Hadoop分布式集群安装
环境准备
- 操作系统使用ubuntu-16.04.2 64位
- JDK使用jdk1.8
- Hadoop使用Hadoop 2.8版本
镜像下载
操作系统
操作系统使用ubuntu-16.04.2-desktop-amd64.iso
下载地址:https://www.ubuntu.com/download/desktop
用户名:dblab 密码:welcome1>
Jdk
Jdk使用jdk-8u121-linux-x64.tar.gz
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Hadoop
Hadoop版本:hadoop-2.8.0.tar.gz
下载地址:http://hadoop.apache.org/releases.html
Spark
Spark版本:spark-2.1.0-bin-hadoop2.7.tgz
下载地址:http://spark.apache.org/downloads.html
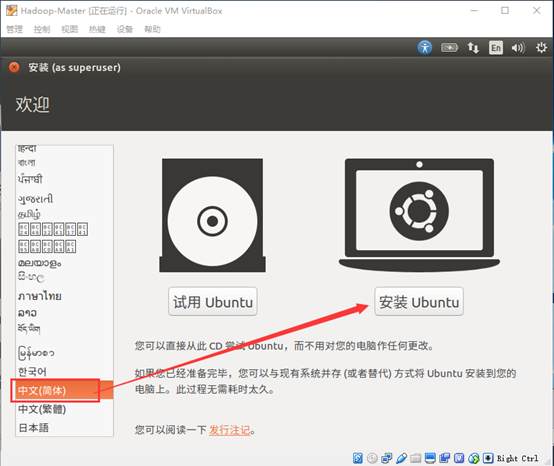
安装Ubuntu
- 选择启动盘
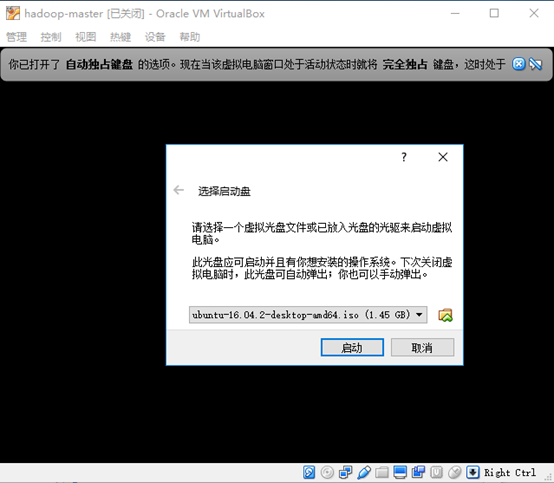
- 选择语言
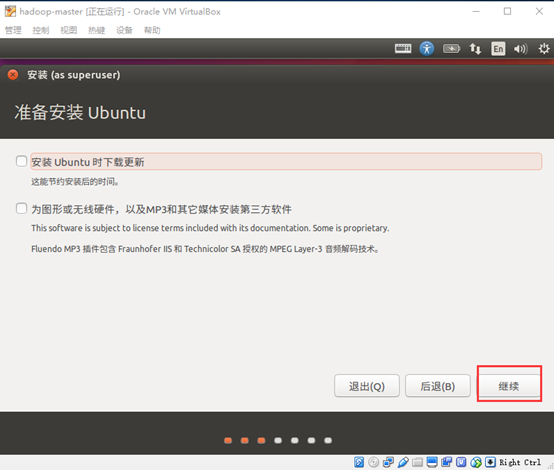
- 安装更新和第三方软件
直接点击继续按钮
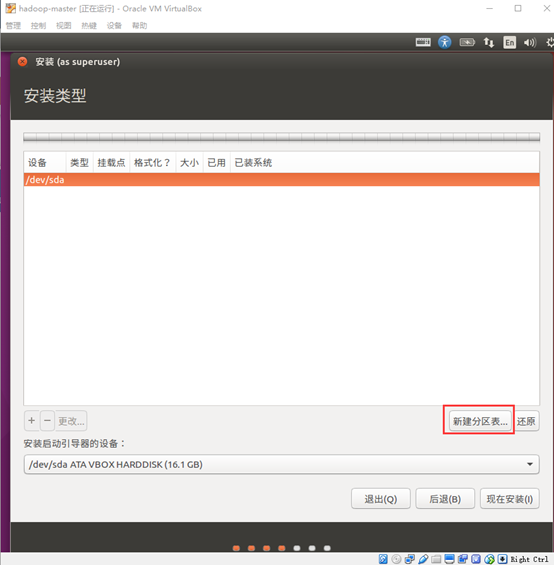
- 确认安装类型
选择"其他选项",点击继续

- 新建分区表
点击"新建分区表" 按钮
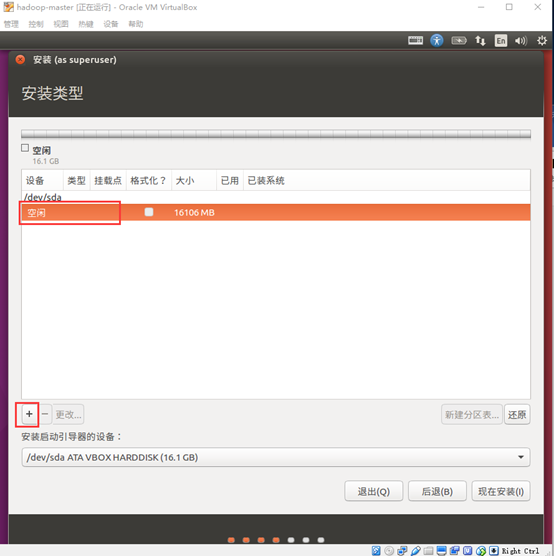
- 创建分区,添加交换空间和根目录
一般来说,我们选择512MB到1G大小作为交换空间,剩下空间全部用来作为根目录
选中空闲,点击"+" 按钮,创建交换空间

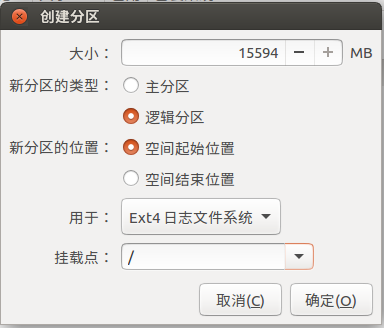
- 创建根目录
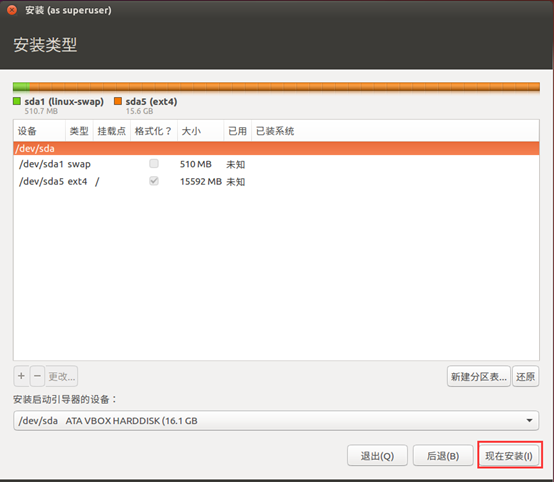
- 开始安装
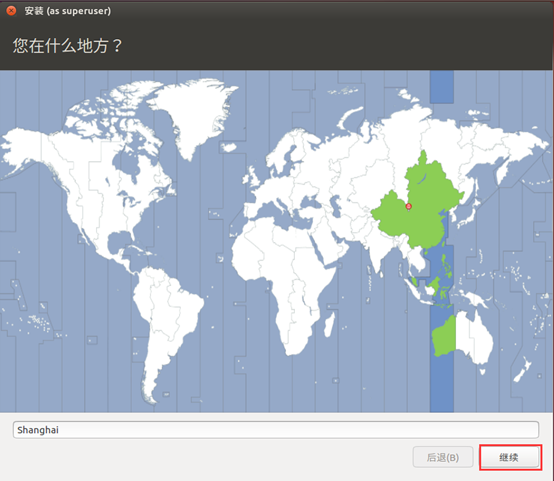
- 选择时区
默认即可,点击"继续"
- 键盘布局
左右都选择汉语
- 设置用户名密码,密码b
- 系统自动安装
Ctrl+alt+T 打开终端,执行下面的命令
sudo apt-get install virtualbox-guest-dkms
新增用户
1、增加一个名为hadoop的用户
sudo useradd -m hadoop -s /bin/bash
这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为 shell。
2、为hadoop用户设置密码,密码设置为hadoop
sudo passwd hadoop
3、为hadoop 用户增加管理员权限
sudo adduser hadoop sudo
