Spark基本原理
仅作《Spark快速大数据分析》学习笔记
定义:Spark是一个用来实现 快速 而 通用 的集群计算平台;(通用的大数据处理引擎;)
改进了原Hadoop MapReduce处理模型,体现在三方面:
a. 速度;(内存计算)
b. 不仅支持批处理,还支持交互式查询(速度快的成果)、流式计算、机器学习、图计算等;(迭代算法)
c. 丰富的API和易用性;
Spark组件主要组成:
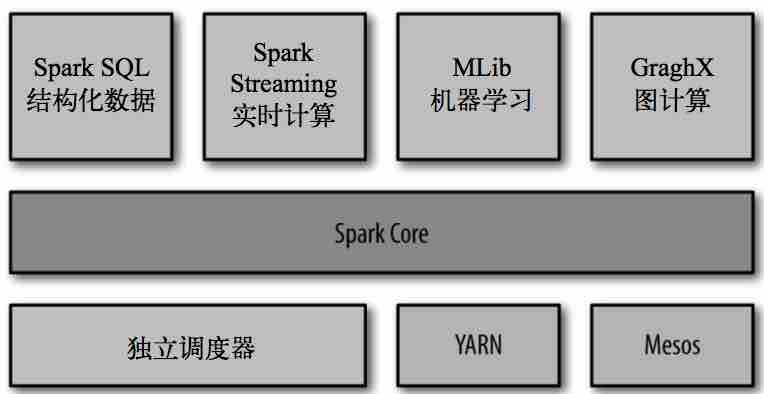
Spark Core:实现了Spark的核心功能,包含任务调度、内存管理、与存储系统交互、错误恢复等;定义了RDD API;
RDD:(resilient distributed dataset)弹性分布式数据集,表示分布在多个计算节点上可以平行操作的元素集合;
通过创建RDD来操作完成 统计计算,这些计算会自动地 在集群上并行进行。
Spark主要的编程抽象;
Spark SQL:Spark操作结构化数据的程序包;
Spark Streaming: Spark 提供的对实时数据进行流式计算的组件 ;
MLlib: 提供常见的机器学习(ML)功能的程序库 ;
GraphX: 是用来操作图(比如社交网络的朋友关系图)的程序库,可以进行并行的图计算;
Spark shell:和其他 shell 工具不一样的是,在其他 shell 工具中你只能使用单机的硬盘和内存来操作数据;
可用来与分布式存储在许多机器的内存或者硬盘上的数据进行交互,并且处理过程的分发由 Spark 自动控制完成;
动作原理:
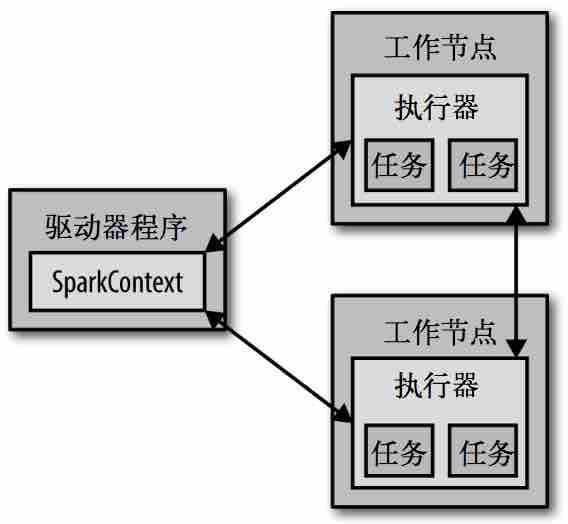
driver program
executor
每个 Spark 应用都由一个 驱动器程序(driver program) 来管理。
a. 驱动器程序包含应用的 main函数;
b. 并且定义了集群上的 分布式数据集;
c. 还对这些 分布式数据集应用了相关操作。
Shell环境下 驱动器程序就是 Spark shell 本身,可利用它输入想要运行的操作。
驱动器程序通过一个 SparkContext对象 来访问Spark,这个对象代表对计算集群的一个连接;slell启动时会自动创建一个SparkContext对象,变量名为sc;
//查看变量 sc
>>> sc
<pyspark.context.SparkContext object at 0x1025b8f90>
一旦有了SparkContext对象,就可以利用它创建RDD,如sc.textFile("/filename"),然后即可进行各种操作;
通常操作RDD的相关操作,驱动器程序一般要管理多个执行器(executor)节点;如count()操作,多个节点会统计文件不同的部分;
Spark基本原理的更多相关文章
- 重温spark基本原理
(一)spark特点: 1.高效,采用内存存储中间计算结果,并通过并行计算DAG图的优化,减少了不同任务之间的依赖,降低了延迟等待时间. 2.易用,采用函数式编程风格,提供了超过80种不同的Trans ...
