以叫hashmap. 2.hashmap的特点是什么? 答:hashmap的特点是key值不能重 ...
- 数组/矩阵转换成Image类
Python下将数组/矩阵转换成Image类 原创 2017年04月21日 19:21:27 标签: python / 图像处理 3596 先说明一下为什么要将数组转换成Image类.我处理的图像是F ...
- [计算机联网故障]WIFI接入正常,但是上网不正常(两种情况)
今天同事拿来一个笔记本,说是连接WIFI都正常,但是就是无法上网.换了单位的wifi和他自己的手机共享wifi都是无法上网. 我首先检查了一下IP地址设置,看是否指定了IP.没有. 然后取消IPv6. ...
- BZOJ 1055 区间DP
1055: [HAOI2008]玩具取名 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 1144 Solved: 668[Submit][Statu ...
- 使用 FFmpeg 处理高质量 GIF 图片
使用 FFmpeg 处理高质量 GIF 图片 - 为程序员服务 http://ju.outofmemory.cn/entry/169845
- Linux/Android——input子系统核心 (三)【转】
本文转载自:http://blog.csdn.net/jscese/article/details/42123673 之前的博客有涉及到linux的input子系统,这里学习记录一下input模块. ...
- ‘CONFIG_ENV_SIZE’未声明(不在函数内【转】
本文转载自: http://bbs.csdn.net/topics/390678466 见论坛讨论.可以临时修复.
- data-toggle data-target
data-toggle https://stackoverflow.com/questions/30629974/how-does-the-data-toggle-attribute-work-wha ...
- 怎么查询数据库中第30到40条记录呢? 通过ID,查询当前第30-40条记录 注意,ID不是顺序的
http://blog.csdn.net/lee576/article/details/5812347 http://bbs.csdn.net/topics/190070614 http://www. ...