4、注销当前用户返回登陆界面,再登陆界面选择刚创建的hadoop用户登陆
5、更新apt
用hadoop用户登陆后,先更新一下apt,
sudo apt-get update
6、安装vim
使用下面的命令安装vim
sudo apt-get install vim
安装SSH、配置SSH无密码登陆
Ubuntu 默认安装了SSH client ,此外还需要安装SSH server:
$ sudo apt-get install openssh-server
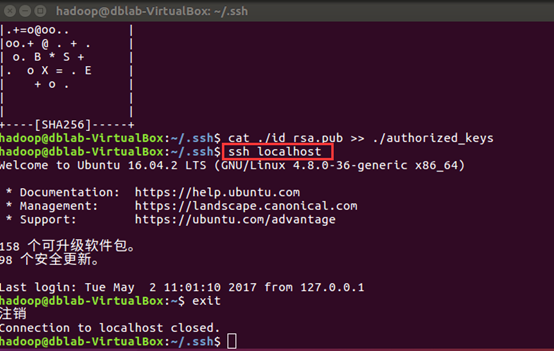
安装后,可以使用如下命令登陆本机:
$ ssh localhost
输入密码可以登陆到本机,我们需要配置称ssh无密码登陆比较方便
退出刚才的ssh
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
此时ssh localhost 命令无需密码可以直接登陆
备注:
在 Linux 系统中,~ 代表的是用户的主文件夹,即 "/home/用户名" 这个目录,如你的用户名为 hadoop,则 ~ 就代表 "/home/hadoop/"。此外,命令中的 # 后面的文字是注释,只需要输入前面命令即可。
在保证了三台主机电脑都能连接到本地localhost后,还需要让master主机免密码登录slave01和slave02主机。在master执行如下命令,将master的id_rsa.pub传送给两台slave主机。
scp ~/.ssh/id_rsa.pub hadoop@slave01:/home/hadoop/
scp ~/.ssh/id_rsa.pub hadoop@slave02:/home/hadoop/

在slave01,slave02 主机上分别运行ls命令

可以看到id_rsa.pub 文件
现在将master的公钥加入各自的节点上
在master主机上通过ssh slave01 可以直接登陆到slave01上
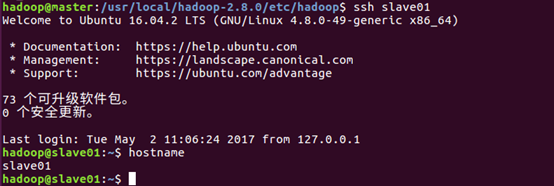
如果master和slave01的用户名不同
还需要在master上修改~/.ssh/config文件,如果没有此文件,自己创建一个
Host master
user Hadoop
Host slave01
user hadoop01
修改hostname
查看当前主机名:
hostname
修改主机名为master
sudo vim /etc/hostname
配置hosts
sudo vim /etc/hosts
重启
安装JDK
下载jdk压缩包方式安装:
- 解压缩放到指定目录
创建目录:
sudo mkdir /usr/java
解压缩到该目录:
sudo tar -zxvf jdk-8u121-linux-x64.tar.gz -C /usr/java
- 修改环境变量
sudo vim ~/.bashrc
文件末尾追加下面内容
#set oracle jdk environment