- spark第一篇--简介,应用场景和基本原理
摘要: spark的优势:(1)图计算,迭代计算(2)交互式查询计算 spark特点:(1)分布式并行计算框架(2)内存计算,不仅数据加载到内存,中间结果也存储内存 为了满足挖掘分析与交互式实时查询的 ...
- 大数据计算新贵Spark在腾讯雅虎优酷成功应用解析
http://www.csdn.net/article/2014-06-05/2820089 摘要:MapReduce在实时查询和迭代计算上仍有较大的不足,目前,Spark由于其可伸缩.基于内存计算等 ...
- 大数据系列之并行计算引擎Spark介绍
相关博文:大数据系列之并行计算引擎Spark部署及应用 Spark: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. Spark是UC Berkeley AMP lab ( ...
- FusionInsight大数据开发---Spark应用开发
Spark应用开发 要求: 了解Spark基本原理 搭建Spark开发环境 开发Spark应用程序 调试运行Spark应用程序 YARN资源调度,可以和Hadoop集群无缝对接 Spark适用场景大多 ...
- Google云平台使用方法 | Hail | GWAS | 分布式回归 | LASSO
参考: Hail Hail - Tutorial windows也可以安装:Spark在Windows下的环境搭建 spark-2.2.0-bin-hadoop2.7 - Hail依赖的平台,并行处 ...
- Spark SQL概念学习系列之Spark SQL基本原理
Spark SQL基本原理 1.Spark SQL模块划分 2.Spark SQL架构--catalyst设计图 3.Spark SQL运行架构 4.Hive兼容性 1.Spark SQL模块划分 S ...
- spark第二篇--基本原理
==是什么 == 目标Scope(解决什么问题) 在大规模的特定数据集上的迭代运算或重复查询检索 官方定义 aMapReduce-like cluster computing framework de ...
- Spark 准备篇-基本原理
本章内容: 待整理 参考文献: <深入理解SPARK:核心思想与源码分析>(第2章) Spark的作业提交及运行流程的异同
随机推荐
- VirtualBox 下主机与虚拟机以及虚拟机之间互通信配置
引用链接:1)http://www.it165.net/os/html/201401/7063.html 2)http://www.cnblogs.com/sineatos/p/4489620.htm ...
- 使用 ftrace 调试 Linux 内核,第 3 部分
内核头文件 include/linux/kernel.h 中描述了 ftrace 提供的工具函数的原型,这些函数包括 trace_printk.tracing_on/tracing_off 等.本文通 ...
- Redis数据结构之简单动态字符串
Redis没有直接使用C语言传统的字符串表示(以空字符结尾的字符数组), 而是自己构建了一种名为简单动态字符串(simple dynamic string,SDS)的抽象类型, 并将SDS用作Redi ...
- Linux主机被SSH精神病(Psychos)暴力攻破后成为肉鸡的攻防过程
近日公司局域网突然变得非常慢,上网受到很大影响,不仅仅是访问互联网慢,就连访问公司内部服务器都感到异常缓慢.于是对本局域网网关进行测试: $ ping 10.10.26.254 发现延时很大, ...
- VMware 虚拟机下载链接
VMware 14 链接: https://pan.baidu.com/s/1mBeyX2Z6hGpbFc8_UC-sEw 提取码: 462t 密钥:AA510-2DF1Q-H882Q-XFPQE-Q ...
- LucaCanali--SystemTap_Linux_IO
https://github.com/LucaCanali/Linux_tracing_scripts/tree/master/SystemTap_Linux_IO
- 改动C:\WINDOWS\system32\drivers\etc\hosts 文件有什么作用
host是一个没有扩展名的系统文件,能够用记事本等工具打开,其作用就是将一些常常使用的网址域名与其相应的IP地址建立一个关联"数据库".当用户在浏览器中输入一个须要登录的网址时,系 ...
- [React] Persist Form Data in React and Formik with formik-persist
It can be incredibly frustrating to spend a few minutes filling out a form only to accidentally lose ...
- docker on UP Board
前言 原创文章,转载引用务必注明链接.水平有限,如有疏漏,欢迎指正. 本文使用Markdown写成,为获得更好的阅读体验和正常的图片.链接,请访问我的博客: http://www.cnblogs.co ...
- C语言宏定义技巧——多次包括头文件内容不同
1. 头文件定义例如以下: /* declears in "funcs.h" */ FUNC_1(ID_FUN1_001) FUNC_1(ID_FUN1_002) FUNC_2( ...