export JAVA_HOME=/usr/java/jdk1.8.0_131
## 这里要注意目录要换成自己解压的jdk 目录
export CLASSPATH=.:${JAVA_HOME}/lib:${JAVA_HOME}/jre/lib
export PATH=${JAVA_HOME}/bin:$PATH
使环境变量马上生效
source ~/.bashrc
- 设置默认jdk版本
- 测试jdk
Java -version

自动安装
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get update
sudo apt-get insall oracle-java8-installer
安装配置spark
安装hadoop
解压缩到指定目录:
sudo tar -zxf ~/下载/hadoop-2.7.3.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.8.0/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
- 配置环境变量
sudo vim ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop-2.8.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使配置生效
source ~/.bashrc
配置hadoop
修改core-site.xml
sudo vim /usr/local/Hadoop-2.8.0/etc/Hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
修改hdfs-site.xml
sudo vim /usr/local/Hadoop-2.8.0/etc/Hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
修改mapred-site.xml(复制mapred-site.xml.template,再修改文件名)
cp /usr/local/Hadoop-2.8.0/etc/Hadoop/mapred-site.xml.template /usr/local/Hadoop-2.8.0/etc/Hadoop/mapred-site.xml
sudo vim /usr/local/Hadoop-2.8.0/etc/Hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>
修改yarn-site.xml
sudo vim /usr/local/Hadoop-2.8.0/etc/Hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改slaves
sudo vim /usr/local/hadoop-2.8.0/etc/hadoop/slaves

配置好后,将 master 上的 /usr/local/Hadoop-2.8.0 文件夹复制到各个节点上。在 master 节点主机上执行:
- cd /usr/local
- sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
- sudo rm -r ./hadoop/logs/* # 删除日志文件
- tar -zcf ~/hadoop.master.tar.gz ./Hadoop-2.8.0 # 先压缩再复制
- cd ~
- scp ./hadoop.master.tar.gz Slave1:/home/hadoop
在slave01,slave02节点上执行:
- sudo rm -rf /usr/local/Hadoop-2.8.0/ #存在的目录删除
- sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local # 解压缩到指定目录
- sudo chown -R hadoop /usr/local/hadoop # 更改权限
启动hadoop集群
首次启动需要先在 Master 节点执行 NameNode 的格式化:
- hdfs namenode -format # 首次运行需要执行初始化,之后不需要
接着可以启动 hadoop 了,启动需要在 Master 节点上进行:
- start-dfs.sh
- start-yarn.sh
- mr-jobhistory-daemon.sh start historyserver
在集群环境中正确配置JAVA_HOME 后还会报如下错误:

所以要修改hadoop-env.sh 配置文件:
sudo vim /usr/local/hadoop-2.8.0/etc/hadoop/hadoop-env.sh
添加修改JAVA_HOME 信息
运行后,在master,slave01,slave02运行jps命令,查看:
Jps
启动集群后
ResourceManager运行在主节点master上,可以Web控制台查看状态, 访问如下地址:
通过登录Web控制台,查看HDFS集群状态,访问如下地址:
NodeManager运行在从节点上,可以通过Web控制台查看对应节点的资源状态,例如节点slave01:
安装配置spark
安装spark
从windows 将spark安装文件发布到master系统上(命令行下使用pscp命令)
D:\workspace\study\soft>pscp spark-2.1.0-bin-hadoop2.7.tar hadoop@master:~/下载
Hadoop分布式集群安装的更多相关文章
- hadoop 分布式集群安装
这一套环境搭完,你有可能碰到无数个意想不到的情况. 用了1周的时间,解决各种linux菜鸟级的问题,终于搭建好了.. 沿途的风景,甚是历练. 环境介绍: 系统:win7 内存:16G(最低4G,不然跑 ...
- hadoop学习之hadoop完全分布式集群安装
注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流.转载请注明来自: http://blog.csdn.net/ab198604/article/details/8250461 要想深入的 ...
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
- CentOS6安装各种大数据软件 第四章:Hadoop分布式集群配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- (转)ZooKeeper伪分布式集群安装及使用
转自:http://blog.fens.me/hadoop-zookeeper-intro/ 前言 ZooKeeper是Hadoop家族的一款高性能的分布式协作的产品.在单机中,系统协作大都是进程级的 ...
- 超快速使用docker在本地搭建hadoop分布式集群
超快速使用docker在本地搭建hadoop分布式集群 超快速使用docker在本地搭建hadoop分布式集群 学习hadoop集群环境搭建是hadoop入门的必经之路.搭建分布式集群通常有两个办法: ...
- 大数据系列之Hadoop分布式集群部署
本节目的:搭建Hadoop分布式集群环境 环境准备 LZ用OS X系统 ,安装两台Linux虚拟机,Linux系统用的是CentOS6.5:Master Ip:10.211.55.3 ,Slave ...
- 基于Hadoop分布式集群YARN模式下的TensorFlowOnSpark平台搭建
1. 介绍 在过去几年中,神经网络已经有了很壮观的进展,现在他们几乎已经是图像识别和自动翻译领域中最强者[1].为了从海量数据中获得洞察力,需要部署分布式深度学习.现有的DL框架通常需要为深度学习设置 ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
随机推荐
- 字符串转UTF-8码(%开头)
var str = '中'; var code = encodeURI(str); console.log(code); // => %E4%B8%AD
- python-----删除列表中某个元素的3种方法
python中关于删除list中的某个元素,一般有三种方法:remove.pop.del: 1.remove: 删除单个元素,删除首个符合条件的元素,按值删除举例说明: >>> st ...
- jQuery 引用地址(包括jquery和google提供的地址), 节省你不必要的流量
转载自:http://www.cnblogs.com/henw/archive/2011/09/30/2196255.html 你可以使用这句代码读取jQuery的最新版本的代码文件. jquery官 ...
- nodejs 全局对象 global
nodejs中有一个全局对象 global,所有的全局变量都是global对象的属性,glabal最根本的作用是作为全局变量的宿主, 全局变量: 1 在最外层定义的变量 2 全局对象的属性 3 隐式定 ...
- gitbucket
github固然强大,但不怎么适合企业级的开发版本管理,原因相信大家都明白,首先在github上上传和拉取代码速度是比较慢的,再者,在Github上创建一个私有仓库是收费的,那么gitbucket是一 ...
- UVaLive 6585 && Gym 100299F Draughts (暴力+回溯)
题意:给定一个 10*10的矩阵,每一个W可以跳过一个B向对角走到#并把B吃掉,并且可以一直跳直到不能动为止,现在是W走的时候,问你最多吃几个B. 析:直接暴力+回溯,深搜就好. 代码如下: #pra ...
- Android Service完全解析,关于服务你所需知道的一切(下) (转载)
转自:http://blog.csdn.net/guolin_blog/article/details/9797169 转载请注册出处:http://blog.csdn.net/guolin_blog ...
- 51nod1127【尺取】
思路: 尺取,写挫了,debug了半天. #include <bits/stdc++.h> using namespace std; typedef long long LL; const ...
- 拓扑排序+DFS(POJ1270)
[日后练手](非解题) 拓扑排序+DFS(POJ1270) #include<stdio.h> #include<iostream> #include<cstdio> ...
- bzoj 3238: [Ahoi2013]差异【SAM+树形dp】
首先只有lcp(i,j)需要考虑 因为SAM的parent树是后缀的前缀的最长公共后缀(--),所以把这个串倒过来建SAM,这样就变成了求两个前缀的最长公共后缀,长度就是这两个前缀在parent树上的 ...